DIY: Ваше собственное облако на базе Kubernetes (часть 2)

Продолжаем серию постов про то как построить своё собственное облако в экосистеме Kubernetes. В прошлой статье мы разобрали как можно подготовить базовый дистрибутив Kubernetes на базе Talos Linux и Flux CD. Теперь нам предстоит обсудить возможность запуска виртуальных машин и всего что для этого необходимо, в первую очередь хранилище и сеть.
Мы поговорим про такие технологии как KubeVirt, LINSTOR и Kube-OVN
Но для начала нам стоит рассказать зачем вообще нужны виртуальные машины, почему бы нам не ограничиться только-лишь контейнерами?
Всё дело в том, что контейнеры в ядре Linux не дают должного уровня изоляции. Несмотря на то, что с каждым годом ситуация становится всё лучше, довольно часто мы сталкиваемся
с уязвимостями, позволяющими покинуть песочницу контейнера и повысить свои привилегии в системе.
С другой стороны и сам Kubernetes изначально не разрабатывался для того чтобы быть мультитенантным, то есть основной паттерн использования всё-таки подразумевает что вы будете создавать отдельный Kubernetes-кластер на каждый независимый проект и команду разработки.
Виртуальные машины являются хорошим компромиссом между производительностью и изоляцией талантов друг от друга. В виртуальных машинах вы можете позволить пользователю запускать произвольный код с правами администратора и не переживать о том что он сможет навредить вашей системе.
Технологии виртуализации в Kubernetes
Есть несколько различных технологий приносящих виртуализацию в мир Kubernetes: в первую очередь это KubeVirt и Kata Containers, но работают они по разному.
Когда Kata Containers имплементирует интерфейс CRI и с помощью гипервизора позволяет организовать дополнительный уровень изоляции для контейнеров запускаемых в едином кластере.

Основная миссия KubeVirt — это позволить запускать традиционные виртуальные машины используя стандартный интерфейс Kubernetes. Виртуальные машины KubeVirt запускаются как обычные процессы прямо в контейнерах. Другими словами, контейнер в Kubernetes — используется всего-лишь как необходимая сущность для запуска процесса виртуальной машины. Это можно хорошо видеть посмотрев на то как реализована живая миграция виртуальных машин в KubeVirt. При необходимости миграции виртуальная машина просто «перетекает» из одного контейнера в другой:

Есть ещё и альтернативный проект — Virtink, который имплементирует легковесную виртуализацию используя Cloud-Hypervisor и изначально ориентирован на запуск виртуальных кластеров Kubernetes используя Cluster API.
Мы имея большую экспертизу с KubeVirt и ввиду того что мы хотели получить наиболее стандартную и функциональную среду для запуска классических виртуальных машин, мы решили использовать именно его.
KubeVirt легко устанавливается и практически сразу позволяет вам запускать виртуальные машины из containerDisk — это когда образ для ВМ хранится и распространяется прямо в докер-образе.
Виртуальные машины, запускаемые с containerDisk хорошо подходят для создания воркеров Kubernetes и других ВМ которым не нужно сохранение состояния.
Для расширения возможностей управления персистентными данными, KubeVirt предлагает отдельный инструмент Containerized Data Importer (CDI). Он, в свою очередь, позволяет клонировать PVC и заполнять их данными из базовых образов. Использование CDI необходимо если вы хотите автоматически провиженить персистентные тома для ваших виртуальных машин, а так же потребуется вам в дальнейшем для использования KubeVirt CSI Driver.
Но прежде всего вам придется решить, где и как вы будете хранить эти данные.
Реализация хранилища под данные ВМ
С появлением интерфейса CSI появилось и огромное количество технологий интегрирующихся с Kubernetes. KubeVirt максимально переиспользует возможности все возможности CSI, поэтому выбор хранилища под виртуализацию обычно эквивалентен выбору хранилища под Kubernetes. Но есть и нюансы, во первых это тип хранилища. Когда для контейнеров вы чаще всего ожидаете получить обычную файловую систему, то для виртуальных машин лучше всего подойдут блочные устройства.
На данный момент интерфейс CSI в Kubernetes позволяет заказывать тома как файловую систему, так и блочные устройства, но необходимо удостовериться что это поддерживает ваше хранилище.
Использование блочных устройств для виртуальных машин уберёт лишний уровень абстракции и в большинстве случаев позволит вам использовать режим ReadWriteMany для организации доступа с нескольких нод одновременно. Использование ReadWriteMany томов — это необходимое требование чтобы работала live-миграция виртуальных машин в KubeVirt.
Теперь о хранилищах, они бывают внешними или интегрированными в случае гиперконвергентной инфраструктуры. Использование внешних хранилищ почти всегда делает систему более стабильной, так как ваши данные хранятся на отдельных нодах ответственных за хранилище.

внешнее хранилище данных
лПодход с внешними хранилищами часто используется в крупных энтерпрайз-системах, потому что такое хранилище часто предоставляет внешний вендор, а за интеграцию с Kubernetes ответственна лишь малая часть — CSI-драйвер, который устанавливается в кластер и ответственен за заказ томов в этом хранилище и подключение их к подам, запускаемым Kubernetes. Хотя такое хранилище так же может быть реализовано и используя лишь свободные технологии.
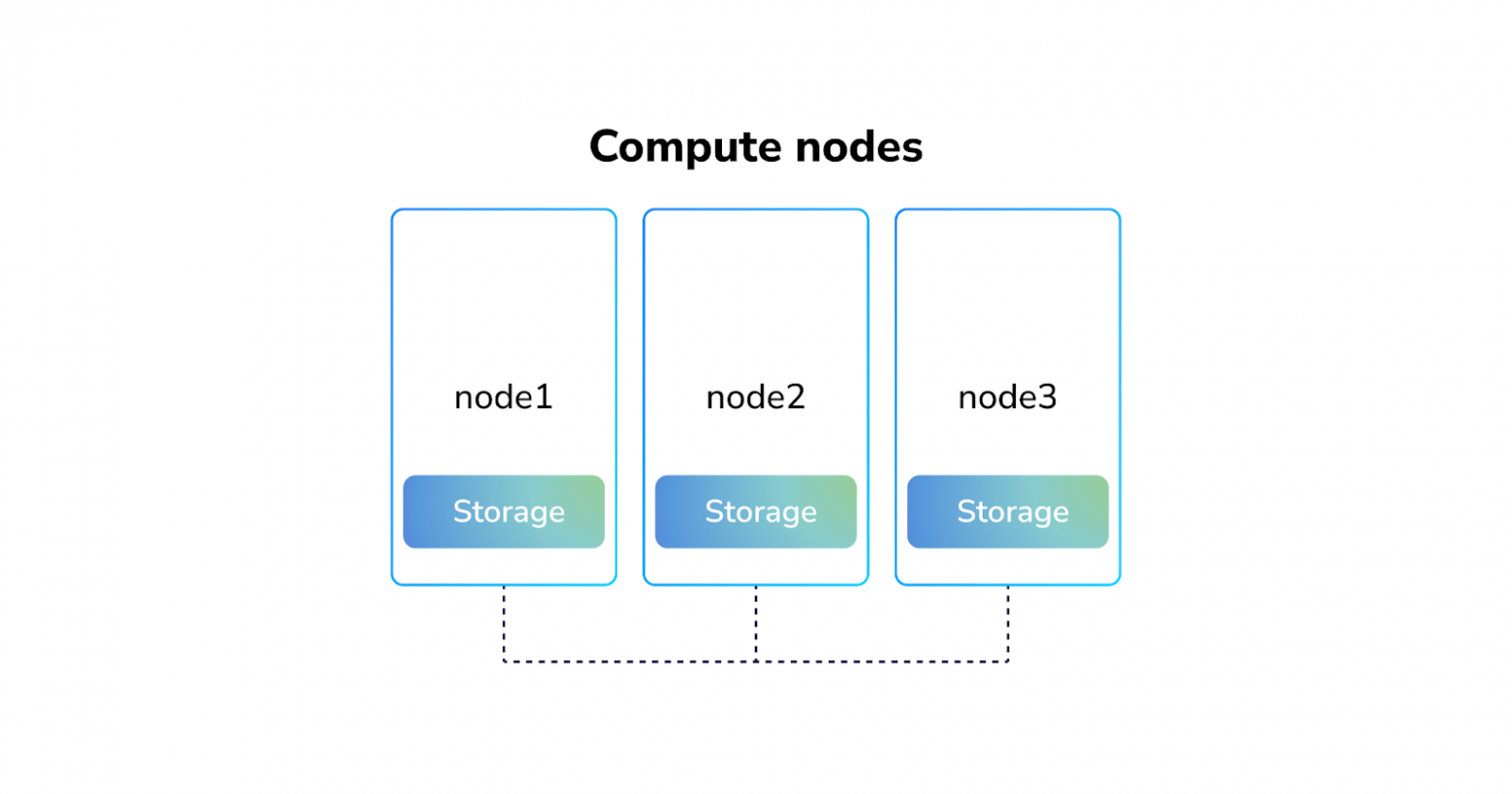
локальное хранилище данных
Гиперконвергентные системы часто реализуются с помощью локальных решений, когда вам не нужна репликация и более умными программными кластерными хранилищами, часто устанавливаемых прямо в Kubernetes: Rook, OpenEBS, Longhorn, LINSTOR и другими.
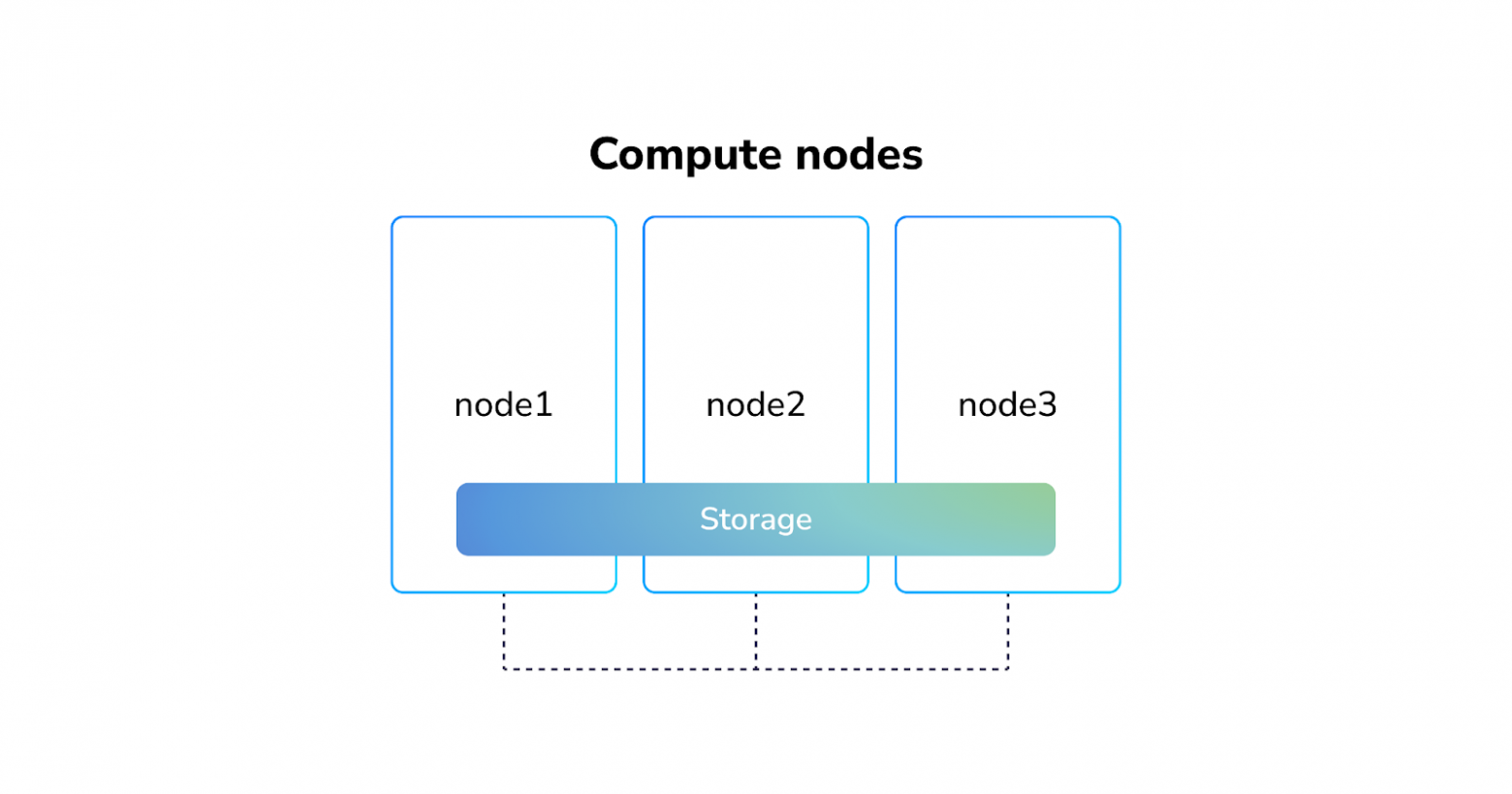
кластерное хранилище данных
Гиперконвергентная система имеет как плюсы, это например data locality — что означает ваши данные могут быть доступны локально, а значит быстрее и скорость доступа к ним, но так же и минусы — такой системой сложнее управлять и обслуживать.
Мы в Ænix хотели предоставить наиболее готовое решение, которые вы могли бы использовать без необходимости покупать и устанавливать отдельное внешнее хранилище, а также было бы оптимально по скорости и использованию ресурсов. Таким решением стал LINSTOR.
Использование проверенных временем и популярных в индустрии технологий вроде LVM и ZFS в качестве бэкенда позволяют быть уверенными в том что данные надёжно сохранены. А репликация на основе DRBD работает быстро, и не требовательна к ресурсам ноды.
Для установки LINSTOR в Kubernetes существует проект Piraeus, который имеет уже всё необходимое для того чтобы использовать его с KubeVirt.
В случае если вы используете Talos Linux, как мы описывали в прошлой статье, вам потребуется включить необходимые модули ядра заранее, как описано в инструкции.
Сеть для виртуальных машин
Несмотря на наличие похожего интерфейса CNI — в действительности сеть в Kubernetes несколько сложнее и как правило состоит из нескольких не связанных друг с другом частей. Давайте разберём каждую из них:
Сеть нод (сеть датацентра)
Сеть с помощью которой ноды связаны между собой обычно никак не управляется Kubernetes, но является важной частью, так как без неё ничего работать не будет. На практике, в bare metal инфраструктуре на данном уровне может вполне существовать и несколько подобных сетей: для коммуникации нод между собой, для репликации хранилища, для доступа извне и т.п.:

сеть нод (сеть датацентра)
Настройка сетевого взаимодействия между физическими узлами выходит за пределы обсуждения данной статьи, потому как в большинстве ситуаций Kubernetes использует уже существующую сетевую инфраструктуру.
Сеть подов
Это сеть, которую предоставляет вам CNI-плагин. Задача CNI-плагина обеспечить прозрачную связность между всеми контейнерами и нодами в кластере. При этом большинство CNI-плагинов реализуют плоскую сеть из которой выделяются отдельные блоки IP-адресов для использования на каждой ноде:

сеть подов (CNI-plugin)
На деле у вас в кластере может быть и несколько CNI-плагинов, управляемых Multus. И этот подход часто используется в решениях основаных на KubeVirt — Rancher и OpenShift. Основной CNI-плагин используется в основном используется для интеграции с Kubernetes, а дополнительные CNI-плагины для реализации приватных сетей (VPC) и интеграции с физическими сетями вашего дата центра.
В качестве дополнительных CNI-плагинов могут использоваться как простые плагины из стандартного инструментария CNI, так и более специализированные вроде macvtap-cni.
В отличие от контейнеров вам также придётся побеспокоиться об IPAM (IP Address Management), в виртуальных средах эту задачу часто решает DHCP, а также о выделении MAC-адресов для виртуальных машин.
В Cozystack мы решили положиться на Kube-OVN, который полностью закрывает вопрос предоставления сети для виртуальных машин, имеет сущности для управления IP- и MAC-адресами, поддерживает live-миграцию виртуальных машин с переносом IP-адреса с ноды на ноду и создания VPC для физического разделения сетей между тенантами.
Используя Kube-OVN вы можете назначать отдельные подсети на целый неймспейс, или подключать их как дополнительные через Multus.
Сеть сервисов
Помимо CNI-плагина, в Kubernetes есть также сеть сервисов, она нужна в первую очередь для service discovery. Дело в том, что изначально Kubernetes был спроектирован так, чтобы запускать поды со случайным адресом. А сеть сервисов предоставляет используется для того чтобы предоставлять удобную абстракцию (стабильные IP-адреса и DNS-имя), которые всегда направят трафик в нужный под.

сеть сервисов (services plugin)
За реализацию сети сервисов в Kubernetes отвечает services plugin, и несмотря на то, что в наше время он всё чаще поставляется в составе CNI-плагина, его стоит рассматривать как отдельную сущность. Стандартная реализация называется kube-proxy и используется в большинстве кластеров. Наиболее продвинутую реализацию предлагает проект Cilium, который можно запустить в режиме kube-proxy replacement.
Cilium разработан на основе технологии eBPF, которая позволяет эффективно оффлоадить сетевой стек Linux, улучшая тем самым производительность и безопасность по сравнению с классическими методами основанными на iptables.
На деле Cilium довольно легко интегрируется с kube-ovn, предоставляя в связке удобную мультитенантную сеть для виртуальных машин, а так же расширенные сетевые политики и функциональность сети сервисов.
Балансировщик внешнего трафика
На данном этапе у вас уже есть всё необходимое для запуска виртуалок в Kubernetes. Но на самом деле это ещё не всё. Вам необходим надёжный способ доступа снаружи вашего кластера к вашим сервисам и внешний балансировщик — это как раз та сущность которая вам поможет в организации этого.
Для Kubernetes на bare-metal существует несколько балансировщиков: MetalLB, kube-vip, LoxiLB, а так же встроенные реализации анонса сервисов в Cilium и Kube-OVN.
Основная задача балансировщика — это предоставить стабильный внешний адрес и направить трафик в сеть сервисов, тогда services plugin направит его уже к вашим подам и виртуалкам:

внешний балансировщик
В большинстве случаев создание балансировщика на bare metal осуществляется через назначение плавающего IP-адреса внутри кластера, который анонсятся наружу с помощью протоколов ARP/NDP или BGP.
После изучения различных вариантов, мы решили остановиться на MetalLB в качестве наиболее простого и надежного решения, хоть и не привязываем строго к использованию только его.
В режиме L2 спикеры MetalLB постоянно обмениваются своим состоянием друг с другом с помощью протокола memberlist, что позволяет не зависеть от Kubernetes control-plane для реализации отказоустойчивости.
На этом про виртуализацию, хранилище и сети в Kubernetes у меня всё.
Все эти технологии уже преднастроены и готовы к использованию в Cozystack, вы можете попробовать их совершенно бесплатно.
В следующей статье мы подробно расскажем о том как используя полученную систему мы реализуем провижининг полнофункциональных Kubernetes-кластеров по кнопке.
