Оценка конкурентности поисковых запросов по вариациям поисковой выдачи
 Оценка степени конкуренции по ключевому запросу является одной из сакральных задач поисковой оптимизации. Надежда обнаружить незамеченный конкурентами запрос с хорошей конверсией сродни поиску филосовского камня. Попробуем и мы внести свою лепту в эту алхимическую тусовку.
Оценка степени конкуренции по ключевому запросу является одной из сакральных задач поисковой оптимизации. Надежда обнаружить незамеченный конкурентами запрос с хорошей конверсией сродни поиску филосовского камня. Попробуем и мы внести свою лепту в эту алхимическую тусовку.
Оказывается, что степень конкуренции можно практически мгновенно оценить только лишь сравнив поисковую выдачу по двум взаимосвязанным запросам — без анализа пузомерок, сайтов-конкурентов, статистики стоимости клика и перелопачивания гор информации.
БэкграундТрудность продвижения в ТОП по заданному ключевому запросу справедливо связывают с количеством конкурентов, борющихся за первые места. Способов оценки степени этой «трудности» существует несколько. Вот самые распространённые из них.Анализ факторов ранжирования. Этот способ состоит в анализе самой поисковой выдачи и сайтов, в неё входящих: общее количество сайтов, количество контекстной рекламы, среднее количество ссылок, степень оптимизированности каждого сайта и т.п. Затем эта информация с помощью весовой функции сводится к одному показателю KEI (Keyword Effectiveness Index), по которому и сравниваются запросы. Основные проблемы применения этого способа состоят в выборе состава показателей, способов их (автоматического) измерения и весов. Просто заметим, что Яндекс использует для ранжирования штук 800 нетривиально рассчитываемых параметров.
Анализ ставок контекстной рекламы. Этот способ сводится к оценке и сравнению аукционных ставок стоимости клика в системах контекстной рекламы (Yandex Direct, Google AdWords). Связь понятна — чем «интереснее» запрос, тем больше рекламодателей борятся за первые места, тем выше ставка. Но принципы формирования цен в контексте и в поисковой оптимизации различаются, что может повлиять и на точность оценок.
Сравнение с конкурентными бюджетами. Эта информация доступна в многочисленных системах автоматического продвижения (SeoPult, Rookee) в качестве статистики её пользователей. Но проблема в том, что по среднечастотным и низкочастотным запросам такой статистики может быть недостаточно, поэтому нередко можно увидеть в качестве оценок стоимости стандартную минимальную сумму. Кроме того, основная (если не единственная) составляющая такого бюджета — ссылочный бюджет. А ссылки нынче играют всё меньшую роль.
Идея Но есть ещё один интересный способ, основанный на некоторых свойствах языка запросов поисковых систем. В этом языке обычно существуют такие понятия как широкие и точные запросы. Смысл их в том, что в ответ на широкий запрос можно получить информацию во всех словоформах и с любым порядком следования слов, а в ответ на точный — именно в том виде, как запрос сформирован.Например, в нотации поискового языка Яндекса широкий запрос будет выглядеть как [купить машину] А точный как [»! купить ! машину»] Основными требованиями к поисковой оптимизации сайтов являются наличие точных вхождений поискового запроса в тексты и разметку сайта, а также использование их в качестве анкоров внешних и внутренних ссылок. В результате сайт, оптимизированный под конкретный запрос, отличается от неоптимизированного бо́льшим количеством именно точных вхождений поискового запроса.Если запрос высококонкурентный, то разница в результатах выдачи по широкому и точному запросам будет различаться несущественно, поскольку оптимизированных сайтов достаточно много и поисковому алгоритму есть из чего выбрать. Если же запрос низкоконкурентный, то недостаток оптимизированных сайтов поисковый алгоритм будет возмещать остальными — теми, где сможет обнаружить слова, близкие к поисковому запросу, но возможно в другой морфологии и в другом порядке следования.В результате, чем ниже конкуренция, тем поисковая выдача разнообразнее, «рыхлее», и тем проще в неё проникнуть новому кандидату. Чем конкуренция выше — тем меньше разнообразия, и тем больше вероятность, что она будет заполнена одними и теми же фигурантами, протиснуться между которыми будет нелегко.
В качестве примера возьмём навскидку несколько разнообразных запросов из автомобильной тематики (чтобы заведомо гарантировать разную степень конкуренции) и посмотрим, что происходит с ними в Яндексе.Широкие и точные формы этих запросов, а так же частотность широких запросов выглядят следующим образом:
[кроссовер] [»! кроссовер»] (239 714)
[митсубиси аутлендер] [»! митсубиси ! аутлендер»] (73 760)
[мицубиси аутлендер] [»! мицубиси ! аутлендер»] (68 149)
[мицубиши аутландер] [»! мицубиши ! аутландер»] (128)
[mitsubishi outlander] [»! mitsubishi! outlander»] (41 392)
Вот как выглядят результаты ранжирования по этим запросам. Здесь цветом отмечены сайты, совпадающие в выдаче по широкому и точному вариантам.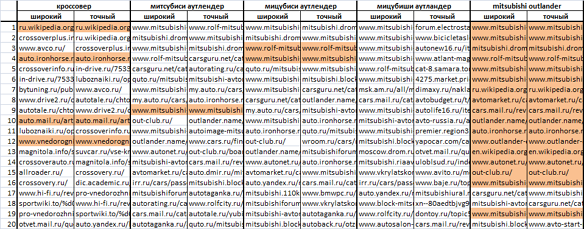
Невооружённым глазом сразу видна разница между [mitsubishi outlander] (41 392) и [мицубиши аутландер] (128) — то есть между запросами с заведомо разной конкуренцией.
Расчёт Визуально идея ясна — чем больше разница между поисковыми выдачами по широкой и точной формам поискового запроса — тем ниже конкуренция. Чем разнообразие ниже — тем конкуренция выше. Но как теперь это посчитать? Как измерить степень этого разнообразия? Воспользуемся для этого выражением для расстояний между рейтингами, полученным в работе Оценка вариативности поисковой выдачи.Примеры расчётов по этому выражению можно посмотреть здесь.
Итак, имеем следующую формулу для расчёта взвешенного относительного расстояния между двумя рейтингами R» и R»
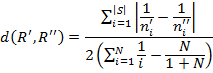
Здесь: N — длина рейтинга (ТОП5, ТОП10 и т.п.);|S| — количество элементов в множестве S = R» U R», то есть общее количество уникальных объектов в двух рейтингах; n«i и n«i — позиции i-го элемента соответственно в рейтинге R» и R», причём если объект отсутствует в рейтинге, то его позиция в этом рейтинге принимается за N+1.
Чем выше разнообразие выдачи, тем больше расстояние между рейтингами. Поэтому в качестве степени конкуренции будем использовать величину, противоположную расстоянию:
Cn = 1 — d
Для наших запросов получим следующие значения степени конкуренции (в процентах) по рейтингу ТОП100.
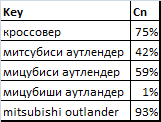
Вопрос теперь в том, на какую глубину просматривать поисковую выдачу. Для ответа на него нам поможет зависимость степени конкуренции от длины рейтинга, представленная на следующем графике
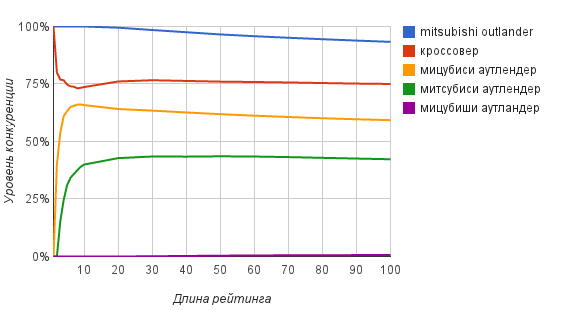
Как видно из графика, уже на уровне ТОП20-ТОП30 можно получать достаточно точные оценки степени конкуренции.
Апробация Какой же метод оценки степени конкуренции точнее отражает затраты на достижение верхушки поискового рейтинга? Я не знаю ответа на этот вопрос. Как не знаю ответа и на более простые вопросы — как вообще посчитать фактические затраты на SEO. Или хотя бы фактические затраты на оптимизацию по конкретному (отдельному) ключевому запросу.Как тогда можно оценить точность прогноза величины, которую мы не в состоянии измерить? Ситуация как в диетологии: можно придумать кучу диет, но реально оценить, что повлияло на продолжительность жизни так и не получится. И так же, как и в диетологии, наверное, получить ответ можно только на опыте многих поколений.
Пока же единственным вариантом проверки точности предложенного способа является здравый смысл и сравнение с аналогами. Ну, а по простоте и удобству ему конкурентов нет. Ведь он может давать оценки даже для вновь появившихся ключевых фраз (внимание тем, кто зарабатывает на трендах)!
Что касается аналогов, то ниже представлены сравнительные результаты оценки степени конкуренции с использованием некоторых из перечисленных ранее методов.
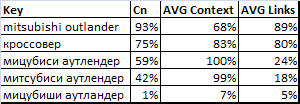
Здесь: Cn — оценка степени конкуренции полученная нашим методом.AVG Context — оценка, полученная по статистике стоимости клика в системах контекстной рекламы (Yandex Direct и Google AdWords). Значения усреднены и пронормированы (за 100% взята максимальная стоимость клика).AVG Links — оценка, полученная в системах автоматического продвижения (SeoPult, SeoPult PRO, Rookee) по значениям рекомендуемого бюджета. Значения усреднены и пронормированы (за 100% взят максимальный бюджет).
Хотя значения и расходятся, но главное, что порядок ранжирования при использовании оценок Cn и AVG Links совпадает. Трудно сказать, какие из этих двух оценок точнее, но в исходных данных SeoPult PRO по трём запросам из пяти статистика отсутствовала (предлагался минимально возможный бюджет системы). Так что есть все основания полагать, что наш алгоритм может справиться с этой задачей лучше.
Что касается прогноза по контекстным ставкам AVG Context, то он явно выбивается из общей тенденции. Пользоваться этим методом нужно с большой осторожностью.
Заключение Простота предлагаемого способа очевидна. Точность расчётов представляется достаточно хорошей. Плюс возможность получать оценки в ситуациях, когда остальные способы бессильны.Что ещё нужно, чтобы достойно встретить старость конкурентов?
