Обзор первого эластичного хранилища данных Snowflake Elastic Data Warehouse
В качестве СУБД для хранилища данных мы используем Vertica, но регулярно анализируем имеющиеся альтернативы, чтобы не пропустить новые интересные технологии.
В апреле с нами связались представители компании Snowflake Computing и предложили попробовать их продукт Snowflake Elastic Data Warehouse — облачное хранилище данных. Они работают над созданием эластичной системы, которая могла бы легко расширяться по мере необходимости — при увеличении объема данных, нагрузки и прочих неприятностях.
Обычно СУБД работают в условиях, когда объем доступных ресурсов ограничен имеющимся оборудованием. Чтобы добавить ресурсов, надо добавить или заменить сервера. В облаке же ресурсы доступны в тот момент, когда они понадобились, и их можно вернуть, если они больше не нужны. Архитектура Snowflake позволяет воспользоваться всеми преимуществами облака: хранилище данных может мгновенно расширяться и сжиматься, не прерывая выполняющиеся запросы.
Существуют и другие хранилища данных, которые работают в облаках, самое известное — Amazon Redshift. Но для их расширения все равно необходимо добавлять сервера, хоть и виртуальные. Что влечет за собой перераспределение данных, а значит — в той или иной мере даунтайм. Про сжатие таких хранилищ речь вообще не идет, никто не захочет лишний раз перекладывать все данные с места на место.
Snowflake предоставляет клиенту эластичное хранилище данных в виде сервиса (Data Warehouse as a Service). Это высокопроизводительная колоночная СУБД, которая поддерживает стандартный SQL и соответствует требованиям ACID. Доступ к данным осуществляется через Snowflake Web UI, Snowflake Client command-line interface, а также ODBC и JDBC.
Мы провели полный цикл тестирования Snowflake, включающий в себя тестирование производительности загрузки данных, тестовых SQL-запросов, масштабирования системы, а также базовых операционных сценариев.
Но прежде чем переходить к результатам тестов, стоит более подробно остановиться на архитектуре.
Архитектура
В качестве платформы Snowflake использует Amazon Web Services. СУБД состоит из трех компонентов: уровень хранения данных (Database Storage), уровень обработки данных (Processing) и облачные сервисы (Cloud Services).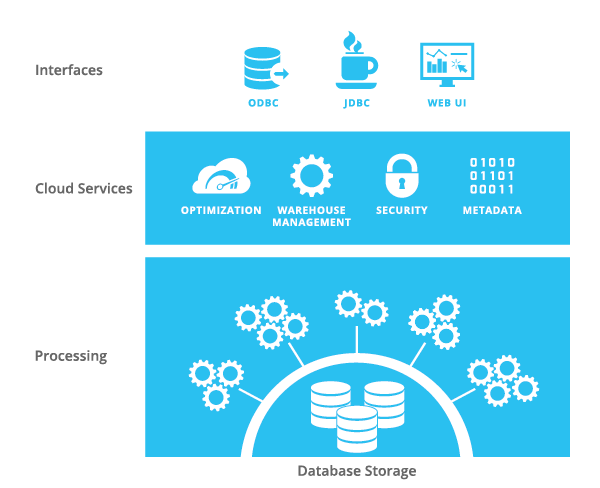
Уровень хранения данных отвечает за безопасное, надёжное и эластичное хранение данных. Эти замечательные свойства обеспечиваются не самим Snowflake, а S3. Данные хранятся в S3, у клиентов нет к ним прямого доступа. Чтобы загружать данные в Snowflake, создаются специальные S3 buckets (staging area), куда нужно складывать файлы, из которых потом можно загрузить данные с помощью Snowflake SQL. Для создания staging area и копирования туда файлов можно использовать стандартные сервисы Amazon Web Services или специальные функции Snowflake SQL. Можно подключить существующие S3 buckets как Staging area, тогда файлы можно загружать без предварительного копирования. При загрузке данные сжимаются (gzip) и приводятся к колоночному формату. Индексы в Snowflake не предусмотрены.
Распределение данных (data distribution) осуществляется автоматически на основе статистики использования данных. Партиционирования нет.
Доступ к данным осуществляется через уровень обработки данных — это набор виртуальных серверов, которые могут обращаться к файлам S3. «Виртуальные кластера» могут состоять из 1 (X-Small), 2 (Small), 4 (Medium), 8 (Large) или 16 (X-Large) виртуальных серверов (ЕС2). Все сервера в виртуальном кластере одинаковы и равнозначны, прямого доступа к ним клиент не имеет. С точки зрения клиента виртуальный кластер — это единое целое. Сервера ЕС2 могут быть двух типов: Standard и Enterprise. На момент тестирования в качестве Standard использовались ЕС2 с 16Gb RAM, 160Gb SSD, 8 cores. Enterprise — в 2 раза больше. У Snowflake есть договор с Амазоном, новые инстансы они получают в течение 5 минут. Т.е. расширение виртуального кластера или создание нового занимает 1-5 минут. Поскольку ЕС2 не хранят никаких данных, их потеря совершенно не критична. Если произошел сбой, ЕС2 просто создается заново.
SSD виртуальных серверов используются в качестве кеша кластера. При выполнении запроса данные из S3 попадают в кеш кластера, и все последующие запросы будут этот кеш использовать. При наличии данных в кеше запросы выполняются до 10 раз быстрее.
Можно создать несколько виртуальных кластеров, которые будут одновременно обращаться к одним и тем же данным. Это позволяет лучше распределить нагрузку. Можно, например, использовать разные виртуальные кластера для обращения к разным таблицам — в этом случае данные разных таблиц будут закешированы разными кластерами, что фактически увеличит объем кеша базы данных.
Для управления данными используются облачные сервисы Snowflake. Используя Snowflake UI, клиент создает базы данных и таблицы, пользователей и роли. Метаданные используются на уровне обработки данных для определения наличия необходимых прав доступа, для компиляции запросов и т.п. Как и где хранятся метаданные, Snowflake не объясняет.
Для каждого виртуального кластера нужно выбрать базу данных, с которой он будет работать. Перед выполнением запроса пользователь должен указать, каким кластером нужно его выполнить. Можно задать кластер по умолчанию.
Можно запускать кластера по расписанию, можно автоматически при поступлении запроса, можно автоматически останавливать, если запросы не поступали в течение определенного времени. Также можно увеличить или уменьшить количество серверов в работающем кластере.
В результате клиент получает эластичное хранилище, которое никак не ограничено по размеру. Никаких процедур по установке, настройке и сопровождению выполнять не нужно — все это обеспечивает Snowflake. Нужно лишь зайти на сайт, создать таблицы, загрузить данные, и запустить запрос.
Особенности
У Snowflake есть несколько интересных особенностей. Например, есть возможность восстановить недавно удаленный объект: таблицу, схему и даже базу данных.
Другая особенность позволяет посмотреть результаты недавно выполненного запроса. Для повторного просмотра данные доступны в течение 24 часов только пользователю, выполнившему запрос. Для просмотра сохраненных результатов не нужен виртуальный кластер, т.к. Snowflake хранит их вместе с метаданными.
Snowflake очень гордится возможностью обработки частично структурированных данных, например JSON или Avro. Данные загружаются как есть, без всякой трансформации и без определенной схемы. Потом можно обращаться к ним на языке SQL, указывая определенные «поля» записи. В рамках тестирования скорость таких обращений мы не проверяли, но обычно в подобных случаях производительность приносится в жертву удобству. Например, в Vertica эта функциональность работает намного медленнее, чем запросы к обычным таблицам.
Цена
Стоимость сервиса складывается из оплаты за объем данных в S3 и почасовой оплаты за используемые виртуальные сервера. Т.е. если у клиента 2 виртуальных кластера по 4 сервера, и они работали по 9 часов 3 минуты, то надо будет заплатить за 2*4*10=80 часов работы сервиса. Немаловажно, что виртуальные сервера оплачиваются только за время работы. Это позволяет существенно экономить, если нагрузка неравномерна в течение дня или система используется лишь эпизодически.
Тестирование
Наш тестовый набор данных состоял из одной большой таблицы (чуть больше 1 миллиарда строк) и нескольких маленьких (от 100 до 100 тысяч строк) — простая схема типа “звезда”. Данные загружали из текстовых файлов в формате CSV. Snowflake советует загружать данные мелкими порциями, один файл на CPU core – так ресурсы будут использоваться наиболее эффективно. Для этого необходимо разбить файл на куски до того, как он попал в Staging area. Еще быстрее копировать данные из одной таблицы в другую. При изменении данных таблица эксклюзивно блокируется (чтение возможно, все запросы DML ставятся в очередь).
| Размер кластера | Вставка из файла | Время |
|---|---|---|
| Medium (4 EC2) | 1 файл 8 ГБ copy into table1 from @~/file/file.txt.gz file_format='csv' |
42m 49.663s |
| Medium (4 EC2) | 11 файлов по 750 МБ copy into table1 from @~/file/ file_format='csv' |
3m 45.272s |
| Small (2 EC2) | 11 файлов по 750 МБ copy into table1 from @~/file/ file_format='csv' |
4m 33.432s |
| Копирование из другой таблицы | ||
| Medium (4 EC2) | insert into table2 select * from table1 | 1m 30.713s |
| Small (2 EC2) | insert into table2 select * from table1 | 2m 42.358s |
Затем мы перешли к выполнению простых запросов. Тут Snowflake нас порадовал, запросы к двум-трем таблицам с фильтрами как по большой, так и по маленьким выполнялись достаточно быстро.
| Размер кластера | Размер таблицы | Первый запуск (S3) | Повторный запуск (кеш) |
|---|---|---|---|
| Small (2 EC2) | 1 млрд строк, 24.4 ГБ | 22,48 сек | 1,91 сек |
| Small (2 EC2) | 5 млрд строк | 109 сек | 7,34 сек |
| Medium (4 EC2) | 1 млрд строк, 24.4 ГБ | 10,67 сек | 1,2 сек |
| Medium (4 EC2) | 5 млрд строк | 3,65 сек |
Видно, что сканирование таблицы выполняется в 10 и более раз быстрее, если данные закешированы. Также видно, что Snowflake хорошо масштабируется, т.е. увеличение числа серверов в кластере дает практически линейный прирост производительности.
Для анализа полученных результатов всегда нужен эталон. В нашем случае это результаты проведения того же теста на кластере Vertica из 5 серверов. Все пять серверов одинаковые: 2xE5-2630, 32GB RAM, 8x1000GB R10 SATA.
| Snowflake (первый) | Snowflake (второй) | Vertica | |
|---|---|---|---|
| Размер кластера | Medium (4 EC2) | Medium (4 EC2) | кластер из 5 серверов |
| Размер таблицы (строк) | 1 млрд | 1 млрд | 1 млрд |
| select count(*) from table1 | 0.2 | 0.27 | 0.69 |
| select count(*), sum(float1) from table1 | 10.6 | 1.33 | 2.89 |
| select count(*), sum(float1) from table1 where country_key=1 | 5.8 | 1.41 | 3.63 |
| select count(*), sum(float1) from table1 a, country c where c.country_code='US' and a.country_key=c.country_key |
2.3 | 1.70 | 2.14 |
| select count(*), sum(float1) from table1 a, country c where c.country_code='ZA' and a.country_key=c.country_key; |
2.1 | 1.51 | 1.94 |
| select count(*), sum(float1), c.country_code from table1 a, country c where a.country_key=1 and a.country_key=c.country_key group by c.country_code |
2.3 | 1.99 | 2.17 |
| select count(*), sum(float1), c.country_code from table1 a, country c where a.country_key>-1 and a.country_key<100000 and a.country_key=c.country_key group by c.country_code; |
4.4 | 4.17 | 3.26 |
| select count(*), sum(float1), c.country_code from table1 a, country c where c.country_code in ('US', 'GB') and a.country_key=c.country_key group by c.country_code; |
2.3 | 2.22 | 2.42 |
| select count(*), sum(float1), c.country_code from table1 a, country c where c.country_code in ('US', 'GB') and a.country_key=c.country_key and a.time_key<45000 group by c.country_code; |
3.8 | 1.47 | 1.03 |
| select count(*), sum(float1), c.country_code from table1 a, country c, time t where c.country_code in ('US', 'GB') and a.country_key=c.country_key and t.date>='2013-03-01' and t.date<'2013-04-01' and t.time_key=a.time_key group by c.country_code; |
3.3 | 1.97 | 1.23 |
| select count(*), sum(float1), c.country_code, r.revision_name from table1 a, country c, time t, revision r where c.country_code in ('US', 'GB') and a.country_key=c.country_key and t.date>='2013-03-01' and t.date<'2013-04-01' and t.time_key=a.time_key and r.revision_key=a.revision_key group by c.country_code, r.revision_name; |
4.4 | 2.66 | 1.49 |
| Общее время выполнения теста, секунд | 41.5 | 20.69 | 22.89 |
Таким образом, при достаточном объеме кеша кластер Snowflake Medium из 4 ЕС2 вполне может соревноваться с кластером Vertica из 5 серверов. Причем на сканированиях Snowflake довольно сильно обгоняет Vertica, но с усложнением запросов начинает отставать. К сожалению, не понятно, в какой мере можно рассчитывать на кеш. Монитринг не доступен, посмотреть статистиику использования тоже нельзя. Видно только, сколько данных необходимо было прочитать для выполнения того или иного запроса, но не видно, откуда эти данные были прочитаны, из кеша или из S3. Также нужно учитывать, что при изменении данных таблицы кеш инвалидируется. Впрочем, данные синтетических тестов никогда не стоит использовать для прогнозирования реальной производительности.
На следующем этапе мы попытались воспроизвести процедуру загрузки данных, которую используем в Vertica. Сначала данные из файла загружаются в очень широкую таблицу (около 200 полей), а затем агрегируются с разной степенью детализации и перекладываются в другие таблицы. Тут-то и начали возникать проблемы. Запросы с большим количеством таблиц или столбцов могли компилироваться по несколько минут. Если для выполнения запроса не хватало памяти, никаких сообщений не выводилось, вместо этого просто возвращался неверный результат. Часто сообщения об ошибках были не информативны, особенно трудно было диагностировать несоответствие форматов при загрузке. Мы прекратили тесты, потому что стало ясно, что Snowflake пока не готов к выполнению наших задач.
Заключение
Тестирование продолжалось около месяца. В течение этого времени специалисты из Snowflake оказывали нам поддержку, помогали советами, даже исправили пару багов. Технология интересная, возможность изменять количество ресурсов на лету выглядит очень привлекательной.
Облачное хранилище данных может быть вполне достойным вариантом, если проект новый, и данных пока не так много. Особенно если судьба проекта неизвестна, и не хочется вкладываться в инфраструктуру для хранения и обработки данных. Но планировать перевод всех данных и систем в облако все-таки пока рано.
