Обзор инструкций ARM NEON для тех, кто знаком с MMX/SSE/AVX
Мир изменился. Я чувствую это в воде, чувствую это в земле, ощущаю в воздухе.
«Властелин колец», Джон Рональд Руэл Толкин
Архитектура x86 долгие десятилетия была лидером по высокопроизводительным решениям. И этот факт позволял ей доминировать даже когда количество устройств на архитектуре ARM вокруг нас стало в несколько раз больше. Если вы пишете высокопроизводительный софт для серверов или рабочих станций, до недавнего времени вы могли обходиться лишь знанием x86. Но невозможно игнорировать события, которые могут поменять расклад сил уже совсем скоро. В связи с этим я решил немного поиграться с ARM и нарыл интересных фактов немного больше, чем на тред в твитере.
У меня нет цели рассказать всё с самого начала, я буду заострять внимание лишь на отличиях и интересных моментах, которые мне встретились. Подразумевается, что вы знаете, что такое инструкции процессора, SIMD, читаете ассемблер и Си на базовом уровне.
Мой опыт написания высокопроизводительного кода в основном связан с обработкой изображений в библиотеке Pillow-SIMD. Там я использовал интринсики в коде на Си чтобы добиться 6–8-кратного ускорения наиболее частых операций.
Под что вообще пишем?
Честно говоря, это самый высокий порог для вхождения в ARM архитектуру из тех, что будут. В x86 есть базовый набор команд, есть расширения (разные версии SSE, AVX, криптография или виртуализация) и есть разрядность (32 или 64 бита). В ARM же, загибайте пальцы:
Есть архитектуры, коих более 20. Называются они примерно так: ARMv7-M, ARMv8-R, ARMv8.3-A.
Есть микроархитектура. Например: Cortex-R4, Cortex-A76.
Есть профайл: Classic, Microcontroller, Real-time, Application.
Есть разные наборы команд! A32, A64, Thumb, Thumb2.
Наконец, расширения набора команд: SIMD, NEON, SVE.
Ну и никуда не делась разрядность: AArch32 и AArch64.
Не претендуя на полноту описания, я подсвечу основные моменты и укажу, что сейчас можно опустить. Все архитектуры соответствуют одному из четырех профайлов. Classic — это прям совсем классик, такое вы вряд ли встретите. Из трёх остальных самое ходовое — это Application. Все телефоны, сервера и рабочие станции это Application. Профайл всегда отражён в названии архитектуры в виде постфикса (A, M, R). Актуальных архитектур всего две — ARMv7 и ARMv8, зато у ARMv8 вышло уже 6 минорных версий, которые тоже называются архитектурами (например, ARMv8.2-A). Причём 64-битная разрядность появилась только в ARMv8. Однако ARMv8-A не гарантирует наличие 64-битного режима у процессора, а вот ARMv8.1-A уже гарантирует.
Если знание архитектуры чипа нужно нам, разработчикам софта, чтобы знать, какой минимальный набор функциональности возможно использовать, то микроархитектура уже нужна для разработчиков чипов, чтобы знать, сколько кеша нужно насыпать, сколько вычислительных блоков должно быть и какие опциональные технологи нужно включить в чип. Причем, бывает как микроархитектура от самой компании ARM (она обычно называется Cortex и следом снова постфикс профайла), так и кастомная, которая может называться Apple Firestorm, Neoverse N1 или никак не называться.
Набор команд A32 используется в 32-битном режиме AArch32, а A64 в 64-битном режиме AArch64. И казалось бы, зачем выделять такие очевидные вещи. Но дело в том, что A32 — не единственный набор команд, который может быть в 32-битном режиме. A32 и A64 всегда используют 32 бита для кодирования любой инструкции, а AArch32 вышел очень давно и многим казалось, что это расточительство и тогда появились альтернативные способы кодирования Thumb и Thumb2. В них часто используемые инструкции занимали 16 бит. Для AArch64 уже ничего такого не завезли, в нём любая инструкция занимает 32 бита.
Ну и наконец, расширения набора команд. Вообще, есть ещё расширения VFPv1-VFPv5 для работы с плавающей точкой, разницу между которыми я так и не смог понять. Как и в x86, в ARM плавающую точку завезли не сразу. В ARMv6 было добавлено расширение SIMD (так и называется), а в ARMv7 появился опциональный 128-битный advanced SIMD, он же ASIMD, он же NEON, по сути прямой аналог SSE последних версий. О нём я буду рассказывать больше всего. А вот аналога AVX в ARM нет, там пошли другим путём. Вместо того, чтобы каждые пять лет представлять новое расширение, под которые нужно будет всё переписывать, было разработано расширение Scalable Vector Extension (SVE), которое позволяет выполнять один и тот же код на чипах, реализующих разный размер векторов. Но на практике, как я понял, SVE реализован только в Fugaku supercomputer.
Это же ужас?
Ну, вообще, да, если вы собрались писать приложение, которое может быть выполнено на любом ARM процессоре, как это бывает с x86. Теоретически на нем может не оказаться не только NEON, но даже 64-битной арифметики с плавающей точкой. Вот только, к счастью, у ARM нет того наследия работающих систем, на которых могли бы запустить ваш код. Это в любом случае будет свежий процессор. И ещё, с максимальной вероятностью это всё же будет AArch64 система. А теперь следите за руками.
AArch64 появился только в ARMv8. ARMv8-A уже гарантирует наличие VFPv4 (64-битный FPU), NEON и криптографии. А SVE можно даже не проверять ещё пару лет. У NEON никаких версий нет. Так же остается только один набор инструкций: A64. А микроархитектура просто ни на что не влияет.
Получается, несмотря на огромное количество вариантов, в реальности писать код под ARM (точнее под AArch64) даже проще, чем под x86. Никакие проверки в рантайме не нужны, просто ставите `#ifdef __aarch64__` и пользуетесь всем, чем хотите.
Знакомство с NEON
Принципиальное устройство x86 и ARM мало чем отличаются. И там и там есть общие регистры и регистры для вычислений с плавающей точкой и SIMD. Для общей картины достаточно прочитать раздел General-purpose registers в AArch64 Instruction Set Architecture. И сразу после этого можно переходить к самому полному вводному гайду — Coding for Neon.
Первое, что бросается в глаза — инструкции загрузки и сохранения в память типизированные. И это даже имеет какое-то применение.
LD3 { V0.16B, V1.16B, V2.16B }, [x0]Тут надо уточнить, что сами регистры не типизированны, тип задается только на момент выполнения инструкции.
Очень приятно удивляет кол-во вариантов всяческих сдвигов. Например, есть вариант, когда сдвиг каждого элемента вектора задается в другом векторе.
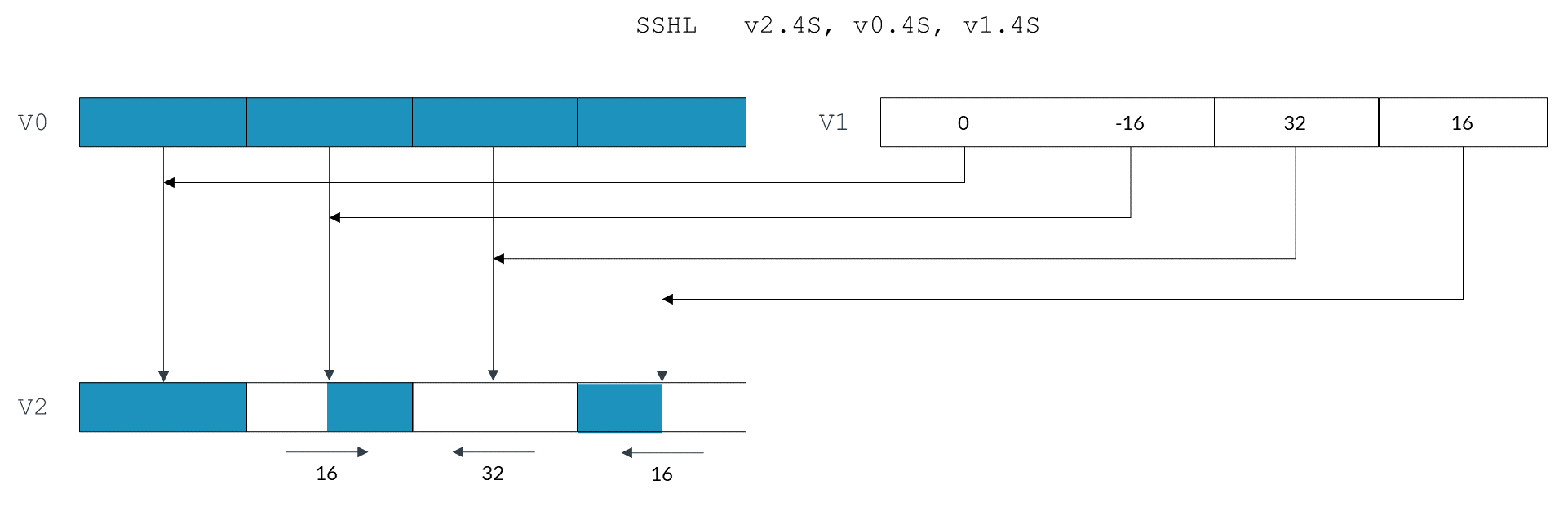
В SSE, например, такого нет. Похожая функциональность появилась только в AVX2 с инструкциями vpsrlv[dq], vpsllv[dq], vpsravd. Но, во-первых, в NEON инструкции сдвигают в обе стороны, в зависимости от знака. Во-вторых, в AVX2 можно сдвинуть только 32-битные и 64-битные значения. На этом вкусности NEON не заканчиваются, из других вариантов сдвига есть:
Сдвиг и сложение с аккумулятором
Сдвиг вправо с округлением
Сдвиг с сатурацией
Сдвиг с уменьшением или увеличением разрядности
Причем некоторые варианты из списка можно комбинировать, и всё это работает с любым типом данных. Поправьте, но вроде SSE ничего из этого не может предложить.
Что касается интринсиков, в отличие от SSE/AVX, где типизированны только регистры для float и double (__m128 и __m128d), в NEON есть типы для всех целых типов и названия придерживаются конвенции stdint.h.
uint8x16_t Sx4 = vld1q_u8(&Srgba[i]);
uint8x16_t Dx4 = vld1q_u8(&Drgba[i]);
uint32x4_t Sax4 = vshrq_n_u32((uint32x4_t) Sx4, 24);
uint32x4_t Dax4 = vshrq_n_u32((uint32x4_t) Dx4, 24);Тут первые две переменны имеют тип »16 беззнаковых int8», вторые — »4 беззнаковых int32». Но, так как это одни и те же регистры, их можно приводить друг к другу. Интересно, что есть типы вроде uint8x16x3_t — это три регистра подряд. В основном такие типы используются для загрузки и сохранения в оперативную память.
Справочник интринсиков
Если вы за последнее десятилетие писали SIMD-код для x86, вы наверняка пользовались Intel Intrinsics Guide. Это прекрасный справочник с интерактивным поиском и фильтром, понятным описанием и псевдокодом для каждой инструкции. И даже есть таблицы задержек и пропускной способности по разным поколениям процессоров Intel.

В нём можно не только искать нужное, но и изучать новое, просто выбирая какое-то поколение инструкций и читая всё подряд.
У ARM аналогом этого гайда служит Neon Intrinsics Reference. И это просто боль и унижение.

Нет никаких фильтров
Поиск работает с перезагрузкой страницы
На странице выводится только 30 функций, снизу есть постраничная навигация, тоже с перезагрузкой страницы
Первый экран занимают бесполезные три абзаца текста, которые нужно каждый раз проматывать. А проматывать приходится очень часто, ведь любой чих — перезагрузка страницы
По запросу «mul» находятся 50 страниц функций! То есть 1500 штук. Знаете, почему в результатах оказалась функция, показанная на скриншоте? Потому что в описании есть слово accumulate!
У каждой инструкции есть много флагов, которые чуть-чуть меняют поведение и почти каждая инструкция работает с несколькими типами данных, которых около 12. И для всего этого создаются отдельные функции. По факту описание и псевдокод написан не для функций, а для инструкции. То есть понять, чем одна функция отличается от другой, почти такой же, оочень сложно.
Вы вообще видели этот псевдокод? Он сам по себе очень избыточен и запутан.
Поэтому, пока я для себя нашел такой вариант: сначала я ищу что-то похожее на то, что мне нужно в алфавитном указателе инструкции с кратким описанием, а уже потом по названию инструкции ищу в справочнике интринсики.
Подходящая задача
Давайте попробуем NEON в деле. В качестве примера кода, на котором можно поэкспериментировать, я выбрал альфа-композитинг с premultiplied alpha. Его можно описать такой формулой:

Алгоритм идеально ложится на SIMD:
#include
#include
#define SHIFTFORDIV255(a)\
((((a) >> 8) + a) >> 8)
#define DIV255(a)\
SHIFTFORDIV255(a + 0x80)
static void
opSourceOver_premul(uint8_t* restrict Rrgba,
const uint8_t* restrict Srgba,
const uint8_t* restrict Drgba, size_t len)
{
size_t i = 0;
for (; i < len*4; i += 4) {
uint8_t Sa = Srgba[i + 3];
Rrgba[i + 0] = DIV255(Srgba[i + 0] * 255 + Drgba[i + 0] * (255 - Sa));
Rrgba[i + 1] = DIV255(Srgba[i + 1] * 255 + Drgba[i + 1] * (255 - Sa));
Rrgba[i + 2] = DIV255(Srgba[i + 2] * 255 + Drgba[i + 2] * (255 - Sa));
Rrgba[i + 3] = DIV255(Srgba[i + 3] * 255 + Drgba[i + 3] * (255 - Sa));
}
} Все операции выполняются над целочисленными значениями. 1 — Sa превращается в 255 - Sa. Так как правую часть мы умножаем на байт, то и левую нужно умножить. А после сложения нужно поделить на 255, это делает макрос DIV255 путём нескольких сдвигов.
Запускать я буду на Raspberry Pi 4, естественно под AArch64. Чем богаты, тем и рады, как говорится. Причем в данном случае мне интересно посмотреть именно пиковую производительность, без влияния памяти. Для этого я буду тестировать на строке длиной 1000 пикселей, то есть всего будет задействовано 12 Кб данных за один вызов функции.
Я буду пользоваться компилятором Clang-9, т.к. он в большинстве случаев выдает более быстрый код, чем GCC. Для начала интересно, как быстро работает чистый код, без векторизации.
$ clang-9 -Wall -O2 -o run.64 main.c -fno-tree-vectorize && ./run.64
Time elapsed: 0.189449
Time elapsed: 0.189280
Time elapsed: 0.189272
Time elapsed: 0.189272Время указано в секундах для 20 тысяч прогонов функции с длиной строк 1000 пикселей. То есть можно сказать, что скорость работы примерно 105 МПх/с. И вообще-то это очень мало, даже для Raspberry Pi. Если включить автоматическую векторизацию, результат будет чуть лучше.
$ clang-9 -Wall -O2 -o run.64 main.c -ftree-vectorize && ./run.64
Time elapsed: 0.082168
Time elapsed: 0.082341
Time elapsed: 0.082135
Time elapsed: 0.082147Ускорение в 2.3 раза существенно, но это не всё, на что можно было бы рассчитывать. Посмотрим, что можно сделать вручную.
NEON-версия
Первое, что нужно сделать, чтобы начать программировать на NEON — подключить заголовочный файл arm_neon.h. Согласитесь, это приятнее, чем каждый раз гуглить ничего не значащие имена заголовочных файлов, вроде smmintrin.h.
1. Загрузка/сохранение. Хотя видно, что код хорошо векторизуется внутри цикла, можно сразу пойти чуть дальше и читать из памяти 128-битный вектор целиком и работать с четырьмя пикселями.
#include
#include
#include
static void
opSourceOver_premul(uint8_t* restrict Rrgba,
const uint8_t* restrict Srgba,
const uint8_t* restrict Drgba, size_t len)
{
size_t i = 0;
for (; i < len*4 - 12; i += 16) {
uint8x16_t Sx4 = vld1q_u8(&Srgba[i]);
uint8x16_t Dx4 = vld1q_u8(&Drgba[i]);
uint8x16_t Rx4 = vaddq_u8(Sx4, Dx4); // Temporary stub
vst1q_u8(&Rrgba[i], Rx4);
}
for (; i < len*4; i += 4) {
uint8_t Sa = Srgba[i + 3];
Rrgba[i + 0] = DIV255(Srgba[i + 0] * 255 + Drgba[i + 0] * (255 - Sa));
Rrgba[i + 1] = DIV255(Srgba[i + 1] * 255 + Drgba[i + 1] * (255 - Sa));
Rrgba[i + 2] = DIV255(Srgba[i + 2] * 255 + Drgba[i + 2] * (255 - Sa));
Rrgba[i + 3] = DIV255(Srgba[i + 3] * 255 + Drgba[i + 3] * (255 - Sa));
}
} Тут пока что Rx4 считается намеренно неправильно. Но зато код запускается и уже можно прикинуть, сколько работает код на NEON, если он ничего не делает:
$ clang-9 -Wall -O2 -o run.64 main.c && ./run.64
Time elapsed: 0.008030
Time elapsed: 0.007872
Time elapsed: 0.007859
Time elapsed: 0.0086298 мс или 2500 МПх/с! Вот мы и ускорили код с помощью NEON в 25 раз.
2. Выделение альфа-канала. Следующая задача — нужно из вектора Sx4 отдельно вытащить все компоненты альфа-канала. Они находятся на 3, 7, 11 и 15 позиции. Причем желательно их сразу размножить на все соседние байты этого же пикселя. Несмотря на множество команд перемешивания байтов, я не нашел ничего специального и сделал через векторный поиск в таблице. Дальше нужно вычесть полученное значение из 255.
uint8x16_t vsubq_u8 (uint8x16_t a, uint8x16_t b);
uint8x16_t vdupq_n_u8 (uint8_t value);
uint8x16_t vqtbl1q_u8 (uint8x16_t t, uint8x16_t idx);
uint8x16_t Sax4 = vsubq_u8(
vdupq_n_u8(255),
vqtbl1q_u8(Sx4, (uint8x16_t){3,3,3,3, 7,7,7,7, 11,11,11,11, 15,15,15,15})
);Интересно, что все компиляторы при оптимизации заменяют операцию вычитания из 255 на побитовое отрицание, что логично.
3. Умножение. Дальше нужно все элементы Sx4 умножить на 255, а элементы Dx4 на соответствующие элементы альфы из Sax4. Все значения 8-битные.
В NEON есть два вида умножения: либо это обычные функции vmulq_*, которые не меняют разрядность и отдают нижнюю часть результата, либо это vmull_* и vmull_high_*, которые делают операцию только над половиной вектора, но зато увеличивают разрядность и отдают результат целиком.
uint16x8_t vmull_u8 (uint8x8_t a, uint8x8_t b);
uint8x8_t vget_low_u8 (uint8x16_t a);
uint8x8_t vdup_n_u8 (uint8_t value);
uint16x8_t vmull_high_u8 (uint8x16_t a, uint8x16_t b);
uint16x8_t Rx2lo = vmull_u8(vget_low_u8(Sx4), vdup_n_u8(255));
uint16x8_t Rx2hi = vmull_high_u8(Sx4, vdupq_n_u8(255));Для умножения Dx4 можно было бы использовать эти же функции, но у них есть ещё одна разновидность, которая тут больше подходит. Это умножение и сложение с аккумулятором. Действительно, нам нужно будет складывать результат умножения, так почему бы не сделать это в одну операцию.
uint16x8_t vmlal_u8 (uint16x8_t a, uint8x8_t b, uint8x8_t c);
uint16x8_t vmlal_high_u8 (uint16x8_t a, uint8x16_t b, uint8x16_t c);
Rx2lo = vmlal_u8(Rx2lo, vget_low_u8(Dx4), vget_low_u8(Sax4));
Rx2hi = vmlal_high_u8(Rx2hi, Dx4, Sax4);4. Деление на 255. Ну что, пришла пора опробовать в деле крутые сдвиги. В Си-версии это происходит так:
#define DIV255(a)\
((((a + 0x80) >> 8) + a + 0x80) >> 8)Первое, что нужно рассмотреть — сдвиги с округлением. Для этого до сдвига прибавляется константа в один бит правее сдвига. По сути это уже сильно упрощает описание деления:
#define ROUND_SHR(a, n)\
((a + (1<<(n-1))) >> n)
#define DIV255(a)\
ROUND_SHR(ROUND_SHR(a, 8) + a, 8)Дальше следует обратить внимание на конструкцию ROUND_SHR(a, 8) + a. Это же сдвиг с аккумулятором vrsraq_n_u16, помните? Ну, а последний сдвиг можно сделать так, чтобы он заодно уменьшал разрядность результата, ведь тот не должен превышать 255. Кроме того, можно уменьшить разрядность не только в нижнюю половину вектора, но и в верхнюю (vqrshrn_high_n_u16).
uint8x16_t vqrshrn_high_n_u16 (uint8x8_t r, uint16x8_t a, const int n);
uint8x8_t vqrshrn_n_u16 (uint16x8_t a, const int n);
uint16x8_t vrsraq_n_u16 (uint16x8_t a, uint16x8_t b, const int n);
uint8x16_t Rx4 = vqrshrn_high_n_u16(
vqrshrn_n_u16(vrsraq_n_u16(Rx2lo, Rx2lo, 8), 8),
vrsraq_n_u16(Rx2hi, Rx2hi, 8), 8);Всё вместе:
static void
opSourceOver_premul(uint8_t* restrict Rrgba,
const uint8_t* restrict Srgba,
const uint8_t* restrict Drgba, size_t len)
{
size_t i = 0;
for (; i < len*4 - 12; i += 16) {
uint8x16_t Sx4 = vld1q_u8(&Srgba[i]);
uint8x16_t Dx4 = vld1q_u8(&Drgba[i]);
uint8x16_t Sax4 = vsubq_u8(
vdupq_n_u8(255),
vqtbl1q_u8(Sx4, (uint8x16_t){3,3,3,3, 7,7,7,7, 11,11,11,11, 15,15,15,15})
);
uint16x8_t Rx2lo = vmull_u8(vget_low_u8(Sx4), vdup_n_u8(255));
uint16x8_t Rx2hi = vmull_high_u8(Sx4, vdupq_n_u8(255));
Rx2lo = vmlal_u8(Rx2lo, vget_low_u8(Dx4), vget_low_u8(Sax4));
Rx2hi = vmlal_high_u8(Rx2hi, Dx4, Sax4);
uint8x16_t Rx4 = vqrshrn_high_n_u16(
vqrshrn_n_u16(vrsraq_n_u16(Rx2lo, Rx2lo, 8), 8),
vrsraq_n_u16(Rx2hi, Rx2hi, 8), 8);
vst1q_u8(&Rrgba[i], Rx4);
}
for (; i < len*4; i += 4) {
uint8_t Sa = Srgba[i + 3];
Rrgba[i + 0] = DIV255(Srgba[i + 0] * 255 + Drgba[i + 0] * (255 - Sa));
Rrgba[i + 1] = DIV255(Srgba[i + 1] * 255 + Drgba[i + 1] * (255 - Sa));
Rrgba[i + 2] = DIV255(Srgba[i + 2] * 255 + Drgba[i + 2] * (255 - Sa));
Rrgba[i + 3] = DIV255(Srgba[i + 3] * 255 + Drgba[i + 3] * (255 - Sa));
}
}Ну и наконец, можно порадоваться результату:
$ clang-9 -Wall -O2 -o run.64 main.c && ./run.64
Time elapsed: 0.047613
Time elapsed: 0.047455
Time elapsed: 0.047452
Time elapsed: 0.047448Это в 1,75 раз быстрее, чем автовекторизованная версия и в 4 раза быстрее, чем версия совсем без векторизации (кстати, для GCC ускорение получается 5,5 раза).
Оптимизация чтения
Полученный результат полностью доказывает жизнеспособность программирования под NEON, однако, от использованной техники (чтение и обработка 4 пикселей, 8 умножений за инструкцию) можно было ожидать больший прирост скорости. Давайте посмотрим, что можно улучшить.
Код выполнялся на процессоре Broadcom BCM2835, который хоть и относительно современный, но супербюджетный. Можно ожидать, что на таком процессоре могут быть существенные задержки даже для доступа к кешу L1. При этом никакие инструкции предвыборки не помогут, т.к. данные уже лежат в самом близком кеше. Зато может помочь предварительное чтение. Для этого нужно на каждом шаге класть «в карман» данные, которые понадобятся на следующем шаге. А из кармана доставать то, что было выбрано на предыдущем.
uint8x16_t Sx4_next = vld1q_u8(&Srgba[0]);
uint8x16_t Dx4_next = vld1q_u8(&Drgba[0]);
// for (; i < len*4 - 12; i += 16) {
for (; i < len*4 - 12 - 16; i += 16) {
// uint8x16_t Sx4 = vld1q_u8(&Srgba[i]);
// uint8x16_t Dx4 = vld1q_u8(&Drgba[i]);
uint8x16_t Sx4 = Sx4_next;
uint8x16_t Dx4 = Dx4_next;
Sx4_next = vld1q_u8(&Srgba[i + 16]);
Dx4_next = vld1q_u8(&Drgba[i + 16]);
...При этом нужно не забыть, что цикл нужно уменьшить на одну итерацию, чтобы не прочитать данные за пределами указателя.
$ clang-9 -Wall -O2 -o run.64 main.c && ./run.64
Time elapsed: 0.038070
Time elapsed: 0.037855
Time elapsed: 0.037834
Time elapsed: 0.037831Гипотеза оказалась верной, это дало прирост ещё 25%. Итого NEON работает ровно в 5 раз быстрее, чем код без векторизации.
Разбор сгенерированного кода
Ну что, пора посмотреть, что напридумывал компилятор.
$ clang-9 -Wall -O2 -o main.s main.c -SЭто вывод уже отформатированный, с некоторыми переименованными регистрами и с комментариями оригинального кода:
ldr q0, [x19] // Sx4 = vld1q_u8(&Srgba[0])
ldr q1, [x20] // Dx4 = vld1q_u8(&Drgba[0])
movi v17.2d, #0xffffffffffffffff
mov x9, xzr
.LBB0_3:
tbl v5.16b, { v0.16b }, v16.16b // vqtbl1q_u8(Sx4, v16)
mvn v5.16b, v5.16b // Sax4 = vsubq_u8(vdupq_n_u8(255), v5)
ext v6.16b, v0.16b, v0.16b, #8
umull v3.8h, v1.8b, v5.8b // Rx2lo = vmull_u8(Dx4, Sax4);
add x10, x19, x9
add x11, x20, x9
umull v4.8h, v6.8b, v17.8b // Rx2hi = vmull_high_u8(Sx4, 0xff)
umlal v3.8h, v0.8b, v17.8b // vmlal_u8(Rx2lo, Sx4, 0xff)
umlal2 v4.8h, v1.16b, v5.16b // vmlal_high_u8(Rx2hi, Dx4, Sax4)
ldr q0, [x10, #16] // Sx4 = vld1q_u8(&Srgba[i + 16])
ldr q1, [x11, #16] // Dx4 = vld1q_u8(&Drgba[i + 16])
ursra v3.8h, v3.8h, #8 // vrsraq_n_u16(Rx2lo, Rx2lo, 8)
ursra v4.8h, v4.8h, #8 // vrsraq_n_u16(Rx2hi, Rx2hi, 8)
uqrshrn v2.8b, v3.8h, #8 // Rx4 = vqrshrn_n_u16(Rx2lo, 8)
add x10, x9, #16
uqrshrn2 v2.16b, v4.8h, #8 // vqrshrn_high_n_u16(Rx4, Rx2hi, 8)
cmp x10, #3972
str q2, [x21, x9] // vst1q_u8(&Rrgba[i], Rx4)
mov x9, x10
b.lo .LBB0_3Хочу напомнить, что q0 и v0 — это разные названия одного регистра. Первое, что стоит отметить — компилятор верно понял задумку с упреждающим чтением и, несмотря на то, что в коде мы использовали копирование из старых переменных в новые, в выводе ничего такого нет. Чтение происходит сразу после того, как данные регистров v0 и v1 больше не используются. Хоть из-за этого загрузка и сместилась с начала итерации в середину, тут стоит положиться на компилятор, т.к. скорее всего он решил так сделать основываясь на латентности операций чтения.
Далее стоит обратить внимание на последовательности umull и umlal. Тут произошло странное, зачем-то компилятор заменил umull2 на ещё один umull. Для этого ему понадобилось в строчке №8 сделать лишнее извлечение верхней части v0 во временный регистр v6. Формально мы использовали функцию vget_low_u8, которая это и подразумевает. Однако это было сделано только для того, чтобы привести переменную к нужному типу. Если посмотреть, что генерируют компиляторы для такого кода, то видно, что они не очень понимают, что нижняя часть регистра — это и есть сам регистр. Ну, а GCC вообще творит какую-то дичь: создает два разных регистра с константами, делает три копирования.
На этом странности не заканчиваются. Для Rx2lo переставлены местами vmull_u8 и vmlal_u8. Формально это ни на что не влияет, но все равно не понятно, зачем.
Ну и последнее, на что можно обратить внимание — это странная работа с индексами. Если для команды str q2, [x21, x9] в качестве смещения используется регистр, то для ldr смещение вычисляется заранее, причем два раза, хотя очевидно, что можно было вычислить x9 + 16 и использовать это значение в обеих загрузках.
Пробуем всё это исправить:
ldr q0, [x19] // Sx4 = vld1q_u8(&Srgba[0])
ldr q1, [x20] // Dx4 = vld1q_u8(&Drgba[0])
movi v17.2d, #0xffffffffffffffff
mov x9, xzr // i = 0
.LBB0_3:
tbl v5.16b, { v0.16b }, v16.16b // vqtbl1q_u8(Sx4, v16)
mvn v5.16b, v5.16b // Sax4 = vsubq_u8(vdupq_n_u8(255), v5)
add x10, x9, #16 // x10 = i + 16
umull v3.8h, v0.8b, v17.8b // Rx2lo = vmull_u8(Sx4, 0xff);
umull2 v4.8h, v0.16b, v17.16b // Rx2hi = vmull_high_u8(Sx4, 0xff)
ldr q0, [x19, x10] // Sx4 = vld1q_u8(&Srgba[i + 16])
umlal v3.8h, v1.8b, v5.8b // vmlal_u8(Rx2lo, Dx4, Sax4)
umlal2 v4.8h, v1.16b, v5.16b // vmlal_high_u8(Rx2hi, Dx4, Sax4)
ldr q1, [x20, x10] // Dx4 = vld1q_u8(&Drgba[i + 16])
ursra v3.8h, v3.8h, #8 // vrsraq_n_u16(Rx2lo, Rx2lo, 8)
ursra v4.8h, v4.8h, #8 // vrsraq_n_u16(Rx2hi, Rx2hi, 8)
uqrshrn v2.8b, v3.8h, #8 // Rx4 = vqrshrn_n_u16(Rx2lo, 8)
uqrshrn2 v2.16b, v4.8h, #8 // vqrshrn_high_n_u16(Rx4, Rx2hi, 8)
cmp x10, #3972
str q2, [x21, x9] // vst1q_u8(&Rrgba[i], Rx4)
mov x9, x10
b.lo .LBB0_3Запускаем:
$ clang-9 -Wall -O2 -o main.o -c main.s && gcc ./main.o -o run.64 && ./run.64
Time elapsed: 0.033388
Time elapsed: 0.033204
Time elapsed: 0.033223
Time elapsed: 0.033190Есть ещё 14% прироста. Итого ускорение 5,7 раз.
Было бы интересно также посчитать, сколько тактов уходит на этот цикл. Имеем 1800МГц (тактов/с), 0.033190 с/запуск и 250×20 * 1000 циклов/запуск. Итого: 1800000000×0.033190 / (250×20 * 1000) ≈ 12 тактов/цикл. Учитывая, что в цикле 17 инструкций, это прекрасный результат. Я не думал, что такой простой процессор может работать так эффективно.
Решение на SSE
Думаю, будет нелишним решить ту же задачу на SSE и сравнить усилия. Загрузка и выгрузка данных ничем не отличается. Дальше нужно размножить альфа-канал пикселей-источников на все остальные каналы. Тут можно сделать полностью аналогично NEON-версии.
__m128i Sax4 = _mm_sub_epi8(
_mm_set1_epi8((char) 255),
_mm_shuffle_epi8(Sx4, _mm_set_epi8(
15,15,15,15, 11,11,11,11, 7,7,7,7, 3,3,3,3)));Существенное отличие только в том, что порядок байтов у _mm_set_epi8 инвертирован.
Дальше нужно 8-битное умножение. В SSE есть такое, это интринсик _mm_maddubs_epi16. И кстати, он же увеличивает разрядность результата и даже делает сложение соседних элементов. Можно было бы подумать, что дело в шляпе.
// Это неправильный код!
__m128i Rx2lo = _mm_maddubs_epi16(
_mm_unpacklo_epi8(_mm_set1_epi8((char) 255), Sax4),
_mm_unpacklo_epi8(Sx4, Dx4));
__m128i Rx2hi = _mm_maddubs_epi16(
_mm_unpackhi_epi8(_mm_set1_epi8((char) 255), Sax4),
_mm_unpackhi_epi8(Sx4, Dx4));Количество инструкций умножения уменьшилось вдвое по сравнению с NEON-версией. Но, к сожалению, _mm_maddubs_epi16 принимает только первый 8-битный аргумент как целое без знака, а второй аргумент считается со знаком, поэтому результат будет неверным. Функции, в которой оба аргумента были бы без знака, нет. А значит, нужно использовать 16-битное умножение и распаковывать каждый аргумент с пустым регистром, что существенно увеличивает и запутывает код.
__m128i Rx2lo = _mm_add_epi16(
_mm_mullo_epi16(_mm_unpacklo_epi8(Sx4, _mm_setzero_si128()),
_mm_set1_epi16(255)),
_mm_mullo_epi16(_mm_unpacklo_epi8(Dx4, _mm_setzero_si128()),
_mm_unpacklo_epi8(Sax4, _mm_setzero_si128())));
__m128i Rx2hi = _mm_add_epi16(
_mm_mullo_epi16(_mm_unpackhi_epi8(Sx4, _mm_setzero_si128()),
_mm_set1_epi16(255)),
_mm_mullo_epi16(_mm_unpackhi_epi8(Dx4, _mm_setzero_si128()),
_mm_unpackhi_epi8(Sax4, _mm_setzero_si128())));Деление на 255 и запаковку приходится делать, описывая каждый шаг, SSE никак не помогает.
Rx2lo = _mm_add_epi16(Rx2lo, _mm_set1_epi16(0x80));
Rx2lo = _mm_srli_epi16(_mm_add_epi16(_mm_srli_epi16(Rx2lo, 8), Rx2lo), 8);
Rx2hi = _mm_add_epi16(Rx2hi, _mm_set1_epi16(0x80));
Rx2hi = _mm_srli_epi16(_mm_add_epi16(_mm_srli_epi16(Rx2hi, 8), Rx2hi), 8);
__m128i Rx4 = _mm_packus_epi16(Rx2lo, Rx2hi);За вычетом загрузок/сохранений, констант и приведений типов, я насчитал 23 интринсика в SSE версии против 10 в NEON. Предложения по улучшению преветствуются.
Моё впечатление
NEON произвел впечатление очень продуманной и эффективной системы команд. Я нашел для себя такие плюсы:
В отличие от SSE, есть консистентность типов данных, с которыми работают разные инструкции.
Порадовало большое количество опций сдвигов, которые оказались полезными на практике.
Можно встраивать NEON-код в любое место приложения без проверок рантайм.
Использование NEON дает ощутимый прирост производительности, примерно равный такому от использования SSE.
Очень понятный ассемблер с типизированными аргументами.
Были опасения, что будет сильно не хватать инструкции
_mm_madd_epi16, делающей 8 умножений и 4 сложения. Однако её функциональность покрывается паройvmull_*/vmlal_*, не требующих подготовки данных.
Минусы я бы отметил следующие:
Абсолютно неюзабельный справочник интринсиков. Это не минус самого NEON, но это то, с чем придется столкнуться.
Производительность сильно зависит от компилятора, возможно придется залочиться на clang.
Имена некоторых интринсиков напоминают читы в играх:
vqrshrn_n_u16,vqdmulh_s16
Бенчмарки
Я собрал все варианты из этой статьи в один репозиторий с make-файлом, чтобы быстро запускать на разных системах или с разным окружением. Помимо Raspberry Pi 4 я смог запустить код ещё на c6g.large инстансе в AWS, которые работают на процессорах AWS Graviton2. Вот что я намерил:
Raspberry Pi 4 |
| |||
GCC 8.3.0 | Clang 9.0.1 | GCC 9.3.0 | Clang 9.0.1 | |
Без векторизации | 267,4 мс | 185,6 мс | 140,2 мс | 103,8 мс |
Авто векторизация | 116,8 | 82,55 | 140,2 | 46,54 |
Ручная векторизация | 46,36 | 47,56 | 22,85 | 17,59 |
Оптимизация чтения | 46 | 36,8 | 24,01 | 16,86 |
Ассемблер | 33,66 мс | 14 мс |
Коэффициентами я обозначил замедление относительно варианта на ассемблере. Таблица получилась очень интересная. Выводов можно сделать много:
Поведение очень сильно зависит от компилятора. Протестированные версии GCC практически везде медленнее Clang.
Автоматическая векторизация в целом работает, но не дает такого же эффекта, как ручная.
Автоматическая векторизация может внезапно не заработать, причем даже на более свежей версии компилятора. При этом функция была выбрана предельно простая для векторизации.
GCC также не оценил оптимизацию чтения. Я не смотрел код, но выглядит так, будто он её просто выкинул.
На более мощных чипах любая векторизация дает более существенный выигрыш. При этом оптимизация чтения для них уже не так критична.
Пока что компиляторы не умеют полностью раскрывать возможности ARM, даже при использовании интринсиков.
Кроме этого я все же решил измерить неизмеримое и сравнить несравнимое. Запустил тесты для ARM на Apple M1, а для x86 на Intel® Xeon. Выбор M1 понятен — кроме него пока нет десктопных процессоров от Apple. А вот на чем запускать x86 было вопросом. На ноутбуке у меня процессор может работать в диапазоне от 2,4 до 4,1 Ггц при разных сценариях. Поэтому я решил запустить на серверном процессоре, у которого стабильная частота.
Ещё момент, в результатах на M1 был сильнейший разброс, вплоть до двух раз. Я запускал не у себя и у меня не было возможности проверить, почему так выходит. Моё предположение, что какое-то время работали слабые ядра. В любом случае, я брал минимальное время.
Apple M1 |
| ||
Clang 12.0.0 | GCC 9.3.0 | Clang 9.0.1 | |
Без векторизации | 43,13 мс | 74,56 мс | 80,26 мс |
Авто векторизация | 16,71 | 74,54 | 80,28 |
Ручная 128-битная векторизация | 9,09 | 14,65 | 13,03 |
Ручная 256-битная векторизация | 7,76 | 6,52 |
Коэффициентами я обозначил замедление относительно ручной 128-битной векторизации. Хочется напомнить, что это далеко не всеобъемлющий бенчмарк и по его результатам нельзя делать выводы о производительности всей платформы. Тем не менее.
Скорость M1 без векторизации впечатляет. Это при том, что частота обоих чипов примерно одинаковая.
Упс, авто векторизация на x86 не сработала на обоих компиляторах. А случай всё ещё простейший.
Несмотря на огромное количество кода в цикле (напомню, 23 инструкции против 10), x86 заметно сильнее ускоряется от векторизации. Это можно объяснить большим количеством исполнительных блоков для целочисленных вычислений внутри каждого ядра или более оптимальным микрокодом.
Хоть 128-битная версия на M1 всё еще выполняется быстрее, чем на x86, против AVX ему нечего противопоставить.
На этом всё. Если нашли какие-то неточности, или знаете ещё что-то интересное о NEON и архитектуре ARM, делитесь в комментариях, обсудим вместе.
