Обучение с подкреплением: как работают новые возможности библиотеки SberPM
Что такое Process Mining и как его применять, мы рассказывали в первом посте. Во второй части мы представили краткое руководство пользования библиотекой для интеллектуального анализа процессов SberPM. В данной статье мы подробнее раскроем функционал библиотеки и расскажем о новом модуле оптимизации процессов и клиентских путей, использующем обучение с подкреплением для поиска оптимального пути.
Оптимизация бизнес-процессов играет важнейшую роль в повышении операционной эффективности компании. В SberPM обучение с подкреплением используется для реконструкции процесса в соответствии с заданными критериями:
Отсутствие зацикленности.
Минимальное время выполнения этапов.
Минимальное число этапов.
Успешное завершение процесса.
Когда применять?
Анализ процесса, где слишком много этапов. Процессы с сотнями и тысячами этапов сложны для анализа и практически непригодны для наглядного отображения.
Есть редко используемые пути. Не все пути в процессе используются равномерно. С помощью RL можно определить и отсеять неоптимальные пути.
Нужен редизайн процесса. Еще один кейс — понять, как улучшить процесс для редизайна.
Необходимо сформировать клиентский путь. Узнать, как быстро и безболезненно «провести» клиента до успешного завершения процесса.
Таким образом, одной из ключевых областей применения данного модуля нам видится аналитика пути клиента. С помощью RL можно не только понять потребности клиента, но и оптимизировать его путь посредством увеличения скорости и конверсии.
Немного теории
Сперва поговорим о том, что такое обучение с подкреплением, или Reinforcement Learning, и чем оно отличается от других разделов Machine Learning.
Все алгоритмы машинного обучения упрощенно можно разделить на 3 большие группы:
Supervised Learning, или обучение с учителем. Модель обучается на заранее размеченных данных c правильными и неправильными ответами. К таким алгоритмам относятся различные классификаторы и регрессоры, на этом же принципе функционируют нейронные сети, решающие задачи сегментации, детекции и т.д.
Unsupervised Learning, или обучение без учителя. Здесь нет разметки, поэтому используются различные закономерности в структуре данных, их размещение в пространстве и другие характеристики. В эту группу входят всевозможные кластеризаторы, алгоритмы понижения размерности, эмбеддеры и так далее.
Reinforcement Learning. Его ключевое отличие состоит в том, что модель учится решать задачу методом проб и ошибок, то есть наиболее приближенно к тому, как мы с вами учимся чему-либо в реальной жизни.
Рассмотрим подробнее, каким образом это происходит. Обычно в обучении с подкреплением выделяют два абстрактных объекта — среда (environment) и агент (agent). Агент взаимодействует со средой, получая от нее фидбэк в виде наград. В процессе обучения агент стремится совершать действия, которые максимизируют получаемые им награды.
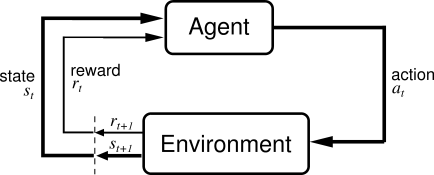
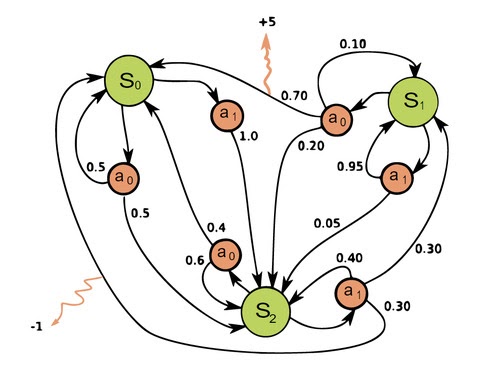
Для лучшего понимания того, что происходит в RL, также необходимо ознакомиться с Markov Decision Process (MDP). МDP позволяет математически корректно сформулировать любую проблему, возникающую в обучении с подкреплением.
Markov Decision Process — это набор пар (кортеж) (S, A, P, R,
