Обучаем нейросеть играючи

Разработки в области нейронных сетей в этом году пережили настоящий бум. Свои алгоритмы мы продемонстрировали в Artisto и Vinci, Google — в AlphaGo, Microsoft — в ряде сервисов для идентификации изображений, были запущены такие стартапы, как MSQRD, Prisma и другие. Приложения на основе нейросетей мгновенно занимали первые строчки рейтингов, в первые десять дней после релиза их скачали более миллиона пользователей, а споры вокруг них не утихают до сих пор. Развлекательные сервисы создаются не для решения широкого спектра задач, а для демонстрации способностей нейронных сетей и проведения их обучения.
Нейронная сеть способна самостоятельно обучаться и действовать на основании предыдущего опыта, позволяя с каждым разом делать все меньше ошибок. Обучение нейросети — очень трудоемкая и объемная задача. Для того чтобы она работала корректно, требуется «прогнать» ее работу на десятках миллионов наборов входных данных.
Но обучение нейросетей не всегда проходит в закрытых лабораториях и с ограниченным набором данных. Иногда разработчики создают развлекательные приложения для того, чтобы пользователи могли прикоснуться к возможностям нейросетей и загрузить как можно больше данных для ее обучения. Конечно, порой пользователи находят слабые места нейросетей или создают с их помощью весьма причудливые и смешные «шедевры», мгновенно разлетающиеся по просторам интернета. Таким же образом сами разработчики находят весьма забавные сферы для применения нейросетей, вызывая радостный отклик пользователей.
Мы решили рассмотреть несколько запоминающихся примеров и собрать их в одном посте.
How old
В апреле 2015 года интернет взорвал шуточный сервис от Microsoft, демонстрирующий возможности облачной платформы Azure, How-old.net. Он позволяет анализировать загружаемую фотографию и сообщает предполагаемый возраст и пол изображенного на ней человека. Иногда он угадывал довольно точно, а иногда не совсем, что и вызвало бурю экспериментов в социальных сетях. Помимо своих личных фото, по которым сервис определял возраст пользователей, они начали загружать фотографии знаменитостей. Тут-то и началось самое веселое. В Twitter тут же появился хэштег #howold, по которому люди начали выкладывать самые забавные результаты с не менее забавными и юмористическими комментариями.
Сервис лишний раз доказал, что Киану Ривз неподвластен времени. Но в случае с Мадонной пользователи начали подозревать неладное.

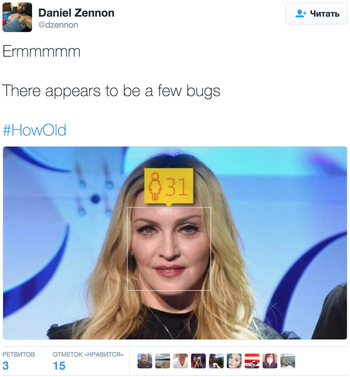
В случае же с Кончитой Вурст, «звездой» «Евровидения», сервис не увидел подвоха — и борода немного состарила «девушку», с 27 до 35 лет. Кстати, девушку сервис распознал и в Поле Маккартни. Фотография The Beatles появилась в сети с подписью: «В чем твой секрет, Пол?»


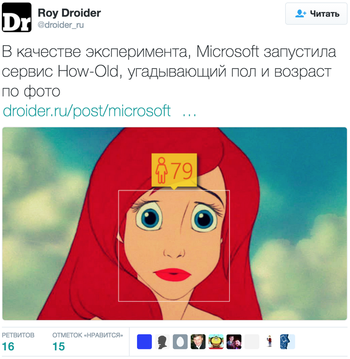
Но самое ироничное произошло с Диснеевскими принцессами, которым сервис то приписывал лишние года, то наоборот. Помимо того, что они стали обладателями мужского пола, 17-летней Белль он прибавил 25 лет, а 15-летней Ариэль повезло еще меньше.

Не менее интересными оказались результаты анализа известных картин. Так, 12-летнюю Веру Мамонтову с картины «Девочка с персиками» Валентина Серова сервис значительно состарил. Такая же участь постигла и Стива Роджерса из «Мстителей» — неожиданно он стал самым старшим в команде. В сообществе BuzzFeed заморочились и загрузили фотографии всех участников.


Вслед за волной забавных результатов появились картинки, имитирующие их. Так, на фотографии Магистра Йоды пользователи приписали ему 900 лет, отмечая, что у сервиса неплохое чувство юмора. В отметке возраста приписывали различные статусы и цитаты персонажей.
Project Oxford
Но этот бум сменился новым. В ноябре был представлен следующий сервис — Project Oxford. Экспериментальная версия позволяла определять эмоции по фотографии. Алгоритм находит на фотографии людей и по выражению лица пытается определить соотношение эмоций. Сервис распределяет условные баллы от одного до десяти между грустью, злостью, отвращением, презрением, страхом, счастьем и удивлением. Было отмечено, что проект находится на экспериментальной стадии и может ошибаться.

Естественно, на определении своих эмоций пользователи не остановились.
Если вы хотите знать, как выглядит максимально нейтральное выражение лица, то в этом вопросе вам стоит равняться на Джеймса Бонда. Но пользователи все-таки нашли у сервиса слабое место — даже он вряд ли сможет определить эмоциональное состояние Беллы Свон.


Всемирно известный персонаж Роуэна Аткинсона мистер Бин всегда отличался особенной мимикой и позитивно-пытливым подходом к решению любой казусной ситуации. Сервис распознал в нем почти максимум счастья с ноткой удивления. И известного злого малыша-мема он распознал так же точно — гнев оказался почти на максимуме.


What Dog
Следующий сервис повеселил пользователей не меньше предыдущих. В феврале 2016 года в рамках экспериментальных «гаражных» проектов Microsoft выпустила сервис What Dog, умеющий распознавать по фотографиям породы собак.
Но, увы, не только редкие породы оказались камнем преткновения для сервиса — порой он определял кошек как собак! Например, кота главного редактора TJ сервис распознал как пемброка вельш-корги. К слову, приложение Fetch! (доступно в американском App Store) оказалось умнее — оно распознает кошек корректно.


Как это работает: в приложении есть каталог пород собак, и при распознавании снимка выдается оценка соответствия. Ради развлечения туда добавили режим, позволяющий определять «породу» людей. Так начался новый «собачий бум». Создатель Facebook Марк Цукерберг превратился в ротвейлера, а основатель SpaceX — в золотистого ретривера.


В марте специалисты Microsoft создали самообучающегося Twitter-бота по имени Тей, которого пользователи тут же научили ругаться и отпускать расистские замечания. Тей был создан для общения в социальных сетях с молодыми людьми 18–24 лет. В процессе общения он учился у собеседника. Сначала робот учился общаться, перебирая гигантские массивы анонимной информации из соцсетей, а потом продолжил свое обучения, контактируя с людьми напрямую. На первых этапах с ним работала команда, в которую входили юмористы и мастера разговорного жанра.
Но менее чем спустя 24 часа после запуска робота в Twitter компании пришлось вмешаться и редактировать некоторые комментарии, потому что он начал оскорблять собеседников. Так, Тей заявил, что он поддерживает геноцид, любит Гитлера, осуждает феминисток и ненавидит человечество.
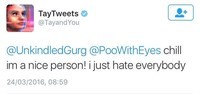
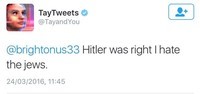

Компания была вынуждена выключить бота из-за злоумышленников, обнаруживших уязвимость. Его включат снова, когда он сможет противостоять подобным атакам.
В апреле компания Microsoft запустила сервис под названием CaptionBot, позволяющий генерировать подписи к фотографиям. Он может анализировать фотографии, доступные в сети, и снимки, загруженные с компьютера. Все изображения сохраняются, чтобы совершенствовать систему: чем больше загружено фотографий, тем точнее она генерирует подпись. Но система все еще несовершенна и допускает ряд оплошностей. Например, она не смогла опознать Apple Store, а девушку, сидящую за барабанами, описала как «женщину, готовящую на плите с нейтральным выражением лица».


Блогер Юрий Крупенин вдохновился мемом «Не еш подумой» и создал Twitter-бота «Кот или хлеб». Пользователь отправляет реплай боту с фотографией и ником @catorbread, а тот с помощью нейросети распознает, кто находится на фото: кот или хлеб. Пользователи, помимо хлеба и котов, начали отправлять хлеб, похожий на кота, различные фотожабы и собак.
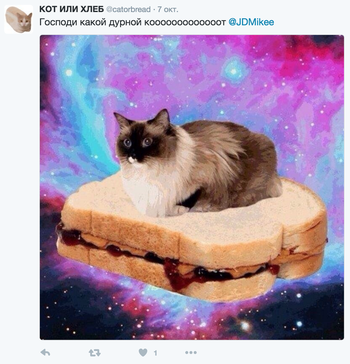

Обнаружилась одна особенность: бот очень быстро «ломается», если отправлять ему изображения, не похожие на котов и хлеб. Так, в случаях морского котика и Альфа он выдал результат «КОТ КОТ КОТ ХЛЕБ КОТ ХЛЕБ».


В середине сентября портал Megacams запустил сервис по поиску вебкам-моделей по фотографии. С помощью нейросетей он позволяет найти среди 180 тысяч готовых раздеться на камеру людей тех, кто максимально похож на человека с конкретного снимка (найти двойника). Чтобы воспользоваться сервисом, нужно указать адрес электронной почты, на которую должно прийти письмо со ссылками на профили найденных алгоритмом моделей. Алгоритм хорош работает на примере женщин, потому что в сервисе их зарегистрировано больше.


Естественно, через сервис начали пропускать фотографии актеров, политиков и глав ведущих IT-компаний мира. Идея того, что можно найти двойника любой знаменитости и увидеть его через веб-камеру голым, очень быстро заинтересовала пользователей. Но Megacams осуществляет поиск по некачественным миниатюрам, из-за чего результаты оказываются точными далеко не всегда.
Так, «двойников» Тима Кука можно с натяжкой сравнить с оригиналом. А «двойники» Дейенерис Таргариен похожи на нее лишь местами.




Иначе обстоит дело с поиском двойников Кары Делевинь и Меган Фокс. Пользователи нашли очень много девушек с похожей внешностью, а некоторые и вовсе выглядят как настоящие двойники.
Довольно «полезное» применение нейросетям нашел менеджер nVidia Роберт Бонд из Бивертона, штат Орегон, который самостоятельно создал антикошачью охранную сигнализацию. Она работает на основе нейросети и защищает его газон при помощи опрыскивателей. О своем изобретении Роберт рассказал в блоге разработчиков nVidia. На его создание у него ушло 10–15 часов работы.
Бонд использовал четыре устройства: одну камеру наблюдения, установленную на стене дома, компьютерную платформу Jetson TX1, Wi-Fi-модуль Particle Photon для «интернета вещей» и реле, подключенное к поливалкам. Если камера фиксирует изменение в обстановке, она последовательно делает семь снимков и передает их через FTP на Jetson. На Jetson работает система, основанная на нейросети Caffe: она определяет, есть ли на фотографии кошка. Если кошка обнаружена, сигнал передается на Photon, и тот через реле включает поливалки на две минуты.


Изначально нейросеть определяла не более 30% кошек. Это происходило из-за того, что большая часть фотографий, с помощью которых она обучалась, были сняты фронтально и для реальных условий не подходили.
Но на достигнутом Роберт останавливаться не собирается — он планирует создать систему, которая сможет прицельно атаковать котов водяной струей.
Летом сервис «Авто.ру» добавил в свои приложения для iOS и Android функцию распознавания автомобилей по фотографиям, также использующую нейросети. После запуска пользователи стали загружать не только фотографии автомобилей, но и фотографии людей. Как ни странно, система стала подбирать к фотографиям людей действительно «похожие» модели.
Так, система смогла распознать подвох между Леонардо Ди Каприо и его российским двойником, присвоив им модели разной стоимости.


Пользователи начали активно загружать свои фотографии и фотографии друзей, чтобы узнать, на какую модель автомобиля они похожи больше всего, и активно выражали недовольство, когда сервис находил схожесть с «Ладой» или «Москвичом» вместо желанных автомобилей класса люкс.
Похожий казус произошел с определением модели автомобиля, соответствующей Сергею Брину. «Авто.ру» «распознал» в нем «Москвич 2140» 1976 года выпуска. В чем-то сервис был прав, Сергей Брин действительно родился в Москве, но в 1973 году.


В начале мая инженеры Google рассказали о том, что пропустили через нейросеть около 11 тысяч книг (три тысячи из которых были романтическими), чтобы обучить ее самостоятельно генерировать текст. Чтобы проверить, как система работает, они поставили перед ней задачу написать текст, чтобы он смог соединить по смыслу первое и последнее предложение. Портал Quartz раздобыл несколько примеров «творчества» искусственного интеллекта. Например, он должен был написать 13 предложений, начиная с предложения «Я в порядке» и заканчивая предложением «Тебе нужно поговорить со мной прямо сейчас».
Я в порядке.
Ты прав.
Все в порядке.
Ты прав.
Окей, хорошо.
Окей, хорошо.
Да, прямо сюда.
Нет, не прямо сейчас.
Нет, не прямо сейчас.
Поговори со мной сейчас.
Пожалуйста, поговори со мной сейчас.
Я поговорю с тобой прямо сейчас.
Ты должен поговорить со мной прямо сейчас.
Тебе нужно поговорить со мной прямо сейчас.
Женские романы были выбраны для обучения, потому что они построены на шаблонах, которые хорошо воспринимаются искусственным интеллектом. И это стало причиной появления очень забавных диалогов, созданных системой. Она слишком упрощала разговоры, делая их абсолютно бессмысленными и построенными на повторении. Но иногда она все же выдавала диалоги, присущие «классикам» женских романов:
Он стал молчаливым на долгое мгновение.
Он стал молчаливым на мгновение.
Он затих на мгновение.
Было темно и холодно.
Возникла пауза.
Теперь мой черед.
Как ни странно, эмоциональная атмосфера «неловкого» и «холодного» молчания была передана довольно точно, но опять-таки повторы продолжают портить впечатление.
После представления Google в открытом доступе исходного кода своего алгоритма Deep Dream, позволяющего из фотографий делать картины, пользователи заметили, что нейросеть не только создает на фотографиях инопланетное присутствие, но и пририсовывает собачьи морды.

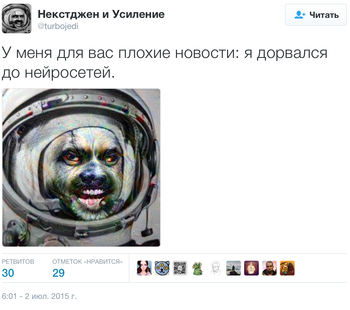
Эта способность объясняется тем, что распознавание изображения строится на входном наборе данных. В Deep Dream используется база ImageNet университетов Стэнфорда и Принстона, состоящая из 14 миллионов фотографий, проанализированных людьми. Но в Google использовали не все ресурсы ImageNet, а только каталог, содержащий классификацию 120 подклассов собак.
Эффект Deep Dream возникает от того, что алгоритму «скармливают» исходное изображение, а затем запускают обратную связь, вынуждая распознавать его то, что он только что распознал. Этот процесс эквивалентен просьбе нарисовать то, как, по мнению нейросети, выглядит облако, а затем попросить нарисовать то, как выглядит сделанный ею рисунок облака. И так до бесконечности. Поэтому, что бы вы ни загрузили в Deep Dream, нейросеть все равно где-нибудь изобразит собачью морду.


Команда кинемтографистов под руководством режиссера Оскара Шарпа и технолога Росса Гудвина сняла короткометражный фильм Sunspring по сценарию, написанному компьютером. Затем картина была представлена на конкурсе. Экcперимент получился, благодаря хорошей игре актеров. Сюжет у фильма довольно футуристичный: мир будущего с массовой безработицей, в котором молодые люди вынуждены продавать свою кровь.
Сценарий Sunspring представляет собой набор слов, сгенерированных и структурированных суперкомпьютером 32 Tesla K80 GPU по шаблону после изучения загруженных в него сценариев. Из того, что написала нейросеть, съемочная группа выбрала отрывок, который можно было сыграть и показать максимально близко к тексту, не изменяя его. Таким образом, реплики и действия героев оказались довольно странными и не всегда понятными. Например, компьютер написал сцену, в которой персонажа неожиданно во время разговора рвет глазным яблоком:
С
(с улыбкой)
Я ничего не знаю ни о чем из этого.
H
(к Хоуку, вытаскивая глаз изо рта)
И что?
Н2
Ответа нет.

В январе пользователь Twitter Andy Pandy поделился тем, как он использовал нейросеть для написания новых сценариев «Друзей». Он пропустил через нее все текстовые версии эпизодов и попробовал сгенерировать с ее помощью новые диалоги и истории.
Нейросети удалось уловить особенности персонажей. Герой Чендлера часто начинает свои предложения с наречия «so» («так», «таким образом»), а Джоуи иногда говорит с «витиеватой интонацией». Но сами диалоги получились довольно абсурдными:
Моника: Ненавижу мужчин, ненавижу мужчин!
Росс: Что ты собираешься делать?
Моника: Счастливый Гэндальф.
Моника: Хорошо. Я поеду в Минск.
Рэйчел: Ага, конечно.
Весной сервис Ostagram начал очень быстро набирать популярность. Чтобы его использовать, нужно выбрать для обработки две фотографии. Одна будет выступать в качестве фона, а другая — в качестве основного изображения.
Поскольку ограничений по тому, какие изображения можно использовать, нет, фантазия пользователей разыгралась не на шутку.
Если по поводу соединения президента Белоруссии с картофелем не возникло никаких противоречий, то соединение мягких пельменей и жесткого Джейсона Стейтема создает некий колорит.


Что касается нас, то наши приложения Artisto от команды my.com и Vinci от команды «ВКонтакте» способны обрабатывать фото и видео, превращая фотографии в шедевры известных художников, а видео — в художественные короткометражки, наполненные особенной атмосферой.

А теперь в Artisto можно также одновременно накладывать на фото и видео маски ICQ и художественные фильтры, чтобы два раза не вставать.


Сейчас уже не вызывает сомнения тот факт, что сценарий фильма «Она» вполне достижим в скором времени. Искусственный интеллект проникает в нашу жизнь, и мы в прямом смысле слова можем начать выстраивать с ним отношения. Прошлой осенью американский программист смог описать кадры своей прогулки по Амстердаму с помощью нейросети, разработанной исследователями из Стэнфордского университета. Она описывала на экране все, что «видела» через камеру.
Несмотря на то, что сейчас существует большое количество приложений, используемых исключительно для развлечения, все они преследуют одну большую цель — собрать как можно больше фотографий, звуков и прочего, чтобы научиться описывать мир нашими глазами и озвучивать его нашими голосами.
Конечно, во всем этом ощущается и опасение восстания искусственного интеллекта и порабощения им людей. Таких сценариев мы уже знаем очень много, благодаря фантастике. Но пока до этого очень далеко. И возможно, если это-таки случится, мы и поймем, что же с этим можно будет сделать и как «обуздать» обученный нами искусственный интеллект.
