Облачная кухня: рецепт приготовления тестов производительности дисковой подсистемы сервера
Хабр, приветствую! Сегодня с вами Дмитрий Михайлов, ИТ-инженер Cloud4Y, и в этой статье я поделюсь с вами опытом проверки производительности виртуальных дисков. Расскажу и покажу, что тут и как, а пощупать всё вживую вы сможете, взяв данные из папки, которую я положил в Nextcloud.
Зачем проверять?
Во-первых, это одна из частых тем обращений в техподдержку. Иногда причина лежит на поверхности: некоторые клиенты запускают что-нибудь из серии CrystalMark и присылают скриншоты замеров, сопровождая их своей интерпретацией. Иные обращаются с общей жалобой на недостаточную производительность ВМ в целом или своего ПО/БД. В этом случае, разумеется, потребуется более глубокая диагностика. Во-вторых, самим интересно :). Так мы можем проверить новые и текущие тома СХД и сравнить системы между собой. Как бы там ни было, методика плюс-минус подходит в обоих случаях.
Что проверяется?
Методика оценивает дисковую подсистему именно в гостевой ОС виртуальной машины. Если в самой ОС всё в порядке, это косвенно позволяет оценить с точки зрения клиента выбранный для диска профиль на соответствие как заявленным параметрам, так и своим требованиям. И можно либо оптимизировать ПО/ОС, либо перейти на более производительный дисковый профиль.
Как проверяется?
Идея заключается в серии замеров утилитой iostat в течении всего времени проверки с периодическим запуском тестовой нагрузки в виде fio. Это позволит сравнить между собой показания «холостого хода» и под нагрузкой. Очень удобно, что iostat умеет сохранять показания в формате json. Это избавляет от костылификации регулярок для парсинга консольного вывода. Полученные json-файлы обрабатываются при помощи библиотек Pandas и MatPlotLib: в JupyterLab строятся графики для дальнейшего анализа.
Работа утилит в командной строке и результаты в виде json позволили оптимизировать проведение диагностики. С другой стороны, это сужает применяемость методики до круга *nix-систем.
Практика №1
Тестовый стенд представляет собой ВМ с Ubuntu 20.04 в качестве гостевой ОС, CPU 2 ядра, RAM 4 ГБ.
Cloud4Y предлагает несколько дисковых политик на выбор, мы попрактикуемся на наиболее популярной из них, vcd-type-med. В конфиге runfio.cfg (можно найти в Приложении к этой статье) отражены её параметры из стандартного договора:
гарантируется, в зависимости от размера диска, до 1000 iops на диск с latency менее 30 мс при нагрузке
70% на чтение
30% на запись
блок 4 КБ
при 50% random’е
Т. е. в данном случае мы проверим соответствие реальных значений заявленным. После запуска и обработки тестов результат выглядит так:

На графике представлены все ключевые метрики, собранные в гостевой ОС. Тестовая нагрузка похожа на два «верблюжьих горба» и составила 700 операций на чтение и 300 на запись при latency около 1 мс, что ещё очень далеко до оговорённых 30 мс. Утилизация диска ожидаемо согласуется с тестами — 100% при нагрузке и около 0% без неё. Длина очереди под нагрузкой была на уровне 5 КБ.
Тест под 100% нагрузкой пройдён. Интересно, а что произойдёт при перегрузке и почему?
Практика №2
Под спойлером графики для нагрузки в 50%, 100%, 200%, 500% и 1000% от номинала
x10 означает 1000% от предусмотренного политикой номинала
т.е. fio запускалась с конфигом
rate_iops=7000,3000,вместо обычных700,300,
Половинная нагрузка ничем принципиально не отличается от полной, интересное начинается при перегрузке. Последние три графика по сути одинаковы. Видно, что утилизация диска в моменты нагрузки также достигает 100%, как и ранее. IOPS’ы подросли немного, примерно на +20% от номинала, и составили 800 на запись и 400 на чтение. А вот длина очереди и latency выросли многократно.
Почему так происходит?
Дело в том, что когда гостевая ОС выходит из зоны комфорта за рамки дисковой политики, vSphere начинает троттлинг: притормаживает «лишние» IO-операции, помещая их в очередь перед отправкой к СХД так, чтобы вернуть ВМ обратно в заданные границы. Таким образом, попытки сэкономить на дисках приведут лишь к неожиданным значительным «тормозам» ПО by design.
Выводы
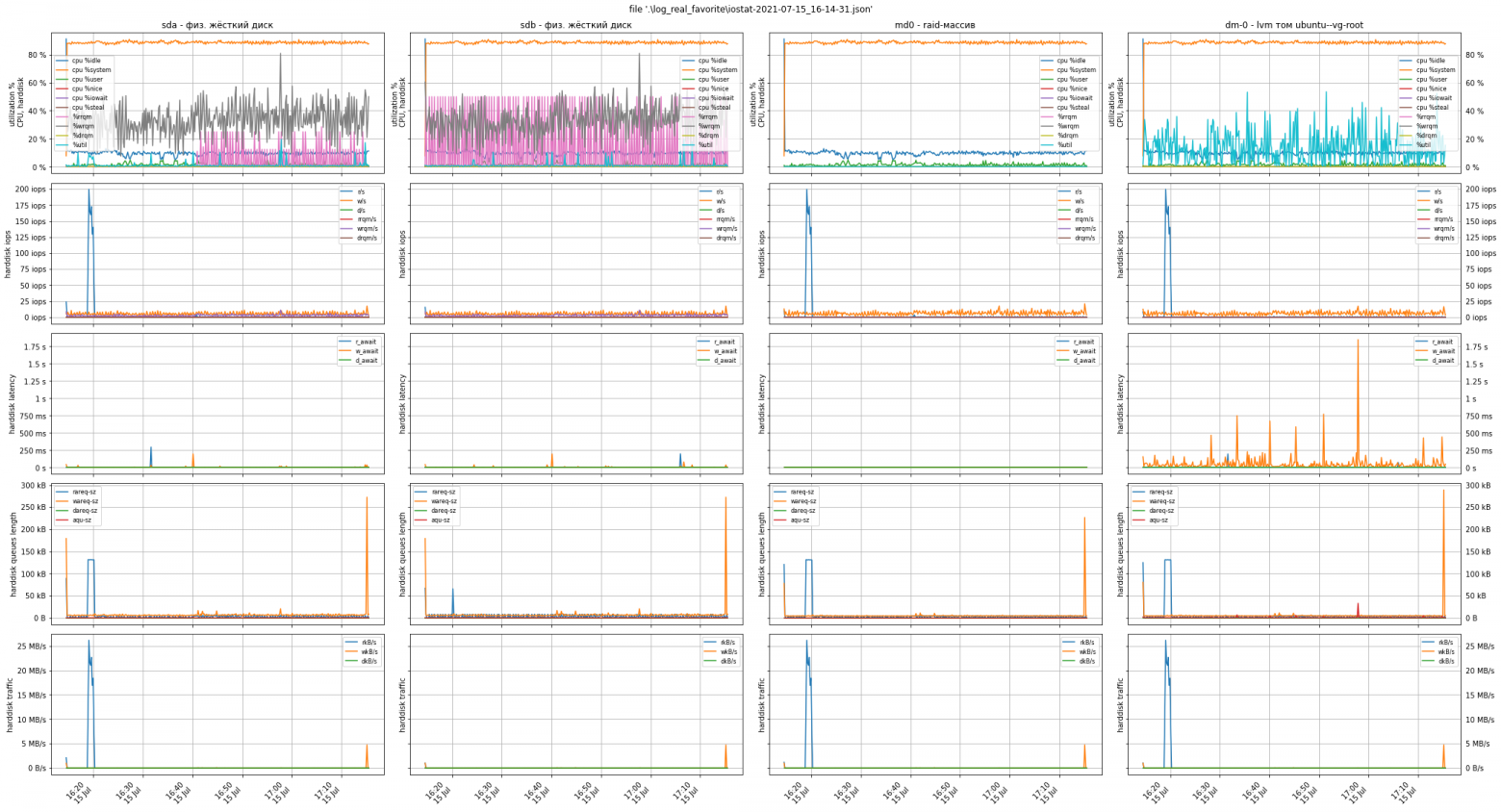
В итоге имеем вполне рабочий инструмент для анализа и диагностики дисковой подсистемы, который подойдёт не только для виртуальных машин, но и для «железных» серверов. Длительность измерений можно увеличить довольно сильно, а вместе или вместо тестовой fio-нагрузки включать/выключать боевое ПО. Так диагностика будет глубже и вы сможете точнее локализовать проблему производительности. Кроме того, в случае более сложной архитектуры дисковой системы, видно картину в целом: физические и логические устройства.
На практике у нас был кейс, когда клиент столкнулся с низкой производительностью софта по обсчёту кубов данных. Сервер был «железный», без виртуализации. Разработчики ПО отвечали клиенту, что проблема в производительности дисковой подсистемы. Мы провели диагностику, фиксируя метрики на протяжении 24 часов, и дали клиенту подробный отчёт, предоставив ему аргументацию для диалога с разработчиками ПО.
Под спойлером ниже — график из этого кейса, в т. ч. как иллюстрация более сложной архитектуры: физические диски были объединены в программный рейд, внутри которого организована LVM-структура томов.
Код
 complex disk subsystem graphs expample
complex disk subsystem graphs expampleПриложения
Ссылки на материалы
Официальная документация VMWare
Кратко о тротлинге при превышении лимита IOPS
Статья VMWare о механизмах лимитирования
Для чего нужны лимиты
Статья в knowledge base Cloud4Y
Запуск тестов
cat ./runfio.cfg
./runfio.sh --repeat 2 --time 60 >> runfio.sh.log &
./runiostat.sh --repeat 1 --count 30 >> runiostat.sh.log &
Нагрузка включится дважды на 60 секунд с интервалом в 60 секунд, т.е. первая, третья и пятая минуты — холостой ход, а вторая и четвёртая — под нагрузкой.
За это время будет сделано 30 замеров с интервалом в 10 секунд, который задан в теле скрипта.
minutes
| 1 | 2 | 3 | 4 | 5 |
--------|---|---|---|---|---|
iostat | + | + | + | + | + |
--------|---|---|---|---|---|
fio | | + | | + | |Исходный код скриптов запуска измерений и нагрузки на Bash
runfio.sh
#!/usr/bin/env bash
# https://brianchildress.co/named-parameters-in-bash/
repeat=${repeat:-1}
time=${time:-10}
while [ $# -gt 0 ]; do
if [[ * ]]; then
param="" class="formula inline">{1/--/}"
declare " class="formula inline">2"
# echo $1 $2 # Optional to see the parameter:value result
fi
shift
done
for i in seq 1 $repeat;
do
sleep $time
# fio --bs=4k --rw=randrw --percentage_random=50 --rwmixread=70 --rwmixwrite=30 --direct=1 --iodepth=256 --time_based --group_reporting --name=iops-test-job --eta-newline=1 --numjobs=1 --filename=runfio.sh.test --runtime=$time --size=1GB --ioengine=libaio --rate_iops=700,300,
fio --runtime=$time --eta-newline=1 runfio.cfg
done
runfio.cfg
[c4y]
bs=4k
rw=randrw
percentage_random=50
rwmixread=70
rwmixwrite=30
direct=1
iodepth=256
time_based
group_reporting
name=iops-test-job
numjobs=1
filename=runfio.sh.test
size=1GB
ioengine=libaio
rate_iops=700,300,
runiostat.sh
#!/usr/bin/env bash
# https://brianchildress.co/named-parameters-in-bash/
repeat=${repeat:-1}
count=${count:-1}
while [ $# -gt 0 ]; do
if [[ * ]]; then
param="" class="formula inline">{1/--/}"
declare " class="formula inline">2"
# echo $1 $2 # Optional to see the parameter:value result
fi
shift
done
for i in seq 1 $repeat;
do
dt=`date '+%Y-%m-%d_%H-%M-%S'`
echo "$i $dt"
./sysstat/iostat -x -t -o JSON 10 $count > "./runiostat.sh-$dt.json"
done
Исходный код построения графиков на Python3
conf.py
# маска для составления списка файлов в подпапке
mask = '*.json'
# корневая папка скрипта является рабочей папкой по умолчанию
base_dir = '.'
# исключающий список папок, которые функция get_folders пропускает
exclude_dirs = ['pycache', '.idea', '.ipynb_checkpoints', '_shell-scripts', '__stuff']
# исключающий список устройств, для которых не нужно строить графики
exclude_dev = [
'fd0',
'sr0',
'loop0',
'loop1',
'loop2',
'loop3',
'loop4',
'loop5',
'loop6',
'loop7',
'loop8',
'loop9',
'loop10',
'loop11',
'loop12',
'loop13',
'loop14',
'loop15',
]
# описания графиков: какую группу метрик выводить, как подписать ось Y и какие у неё единицы измерения
figures = [
{ # 1й график
'labels': 'CPU utilization',
'units': '%',
'metrics': ['avg-cpu.idle', 'avg-cpu.system', 'avg-cpu.user', 'avg-cpu.nice', 'avg-cpu.iowait', 'avg-cpu.steal'],
'legends': ['idle', 'system', 'user', 'nice', 'iowait', 'steal'],
},
{ # 2й график
'labels': 'harddisk utilization',
'units': '%',
'metrics': ['rrqm', 'wrqm', 'util', 'drqm']
},
{
'labels': 'harddisk iops',
'units': 'iops',
'metrics': ['r/s', 'w/s', 'rrqm/s', 'wrqm/s', 'd/s', 'drqm/s']
},
{
'labels': 'harddisk latency',
'units': 's',
'metrics': ['r_await', 'w_await', 'd_await']
},
{
'labels': 'harddisk queue sizes',
'units': 'B',
'metrics': ['rareq-sz', 'wareq-sz', 'aqu-sz', 'dareq-sz']
},
{
'labels': 'harddisk traffic',
'units': 'B/s',
'metrics': ['rkB/s', 'wkB/s', 'dkB/s']
},
]
helper.py
import json
import glob
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mpl_dates
from matplotlib.ticker import EngFormatter
import os
# для проверки через isinstance
import matplotlib
import numpy
import conf
# возвращает список папок внутри conf.base_dir в виде объектов со свойствами .name и .path
def get_folders(base_dir=None, exclude_dirs=None):
if base_dir is None:
base_dir = conf.base_dir
if exclude_dirs is None:
exclude_dirs = conf.exclude_dirs
return [f for f in os.scandir(base_dir) if f.is_dir() and f.name not in exclude_dirs]
# возвращает список файлов по маске conf.mask в указанной папке
def get_files(folder, mask=None):
if not isinstance(folder, str):
folder = ''
files = []
if mask is None:
files += glob.glob(os.path.join(folder, conf.mask))
else:
files += glob.glob(os.path.join(folder, mask))
return files
#
def get_json(file=None):
if file:
with open(file) as f: # импорт json из списка файлов
js = json.load(f)
return js
#
def normalize(df=None): # нормализует колонки для корректного отображения приставок перед единицами измерения
if 'r_await' in df.columns:
df['r_await'] = df['r_await'] / 1000 # milliseconds -> seconds
if 'w_await' in df.columns:
df['w_await'] = df['w_await'] / 1000 # milliseconds -> seconds
if 'd_await' in df.columns:
df['d_await'] = df['d_await'] / 1000 # milliseconds -> seconds
if 'rareq-sz' in df.columns:
df['rareq-sz'] = df['rareq-sz'] * 1024 # kBytes -> Bytes
if 'wareq-sz' in df.columns:
df['wareq-sz'] = df['wareq-sz'] * 1024 # kBytes -> Bytes
if 'dareq-sz' in df.columns:
df['dareq-sz'] = df['dareq-sz'] * 1024 # kBytes -> Bytes
if 'aqu-sz' in df.columns:
df['aqu-sz'] = df['aqu-sz'] * 1024 # kBytes -> Bytes
if 'rkB/s' in df.columns:
df['rkB/s'] = df['rkB/s'] * 1024 # kBytes/s -> Bytes/s
if 'wkB/s' in df.columns:
df['wkB/s'] = df['wkB/s'] * 1024 # kBytes/s -> Bytes/s
if 'dkB/s' in df.columns:
df['dkB/s'] = df['dkB/s'] * 1024 # kBytes/s -> Bytes/s
return df
#
def merge_dataframes(gen_data=None, dev_data=None, device=None, datetime_format=None):
if gen_data is None or dev_data is None or device is None:
return None
df = pd.concat([
dev_data[dev_data['disk_device'] == device].reset_index(),
gen_data['timestamp'],
gen_data['avg-cpu.user'],
gen_data['avg-cpu.nice'],
gen_data['avg-cpu.system'],
gen_data['avg-cpu.iowait'],
gen_data['avg-cpu.steal'],
gen_data['avg-cpu.idle'],
], join='inner', axis=1)
df.drop(['index'], inplace=True, axis=1)
df.index = pd.to_datetime(df['timestamp'], format=datetime_format) # '%d.%m.%Y %H:%M:%S' # https://nbviewer.jupyter.org/gist/nipunbatra/6947228 # df['time'] = pd.to_datetime(df['timestamp'], format='%d.%m.%Y %H:%M:%S')
df = normalize(df=df)
return df
#
def plot(
files=None, # список файлов, по которым нужно строить графики
w=4, # ширина графика
h=3, # высота графика
datetime_format=None, # формат отметок времени в json-файле
first=0, # первая точка
last=None, # последняя точка
dev_desc=None, # описания устройств, узнать можно командой ls -l /dev/mapper
dev_placement='col', # как располагать устройства, в колонках или строках
): # непосредственно рисует графики
if dev_desc is None:
dev_desc = {}
if files is None:
return -1
if isinstance(files, str):
files = [files]
for file in files:
# обработка (импорт данных, построение графиков) по одному файлу за раз
with open(file) as f: # импорт json из списка файлов
j = json.load(f)
# преобразование json в dataframe https://towardsdatascience.com/all-pandas-json-normalize-you-should-know-for-flattening-json-13eae1dfb7dd
general = pd.json_normalize(j['sysstat']['hosts'][0]['statistics']) # метки времени
device = pd.json_normalize(j['sysstat']['hosts'][0]['statistics'], record_path=['disk']) # статистика дисков
devs = [dev['disk_device'] for dev in j['sysstat']['hosts'][0]['statistics'][0]['disk'] if dev['disk_device'] not in conf.exclude_dev]
# devs.sort(reverse=True)
if dev_placement == 'col'