Новые оптимизации для х86 в ожидаемом GCC 5.0
Итак, фактическую разработку новых оптимизаций в GCC 5.0 можно считать законченной. Продукт GCC 5.0 находится сейчас в фазе stage3, то есть идет доработка уже внедренных оптимизаций. В данной и последующих статьях я расскажу об оптимизациях, реализованных в GCC 5.0 для х86 и об их влиянии на производительность программ для процессоров линейки Intel Atom и Intel Core. Сегодня речь пойдет о векторизации групповых обращений в память. В последующих статьях я расскажу об ускорениях в 32-битном PIC режиме и дополнительном усилении векторизации.Как вы уже, наверное, догадались, в GCC 5.0 существенно улучшена векторизация групповых обращений в память. Под групповым обращением в память понимается итерируемая последовательность обращений. Например: x = a[i], y = a[i + 1], z = a[i + 2] итерируемое по i — это группа загрузок из памяти длиной 3. Длина группы обращений в память — это расстояние между самым младшим и старшим адресами в группе. Для примера выше — это (i + 2) — (i) + 1 = 3Количество обращений в память в группе не превосходит ее длину. Например: x = a[i], z = a[i + 2] итерируемое по i — это группа длиной 3, несмотря на то, что обращений в память всего 2.GCC 4.9 векторизует группы, где длина — это степень 2 (2, 4, 8…).
GCC 5.0 векторизует группы, где длина равна 3 или степени 2 (2, 4, 8…). Другие длины не векторизуются, так как встречаются в реальных приложениях очень редко.
Чаще всего векторизация группы обращений в память применяется при работе с массивами структур.
1. Конвертация изображений, скажем, в структуре RGB. Пример.2. Работа с N-мерными координатами (скажем, чтобы нормализовать трехмерные точки). Пример.3. Умножение векторов на константную матрицу:
a[i][0] = 7 * b[i][0] — 3 * b[i][1]; a[i][1] = 2 * b[i][0] + b[i][1]; В целом в GCC 5.0 (по сравнению с 4.9)Появилась векторизация группы обращений в память длиной 3 Существенно улучшилась векторизации группы загрузок из памяти для любой длины Стали использоваться техники векторизации групп обращений в память оптимальные для конкретного x86 процессора. Далее приведены таблицы, позволяющие оценить увеличение производительности при использовании GCC 5.0 на байтовых структурах (наибольшее количество элементов в векторе) по сравнению с GCC 4.9. Для оценки используется следующий цикл: int i, j, k; byte *in = a, *out = b; for (i = 0; i < 1024; i++) { for (k = 0; k < STGSIZE; k++) { byte s = 0; for (j = 0; j < LDGSIZE; j++) s += in[j] * c[j][k]; out[k] = s; } in += LDGSIZE; out += STGSIZE; } Где:c — это константная матрица: const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1}; Такая матрица используется чтобы минимизировать вычисления внутри цикла до сравнительно быстрых сложений и вычитаний.in и out — указатели на глобальные массивы «a[1024 * LDGSIZE]» и «b[1024 * STGSIZE]» byte это unsigned char LDGSIZE и STGSIZE – макросы, определяющие длину группы загрузок из памяти и сохранений в память соответственно Опции компиляции "-Ofast" плюс "-march=slm" для Silvermont, "-march=core-avx2" для Haswell и все комбинации -DLDGSIZE={1,2,3,4,8} -DSTGSIZE={1,2,3,4,8}
Прирост производительности GCC 5.0 по сравнению с 4.9 (во сколько раз ускорилось, больше — лучше).
Silvermont: Intel® Atom™ CPU C2750 @ 2.41GHz
Прирост до 6.5 раз!
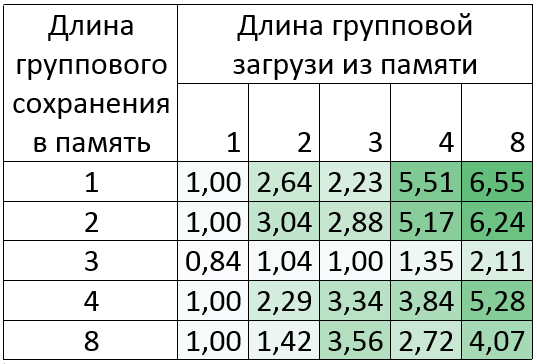
Как видно из таблицы, результаты для групп сохранений в память длиной 3 не очень хорошие. Это происходит потому, что для такого преобразования требуется 8 инструкций «pshufb», длительность исполнения которой на Silvermont около 5 тактов. Несмотря на это, векторизация других команд в цикле может дать больший прирост. Это видно на примере группы загрузок из памяти длиной 2, 3, 4 и 8.
Пример GCC ассемблера для группы загрузок из памяти длиной 2:
GCC 4.9 GCC 5.0 movdqa .LC0(%rip), %xmm7movdqa .LC1(%rip), %xmm6movdqa .LC2(%rip), %xmm5movdqa .LC3(%rip), %xmm4movdqu a (%rax,%rax), %xmm1movdqu a+16(%rax,%rax), %xmm0movdqa %xmm1, %xmm3pshufb %xmm7, %xmm3movdqa %xmm0, %xmm2pshufb %xmm5, %xmm1pshufb %xmm6, %xmm2pshufb %xmm4, %xmm0por %xmm2, %xmm3por %xmm0, %xmm2 movdqa .LC0(%rip), %xmm3movdqu a (%rax,%rax), %xmm0movdqu a+16(%rax,%rax), %xmm1movdqa %xmm3, %xmm4pand %xmm0, %xmm3psrlw $8, %xmm0pand %xmm1, %xmm4psrlw $8, %xmm1packuswb %xmm4, %xmm3packuswb %xmm1, %xmm0 Здесь, как и в приведенном ниже примере для Haswell, стоит отметить, что большинство констант ».LC» будут инвариантами в цикле, однако только при наличии свободных регистров. В противном случае их придется ставить непосредственно в phufb: «pshufb .LC0, %xmm3». Такой pshufb будет больше на размер адреса и потенциально дольше исполнятся.Haswell: Intel® Core™ i7–4770K CPU @ 3.50GHzПрирост до 3 раз!

В данном случае результаты для групп сохранений в память длиной 3 намного лучше, так как на Haswell инструкция «pshufb» исполняется за 1 такт. Более того, наибольший прирост здесь именно для внедренной векторизации групп обращений в память длиной 3.
Пример GCC ассемблера для группы загрузок из памяти длиной 2:
GCC 4.9 GCC 5.0 vmovdqa .LC0(%rip), %ymm7vmovdqa .LC1(%rip), %ymm6vmovdqa .LC2(%rip), %ymm5vmovdqa .LC3(%rip), %ymm4vmovdqu a (%rax,%rax), %ymm0vmovdqu a+32(%rax,%rax), %ymm2vpshufb %ymm7, %ymm0, %ymm1vpshufb %ymm5, %ymm0, %ymm0vpshufb %ymm6, %ymm2, %ymm3vpshufb %ymm4, %ymm2, %ymm2vpor %ymm3, %ymm1, %ymm1vpor %ymm2, %ymm0, %ymm0vpermq $216, %ymm1, %ymm1vpermq $216, %ymm0, %ymm0 vmovdqa .LC0(%rip), %ymm3vmovdqu a (%rax,%rax), %ymm0vmovdqu a+32(%rax,%rax), %ymm2vpand %ymm0, %ymm3, %ymm1vpsrlw $8, %ymm0, %ymm0vpand %ymm2, %ymm3, %ymm4vpsrlw $8, %ymm2, %ymm2vpackuswb %ymm4, %ymm1, %ymm1vpermq $216, %ymm1, %ymm1vpackuswb %ymm2, %ymm0, %ymm0vpermq $216, %ymm0, %ymm0 Из всего вышесказанного следует вывод: используя GCC 5.0, можно существенно ускорить производительность приложений, подобных описанным выше. Начинать пробовать можно уже сейчас! Большинство правок планируется портировать в Android NDK.Компиляторы используемые в замерах:
Скачать пример, на котором производились замеры, можно из оригинального текста статьи на английском.
