Низкоуровневое обнаружение (LLD) в Zabbix через SQL-запросы

Привет, Хабр! В этой статье поделюсь полезным подходом мониторинга в Zabbix — через обнаружение элементов данных в ответе на SQL-запрос. Этот тип мониторинга обычно используется в бизнес-мониторинге, когда собираются показатели производительности бизнес-процесса: количество пользователей, транзакций или выполняется контроль статуса операций. В целом, это универсальный подход, про который администраторы Zabbix иногда забывают. А он есть. Добро пожаловать под кат.
Что будем делать в этой статье:
- Клонируем репозиторий pg_stat_monitor от Percona и соберём этот плагин из исходников;
- Добавим плагин pg_stat_monitor в БД PostgreSQL, на которой работает Zabbix;
- Создадим шаблон для выполнения SQL-запроса в pg_stat_monitor;
- Создадим правило низкоуровневого обнаружения для разбора ответа от SQL-запрос;
- Создадим зависимые прототипы элементов данных для мониторинга некоторых характеристик производительности БД.
На сервере предварительно уже установлен Zabbix 5.2, работающий на PostgreSQL 12.
Pg_stat_monitor — плагин для сбора статистики от Percona, основанный на pg_stat_statements. Можно сказать, что pg_stat_monitor — это pg_stat_statements на стероидах. Основной недостаток pg_stat_statements — отсутствие агрегированной статистики (и гистограмм в т.ч.) по накопленным запросам и статистике по ним. Соответственно, pg_stat_monitor лишен такого недостатка. Объём статистики, которая может собираться, настраивается в конфигурации плагина. Работает плагин следующим образом:
- собирается статистика и объединяется в корзину (агрегат);
- корзина собирается и хранится заданный период времени;
- когда время истекает, pg_stat_monitor сбрасывает всю накопленную статистику и начинает собирать её заново.
Т.к. все данные из корзины в итоге исчезнут, нужно успеть прочитать эти данные. Как раз их мы и будем читать при помощи Zabbix.
Исходный код плагина доступен в репозитории Percona на Github. Мы его оттуда клонируем, соберём на тестовом сервере и подключим к имеющемуся инстансу PostgreSQL.
# dnf -y install gcc git libpq-devel postgresql-server-devel
# cd /tmp
# git clone git://github.com/Percona/pg_stat_monitor.git
# cd pg_stat_monitor
# make USE_PGXS=1
# make USE_PGXS=1 install
# sudo -i -u postgres psql
# postgres=# alter system set shared_preload_libraries=pg_stat_monitor;
# postgres=# \q
# systemctl restart postgresql
# sudo -i -u postgres psql
# postgres=# create extension pg_stat_monitor;
# postgres=# \q
После установки можно убедиться, что всё работает и спросить у плагина его настройки:

Ещё можно спросить, что он вообще может показать:
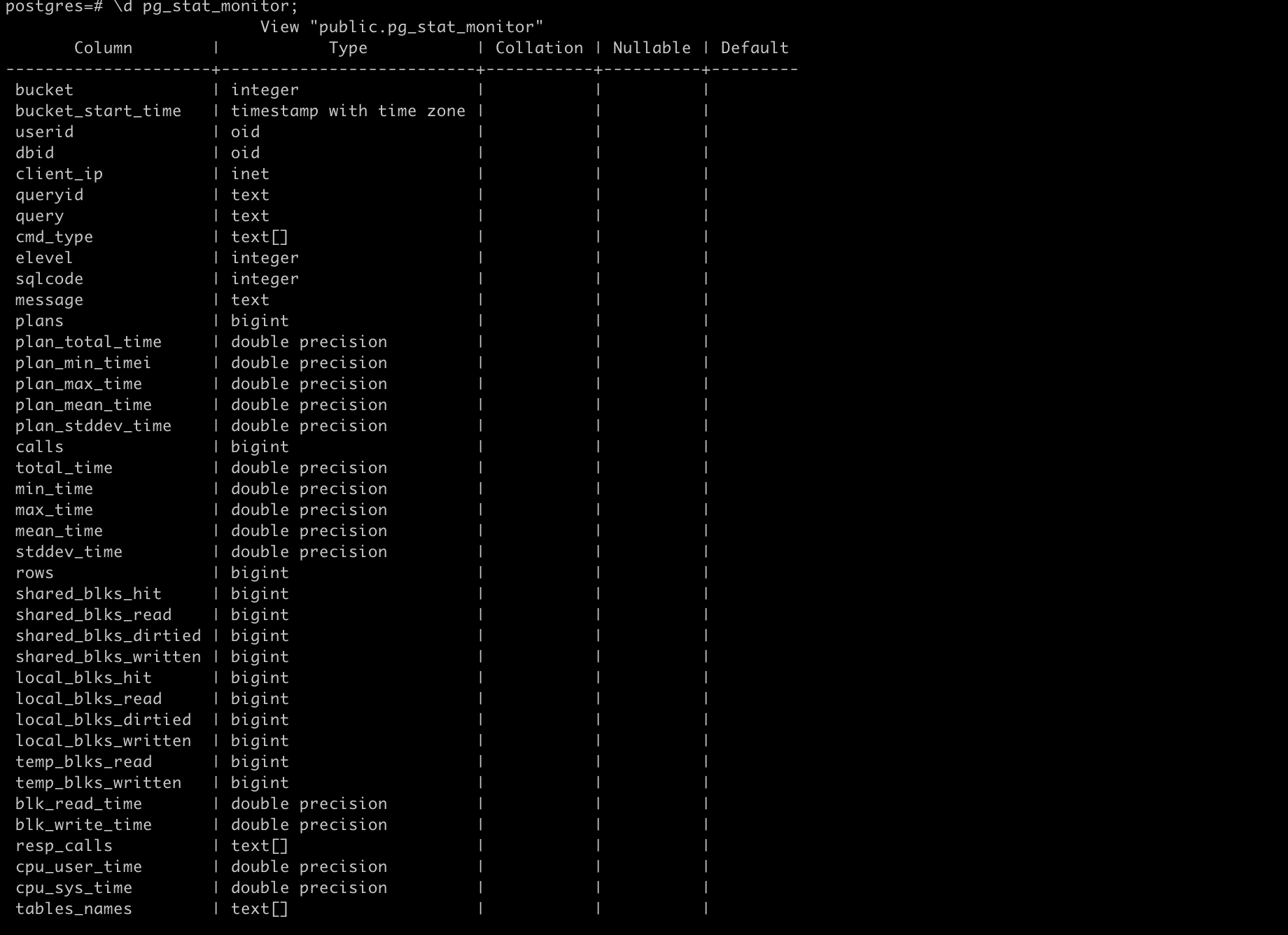
Некоторые из данных со скриншота выше мы будет потом забирать в Zabbix.
Теперь установим на сервер с БД драйвер ODBC:
# dnf -y install postgresql-odbc
И проверим как там называется драйвер:

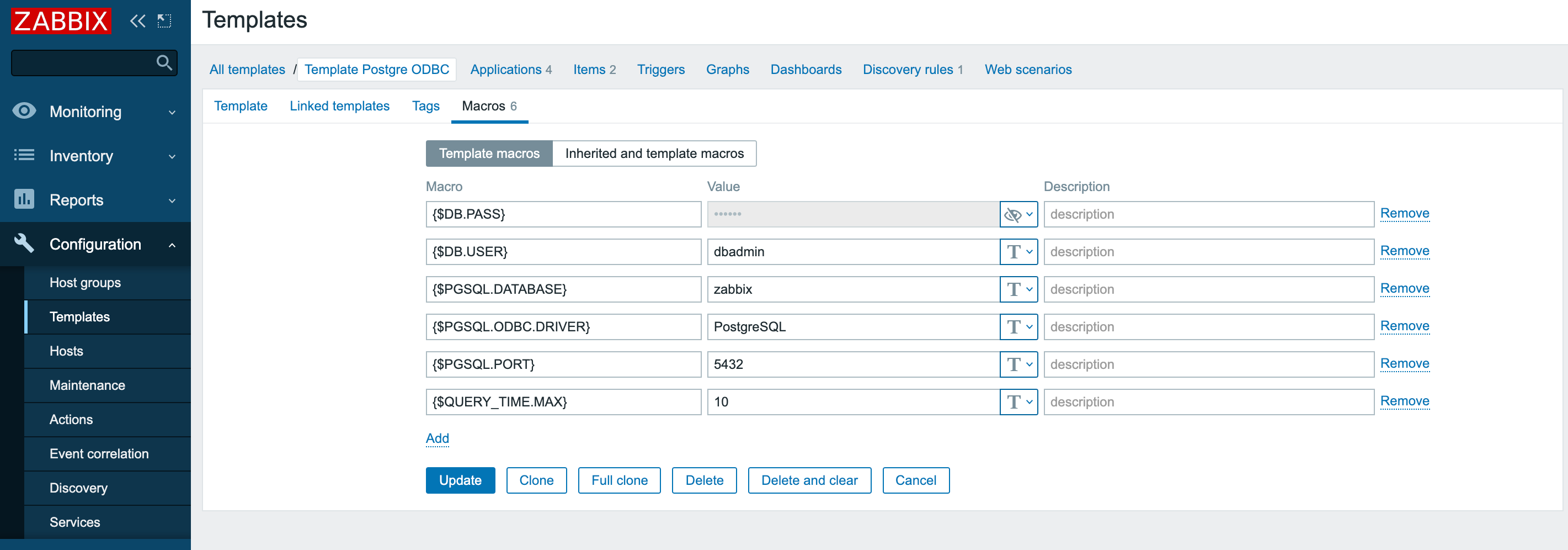
Теперь можно перейти в Zabbix, добавить некоторые макросы:
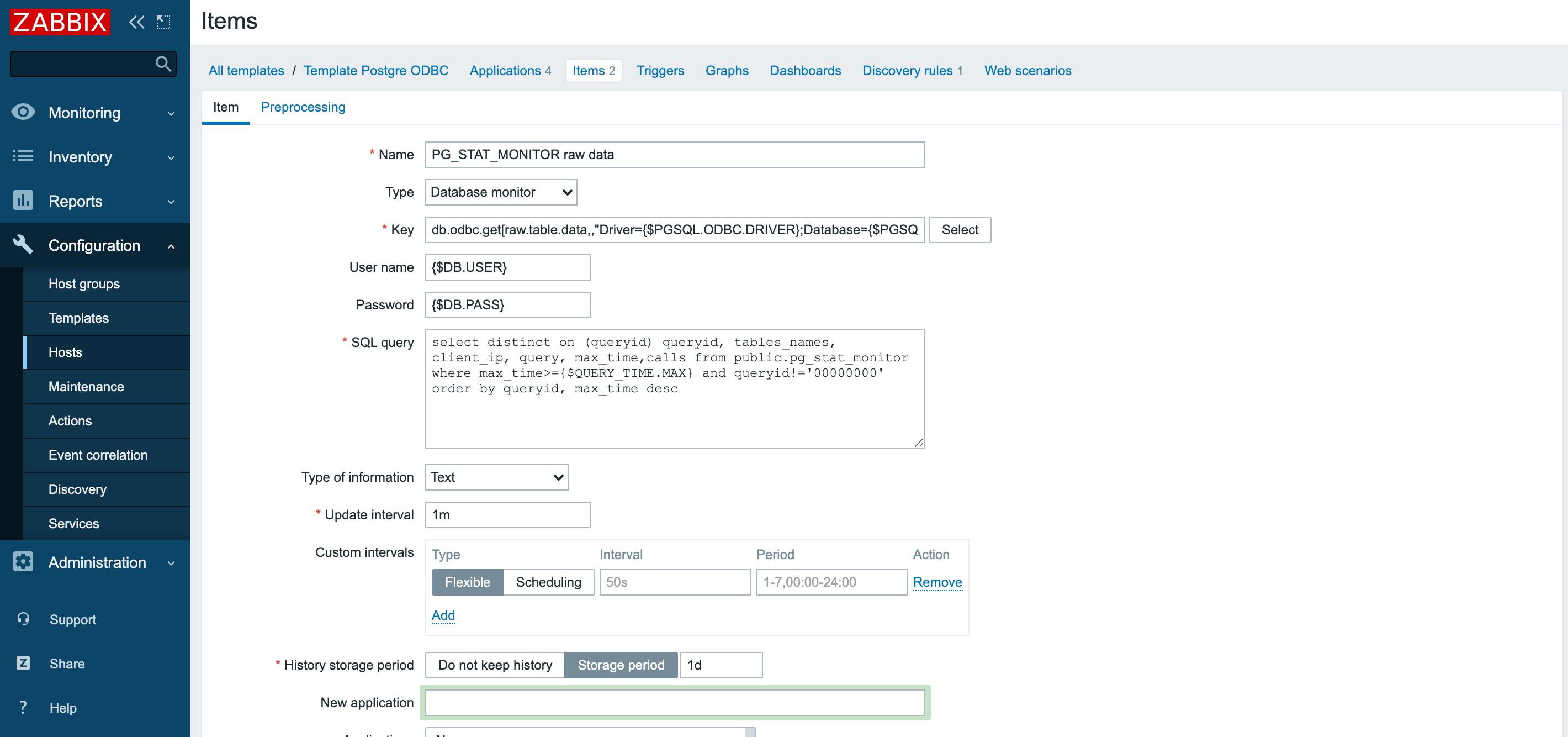
И создать мастер-элемент данных, из которого потом будут разбирать всё необходимое зависимые элементы:
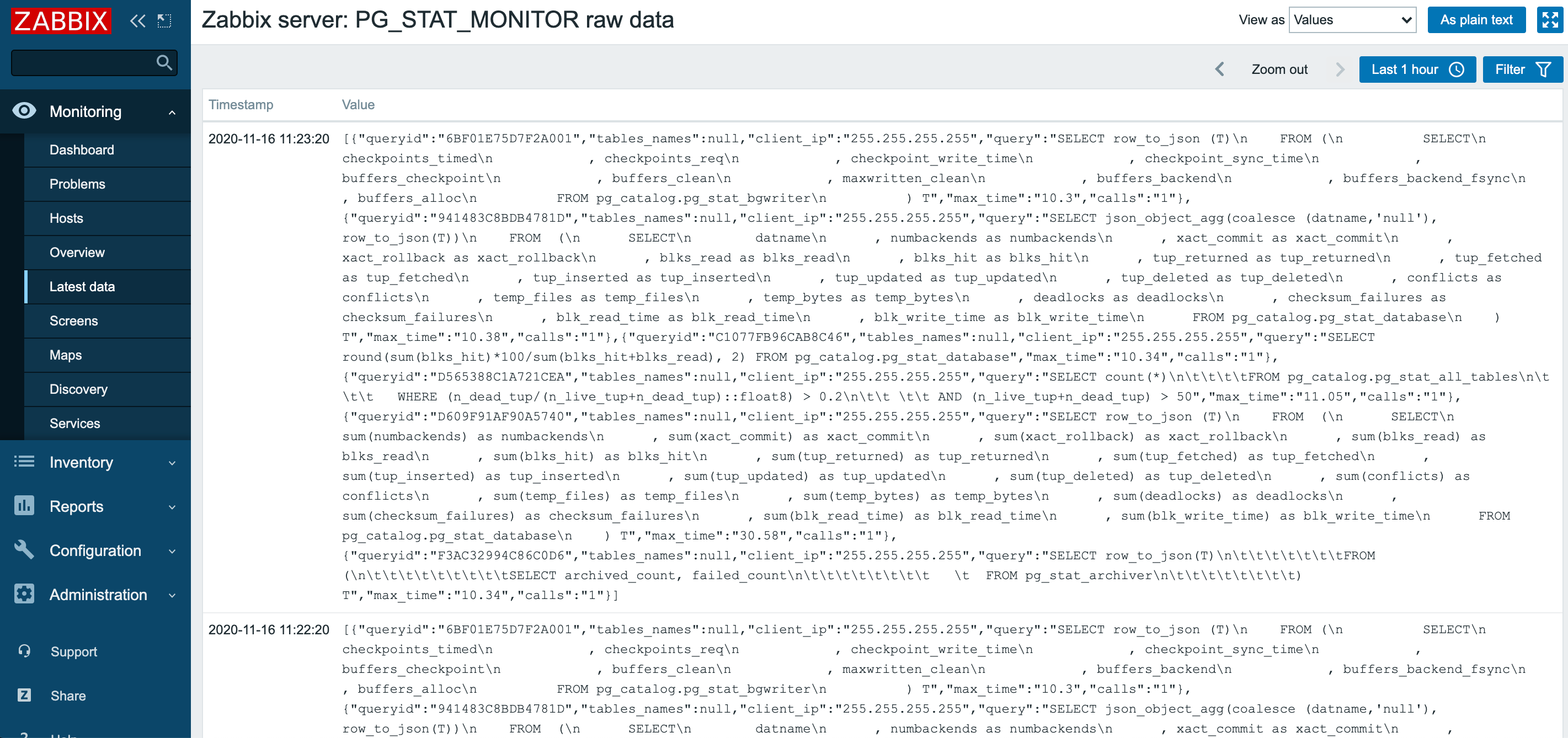
В результате получим вывод в формате JSON:
На следующем шаге добавим к шаблону правило дискаверинга:
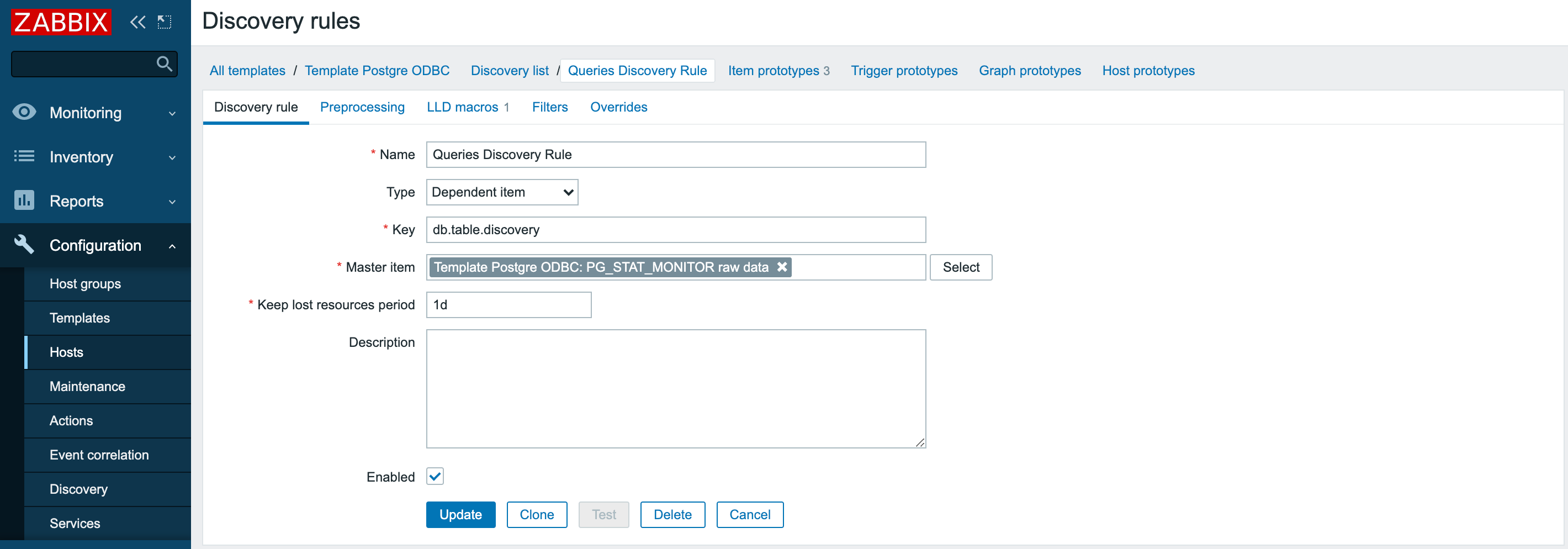
Добавим LLD-макрос для создания новых объектов по полю queryid:

Создаём один из прототипов элементов данных:
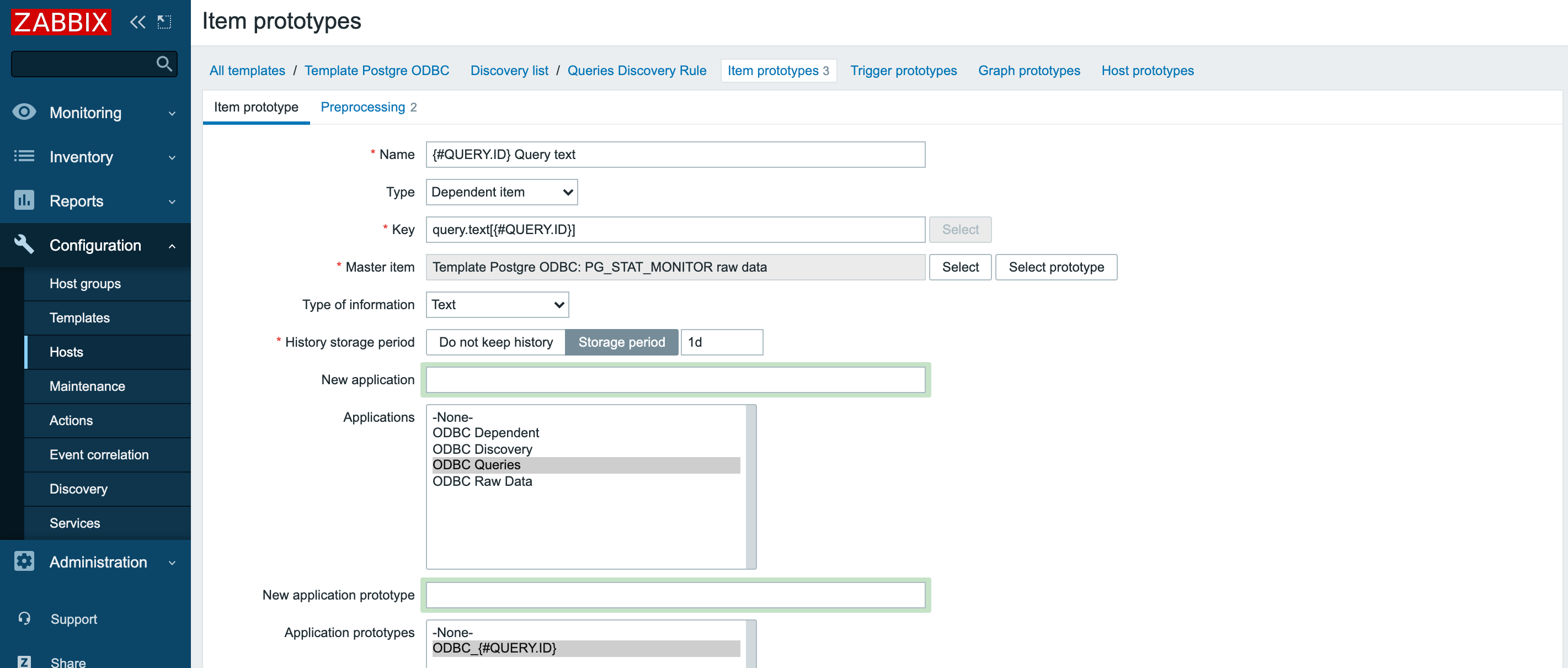
И шаги препроцессинга:

В итоге мы настроили три прототипа данных для разбора полей с текстом запроса, максимальным временем выполнения и количеством вызовов:

В результате всех выполненных настроек получим следующую картину:
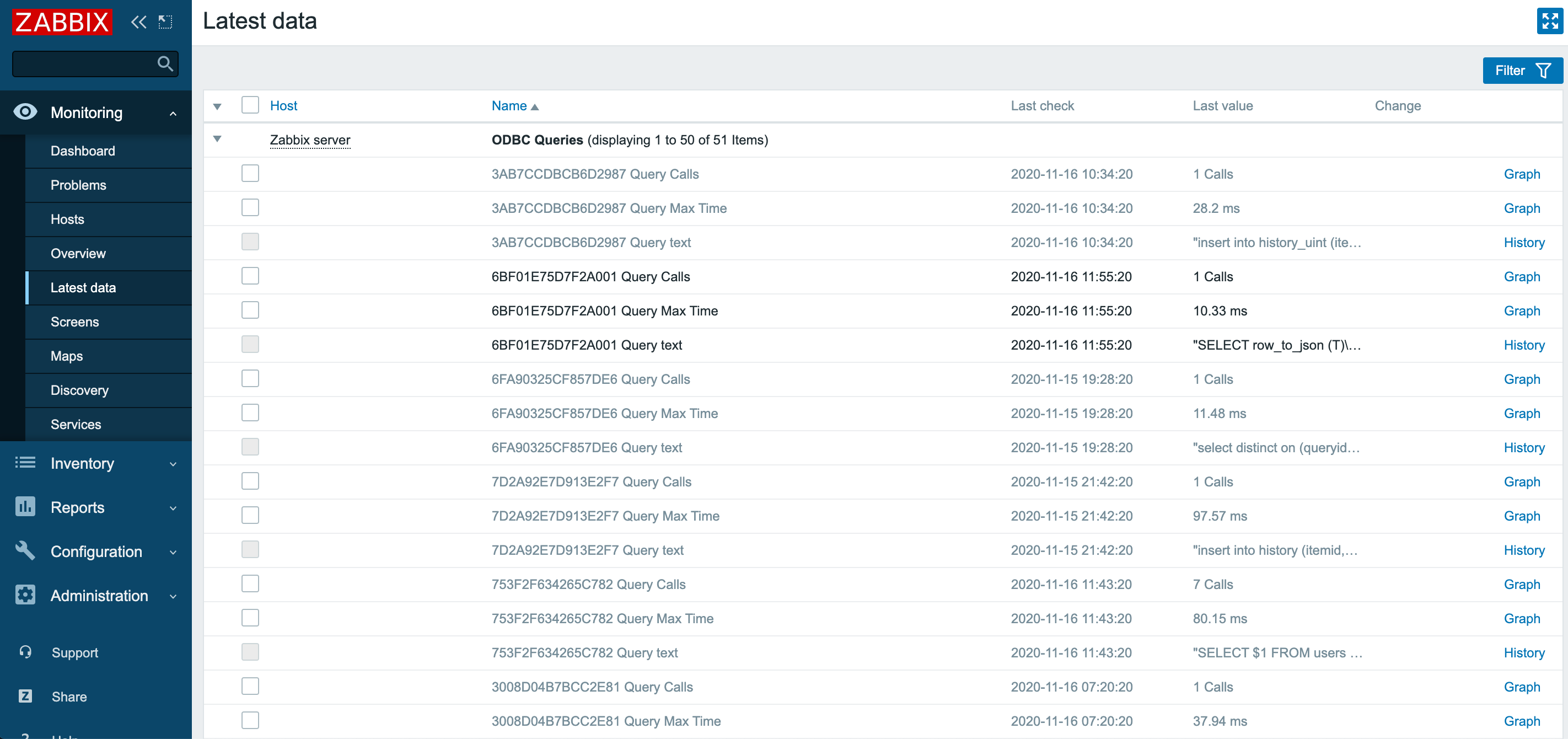
Некоторые из запросов окрашены в серый, потому что queryid с ними более не обнаруживаются. Можно настроить минимальное время хранения таких объектов и удалять их сразу после отправки оповещения о длительном SQL-запросе.
Мы рассмотрели общую концепцию настройки низкоуровнего обнаружения через SQL-запросы. Примерно таким образом можно автоматизировать мониторинг специализированных метрик из баз данных. А собирая все необходимые данные в представления, можно за один запрос извлекать максимум требуемой информации. Подробнее о наших услугах относительно Zabbix вы можете узнать на специальной странице.
А ещё можно почитать:
Zabbix под замком: включаем опции безопасности компонентов Zabbix для доступа изнутри и снаружи
Добавляем CMDB и географическую карту к Zabbix
Структурированная система мониторинга на бесплатных решениях
Мониторинг принтеров в Zabbix
Как сократить объем дискового пространства, занимаемого БД Zabbix
Как снизить количество шумовых событий в Zabbix
