NER: Как мы обучали собственную модель для определения брендов. Часть 2
Привет всем! Сегодня продолжим рассказ о том, как наша команда Data Science из CleverData начала выделять бренды в строках онлайн-чеков. Цель такого упражнения — построение отчета для бренд-анализа, о котором мы подробно рассказали в первой статье на эту тему. Из второй части вы узнаете, как на базе пайплайна (сводки с данными) для получения разметки по брендам мы обучили собственную NER-модель.

Почему решили развивать собственную NER-модель
После полученного воодушевляющего отчета на основе пайплайна, о котором мы говорили в прошлой статье (напомним, использовали предобученные NER-модели на тэг Organization: Spacy, Natasha, NER Rus_Bert torch (DeepPavlov), NER Ontonotes Bert mult torch (DeepPavlov)), стало понятно, что игра стоит свеч и что имеет смысл развивать собственную NER-модель. Частично разметка была получена как раз тем «многомодельным» пайплайном. Но нам хотелось, чтобы новая модель была сильнее действующих, поэтому разметку мы дорабатывали. Да, вручную. Да, всей командой. Нет, не страшно. И даже очень классно.
Напомним что, NER (Named entity recognition) — это распознавание именованных сущностей. Сущности — наиболее важные фрагменты конкретного предложения (словосочетания с существительными, глагольные словосочетания и др.). По-другому можно сказать, что NER — это процесс обнаружения в тексте именованных объектов. Например, имен людей, названий мест, компаний и т. д. В нашем конкретном случае, в отличие от классической задачи NER, мы будем выделять только один тип именованных сущностей — бренды.
Для своих экспериментов мы использовали большие данные чеков онлайн-покупок, которые совершали исследуемые сегменты. Для обучения модели мы взяли в качестве данных случайные чеки, которые относятся к разным дням недели, так и к разным месяцам года (2022.01.02–2022.01.20, 2022.02.01–2022.02.15, 2022.03.01–2022.03.15). Общее число строк составило 415 тысяч.
Модели, которые планировали тестировать: rubert-tiny, rubert-tiny2, paraphrase-multilingual-MiniLM-L12-v2, distiluse-base-multilingual-cased-v1 и DeBERTa-v2.
Как планировали эксперимент
Общий пайплайн при первом приближении можно описать так.
Строка чека подвергается предобработке токенизатором, с целью корректного разделения слов (и знаков препинания) перед тэгированием чеков и подачей в токенизаторы моделей.
Чеку сопоставляется последовательность тэгов формата [B — beginning, I — in brand, O — out of brand], согласно выделенным брендам (тэгирование). B-brand означает, что на текущем токене начинается название бренда; I-brand — что текущий токен является продолжением названия предыдущего токена; O — токены, которые не относятся к брендам.
Данные совершенно случайным образом разделяются на train-valid-test выборки.
Данные [чек — список тэгов] подаются в трансформеробразную предобученную языковую модель, поверх которой ставится классификатор (на каждый элемент последовательности).
Во время обучения считаются метрики (в качестве основной используется взвешенная f1-метрика): по каждой последовательности тэгов [B, I, …].
Для получения разметки вида «строка чека — бренд (ы)» к этим данным был применён пайплайн, описанный в прошлой статье.
После применения пайплайна с целью усиления разметки своими естественными нейросетями или методом «внимательного взгляда» мы классифицировали бренды, выделенные на уже обработанных данных, на три класса:
условно-чистые, очевидные (пример: Samsung, Tefal, Бирюса) — такие строки на всякий случай отсматривали, предполагая, что скорее всего ошибок не будет;
подозрительные и неочевидные (пример: Apple. Вроде как Samsung, но ведь есть и духи Green Apple) — отсматривали и разделяли на нужное и ненужное;
«мусорные» — те, которые мы в первой итерации вообще не отсматривали глазами, так как там сплошной мусор (пример: Сад. Какой сад? Фруктовый? Гигант? Или сокращение от «садовый»?).
Семена овощей Русский огород 319029 Огурец Отелло F1 10 шт.

А все ли так легко
Во время разметки данных возникали вопросы следующего характера.
Выделять ли бренд в чеке, если он не имеет отношения к самому товару (пример: «стекло для Apple iphone» — Apple не является брендом стекла).
Какие именованные сущности выделять в строках, где указан один и тот же бренд на оригинальном языке и в русской транслитерации?

Поразмыслив, при перепроверке разметки руководствовались двумя принципами: перечислять все бренды, которые указаны в строке и брать только основной бренд (не проваливаться в линейки).
После обработки датасета получили данные следующего вида: 101336 строк (без дубликатов, очищенные от «спорных» для разметки строк), содержащие более тысячи уникальных брендов (1064).
С брендом | Без бренда | Итого | |
Строк, тыс. | 75.6 | 25.7 | 101.3 |
Доля, % | 74.64 | 25.3 | 100 |
Токенизация
Перед подачей в модель данные будут проходить этап токенизации, так как модели напрямую не работают с текстами. При этом, в зависимости от токенизатора, слитно написанные элементы могут рассматриваться как один токен. Например, 4.5% может быть рассмотрен как уникальный токен (как и 1% и др.), тогда как знак % сам по себе может быть информативным токеном и рассматривать (обучать) его стоит отдельно от связки с конкретным числом.
Для того, чтобы наши данные токенизировались на желаемом уровне вне зависимости от самого принципа работы токенизатора, мы решили сделать подобное разделение на этапе препроцессинга. Для такого корректного разделения текстов по словам и символам, было рассмотрено четыре разных токенизатора. Выбрали nltk.tokenize.wordpunct_tokenize, так как он хорошо справлялся с разделением, в том числе при наличии специальных символов (например, ®).
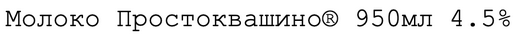

Таким образом, мы обработали достаточное, как нам казалось, количество строк. И в первой итерации на всех моделях получили высочайшие метрики.
Эксперимент № 1
В качестве сэмпла для пробного обучения был взят датасет объемом 30 тысяч строк. Первая итерация обучения по всем моделям показала метрики 0.99+ f1 на train/validation/test-выборках.

При этом модели могли учиться более десяти эпох без признаков переобучения на валидационной выборке. Подозрительно, решили мы. Это натолкнуло нас на следующие вопросы.
Стоит ли включить в валидационную/тестовую выборку бренды, неизвестные для тренировочной выборки?
Достаточно ли используемой f1-метрики (по токенам) для оценки модели?
Нужно ли пересмотреть/перепроверить данные?
В самом деле, в тренировочной и в тестовой выборке встречаются достаточно похожие строки:

Анализ ошибок эксперимента № 1
К чему пришли.
Надо найти те бренды, которые не выделяются пайплайном и добавить их в разметку.
Одна из наших целей — выявлять в том числе те бренды, которых в обучающей выборке не наблюдалось. Поэтому сделаем два теста: один стратифицированный (набор брендов согласно распределению в обучающей и валидационной выборках), другой — неизвестный (только те бренды, которых нет в обучающей и валидационных выборках).
Бренды, не выявляемые пайплайном, — многословные и символосодержащие (внимательный читатель уже, наверное, задал себе и нам вопрос, что понимается под «словом» в понятии «многословный»).
Добавить построчную метрику качества, то есть имеет смысл смотреть не только на потэговый взвешенный F1 score, но и на метрику, которая отражает корректность целиком предсказанной строки (построчная accuracy). Даже одна ошибка в определении тэгов строки будет влиять на итоговый результат: или мы получим лишние бренды (если неправильно определим O), или пропустим истинный бренд (неправильное определение B), или захватим лишь часть названия бренда (ошибка определения I-тэга).
Шаг назад
Пришлось возвращаться к разметке. И это было очень интересно. Имеем проблемы с многословными и символосодержащими брендами? Давайте вместо того, чтобы пытаться их выявить, пойдем в обратном направлении.
Поймем конструкцию многословных брендов (Dr. …, Mr…, person_1&person_2, пример — Dolce & gabbana).
По эвристикам, полученным в п. 1, найдем соответствующие таким брендам покупки.
Эксперимент № 2
Итак, обучаем.
Состав дадасета:
Train | Validation | Test 1 (неизвестные для модели бренды) | Test 2 (стратифицирован по брендам) | |
Строк, % | 70 | 15 | 6 | 9 |
Брендов, % | 90 | 33 | 10 | 44 |
Пример поведения метрик:

Отметим, чтопри множестве тестовых запусков мы с удивлением обнаруживали, как модели сами исправляют ошибки разметки.

Результаты
После того, как разметка была исправлена, мы протестировали несколько предобученных моделей с разными гиперпараметрами. Лучшие результаты по каждой из моделей в таблице ниже.
Модель | Тест «Неизвестные бренды» | Тест стратифицированный | |||
f1 (по лэйблам) | Accuracy (построчно) | f1 (по лэйблам) | Accuracy (построчно) | Время инференса на 10 тыс. строк (gpu) | |
microsoft/mdeberta-v3-base | 0.98 | 0.84 | 0.998 | 0.98 | 1min 16s |
paraphrase-multilingual-mpnet-base-v2 | 0.92 | 0.71 | 0.999 | 0.96 | 3min 1s |
cointegrated/rubert-tiny2 | 0.91 | 0.58 | 0.999 | 0.986 | 12.4 s |
paraphrase-multilingual-MiniLM-L12-v2 | 0.91 | 0.53 | 0.998 | 0.98 | 1min 15s |
Лучшей по результатам оказалась deberta, идеально определяя 84% последовательностей в строках брендов, которых она никогда не видела, — отличный показатель для такой тяжелой задачи. Для стандартного стратифицированного теста метрика составила 98%, что также очень хорошо и более чем подходит для решения нашей задачи — построения отчёта для бренд-анализа.
Если вы хотите следить за новостями CleverData — присоединяйтесь к нашему Telegram-каналу.
Соавтор статьи — @Alex643
