Неперсонализированные рекомендации: метод ассоциаций
Персональные рекомендации позволяют познакомить пользователя с объектами, о которых он, возможно, никогда не знал (и не узнал бы), но которые могут ему понравиться с учетом его интересов, предпочтений и поведенческих свойств. Однако, часто пользователь ищет не новый объект, а, к примеру, объект A похожий на объект B («Форсаж 2» похож на «Форсаж»), или объект A, который приобретается/потребляется с объектом B (сыр с вином, пиво с детским питанием, гречка с тушенкой и т.д.). Построить такие рекомендации позволяют неперсонализированные рекомендательные системы (НРС).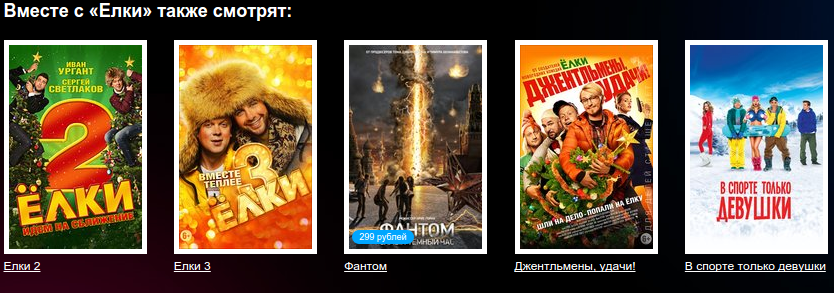 Рекомендовать похожие/сопутствующие объекты можно, ориентируясь на знания об объектах (свойства, теги, параметры) или на знания о действиях, связанных с объектами (покупки, просмотры, клики). Преимуществом первого способа является то, что он позволяет достаточно точно определить похожие по свойствам объекты («Форсаж 2» и «Форсаж» — похожие актеры, похожий жанр, похожие теги, …). Однако данный способ не сможет порекомендовать сопутствующие объекты: сыр и вино. Еще одним недостатком этого способа является тот факт, что для разметки всех объектов, доступных на сервисе, требуется не мало усилий.
Рекомендовать похожие/сопутствующие объекты можно, ориентируясь на знания об объектах (свойства, теги, параметры) или на знания о действиях, связанных с объектами (покупки, просмотры, клики). Преимуществом первого способа является то, что он позволяет достаточно точно определить похожие по свойствам объекты («Форсаж 2» и «Форсаж» — похожие актеры, похожий жанр, похожие теги, …). Однако данный способ не сможет порекомендовать сопутствующие объекты: сыр и вино. Еще одним недостатком этого способа является тот факт, что для разметки всех объектов, доступных на сервисе, требуется не мало усилий.
В то же время почти каждый сервис логирует информацию о том, какой пользователь просмотрел/купил/кликнул какой объект. Данной информации достаточно для построения НРС, которая позволит рекомендовать как похожие, так и сопутствующие объекты.
Под катом описан метод ассоциаций, позволяющий построить неперсонализированные рекомендации, основываясь лишь на данных о действиях над объектами. Там же код на Python, позволяющий применить метод для большого объема данных.
Построение неперсонализированных рекомендаций Для начала рассмотрим базовый алгоритм построения неперсонализированных рекомендаций. Предположим, что у нас есть объекты — фильмы и пользователи. Пользователи просматривают фильмы. Нашими исходными данными является разреженная матрица D (фильмы x пользователи). Если пользователь u просмотрел фильм f, то в соответствующей ячейке матрицы D стоит 1.Для того чтобы найти фильмы, похожие на заданный фильм f необходимо знать схожесть фильма f со всеми остальными фильмами. Данные о схожести хранятся в матрице S (фильмы x фильмы).
Базовый алгоритм построения неперсонализированных рекомендаций выглядит следующим образом:
для заданного фильма f найти соответствующую ему строку R в матрице S; выбрать из строки R множество наиболее похожих на f фильмов — FR; FR и есть непресонализированные рекомендации (похожие/сопутствующие). Метод схожести Из описанного видно, что рекомендации и их качество зависят только от способа построения матрицы S, а если быть точнее — от способа определения схожести двух фильмов.Как определить схожесть фильмов x и y, если их посмотрело множество пользователей X и Y соответственно? Наиболее простое решение — Коэффициент Жаккара, который вычисляет схожесть двух объектов (x и y) как:
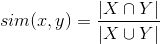
Здесь числитель — количество пользователей, просмотревших как фильм x, так и фильм y. Знаменатель — количество пользователей, которые просмотрели или фильм x или фильм y.
Вычисленное значение является симметричным: x похож на y также, как y похож на x. Если же мы хотим сделать коэффициент асимметричным, то можно поменять формулу на следующую:
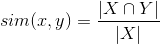
На первый взгляд данный метод является идеальным: он увеличивает значение схожести фильмам, которые смотрят вместе, и нормализует метрику относительно количества пользователей, которые просмотрели фильм.
«Проблема Гарри Поттера» или «банановая ловушка» Рассмотрим указанную выше формулу для случая, когда объект y очень популярен (например, фильм о Гарри Поттере). Так как фильм очень популярен и его смотрело много людей, то sim (x, y) будет стремиться к 1 почти для всех фильмов x. Это значит, что фильм y будет похож на все фильмы, а это в большинстве случаев плохо. Вряд ли «Гарри Поттер» будет похож на фильм «Зеленый слоник».«Проблему Гарри Поттера» также называют «банановой ловушкой»(banana trap). Предположим, что некоторый магазин пытается увеличить прибыль путем рекомендации покупателю товаров, которые часто берут вместе с тем, что покупатель собирается приобрести. Одним из наиболее покупаемых товаров в продуктовом магазине являются бананы. Используя формулу выше, система будет рекомендовать всем покупателям приобрести бананы. Бананы будут покупаться — все хорошо. Но это плохие рекомендации, так как бананы покупались бы и без рекомендаций. Рекомендуя бананы, мы уменьшаем прибыль как минимум на один удачно рекомендованный товар, отличный от бананов.
Метод ассоциаций Очевидно, что формулу надо модифицировать таким образом, чтобы объект x делал объект y более привлекательным. Т.е. нужно учитывать не только то, что объекты x и y берут вместе, но и то, что объект x не берут без y.Модифицируем формулу схожести следующим образом:
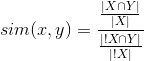
Если y — очень популярный объект, то знаменатель в формуле будет большим. Тогда значение схожести будет меньше, а рекомендации будут более релевантными. Данный метод называется методом ассоциаций.
Сравнение методов
Для сравнения работы метода ассоциаций и коэффициента Жаккара рассмотрим поиск похожих фильмов с использованием этих двух методов по следующим исходным данным.фильмы\пользователи
А B
C
D
E
1. Гарри Поттер и философский камень
1
1
1
1
1
2. Хоббит: Нежданное путешествие
1
1
1
3. Хоббит: Пустошь Смауга
1
1
1
4. Хроники Нарнии: Принц Каспиан
1
5. Сердце дракона
1
Матрица схожести, построенная с помощью асимметричного коэффициента Жаккара, выглядит следующим образом (диагональ зануляем, чтобы не рекомендовать исходный фильм): фильмы\фильмы
1
2
3
4
5
1
0
0,6
0,6
0,2
0,2
2
1
0
0,667
0
0,333
3
1
0,667
0
0
0
4
1
0
0
0
0
5
1
1
0
0
0
Матрица схожести для метода ассоциаций будет выглядеть следующим образом (помимо диагонали зануляем бесконечности — случаи, когда 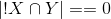 ).фильмы\фильмы
1
2
3
4
5
1
0
0
0
0
0
2
1,5
0
2
0
0
3
1,5
2
0
0
0
4
0,25
0
0
0
0
5
0,25
0,5
0
0
0
Как видно из матрицы схожести, метод ассоциаций позволяет учесть сверхпопулярность фильма «Гарри Поттер и философский камень». При построении рекомендаций методом ассоциаций для фильма «Хоббит: Нежданное путешествие» вес «Гарри Поттера» (1,5) будет меньше, чем вес более релевантного фильма «Хоббит: Пустошь Смауга» (2).Реализация
Ниже приведена функция для построения матрицы схожести на базе метода ассоциаций. Функция написана на Python с использованием scipy и scikit-learn. Данная реализация позволяет быстро и без особых затрат вычислить матрицу схожести для большого объема исходных данных.Так как в пределах одной строки матрицы значения |X| и |! X| не меняются, а схожие объекты будут находиться в пределах одной строки, то |X| и |! X| были опущены при вычислении метрики ассоциации. Конечная формула метрики выглядит так:
).фильмы\фильмы
1
2
3
4
5
1
0
0
0
0
0
2
1,5
0
2
0
0
3
1,5
2
0
0
0
4
0,25
0
0
0
0
5
0,25
0,5
0
0
0
Как видно из матрицы схожести, метод ассоциаций позволяет учесть сверхпопулярность фильма «Гарри Поттер и философский камень». При построении рекомендаций методом ассоциаций для фильма «Хоббит: Нежданное путешествие» вес «Гарри Поттера» (1,5) будет меньше, чем вес более релевантного фильма «Хоббит: Пустошь Смауга» (2).Реализация
Ниже приведена функция для построения матрицы схожести на базе метода ассоциаций. Функция написана на Python с использованием scipy и scikit-learn. Данная реализация позволяет быстро и без особых затрат вычислить матрицу схожести для большого объема исходных данных.Так как в пределах одной строки матрицы значения |X| и |! X| не меняются, а схожие объекты будут находиться в пределах одной строки, то |X| и |! X| были опущены при вычислении метрики ассоциации. Конечная формула метрики выглядит так:
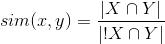
def get_item_item_association_matrix (sp_matrix): »«Простой способ построения матрицы ассоциаций : param sp_matrix: матрица с исходными данными о просмотрах (фильмы x пользователи) : return: матрица схожести фильмов (фильмы x фильмы) »« watched_x_and_y = sp_matrix.dot (sp_matrix.T).tocsr () watched_x = csr_matrix (sp_matrix.sum (axis=1)) magic = binarize (watched_x_and_y).multiply (watched_x.T) watched_not_x_and_y = magic — watched_x_and_y rows, cols = watched_not_x_and_y.nonzero () data_in_same_pos = watched_x_and_y[rows, cols].A.reshape (-1) return csr_matrix ((data_in_same_pos / watched_not_x_and_y.data, (rows, cols)), watched_x_and_y.shape) Заключение Метод ассоциаций является всего лишь одним из способов построения неперсонализированных рекомендаций. Как и для любого другого метода, перед его применением нужно решить ряд вопросов: — определить минимальное количество данных, при котором можно применять метод; — определить пороговое значение метрики ассоциации; — определить, что делать, если у рекомендованных объектов значение метрики ассоциации меньше порогового; — и т.д.
Из перечисленного следует, что метод ассоциаций может быть применен не для всех объектов. Поэтому его стоит комбинировать с одним или более методов построения неперсонализированных рекомендаций. Такой подход позволит создавать хорошие рекомендации независимо от количества данных о пользователе или объекте.
P.S. Удачных рекомендаций!
