Немного о производительности сетевого оборудования Cisco

В этом году мы опубликовали две статьи, связанные со сравнением функциональности маршрутизаторов и межсетевых экранов компании Cisco, а также с обзором разделения control и data plane в сетевом оборудовании. В комментариях к этим статьям был затронут вопрос производительности сетевого оборудования. А именно как зависит производительность маршрутизаторов Cisco разных поколений от включения на них тех или иных сервисов. Так же обсуждалась тема производительности межсетевых экранов Cisco ASA. В связи с этим возникло желание посмотреть на эти вопросы с практической стороны, подкрепив известные моменты цифрами. О том, что получилось и, что получилось не очень, расскажу под катом.
Под производительностью будем подразумевать пропускную способность устройства, измеряемую в Мбит/с. Стенд для тестирования представлял из себя два ноутбука, с установленной программой iPerf3. Методика испытания — достаточно проста. iPerf3 запускался в режиме передачи пакетов по протоколу TCP. Использовалось 5 потоков. Я не ставил перед собой цели определить реальную производительность устройств. Для этой задачи необходима более сложная экипировка, так как требуется воссоздавать паттерны трафика реальной сети. Да и мерить нужно было бы количество обрабатываемых пакетов. У нас же основной задачей была оценка влияния использования различных сервисов на работу устройства, а также сравнение результатов, полученных на различных устройствах. Таким образом, выбранный инструментарий на первый взгляд казался достаточно подходящим для поставленных задач.
Cisco Integrated Services Router (ISR) Generation 1 и 2
Для начала из коробки были взяты два младших маршрутизатора Cisco 871 и 881. Это маршрутизаторы разных поколений (871 более старый — G1, а 881 более новый — G2), которые обычно ставятся в небольшие офисы, например, в удалённые филиалы компании.
Исследуемые маршрутизаторы имеют сходные черты в плане программной и аппаратной архитектуры: операционная система — Cisco IOS, «мозг» устройств — SoC MPC 8272 в 871 и SoC MPC 8300 в 881.
Для каждого маршрутизатора проверялись следующие режимы работы:
- Маршрутизация с использованием технологии Cisco Express Forwarding (CEF).
- Маршрутизация без использования оптимизирующих технологий (Process Switching).
- Маршрутизация (CEF) и применённый список доступа (ACL) на одном из интерфейсов.
- Маршрутизация (CEF) и ACL на одном из интерфейсов с опцией log.
- Маршрутизация (CEF) и включённая служба трансляции адресов (NAT*).
- Маршрутизация (CEF) и включенные сервисы межсетевого экранирования (CBAC для 871 и ZPF для 881).
- Маршрутизация (CEF), МСЭ и NAT.
* При тестировании настраивался как статический, так и динамический NAT. Оба варианта показали примерно одинаковое влияния на производительность устройства.
Тестирование затрагивало маршрутизацию трафика (L3-коммутацию) на базе CEF и Process Switching. Оба режима работы на исследуемых устройствах являются программной обработкой пакетов. Разница в том, как именно маршрутизатор принимает решение куда отправить пакет. В случае Process Switching маршрутизатор для каждого пакета определяет, куда его передать и формирует/модифицирует необходимые заголовки в рамках отдельного процесса на основании таблицы маршрутизации и L2-таблиц. Происходит так называемая процессорная обработка. В случае CEF маршрутизатор использует заранее подготовленные специальным образом таблицы FIB (таблица префиксов) и Adjacency (таблица данных по соседям), которые позволяют существенно снизить нагрузку на ЦПУ и повысить скорость обработки пакета внутри устройства.
Для более наглядного сравнения данные по разным устройствам нанесены на один график (рисунок 1).
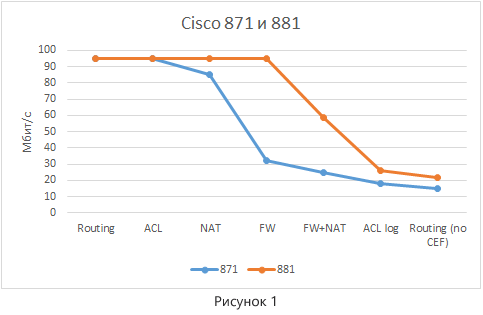
Отметим основные моменты:
- Так как интерфейсы на устройствах имеют тип FastEthernet, максимальная пропускная способность точка-точка, полученная через iPerf3, не превышала 95 Мбит/с. При этом загрузка ЦПУ для некоторых режимов тесетирования не достигала своих пиковых значений, а значит цифра 95 Мбит/с для этих маршрутизаторов не предел.
- Маршрутизатор 881 выглядит лучше, так как имеет более продвинутую аппаратную начинку (в первую очередь процессор общего назначения, далее ЦПУ).
- Как и следовало ожидать, мы видим заметную деградацию производительности при включении сервисов.
- При отключении CEF мы имеем существенное уменьшение производительности, так как маршрутизатор начинает обрабатывать каждый пакет не самым оптимальным образом.
- Включение опции log в ACL приводит к повышению нагрузки на устройство (загрузка ЦПУ в этом случае составляет 99%), что негативно сказывается на производительности. Обусловлено это тем фактом, что опция log заставляет маршрутизатор обрабатывать каждый пакет, попадающий в отмеченную строчку ACL, в режиме Process Switching, что существенно увеличивает нагрузку на процессор.
Предлагаю рассмотреть подробнее загрузку ЦПУ в случае маршрутизации в режиме CEF и Process Switching. Маршрутизация в режиме CEF:
Router881#sh processes cpu sorted
CPU utilization for five seconds: 47%/42%; one minute: 40%; five minutes: 35%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
89 143724 8597 16717 1.51% 1.42% 1.43% 0 COLLECT STAT COU
5 25792 638 40426 1.43% 0.29% 0.20% 0 Check heaps
97 45204 180099 250 0.63% 0.57% 0.47% 0 Ethernet Msec Ti
…
Общая загрузку ЦПУ составляет 47%. Из них 42% уходит на обработку прерываний, вызванных передачей пакетов. Прерывания при передаче пакетов бывают двух типов: прерывание получения и прерывание передачи пакета. Прерывание получения пакета инициируется интерфейсным процессором, когда пакет получен через интерфейс маршрутизатора и он готов к обработке. Получив такое прерывание ЦПУ прекращает обработку текущих процессов, и начинает выполнять обработку пакета. Так как включен режим CEF, ЦПУ принимает решение, куда передать пакет на основании таблиц CEF (FIB и Adjacency) во время прерывания. Т.е. ему не требуется отправлять пакет на процессорную обработку, а значит существенно экономятся процессорные мощности. В связи с этим на процессы в маршрутизаторе тратится лишь 5% загрузки ЦПУ. Прерывание отправки пакета передаётся на ЦПУ, когда пакет был отправлен интерфейсным процессором дальше по каналам связи. ЦПУ реагирует на это прерывание обновлением счётчиков и освобождением памяти, выделенной для хранения пакета. В плане вклада в общую загрузку устройства данное прерывание менее интересно.
Маршрутизация в режиме Process Switching:
Router881#sh processes cpu sorted
CPU utilization for five seconds: 99%/27%; one minute: 82%; five minutes: 48%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
129 98988 6013 16462 69.91% 55.95% 19.35% 0 IP Input
89 145568 9248 15740 1.11% 1.11% 1.33% 0 COLLECT STAT COU
97 45480 193804 234 0.23% 0.23% 0.35% 0 Ethernet Msec Ti
…
Теперь общая загрузка ЦПУ составляет 99%. Причём только 27% уходит на прерывания. Остальные 72% тратятся на выполнение процессов. Процесс IP Input забирает практически 70% процессорного времени. Именно этот процесс отвечает за процессорную обработку пакетов, т.е. тех пакетов, которые не могут быть обработаны во время прерывания (например, отключен CEF или в его таблицах нет нужной информации для передачи, пакеты адресованы непосредственно маршрутизатору или являются широковещательным трафиком и пр.). А так как в нашем примере отключены CEF и Fast Switching (об этом методе я не упоминал в силу его неактуальности), после того как к ЦПУ пришло прерывание получения пакета, ЦПУ отправляет пакет на процессорную обработку. Прерывание завершается и ЦПУ обрабатывает пакет непосредственно в рамках одного из своих процессов. Поэтому мы и видим такую утилизацию ЦПУ процессом IP Input.
Ещё интересно будет посмотреть на загрузку ЦПУ в случае ACL с опцией log.
Router881#sh processes cpu sorted
CPU utilization for five seconds: 99%/37%; one minute: 80%; five minutes: 52%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
129 297672 15360 19379 60.83% 48.79% 29.67% 0 IP Input
89 150496 10973 13715 0.72% 0.93% 1.22% 0 COLLECT STAT COU
97 46036 232697 197 0.16% 0.17% 0.21% 0 Ethernet Msec Ti
…
Опция log в ACL заставляет маршрутизатор каждый пакеты отправлять на процессорную обработку, признаком чего, как и в предыдущем примере, является высокая утилизация ЦПУ процессом IP Input.
Cisco ASA 5500
Давайте посмотрим теперь на такое устройство как межсетевой экран Cisco ASA 5505. Можно сказать, что ASA 5505 — это аналогичное маршрутизатору Cisco 881 устройство в плане позиционирования (для небольших офисов и филиалов). Эти устройства примерно из одного ценового сегмента и обладают относительно сходными аппаратными характеристиками. В ASA 5505 используется ЦПУ AMD Geode с тактовой частотой 500 MHz. Самое главное отличие –операционная система. В ASA 5505 используется ASA OS. Про различия между маршрутизаторами и ASA в плане функциональности мы говорили в отдельной статье. Посмотрим теперь на производительность ASA и влияния на неё различных сервисов.
Так как на ASA нет чистой маршрутизации и каких-то выделенных технологий оптимизации маршрутизации трафика, проверялись лишь следующие режимы работы:
- Межсетевой экран.
- Межсетевой экран и включённая служба трансляции адресов (NAT).
- Межсетевой экран и ACL на одном из интерфейсов с опцией log.
Для более наглядного сравнения данные по таким устройствам как ASA 5505 и маршрутизатор 881 нанесены на один график (рисунок 2).
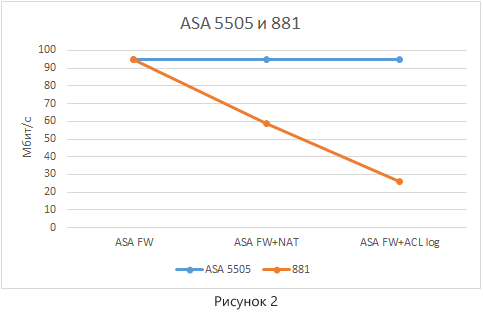
Из диаграммы видно, пропускная способность ASA 5505 во всех режимах работы ограничена лишь техническими аспектами стенда. Причём, если мы посмотрим на загрузку ЦПУ, то для всех вариантов она практически идентична:
cbs-asa-vpn# sh proc cpu-usage non-zero sorted
PC Thread 5Sec 1Min 5Min Process
0x082a2849 0xa86e0994 31.1% 25.4% 13.4% Dispatch Unit
0x09bcebdb 0xa86d094c 6.4% 5.1% 5.9% esw_stats
0x08e68295 0xa86ced10 0.2% 0.1% 0.2% ci/console
0x0919171d 0xa86c9404 0.2% 0.2% 0.2% IP SLA Mon Event Processor
0x08f0591c 0xa86ce68c 0.1% 0.1% 0.1% update_cpu_usage
Можно сделать следующие выводы:
- При относительно схожих ценовых и аппаратных параметрах ASA 5505 предоставляет большую производительность, чем маршрутизатор 881.
- Производительность ASA практически не зависит от сервисов (во всяком случае в рамках данного стенда её выявить не удалось).
- Опция логирования (log) в ACL не приводит к деградации производительности. Обусловлено этой спецификой реализаций функции маршрутизации в устройстве.
Таким образом, операционная система ASA OS кажется более сбалансированной в плане влияния сервисов на производительность устройства.
Cisco ISR 4000
Идём дальше. Предлагаю посмотреть, как обстоят дела с влиянием сервисов на производительность маршрутизаторов Cisco ISR 4000. Это самая новая линейка маршрутизаторов Cisco для небольших и средних инсталляций. Как мы помним, в этих маршрутизаторах используется операционная система Cisco IOS XE, которая умеет работать в многопоточном режиме. С точки зрения аппаратной начинки, в этих маршрутизаторах используются многоядерные процессоры.
И так достаём из коробки самый младший Cisco ISR 4000 — 4321. Активируем на нём performance license, чтобы получить заявленную максимальную производительность 100 Мбит/с, и начинаем тестировать. Важно отметить, что на маршрутизаторах ISR 4000 всегда используется шейпер, ограничивающий максимальную производительность устройства. Используется два порога: базовая (для 4321 — это 50 Мбит/с) и расширенная (для 4321 — это 100 Мбит/с; активируется лицензией performance license) производительности. Такая схема работы направлена на получение прогнозируемых значений производительности устройства, не позволяя «захлёбывать» от большого количества трафика.
Для начала проверяем производительность чистой маршрутизации в режиме CEF без дополнительных сервисов. Запускаем iPerf3 и получаем 95 Мбит/с. Ожидаемо. Смотрим в этот момент на загрузку ЦПУ:
cbs-rtr-4321#show proc cpu sorted
CPU utilization for five seconds: 1%/0%; one minute: 1%; five minutes: 1%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
658 8563421 409607083 20 0.47% 0.48% 0.48% 0 IP SLAs XOS Even
79 1123726 12408975 90 0.15% 0.06% 0.07% 0 IOSD ipc task
2 120745 326115 370 0.07% 0.00% 0.00% 0 Load Meter
667 420 1850 227 0.07% 0.03% 0.04% 2 SSH Process
…
Вот это результат! Загрузка ЦПУ 1%. Круто! Но не всё так идеально. Понимание данного феномена приходит после более детального изучения специфики работы IOS XE.
IOS XE — это операционная система, созданная на базе Linux«а, тщательно допиленного и оптимизированного вендором. Традиционная операционная система Cisco IOS запускается в виде отдельного Linux процесса (IOSd). Самое интересное заключается в том, что в IOS XE мы имеем отдельный основной процесс, выполняющий функции data plane. Т.е. мы имеем чёткое разделение control и data plane на программном уровне. Процесс, отвечающий за control plane, называется linux_iosd-imag. Это собственно и есть привычным нам IOS. Процесс, отвечающий за data plane, называется qfp-ucode-utah. QFP, знакомо? Сразу вспоминаем про сетевой процессор QuantumFlow Processor в маршрутизаторах ASR 1000. Так как изначально IOS XE появился именно на этих маршрутизаторах, процесс, отвечающий за передачу пакетов, получил аббревиатуру qfp в своём названии. В дальнейшем для ISR 4000, видимо, ничего менять не стали, с одной лишь разницей, что в ISR 4000 QFP является виртуальным (выполняется на отдельных ядрах процессора общего назначения). Кроме озвученных процессов в IOS XE присутствуют и другие вспомогательные процессы.
Таким образом, чтобы посмотреть на сколько загружены процессорные мощности, анализируем вывод следующих команд, специфичных для IOS XE:
cbs-rtr-4321#show platform software status control-processor brief
Load Average
Slot Status 1-Min 5-Min 15-Min
RP0 Healthy 1.14 1.05 1.01
Memory (kB)
Slot Status Total Used (Pct) Free (Pct) Committed (Pct)
RP0 Healthy 3950540 3888836 (98%) 61704 ( 2%) 2517892 (64%)
CPU Utilization
Slot CPU User System Nice Idle IRQ SIRQ IOwait
RP0 0 5.28 10.57 0.00 79.84 4.19 0.09 0.00
1 1.80 1.60 0.00 95.99 0.50 0.10 0.00
2 41.00 2.70 0.00 56.30 0.00 0.00 0.00
3 23.02 76.97 0.00 0.00 0.00 0.00 0.00
В нашем маршрутизаторе используется четыре ядра (CPU 0, 1, 2, и 3). Команда позволяет нам получить информацию по загрузке каждого из них.
Примечание
Увидеть аппаратную начинку маршрутизатора можно выводом стандартной для Linux информации из файла dmesg: more flash:/tracelogs/dmesg.
В маршрутизаторе ISR 4321 используется процессор:
CPU0: Intel® Atom™ CPU C2558 @ 2.40GHz stepping 08
Следующая команда позволяет нам увидеть утилизацию процессорных мощностей различными процессами:
cbs-rtr-4321#show platform software process slot RP active monitor cycles 1 interval 1 top - 15:03:45 up 18 days, 21:00, 0 users, load average: 1.13, 1.05, 1.01
Tasks: 316 total, 2 running, 314 sleeping, 0 stopped, 0 zombie
Cpu(s): 8.8%us, 22.3%sy, 0.0%ni, 68.8%id, 0.0%wa, 0.1%hi, 0.0%si, 0.0%st
Mem: 3950540k total, 3889372k used, 61168k free, 199752k buffers
Swap: 0k total, 0k used, 0k free, 1608388k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3111 root 20 0 1041m 589m 333m S 150 15.3 28747:48 qfp-ucode-utah
1915 root 20 0 1957m 182m 124m S 10 4.7 2216:08 fman_fp_image
22575 root 20 0 360m 74m 30m S 2 1.9 392:16.70 bsm
23130 root 20 0 46828 25m 11m S 2 0.7 23:08.43 cmand
26108 root 20 0 2378m 896m 374m S 2 23.2 881:05.01 linux_iosd-imag
27088 root 20 0 2204 1096 728 R 2 0.0 0:00.02 top
1 root 20 0 1820 520 440 S 0 0.0 0:10.97 init
2 root 20 0 0 0 0 S 0 0.0 0:00.00 kthreadd
…
В данном примере, IOS съедает всего 2%, а QFP — 150% (что эквивалентно утилизации одно ядра полностью и ещё одного на половину).
Так, что же в итоге показывает тогда команда «show processes cpu»? Она выводит загрузку виртуального ЦПУ, который был выделен процессу IOSd. Под данный процесс на маршрутизаторах ISR 4000 выделяется одно из ядер ЦПУ.
Из всего этого можно сделать вывод, что в IOS XE архитектура обработки пакетов существенно изменилась по сравнению с обычным IOS. IOS больше не занимается обработкой абсолютно всех пакетов. Данным процессом обрабатываются лишь те пакеты, которые требуют процессорной обработки. Но даже в этом случае в IOS XE используется более новый механизм Fastpath, который реализует передачу пакетов для процессорной обработки посредствам отдельного потока внутри IOSd, а не через прерывания. Прерывания в IOSd возникают только, когда не возможна обработка через Fastpath.
Вернёмся к нашей задаче. Проверим следующие режимы работы:
- Маршрутизация с использованием технологии CEF.
- Маршрутизация и применённый список доступа (ACL) на одном из интерфейсов.
- Маршрутизация (CEF) и ACL на одном из интерфейсов с опцией log.
- Маршрутизация (CEF) и включённая служба трансляции адресов NAT.
- Маршрутизация (CEF) и включенные сервисы межсетевого экранирования (ZPF).
- Маршрутизация (CEF), МСЭ и NAT.
Необходимо отметить, что отключить CEF на 4321 (да и на всей линейке ISR 4000) нельзя. Теперь это базовая технология маршрутизации.
Результаты тестирования представлены на рисунке 3. Для большей наглядности на один график нанесены значения пропускной способности (а они у нас во всех случаях одинаковы) и загрузку ЦПУ процессом QFP. Процесс IOSd не интересен в силу того, что во всех режимах загрузка виртуального ЦПУ внутри IOSd минимальна — 1%.
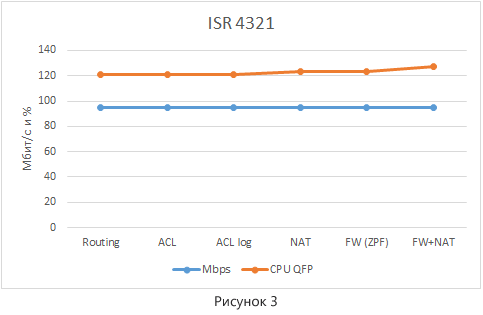
При проведении тестирования выявить зависимость производительности маршрутизатора ISR 4321 от включения сервисов не удалось. Есть небольшое повышение загрузки CPU, но совсем незначительное. Также стоит отметить, что включение опции log в ACL больше не приводит к драматическим потерям в производительности, так как пакет не отправляется на процессорную обработку.
Итоги
На примере нескольких устройств разных поколений и типов мы попытались рассмотреть, как зависит производительность от включения различных сервисов. В целом полученные результаты укладываются в ранее известные факты. Америки мы не открыли. Краткие выводы, полученные в результате тестирования, можно сформулировать так:
- Происходит существенная деградация производительности маршрутизаторов ISR G1 и G2 при включении сервисов.
- Производительность ASA менее подвержена влиянию сервисов. При сравнимой цене с маршрутизатором мы получаем большую производительность.
- Влияние включения сервисов на производительность ISR 4000 минимальна.
Спасибо за внимание. Надеюсь, что какая-то информация из статьи поможет в работе с оборудованием Cisco.
