Нейросетевое генеративное искусство: как программисту стать художником

Наверняка на Хабре есть люди, уже глубоко изучившие генерацию картинок с помощью нейросетей. Но много и тех, кто ещё не разбирался, почему у Stable Diffusion в названии есть слово «диффузия» и чем разновидности нейросетей различаются.
Для тех, кто не готов забираться в глубокие дебри, но хочет в один присест наверстать всё главное, может быть полезен доклад Дмитрия Сошникова @shwars с нашего мероприятия TechTrain. Поэтому мы сделали для Хабра текстовую расшифровку (видеозапись также прилагаем).
Докладу всего полгода, но за это время нейросети успели развиться ещё сильнее. Так что, если тема вам интересна, заодно порекомендуем и наш следующий TechTrain, который пройдёт уже завтра (1 апреля): там будет целый ряд докладов про AI, в том числе новый от Дмитрия. Участие бесплатно.
Далее повествование идёт от лица Дмитрия.
Магия программирования и генеративное искусство
Я очень люблю компьютерное искусство, это новый способ выразить себя. Когда смотришь на картины, думаешь: «Хорошо людям — они могут своё воображение представлять на холсте. Мне бы тоже так». И оказывается, что, будучи программистом, тоже можно рисовать.

То, что вы видите сейчас, нарисовано нейросетью. А всего лишь год назад было сложно себе представить, что внутри компьютера в результате процесса умножения больших матриц будут получаться рисунки в ответ на текстовый запрос. Это ощущается как магия. Как говорил фантаст Артур Кларк: «Любая достаточно продвинутая технология неотличима от магии».
И магия сопровождает программирование на каждом шаге. Можно написать простую программу, которая сможет генерировать сколь угодно сложные объекты:

Это так называемая снежинка Коха: фрактал, который потенциально может бесконечно детализироваться (достаточно указать, какой уровень детализации мы хотим). Магия программирования в том, что небольшие конечные объекты способны генерировать потенциально бесконечную сложность.
На этом основаны художественные приёмы. Есть целое направление компьютерного генеративного искусства, где стандартом является язык Processing — модифицированная версия Java с рисовательными примитивами. Могу рекомендовать книгу «Generative Art: A Practical Guide Using Processing» Мэтта Пирсона.
С этим связан интересный сайт openprocessing.org, где собраны работы разных людей. Давайте посмотрим на одну из них. На первый взгляд, здесь рисуются случайные кривые, но потом они складываются в фотографию:

На OpenProcessing можно заглянуть в код любой работы, можно сделать свой форк. В этой работе код — всего лишь два небольших файла на Processing.
Один из них выглядит так
var imgs = [];
var imgIndex = -1;
var img;
var paint;
var subStep = 800;
var z = 0;
var isStop = false;
var count = 0;
function preload() {
imgs[0] = loadImage("test1.png");
imgs[1] = loadImage("test2.png");
imgs[2] = loadImage("test3.png");
}
function setup() {
if(windowWidth < 600)
createCanvas(windowWidth, windowWidth);
else
createCanvas(600, 600);
img = createImage(width, height);
nextImage();
paint = new Paint(createVector(width/2, height/2));
background(255, 255, 255);
colorMode(RGB, 255, 255, 255, 255);
}
function draw() {
//console.log(frameRate());
if (!isStop) {
for (var i = 0 ; i < subStep ; i++) {
paint.update();
paint.show();
z+= 0.01;
}
}
count++;
if (count > width) {
isStop = true;
}
//background(255);
//image(img, 0, 0, width, height);
}
function fget(i, j) {
var index = j * img.width + i;
index *= 4;
return color(img.pixels[index], img.pixels[index+1], img.pixels[index+2], img.pixels[index+3]);
}
function fset(i, j, c) {
var index = j * img.width + i;
index *= 4;
img.pixels[index] = red(c);
img.pixels[index+1] = green(c);
img.pixels[index+2] = blue(c);
img.pixels[index+3] = alpha(c);
}
function keyPressed() {
console.log(key);
if (key === 's' || key === 'S') {
isStop = !isStop;
}
}
function mouseClicked() {
nextImage();
isStop = false;
count = 0;
}
function touchStarted() {
nextImage();
isStop = false;
count = 0;
}
function nextImage() {
if (!img) return;
imgIndex = (++imgIndex) % imgs.length;
var targetImg = imgs[imgIndex];
img.copy(targetImg, 0, 0, targetImg.width, targetImg.height, 0, 0, img.width, img.height);
//img.resize(width, height);
img.loadPixels();
clear();
}
Тут мы пишем код, который делает что-то красивое, и человек целиком выступает в роли автора, а компьютер — просто исполнитель.
Но существуют также искусственный интеллект и машинное обучение. Можно «накормить» компьютер картинами, например, из сборника художественных работ WikiArt, и пусть он сам научится рисовать.

Искусственный интеллект можно использовать в генеративном искусстве двумя способами. Первый подход — просто использовать возможности искусственного интеллекта, чтобы реализовать идею человека. Второй — натренировав искусственный интеллект на картинах, начать воспринимать его как соавтора.
Пример первого подхода — когнитивный портрет. Мы берем фотографии людей и накладываем их друг на друга автоматически таким образом, что определенные части лица совпадают:

Глаза и рот — опорные точки лица. Мы хотим сделать так, чтобы они совпали, и получился бы усредненный портрет. О том, как это сделать, я ранее рассказывал своём блоге.
Ещё я сделал картину, которая называется «Взросление»:

Я взял фотоархив, с помощью автоматического распознавания лиц вычленил фотографии своей дочери и разложил их по возрасту в пять разных кучек. И склеил так, что детская фотография перетекает в более взрослую. О «Взрослении» у меня тоже есть отдельный пост. А ещё есть видео взросления.
Как научить ИИ рисовать самостоятельно?
Чтобы ответить на этот вопрос, сначала нужно разобраться, как работают нейросети.
Нейросеть — подобие того, как работает наш мозг. У неё есть искусственные нейроны, которые суммируют сигналы со своих входов и передают на выход. На следующем уровне сигнал из предыдущих слоев нейронов опять суммируется и передается на выход. В итоге получается нужный нам результат.
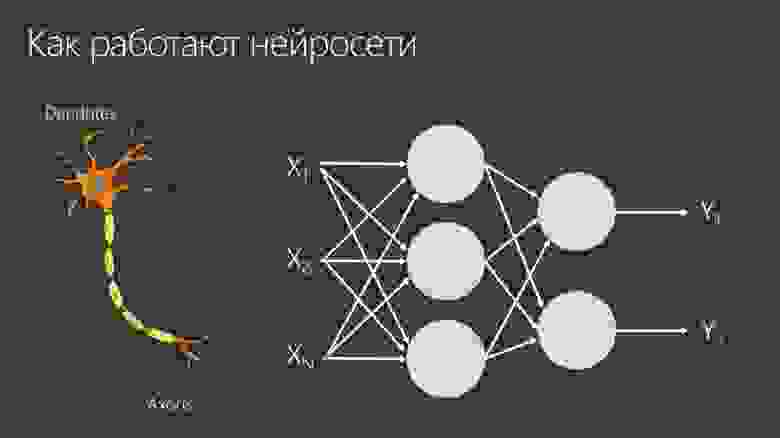
Например, если я хочу научиться отличать кошку от собаки на фотографии, то мне нужно на вход подать изображение этой кошки. Каждый пиксель на фотографии будет входом в нейронную сеть. Если у меня есть картинка размером 100 на 100 пикселей, то это значит, что будет 10 000 входных нейронов. Будет два выхода — «кошка» или «собака». Если это кошка, то выход должен быть 1–0, а если это собака, то 0–1. Мы будем показывать нейросети много картинок и ожидать, что она научится распознавать их правильно.

Здесь есть проблема. В реальной жизни кошка может оказаться не в середине, а в углу фотографии. Поскольку каждый пиксель жестко привязан к какому-то нейрону, то оказывается, что идею кошки такой нейросети очень сложно ухватить. Ей нужно подстраиваться под возможность наличия кошки в каждом месте изображения. Но когда человек смотрит на картинку — он сканирует ее и ищет типичные признаки. Нужно, чтобы нейросети действовали примерно так же.
Свёрточные сети
Есть архитектура «свёрточные сети» (convolutional neural networks, CNN). Они устроены таким образом: сеть «бежит» по изображению фильтром — матрицей, которую мы умножаем на локальную окрестность.
Если мы возьмем такую матрицу, где один столбец яркий, другой столбец — наоборот, тёмный, и мы будем умножать это на картинку, то все вертикальные штрихи на картинке будут усиливаться. Это устроено так: если есть какая-то граница, то одна её часть умножается на что-то большое, вторая — на что-то маленькое. И получается большой отклик.
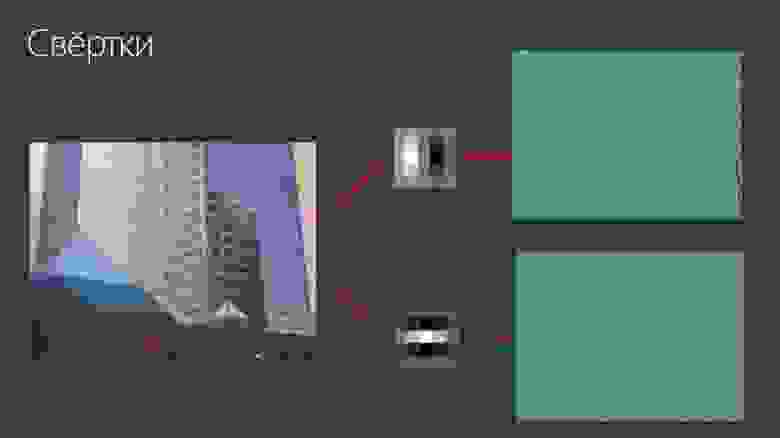
А если мы, например, возьмем горизонтальную матрицу, то будут фиксироваться горизонтальные штрихи. Возьмем наклонную матрицу — будут фиксироваться наклонные. На основе этого и работают архитектуры нейронных сетей.
Так же устроено зрение простейших насекомых. Биологи обнаружили, что в их глазах есть фильтры, которые выглядят, как разные наклонные объекты, из которых формируется первый уровень понимания действительности.

Из этих штрихов мы можем комбинировать более сложные объекты, например, глаза. А на следующем уровне комбинировать из этих кусочков сами лица. Каждый уровень нейронной сети может обнаруживать какие-то паттерны.
Применив это иерархически, мы учимся выхватывать из изображения нужные нам вещи и узнавать объекты.

А как генерировать? Автоэнкодер
Мы подавали на вход изображение, применяли иерархическое вычленение признаков и получали на выходе некоторый вектор чисел. Этот вектор описывает всё, что было в фотографии. И поверх него мы можем обучить классификатор, который будет говорить нам, кошка это или собака, картина или фотография.
Но пока что мы ничего не генерируем. А как же обучить нейросеть генерировать изображения?
Простейшая идея — сделать сеть, которая называется «автоэнкодер». Мы подаём ей на вход изображение и на выходе просим восстановить такое же:

По сути, нейросеть сталкивается с задачей сжатия информации: сначала ей надо сжать изображение в вектор, а затем из него восстановить исходное изображение. Для этого ей нужно внутри признаков в свёртке запоминать какие-то паттерны.
Как это происходит? Представьте, что вам нужно воссоздать картину по минимуму информации. Например, вы с другом договорились: он смотрит на картину, говорит вам какое-то количество информации, а вы потом должны эту картину нарисовать. Если он говорит одно слово («портрет»), то вы нарисуете что-то не очень похожее на оригинал. Если скажет «портрет женщины», вы нарисуете чуть более похожую вещь. А по описанию «портрет женщины с белыми волосами, сидящей за столом и держащей перед собой компьютер» вы нарисуете что-то, ещё более похожее на оригинал — руководствуясь своим пониманием того, что такое женщина, компьютер и белые волосы.
Когда тренируют автоэнкодер, ожидают, что нейросеть тоже научится запоминать эти вещи внутри себя. Она будет называть их словами: это будут паттерны, которые она будет выдавать в ответ на определенные значения вектора. Такой автоэнкодер достаточно часто используется на практике, но в чистом виде для генерации он работает не очень хорошо. Как выглядела бы такая генерация: мы бы отрезали начало и использовали только вторую часть свёртки. На вход мы бы подавали случайные вектора и смотрели бы, что получается.
Нужно очень сильно постараться, чтобы подать автоэнкодеру на вход вектор, генерирующий что-то красивое. Обычно получается случайное сочетание образов, далёкое от реальности, как сон — настолько странное, что в этом сложно увидеть что-то «хорошее».
Решаем проблему случайного вектора
Существует более интересная архитектура — генеративно-состязательные сети (generative adversarial networks, GAN). У них тоже есть генератор, очень похожий на вторую часть автоэнкодера: мы подаем на вход случайный вектор, а на выходе генерируется изображение.
Но есть и другая сеть, дискриминатор. Ей мы подаём на вход не только сгенерированное изображение, но и настоящее. Задача дискриминатора — суметь отличить сгенерированное.

В результате две сети учатся совместно. В самом начале генератор создаёт мусор, и дискриминатору очень просто: он легко отличает мусор от настоящего изображения.
Дальше мы говорим: «Раз дискриминатор определил, что вот эта картина — хорошая, давай дальше обучаться на ней». Нейросети ведь обучаются алгоритмом обратного распространения. Тогда генератор начинает создавать что-то более похожее на то, что нам нужно, и улучшается. Он улучшается настолько, что дискриминатор перестает отличать одно от другого. Значит, теперь нам нужно дообучать уже дискриминатор. И мы учим их по очереди, пока не получится так, что генератор научается создавать что-то действительно подходящее.
Вроде бы это хороший способ, но на практике работает не всегда. Вот пример того, что нейросеть считает хорошими картинами, хотя человек назовёт хорошим пейзажем только то, что справа:

Поэтому, чтобы получить какой-то интересный результат, нам обязательно нужно участие человека.
Искусство или нет?
Если, мы обучили нейросеть, и она способна по любому случайному вектору генерировать какую-то картину, считать ли это искусством? Можно подискутировать в комментариях, но пока что вброшу такую метрику: был прецедент, когда картина, сгенерированная искусственным интеллектом, была продана на аукционе за 432 с половиной тысячи долларов.
Группа энтузиастов взяла код и смогла продать результат. Исходный автор кода ничего не получил, и разыгралась не очень красивая история. Но нам важно другое — есть прецедент. Раз за это готовы платить как за искусство, значит, наверное, это искусство?

Как научить рисовать ребенка
Когда ребенок учится рисовать, он смотрит на реальный мир, учится воспроизводить что-то похожее. Потом ему показывают разные картины художников — он смотрит на технику, учится воспроизводить отдельные элементы… И нейросеть делает похоже:


Конечно, она делает чуть хуже. Но она «понимает», что на картине есть характерный для холста узор, какие элементы нужны для изображения человека (например, глаза), какова примерная композиция портрета.
Можно в таймлапсе посмотреть, как такая нейросеть училась — процесс занял 11 часов. Её просят что-нибудь сгенерировать, и в начале получается не очень хорошо, но чем дальше она учится — тем получается что-то более похожее на изображение. Справа — цветы, слева — портрет.
Для портрета нейросети очень сложно нащупать правильное размещение всех фрагментов — например, то, что у человека два глаза, и они обязательно на голове. Это неочевидные факты, которые она долго-долго пытается понять, но в конечном итоге, пытаясь нарисовать какое-то лицо с тремя глазами, она все-таки понимает, что, наверное, должно быть два глаза, и учится этот паттерн отличать.
Называем то, что нарисовали
Человек, помимо чисто визуальных паттернов, знает языковые паттерны. Он называет портрет портретом. Поэтому, чтобы хорошо рисовать, нам важно скрестить возможности по пониманию текста и созданию изображения.
Для естественного языка тоже есть нейросети. Это направление стало очень бурно развиваться в 2018–2019 годах, стали обучать генеративные модели. Сначала использовали так называемые рекуррентные сети, которые предсказывают по нескольким предыдущим словам следующее.
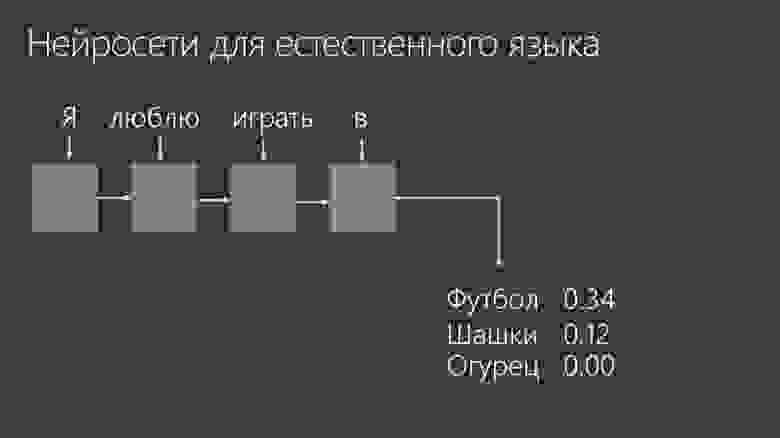
Например, мы говорим: «Я люблю играть в…». Эти слова известны, а нужно предсказать, какое слово будет следующим. Например футбол — с вероятностью 0,34, шашки — уже 0,12, а огурец — 0. Потому что играть в огурец не принято.
Мы даем нейросети большие массивы текстов, и получаем авторегрессионные модели, которые предсказывают следующее слово.
Несколько лет назад в Microsoft мы делали небольшую выставку в рамках одной из конференций, где показывали, как нейросеть учится рисовать картины и генерировать текст. Обучали по буквам генерировать сказки. В начале нейросеть не очень понимает, что нужно, дальше она начинает видеть какие-то паттерны, слоги, из них складывать слова, и в конечном итоге получается уже более осмысленный текст:

Эта сеть обучалась несколько часов на персональном компьютере. Но если потратить несколько месяцев и миллионы или миллиарды долларов, то удаётся обучить существенно более серьезные модели. Модель под названием GPT-3 оказалась способна генерировать очень разумный текст. В примере белый текст — то, что написал человек.

Дальше мы просим нейросеть сказать, а что же могли обнаружить ученые. И сеть пишет текст, по стилистике типичный для газетной статьи, с цитатами и статистикой.
А если бы мы в начале делали затравку, например в виде стихов, то на выходе мы бы получали тоже стихи. Вот пример, где использовалась модель Yandex YaLM:

Здесь желтое — то, что человек написал или вручную подправил. Остальное — то, что способна сгенерировать нейросеть. В таком стихе есть даже какой-то смысл. Хотя он пока что не выходит за рамки того, что мог бы написать десятилетний ребенок.
Удивительно, что всё происходит путем умножения чисел внутри компьютера. Компьютер, безусловно, не понимает, что он делает, и не испытывает по этому поводу эмоций. Он просто умножает числа, эти числа потом складываются в слова, и на выходе получается что-то осмысленное. В этом есть магия и чудо.
В 2020 году я на «ЛитРес: Самиздате» выпустил книжку с короткими рассказами, написанными совместно с нейросетью. Она называется «Жизнеописание Сергея Сергеевича в рассказах, правдивых и не очень». Также недавно в продажу вышла книга «Нейро Пепперштейн», написанная сетью, которую обучили стилю конкретного писателя. В ней — рассказы и самого Павла Пепперштейна, и написанные нейросетью.
Мультимодальные модели
Понимание текста — одна возможность, генерировать изображение — другая. Интереснее всего их совмещать. Получаются мультимодальные модели: мы хотим научить компьютер тоже называть картинки словами.
Существенным достижением был выпуск модели под названием CLIP от OpenAI. Она обучалась на парах «картинка и подпись к этой картинке».
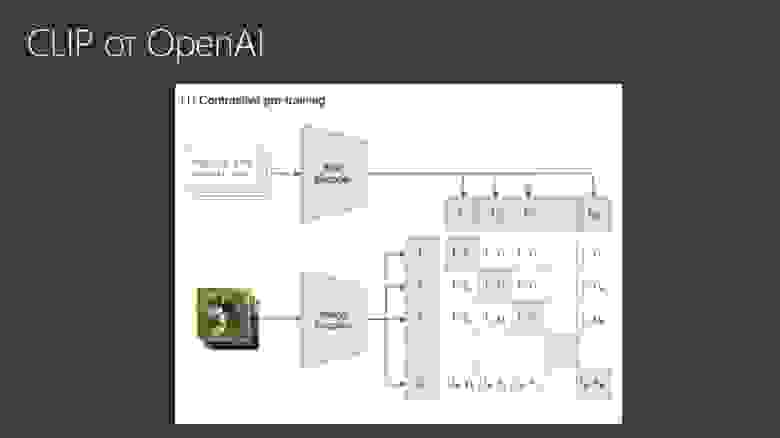
Например, ей дают картинку собачки, и пишут, что это щенок. И дальше эта модель обучается. Сначала с помощью нейросети мы кодируем текст в некоторый вектор для каждого из входных фрагментов. Затем кодируем картинку в вектор с помощью энкодера.
Дальше мы подстраиваем нейросеть таким образом, чтобы для картинки, которая соответствует подписи, расстояние междувекторами было минимальным. А для неправильных картинок — тех, которые сопоставлены с неправильной подписью — наоборот максимальным.
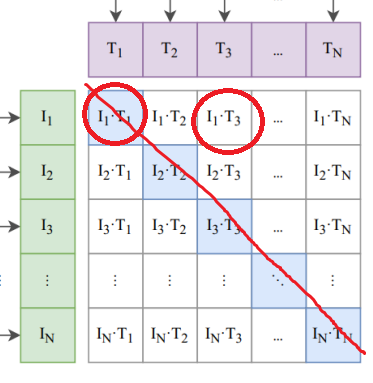
Так мы обучаем энкодер и декодер генерировать векторы, которые для одинаковых картинок и одинаковых подписей имеют близкое расстояние между собой. По расстоянию между векторами мы можем сравнивать, насколько картинка соответствует текстовому описанию. Это и есть то, что делает CLIP: ей можно дать текст и картинку, и на выходе понять, насколько они между собой близки.
Это открыло возможности для генеративных моделей нового уровня. Архитектура VQGAN + CLIP, оказавшаяся популярной год назад, использует некоторую генеративную сеть, похожую на автоэнкодер (его вторую часть).
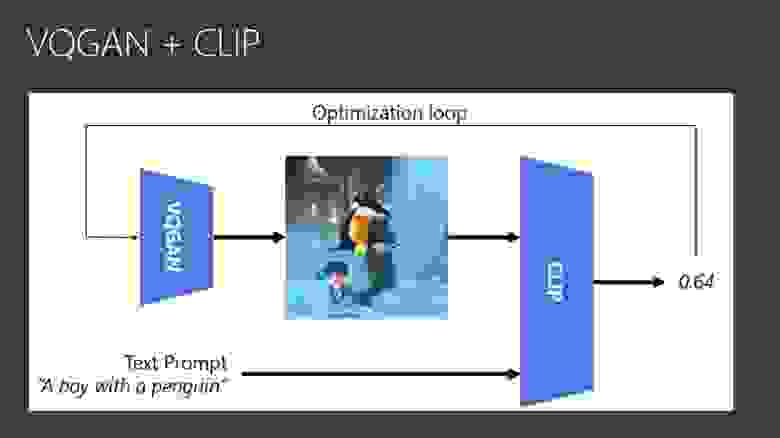
Задача этой сети — подобрать правильный входной вектор, чтобы картинка была осмысленной. Мы подаем на вход случайный вектор, на выходе получается непонятно что. Этот результат мы подаем на вход CLIP«у и сравниваем с текстовым описанием.
Например, мы хотим получить картинку «Мальчик с пингвином». CLIP говорит: «это не очень похоже». Этот результат дальше используем для оптимизации — отправляем его обратно в VQGAN, чтобы изменить вектор на более подходящий.
Мы действуем итерационно, подгоняя входной вектор, чтобы картинка всё больше и больше подходила на текстовое описание.
Это дает хорошие результаты. Например, по запросу «импрессионистская картина молодой женщины» — получаются вот такие вот картины.

Мы можем использовать разные генераторы, а CLIP выступает в роли дискриминатора, который смотрит, насколько картинка похожа на то, что нам нужно.
Год назад ко дню учителя я делал коллекцию учителей, сгенерированных с помощью VQGAN + CLIP. Получались такие картины.

Они говорят о том, что нейросеть «понимает», чем учитель математики отличается от учителя географии.
Другой проект: мы использовали нейросеть для того, чтобы получить описание существующей картины, и по этому описанию сгенерировать что-то другое. Это как «испорченный телефон»: один человек смотрит на картину, пытается ее описать, а другой рисует по описанию.

Относительно недавно OpenAI представила свою модель под названием DALL-E 2, а Google — свою Imagen. И они могут генерировать довольно фотореалистичные изображения по текстовому описанию.

Вот еще пример котика, сидящего на окне на фоне большого города, сгенерированного с помощью русскоязычной модели ruDALL-E, выпущенной в «свободное обращение» командой Сбера.
Чтобы попробовать это самостоятельно, вы можете зайти на сайт ruDALL-E или craiyon.com. Это урезанная версия DALL-E 2, в которой вы можете ввести описание на английском языке и сгенерировать изображение.
Диффузные модели
Шокирующим событием, которое потрясло весь мир генеративного искусства, был выпуск модели Stable Diffusion в открытый доступ. В отличие от других закрытых моделей, вы можете не просто использовать эту через веб-интерфейс, а скачать её веса и самостоятельно начать генерировать изображения, которые будут похожи на настоящие картины.
Если вы поэкспериментируете со Stable Diffusion, вы поймете, что нейросеть знает в лицо многих актеров, знает различные техники различных художников… Датасет, на котором она обучалась, действительно большой.

Как такие модели работают и почему Stable Diffusion так называется? Дело в том, что они основаны на принципе диффузии. Если у нас есть изображение и мы начнём перемешивать его пиксели, то постепенно придём к «шуму». Этот процесс перемешивания называется диффузией.
Мы можем обучать нейронную модель обратной диффузии — по шуму восстанавливать смысл. Как если бы человеку показали размытую картину за стеклом и сказали: «Что там нарисовано?»

Человек сказал бы: «Эйфелева башня». Потому что он знает, как выглядит Эйфелева башня. Можно обучать нейросеть делать то же самое. Но делать это в пространстве пикселей оказывается слишком сложно — их слишком много.
Поэтому Stable Diffusion использует идею латентной диффузии. Сначала с помощью автоэнкодера мы переходим в пространство векторов меньшей размерности, и уже в нём совершаем процесс диффузии. А затем — процесс обратной диффузии, управляемый с помощью текста.
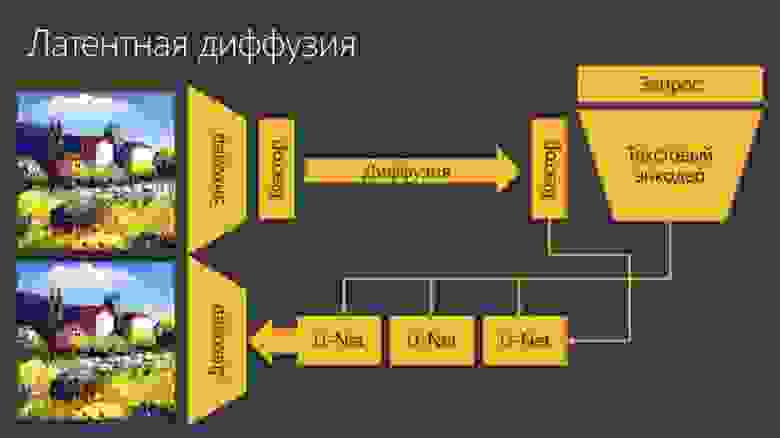
Когда мы даем текстовый запрос для процесса обратной диффузии — мы делаем так, чтобы ответ был похож на этот текстовый запрос — с помощью сети, которая похожа по архитектуре на CLIP.
В итоге мы получаем вектор в так называемом латентном пространстве и с помощью декодера декодируем его в финальное изображение.
Нам не нужно понимать мельчайшие детали, чтобы сгенерировать картину. Мы можем сначала сгенерировать некоторый вектор, а декодер восстановит все детали.
Примерно так устроены такие модели, и результаты у них совершенно другие. Вот проект, который я сделал на день учителя в этом году. На сайте http://teachers.experient.art можно посмотреть на то, как Stable Diffusion видит себе различных учителей.

Что почитать и как попробовать
У меня в блоге есть статья, в которой я описываю особенности нейрогенеративных моделей и их влияние на будущее искусства. А также ещё одна, в которой непосредственно говорится про то, как сгенерировать изображение.
Как попробовать самостоятельно? Для «питонистов» есть Jupyter Notebook и Google Colab. Вы можете скачать исходники и поэкспериментировать:
Если вы хотите показать это кому-то, кто не понимает, что такое Google Colab и Python, есть инструмент beta.dreamstudio.ai. Они дают сгенерировать бесплатно какое-то количество изображений.
Еще есть инструмент neural.love, который тоже пытаются монетизировать, но некоторые простые изображения там тоже можно генерировать бесплатно.
Выводы
Искусственный интеллект — эффективный инструмент для творчества. Его можно использовать для простых задач: например, извлечь опорные точки. Но он может и сам делать значительную часть работы.
Однако он не придумает идею. Именно человеку хочется что-то выразить — либо рисуя самостоятельно, либо с помощью Stable Diffusion получая результаты и отбирая из них лучшее. Вклад человека всегда очень велик. Не надо считать, что компьютер рисует всё сам и заменит художника.
Еще один важный момент: искусственный интеллект способен привнести случайность. Когда я попробовал писать книгу совместно с искусственным интеллектом, я испытал примерно такое же чувство, как когда мы в детстве с моим приятелем писали книжку по очереди. Ты написал какую-то часть, и ждешь —, а что же другой человек напишет. Он же наверняка что-то оригинальное придумает. Это очень приятное чувство, и с искусственным интеллектом ты ощущаешь примерно то же самое. Он придумывает что-то интересное, а человек подстраивает это под свою исходную идею.
Что дальше?
Дмитрий выступил с этим докладом в октябре. Казалось бы, прошло всего несколько месяцев. Но нейросети уже успели сделать шаг вперед — GPT-4 генерирует текст не на уровне 10-летнего ребенка, а пишет дипломы за студентов (кстати, вот ещё одна статья Дмитрия про GPT в образовании) и код за разработчиков, а генерацию изображений начали использовать в реальных продуктах. Например, недавно вышло дополнение к популярной настолке «Имаджинариум», созданное с помощью нейросети. Люди осваивают искусство промптинга — при правильном запросе нейросеть результаты, не отличающиеся от работ digital-художников. Для таких запросов уже существуют специальные каталоги.

А вот так по мнению нейросети выглядит TechTrain — наш бесплатный IT-фестиваль. Он пройдет 1 апреля и будет посвящен роли искусственного интеллекта в разработке и жизни. Обсудим и машинное обучение в целом, и конкретные технологии. А также снова попробуем ответить на вопрос, как ИИ изменит нашу жизнь еще через полгода. Переходите по ссылке, чтобы участвовать.
