Нейросеть Google Translate составила единую базу смыслов человеческих слов
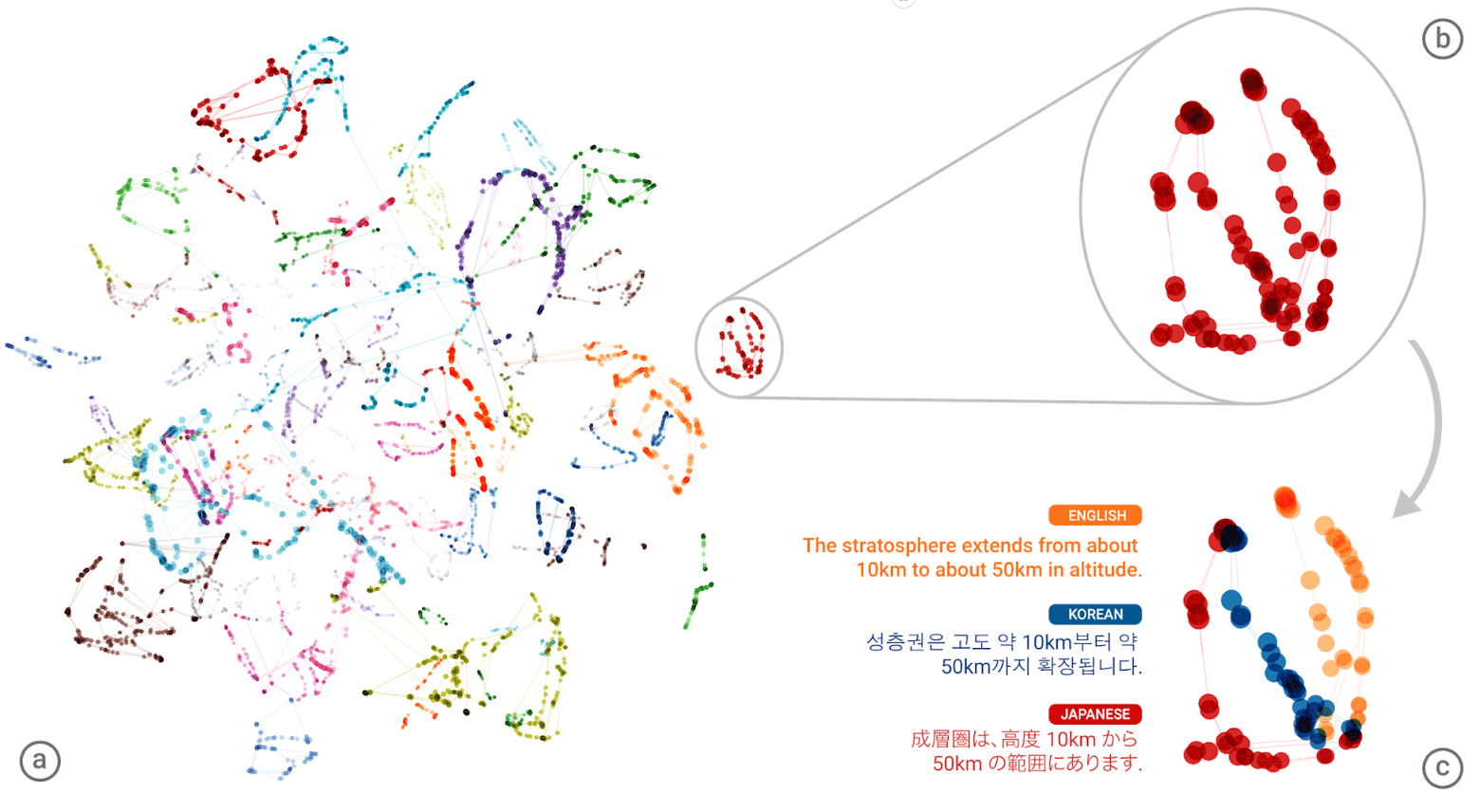
«Универсальный язык» нейронной сети Google Neural Machine Translation (GNMT). На левой иллюстрации разными цветами показаны кластеры значений каждого слова, справа внизу — смыслы слова, полученные для него от из разных человеческих языков: английского, корейского и японского
За последние десять лет система автоматического перевода текстов Google Translate выросла с нескольких языков до 103, а сейчас она переводит 140 млрд слов ежедневно. В сентябре сообщалось, что разработчики приняли решение полностью перевести сервис Google Translate на глубинное обучение. У этого подхода есть много преимуществ. Перевод становится гораздо лучше. Более того, система может переводить тексты на языки, для которых никогда не видела переводов, то есть не обучалась специально для этой языковой пары.
Нейросеть Google для машинного перевода называется Google Neural Machine Translation (GNMT). От самого начала и до конца перевод текста теперь полностью выполняет нейросеть. Традиционно ИИ использовался в Google Translate в ограниченном режиме, для некоторых вспомогательных задач. Например, для сравнения текстов, доступных на нескольких языках, вроде официальных документов ООН или Европарламента. В таком режиме сравнивался перевод каждого слова в текстах.
Нейросеть NMTS работает на принципиально новом уровне. Она не только анализирует существующие варианты перевода в процессе обучения, но и выполняет интеллектуальный анализ предложений, разбивая их на «словарные сегменты». В определённой репрезентации внутри сети эти «словарные сегменты» соответствуют смыслам слов.
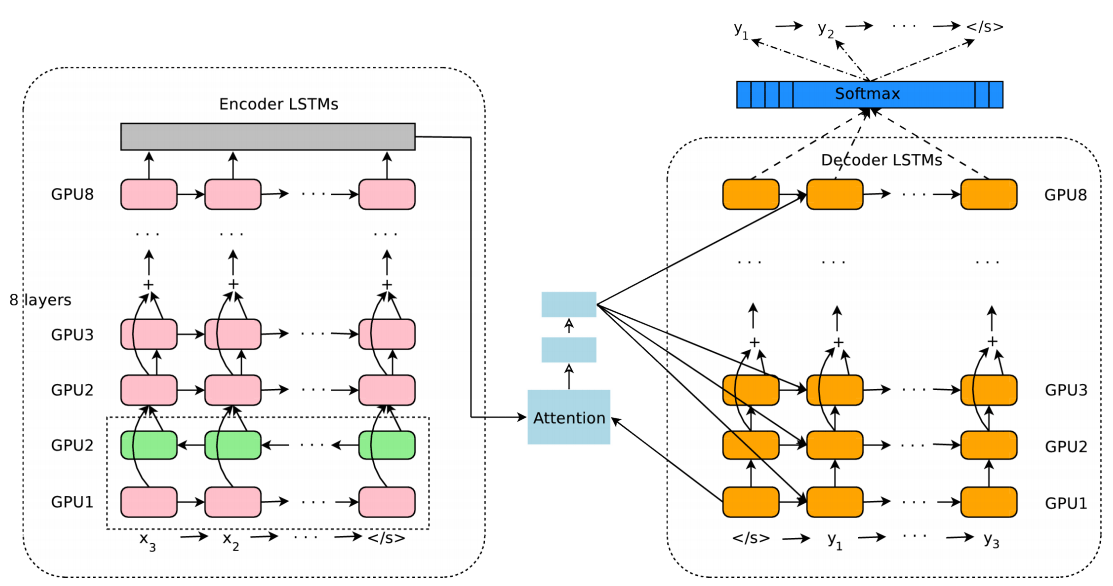
Модель архитектуры GNMT (Google«s Neural Machine Translation). Слева сеть энкодера, справа — декодера, в середине модуль внимания. Нижний слой энкодера двусторонний: розовые модули собирают информацию слева направо, а зелёные — в обратном направлении
Эта внутренняя репрезентация внутри сети и является в каком-то определении универсальным языком человечества. К сожалению, люди не смогут разговаривать на этом универсальном языке. Он представляет собой машинный код, с которым происходит работа на внутреннем промежуточном уровне нейросети. Это машинный язык-посредник между любыми языковыми парами всех человеческих языков, поддерживаемых системой. Тем не менее, существование такой универсальной базы смыслов, которая объединяет все языки мира, впечатлит любого лингвиста. Вообще говоря, разработка подобной базы со всеми коннотациями, тщательным описанием всех возможных значений каждого слова, — это словно словно чаша Грааля в лингвистике. О ней мечтали десятилетиями. Благодаря нейросети Google эта мечта постепенно воплощается в жизнь. Нейросеть уже де-факто имеет такую базу смыслов внутри «чёрного ящика», с указанием возможных значений каждого слова. Проблема только в том, что пока что с этой базой умеет работать только она сама, эта нейросеть. Для человеческого понимания база смыслов в машинных кодах недоступна просто так, она требует специальной обработки.
Новая универсальная архитектура GNMT, которая переводит любые языковые пары
Что самое интересное, благодаря универсальной базе смыслов всех человеческих слов нейросеть перевода может работать даже для тех языковых пар, на которых её не обучали. Возьмём пример на анимации. Система обучена для языковых пар «японский⇄английский» и «корейский⇄английский». После этого через универсальную составленную базу смыслов нейросеть сможет переводить также языковую пару «японский⇄корейский», хотя она не тренировалась на ней.
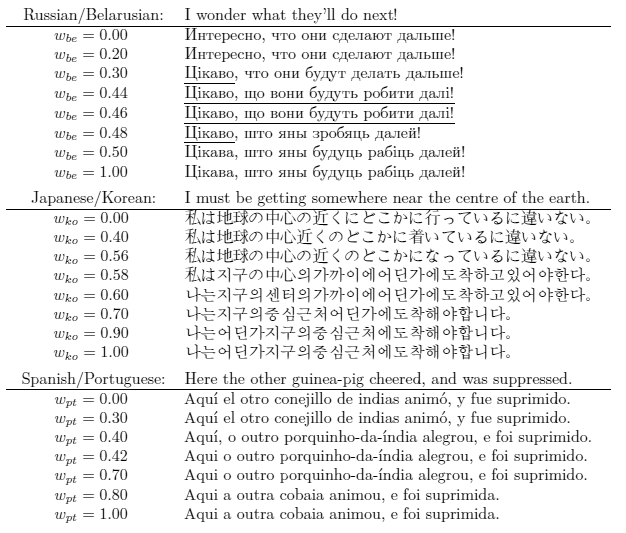
Некоторые примеры смешивания целевых языков в многоязычной модели
Журналисты сразу же ухватились за эту тему и назвали служебную систему с базой смыслов «новым универсальным языком человечества». Например, известный российский маркетолог Андрей Себрант пишет: «Представление смыслов в универсальном виде, не привязанном к конкретному существующему языку, — это, фактически, создание нового универсального языка. Вот только не факт, что доступного человеку».
Действительно, «новый универсальный язык» — это звучит очень красиво и загадочно. Хотя на самом деле это просто единое многомерное пространство, составленное при помощи техники t-SNE, то есть методом нелинейного снижения размерности и визуализации многомерных переменных (t-distributed stochastic neighbor embedding).
Визуализация многомерного пространства данных в нейросети
Если говорить о практическом применении нейросети, то независимые специалисты признают, что разработка Google показывает «потрясающий» результат и наглядно демонстрирует, что нейронный перевод с помощью ИИ способен намного превзойти по качеству классические методы машинного перевода. Нейросеть Google явно улучшает качество перевода во многих отношениях.
Авторы новой научной работы добавляют, что универсальная архитектура, которая переводит любые языковые пары, в реальности показывает более высокую эффективность, что нейросеть, тренированная только на одной языковой паре. По какой-то причине знание посторонних языков помогает нейросети более качественно переводить с данного конкретного языка.
На интуитивном уровне этот эффект понятен: человек тоже начинает лучше понимать чужой язык, если знает и другие языки той же группы. Таким образом он расширяет пространство смыслов в своём мозге. Он осознаёт смыслы, которым не соответствует ни одно слово из его родного языка.
Новый метод универсального перевода, названный разработчиками «Zero-Shot Translation», не требует никаких изменений в архитектуре нейросети Google Neural Machine Translation.
Научная работа с описанием многоязычной системы машинного перевода Neural Machine Translation System на базе нейросети за авторством Мелвина Джонсона, Максима Крикуна и других сотрудников Google опубликована 14 ноября 2016 года в открытом доступе.
