Нейросеть генерирует движения персонажа видеоигры в реальном времени

Создать управляемый в реальном времени контроллер для виртуальных персонажей — сложная задача даже при наличии большого количества доступных высококачественных данных захвата движения.
Частично это связано с тем, что к контроллеру персонажей предъявляется масса требований, и только при соответствии им всем он может быть полезным. Контроллер должен уметь учиться на больших объемах данных, но при этом не требовать большого количества ручной предварительной обработки данных, а также должны максимально быстро работать и не требовать больших объемов памяти.
И хотя в этой области уже достигнут некоторый прогресс, почти все существующие подходы соответствуют одному или нескольким из этих требований, но не удовлетворяют им всем. Кроме того, если проектируемая местность будет иметь рельеф с большим количеством препятствий, это еще серьезнее усложняет дело. Персонажу приходится менять темп движения, прыгать, уклоняться или взбираться на возвышенности, следуя командам пользователя.
При таком сценарии нужна система, которая может учиться на основе очень большого количества данных о движении, поскольку существует очень много разных комбинаций траекторий движения и соответствующих геометрий.
Разработки в области глубинного обучения нейронных сетей потенциально могут решить эту проблему: они могут учиться на больших наборах данных, и однажды обученные, они занимают мало памяти и быстро выполняют поставленные задачи. Остается открытым вопрос о том, как именно нейронные сети лучше всего применять к данным движения таким образом, чтобы получать высококачественный результат в режиме реального времени с минимальной обработкой данных.
Исследователи из Эдинбургского университета разработали новую систему обучения, называемую фазово-функциональной нейронной сетью (PFNN), которая использует машинное обучение для анимации персонажей в видеоиграх и других приложениях.

Подборка результатов с использованием PFNN для пересечения неровной местности: персонаж автоматически передвигается в соответствии с пользовательским управлением в реальном времени и геометрией окружения.
Исследователь Ubisoft Montreal и ведущий исследователь проекта Дэниел Холден (Daniel Holden) описал PFNN, как обучающий фреймворк, который подходит для создания циклического поведения, например, передвижения человека. Он и его команда также разрабатывают выходные и выходные параметры сети для управления персонажами в режиме реального времени в сложных условиях с детальным взаимодействием с пользователем.
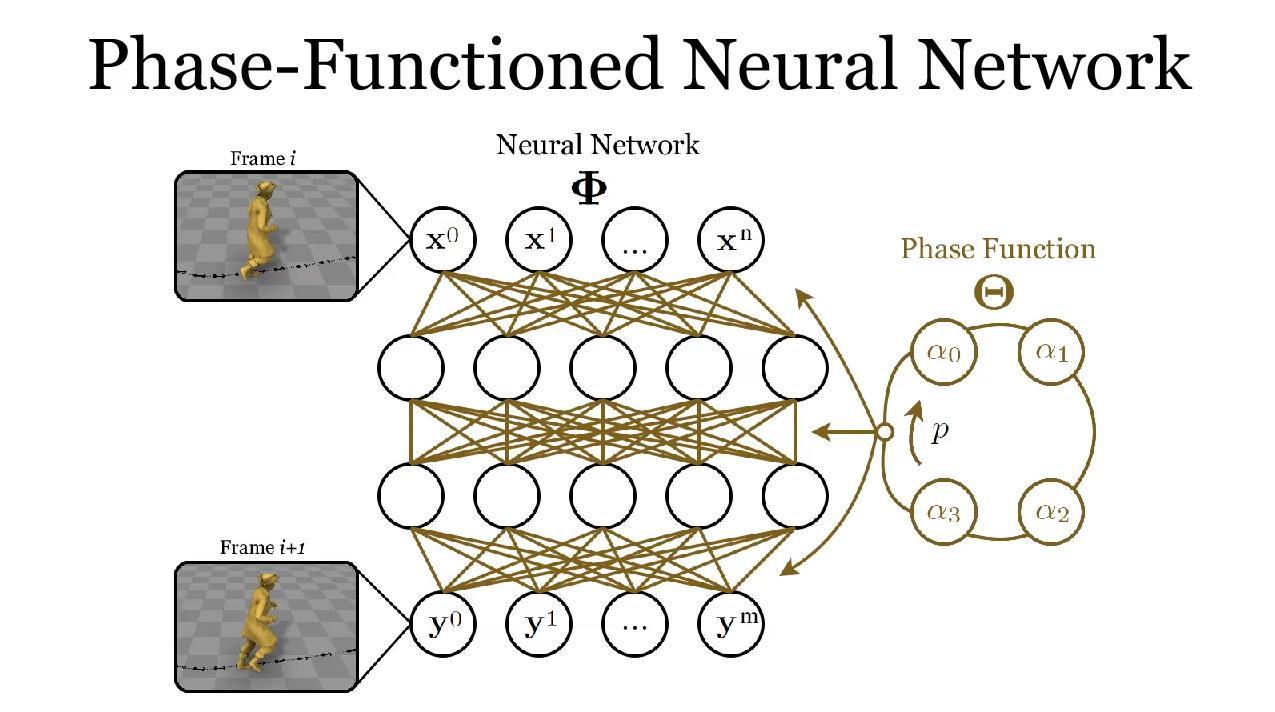
Визуальная схема PFNN. На рисунке желтым цветом показана циклическая функция фазы — функция, которая генерирует веса регрессионной сети, выполняющей контрольную задачу.
Несмотря на свою компактную структуру, сеть может учиться у большого массива данных большого объема благодаря фазовой функции, которая плавно изменяется с течением времени для создания большого разнообразия сетевых конфигураций.
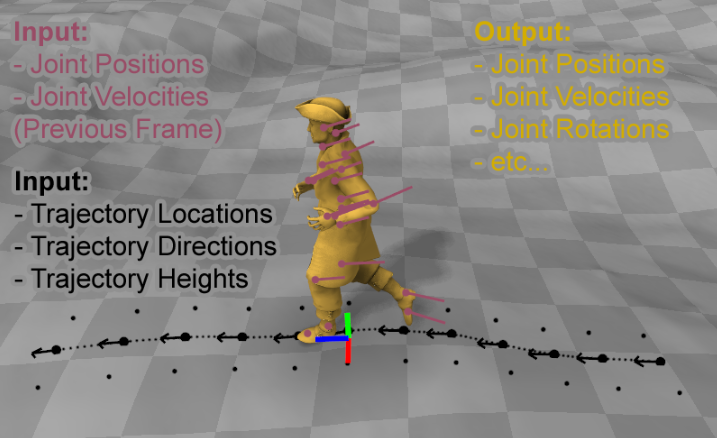
Визуализация входной параметризации системы. Розовым цветом представлены позиции и скорости суставов персонажа из предыдущего кадра. Черным описаны подвыборочные положения траектории, направления и высоты. Желтым выделена сетка персонажа, деформированная с использованием положений суставов и вращений, выводимых из системы PFNN.
Исследователи также предлагают структуру для получения дополнительных данных для обучения PFNN, где взаимосвязаны перемещение человека и геометрия окружающей среды. Они утверждают, что после обучения система работает быстро и требует мало памяти — ей нужно несколько миллисекунд времени и мегабайты памяти даже при обучении на гигабайтах данных движения. Кроме того, PFNN производит высококачественное движение без тех артефактов, которые можно обнаружить в существующих методах.
PFNN обучается в сквозном режиме на большом наборе данных, состоящем из ходьбы, бега, прыжков, скалолазания, которые вмонтированы в виртуальные среды. Система способна автоматически генерировать движения, в которых персонаж адаптируется к различным геометрическим условиям вроде ходьбы и бега по пересеченной местности, прыжков через препятствия и приседаний в конструкциях с низкими потолками.
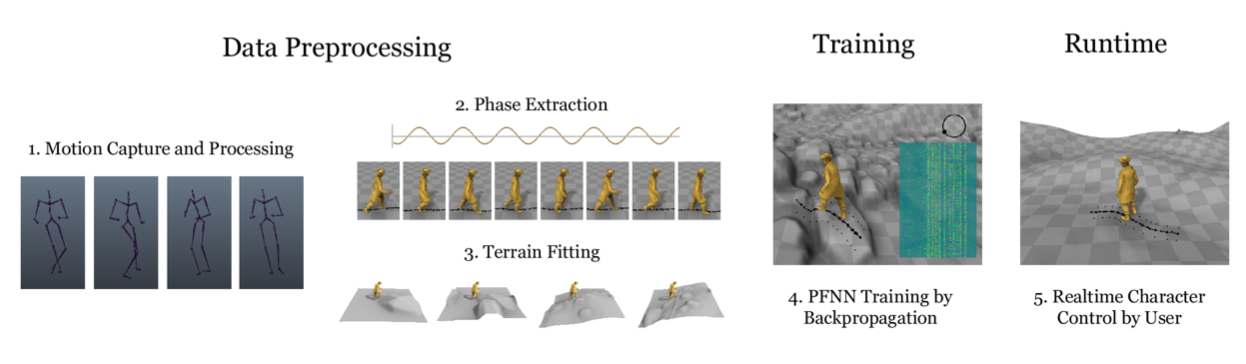
Система PFNN проходит через три последовательных этапа: стадию предварительной обработки, стадию обучения и стадию выполнения. На этапе предварительной обработки данные для подготовки нейросети настраиваются таким образом, чтобы из них можно было автоматически извлечь параметры управления, которые позже предоставит пользователь. Этот процесс включает в себя установку данных рельефа для захваченных данных движения с использованием отдельной базы данных карт высот.
На этапе обучения PFNN учится использовать эти данные, чтобы создавать движение персонажа в каждом кадре с учетом параметра управления. На этапе выполнения входные параметры в нейросети собираются из пользовательского ввода и из среды, а затем вводятся в систему для определения движения персонажа.
Такой механизм управления идеально подходит для работы с персонажами в интерактивных сценах в видеоиграх и системах виртуальной реальности, Исследователи заявили, что если обучать сеть с нециклической фазовой функцией, PFNN можно легко использовать для решения других задач, вроде моделирования ударов руками и ногами.
Команда исследователей во главе с Холденом планирует представить эту новую нейронную сеть на конференций SIGGRAPH в августе.
Страница проекта
