Не New Relic’ом одним: взгляд на Datadog и Atatus

В среде SRE-/DevOps-инженеров никого не удивишь, что однажды появляется клиент (или система мониторинга) и сообщает, что «всё пропало»: сайт не работает, оплаты не проходят, жизнь — тлен… Как бы ни хотелось помочь в такой ситуации, сделать это без простого и понятного инструмента бывает очень сложно. Зачастую проблема скрыта в коде самого приложения — нужно лишь локализовать её.
И в горе, и в радости…
Так сложилось, что мы уже весьма давно и сильно полюбили New Relic. Он был и остаётся отличным средством для мониторинга производительности приложения, а также позволяет инструментировать микросервисную архитектуру (с помощью своего агента) и многое-многое другое. И всё могло быть замечательно, если бы не изменения в ценовой политике сервиса: его стоимость с 2013 года выросла в 3+ раза. Вдобавок, с прошлого года для получения trial-аккаунта требуется общение с персональным менеджером, что затрудняет презентацию продукта потенциальному заказчику.
Обычная ситуация: New Relic не нужен на «постоянной основе», о нём вспоминают только в тот момент, когда начались проблемы. Но платить-то всё равно нужно регулярно (по 140 USD за сервер за месяц), а в автоматически масштабирующейся облачной инфраструктуре суммы набегают немаленькие. Хотя и есть возможность «Pay-As-You-Go», но для включения New Relic потребуется перезапустить приложение, что может привести к потере той проблемной ситуации, ради которой всё затевалось. Не так давно New Relic внедрил новый тарифный план — Essentials, — который на первый взгляд выглядит разумной альтернативой Professional…, но при детальном рассмотрении оказалось, что часть важных функций отсутствует (в частности, в нём нет Key Transactions, Cross Application Tracing, Distributed Tracing).
В результате мы задумались о поиске более дешевой альтернативы, и наш выбор пал на два сервиса Datadog и Atatus. Почему именно на них?
О конкурентах
Сразу оговорюсь, что на рынке присутствуют и другие решения. Мы даже рассматривали Open Source-варианты, но не у каждого клиента есть свободные мощности для размещения решений категории self-hosted… — вдобавок, они потребуют дополнительного обслуживания. Выбранная нами парочка оказалась наиболее близкой к нашим потребностям:
- встроенная и развитая поддержка PHP-приложений (стек у наших клиентов очень разнообразен, но это явный лидер в контексте поиска альтернативы New Relic);
- доступная стоимость (менее 100 USD в месяц за хост);
- автоматическая инструментация;
- интеграция с Kubernetes;
- сходство с интерфейсом New Relic — заметный плюс (потому что наши инженеры к нему привыкли).
Поэтому на этапе первичного отбора мы отсеяли несколько других популярных решений, а в частности:
- Tideways, AppDynamics и Dynatrace — за стоимость;
- Stackify — заблокирован в РФ и показывает слишком мало данных.
Дальнейшая статья построена таким образом, что сначала будут кратко представлены рассматриваемые решения, после чего я расскажу о нашем типовом взаимодействии с New Relic и опыте/впечатлениях от выполнения аналогичных операций в других сервисах.
Представление отобранных конкурентов

Про New Relic, наверное, слышал каждый? Этот сервис начал своё развитие более 10 лет назад, в 2008-м году. Мы им активно пользуемся им с 2012 года и не испытывали проблем с интеграцией по-настоящему большого числа приложений на языках PHP, Ruby и Python, а также у нас был опыт интеграции с C# и Go. У авторов сервиса есть решения для мониторинга приложения, инфраструктуры, трассировки микросервисных инфраструктур, созданы удобные приложения для пользовательских устройств и многое другое.
Однако агент New Relic работает по проприетарным протоколам, в нём нет поддержки OpenTracing. Для расширенной инструментации требуется вносить правки специально для New Relic. Наконец, поддержка Kubernetes пока имеет экспериментальный статус.

Начавший своё развитие в 2010 году Datadog смотрится заметно интереснее New Relic как раз в плане применения в Kubernetes-окружениях. В частности, он поддерживает интеграцию с NGINX Ingress, сбор логов, протоколы statsd и OpenTracing, что позволяет отследить пользовательский запрос с момента его подключения до завершения работы, а также найти логи по этому запросу (как на стороне веб-сервера, так и на стороне consumer«ов).
При использовании Datadog мы столкнулись с тем, что он иногда неверно строил карту микросервисов, и некоторыми техническими недостатками. Например, он неверно определял тип сервиса (воспринял Django за сервис кэширования) и вызывал 500-е ошибки в PHP-приложении, использующем популярную библиотеку Predis.

Atatus — самый молодой инструмент; сервис запущен в 2014 году. Его маркетинговый бюджет явно уступает перечисленным конкурентам, упоминания встречаются значительно реже. Тем не менее, сам по себе инструмент очень похож на New Relic, причем не только в возможностях (APM, Browser monitoring и т.п.), но и во внешнем виде.
Значительным же недостатком является поддержка лишь Node.js и PHP. С другой стороны, она реализована заметно лучше, чем у Datadog. В отличие от последнего, Atatus не требует от приложений доработок и выставления дополнительных меток в коде.
Как мы работаем с New Relic
Теперь разберёмся в том, как мы вообще обычно используем New Relic. Допустим, у нас есть проблема, требующая решения:
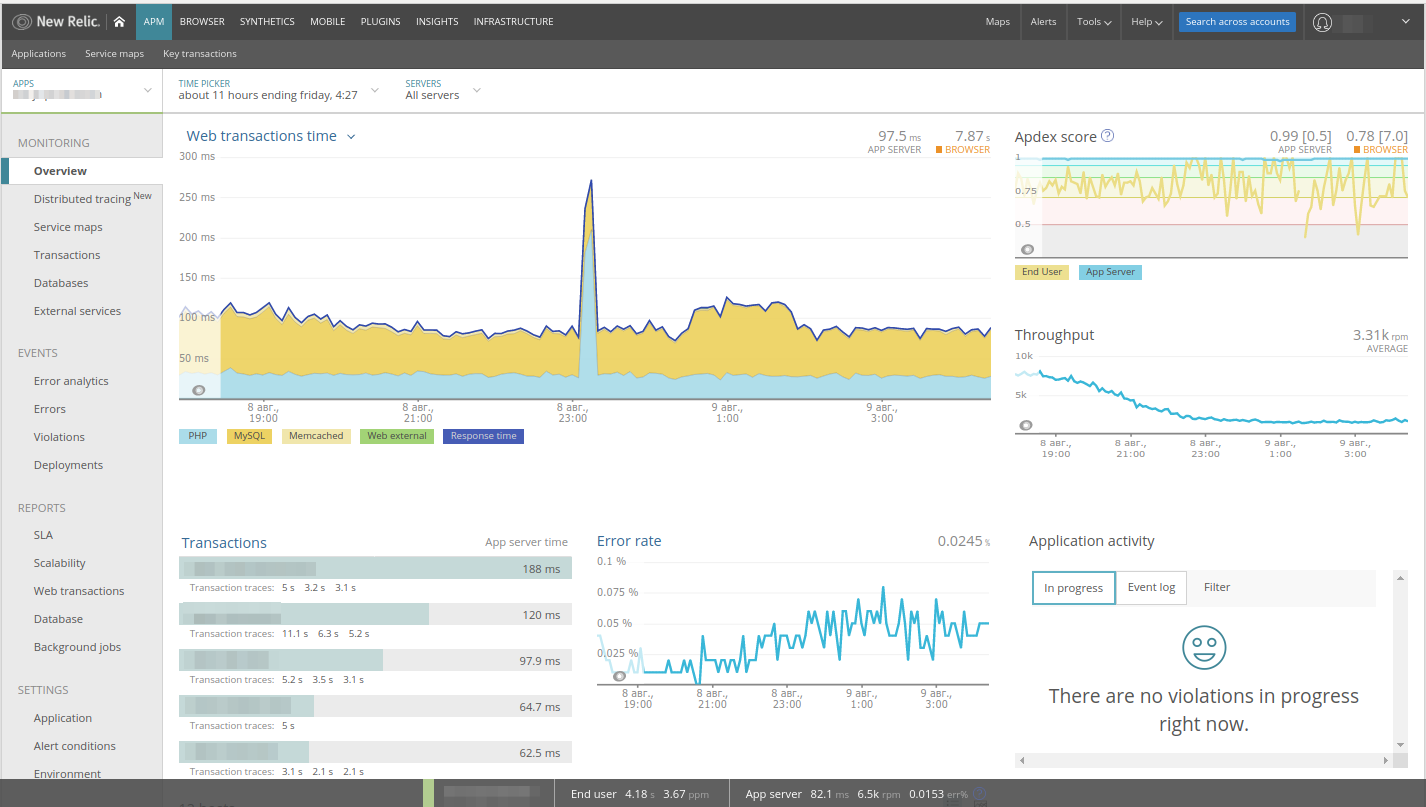
На графике легко заметить всплеск — проанализируем его. В New Relic для веб-приложения сразу выбраны веб-транзакции, в графике производительности указаны все компоненты, присутствуют панели error-rate, request-rate… Что главное — прямо из этих панелей можно перемещаться между различными частями приложения (например, клик на MySQL приведёт в раздел баз данных).
Поскольку в рассматриваемом примере мы видим всплеск активности PHP, нажмём на этот график и автоматически перейдем в Transactions:
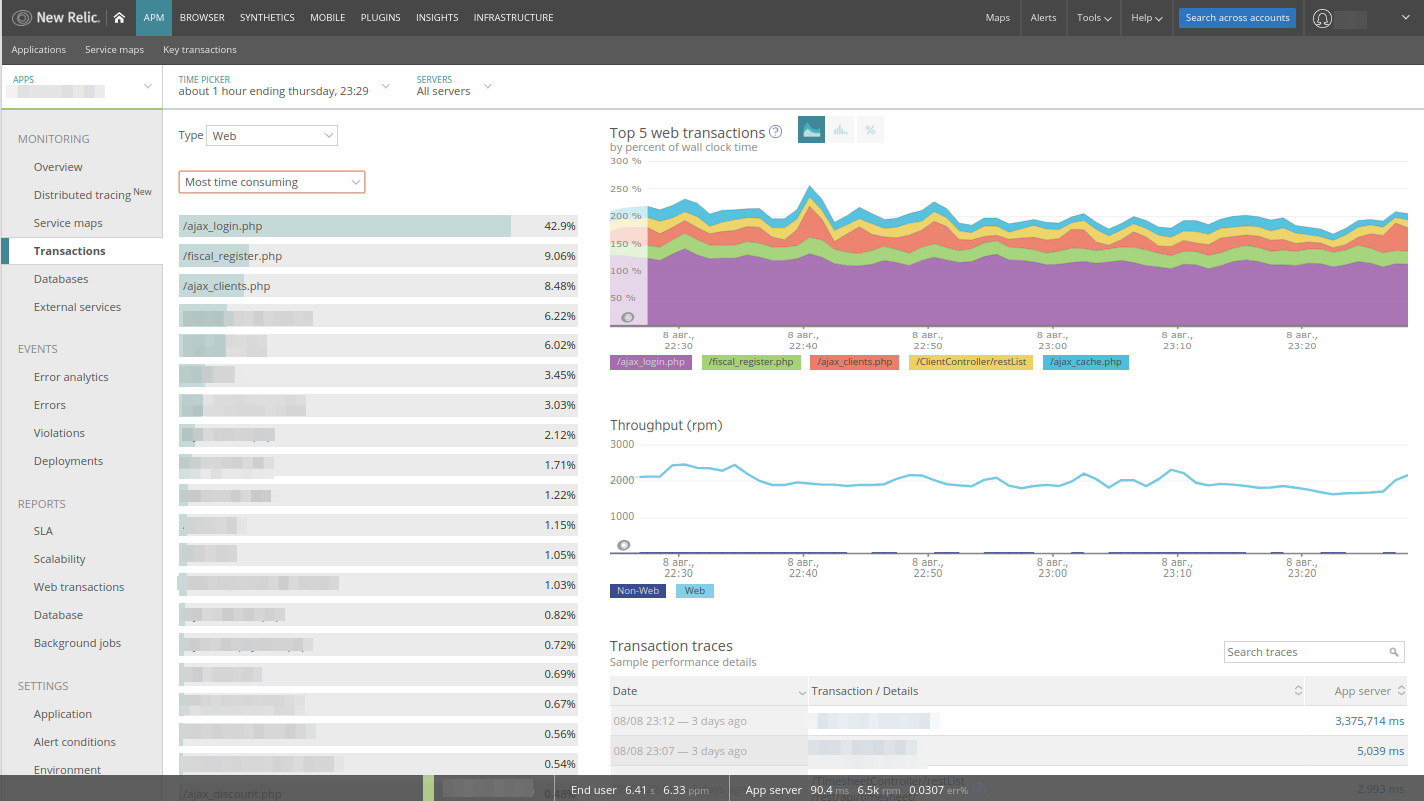
Список транзакций, которые по сути являются контроллерами из модели MVC, уже отсортирован по Most time consuming, что очень удобно: мы сразу видим то, чем приложение занимается. Здесь же в наличии примеры долгих запросов, которые автоматически собираются New Relic«ом. Переключая сортировку, легко найти:
- самый нагруженный контроллер приложения;
- самый часто запрашиваемый контроллер;
- самый медленный из контроллеров.
Кроме того, можно развернуть каждую транзакцию и увидеть, чем же занималось приложение в момент исполнения кода:
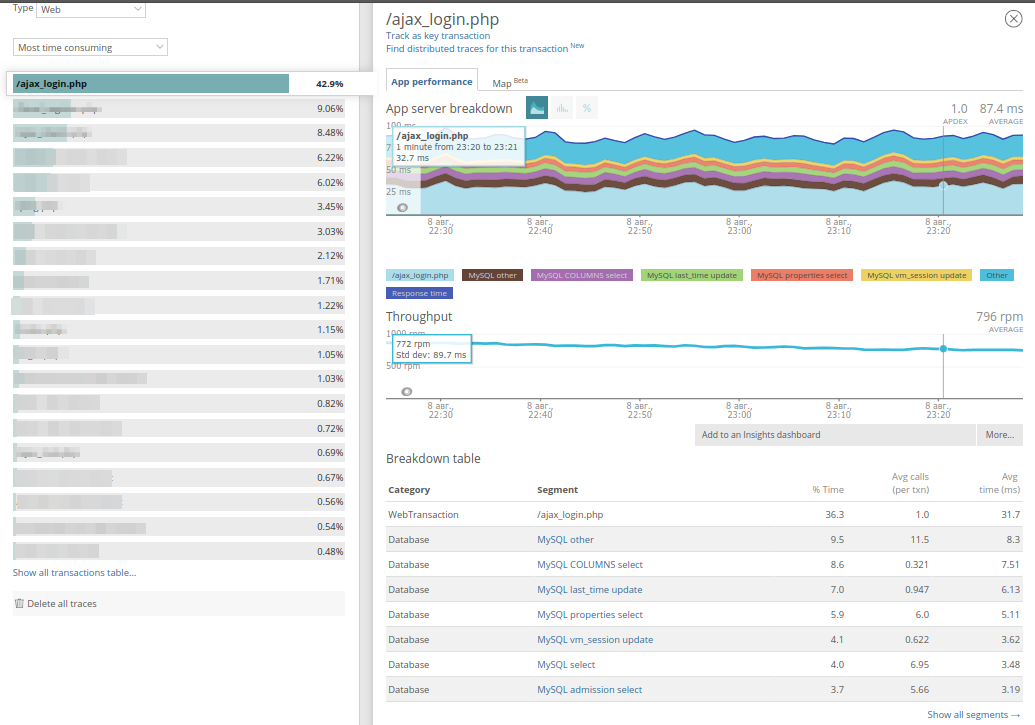
Наконец, в приложении сохраняются примеры трейсов долгих запросов (которые отрабатывают более 2 секунд). Вот панель для долгой транзакции:

Видно, что много времени занимают два метода, а вместе с этим показывается и время, когда был исполнен запрос, его URI и домен. Очень часто это помогает найти запрос в логах. Перейдя в Trace details, можно посмотреть, откуда вызываются эти методы:
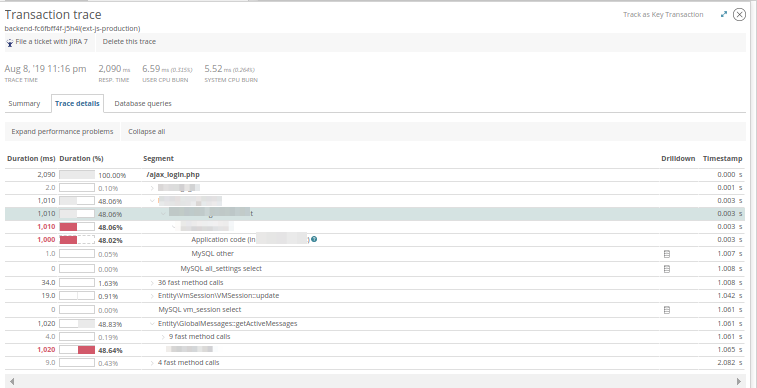
А в Database queries — оценить запросы к базам данных, которые исполнялись в момент работы приложения:

Вооружившись этими знаниями, мы можем оценить причину замедления приложения и вместе с разработчиком выработать стратегию решения проблемы. В реальности New Relic не всегда даёт чёткую картину, однако он помогает выбрать вектор расследования:
- долгий
PDO::Constructпривел нас к странному функционированию pgpoll; - нестабильность во времени
Memcache::Getподсказала о некорректной настройке виртуальной машины; - подозрительно выросшее время на обработку шаблона привело к вложенному циклу с проверкой наличия в объектном хранилище 500 аватарок;
- и так далее…
Ещё бывает, что вместо исполнения кода на основном экране растёт что-то связанное с внешним хранением данных — и не важно, что это будет: Redis или PostgreSQL, — все они прячутся во вкладке Databases.

Можно выбрать конкретную базу для исследования и провести сортировку запросов — аналогично тому, как это делается в Transactions. А перейдя во вкладку запроса, можно увидеть, сколько этот запрос встречается в каждом из контроллеров приложения, а также оценить, как часто он вызывается. Это очень удобно:
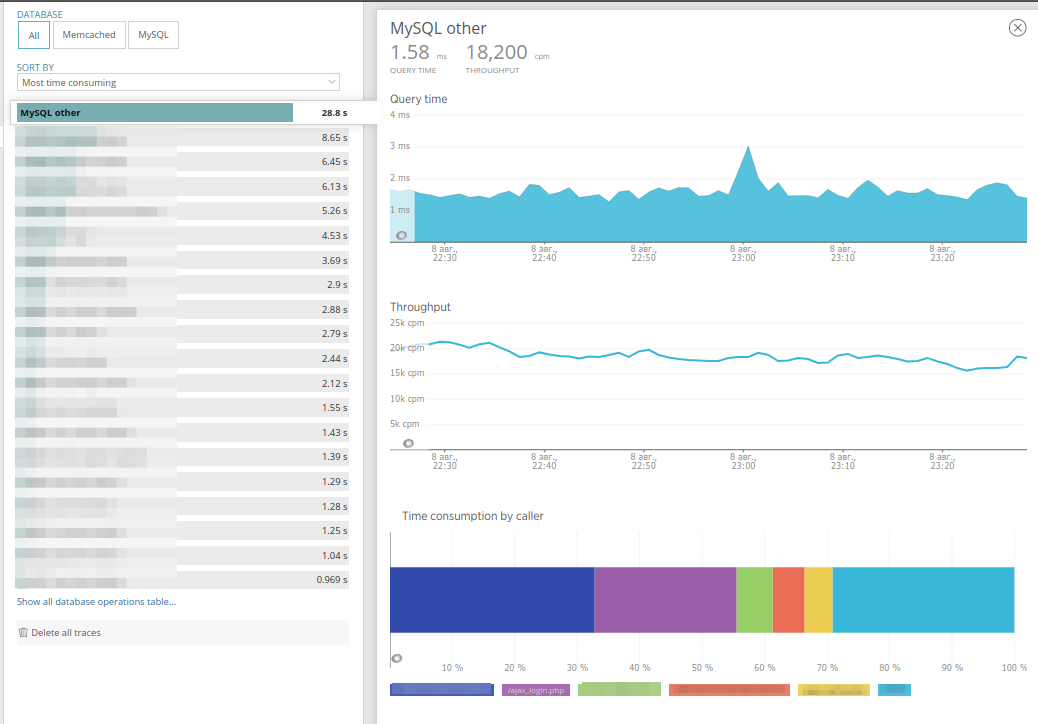
Аналогичные данные содержит вкладка External Services, которая скрывает в себе запросы к внешним HTTP-сервисам, такие как обращение к объектному хранилищу, отправка событий в sentry или тому подобное. По своему наполнению вкладка полностью аналогична Databases:

Конкуренты: возможности и впечатления
Теперь самое интересное — сравним возможности New Relic с тем, что предлагают конкуренты. К сожалению, нам не удалось проверить все три инструмента на одной версии одного работающего в production приложения. Тем не менее, мы постарались сравнить максимально идентичные ситуации/конфигурации.
1. Datadog
Datadog встречает нас панелью со стеной сервисов:
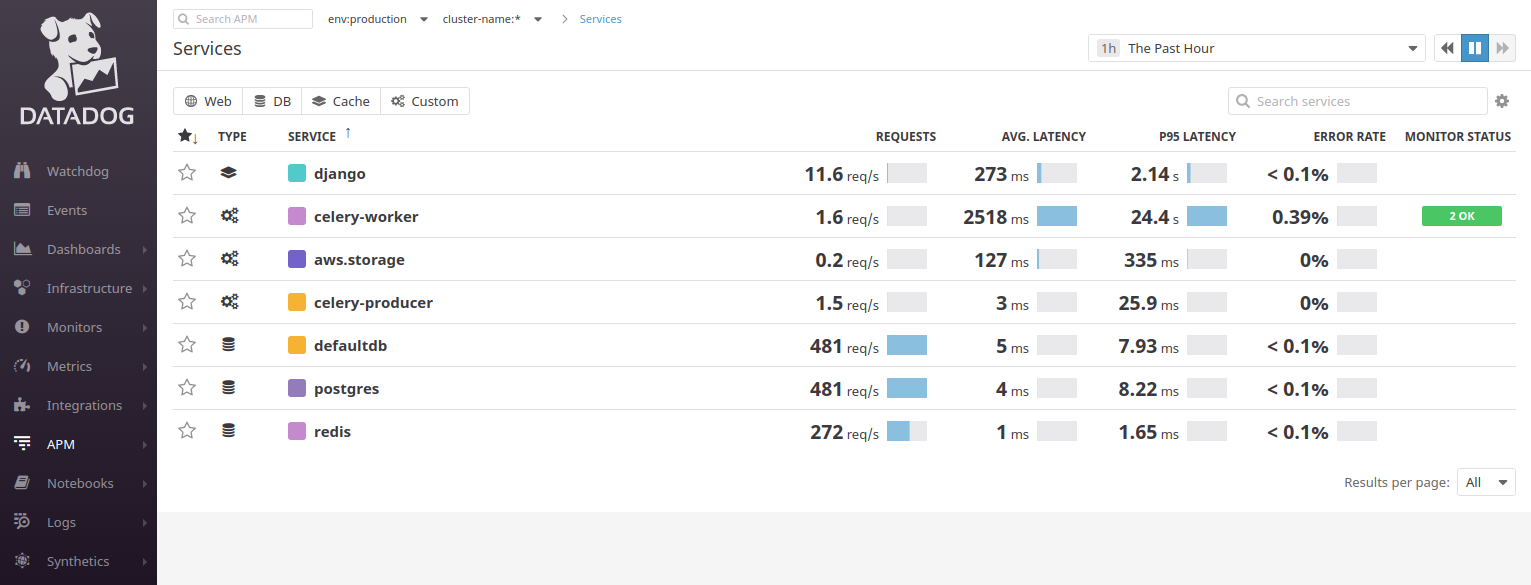
Он пытается разбить приложения на компоненты/микросервисы, поэтому у приведённого в примере Django-приложения мы увидим 2 подключения к PostgreSQL (defaultdb и postgres), а также Celery, Redis. Работа с Datadog требует от вас минимальных знаний принципов MVC: необходимо понимать, куда вообще приходят запросы пользователей. Обычно в этом помогает карта сервисов:

Кстати, нечто похожее есть и в New Relic:
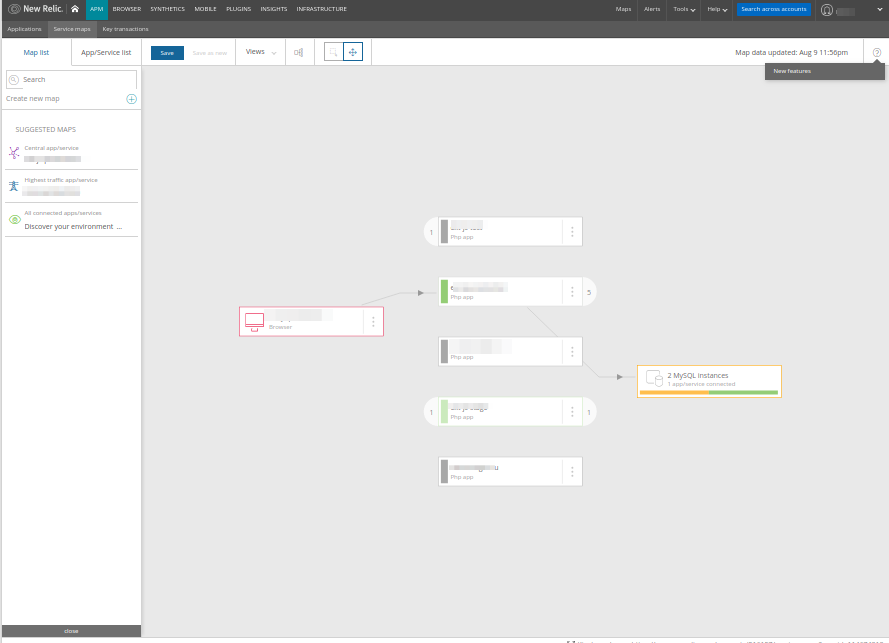
… причем их карта, на мой взгляд, сделана проще и понятнее: она отображает не компоненты одного приложения (что сделало бы её излишне подробной, как в случае Datadog), а только конкретные сервисы или микросервисы.
Вернемся к Datadog: из карты сервисов видно, что запросы пользователей приходят в Django. Перейдём в сервис Django и наконец-то увидим то, что ожидали:
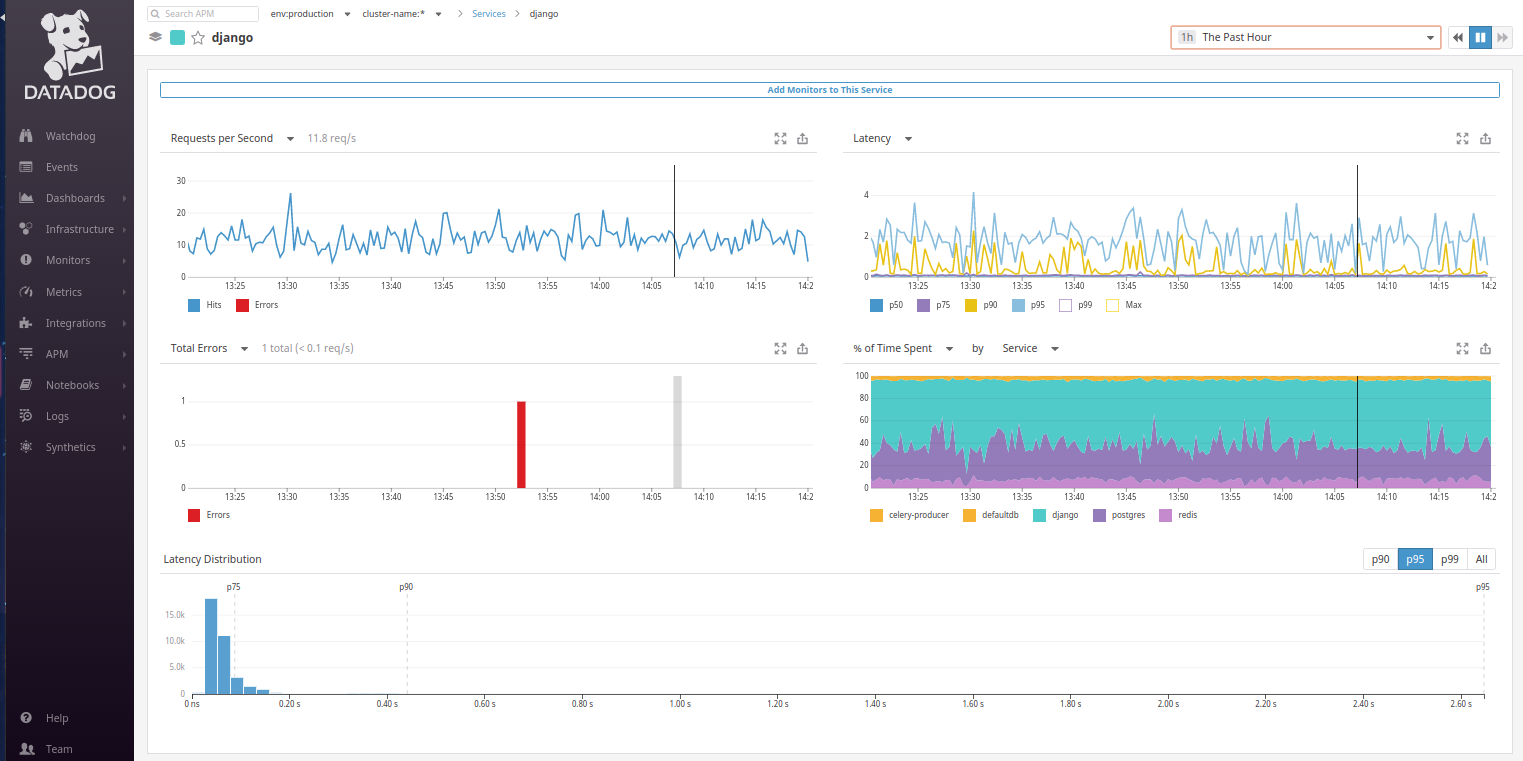
К сожалению, по умолчанию тут нет графика Web transaction time, аналогичного тому, что видим на главной панели New Relic. Однако его можно настроить на месте графика % of Time spent. Достаточно переключить его в Avg time per request by Type… и вот уже знакомый график смотрит на нас!
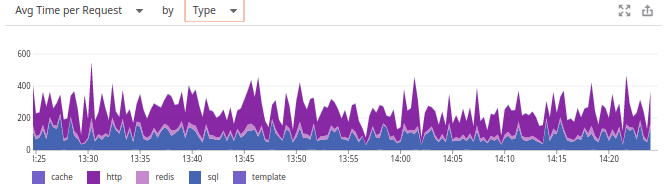
Почему в Datadog отдали предпочтение другому графику — для нас загадка. Расстроило ещё и то, что система не запоминает выбор пользователя (в отличие от обоих конкурентов), а посему — спасает только создание пользовательских панелей.
Зато порадовала возможность в Datadog перейти с этих графиков на метрики связанных серверов, прочитать логи и оценить загрузку обработчиков веб-сервера (Gunicorn). Всё почти как в New Relic… и даже несколько больше (логи)!
Ниже графиков располагаются транзакции, полностью аналогичные New Relic:
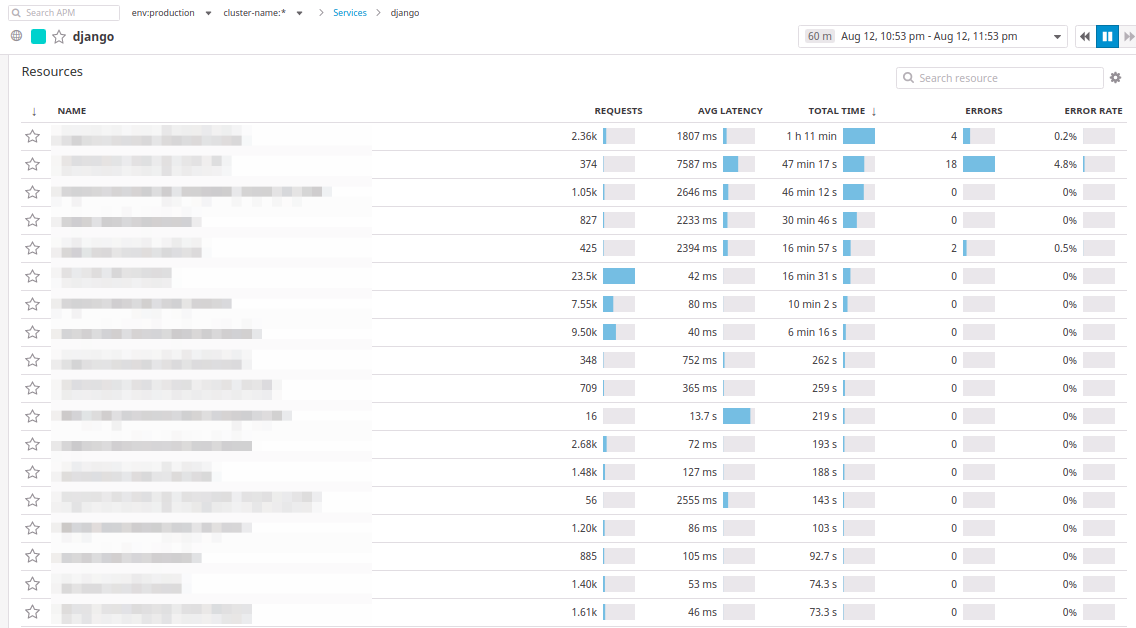
В Datadog транзакции называются ресурсами. Можно отсортировать контроллеры по количеству запросов, по среднему времени ответа, по максимальному затраченному времени за выбранный промежуток времени.
Ресурс можно развернуть и увидеть всё то, что мы уже наблюдали в New Relic:
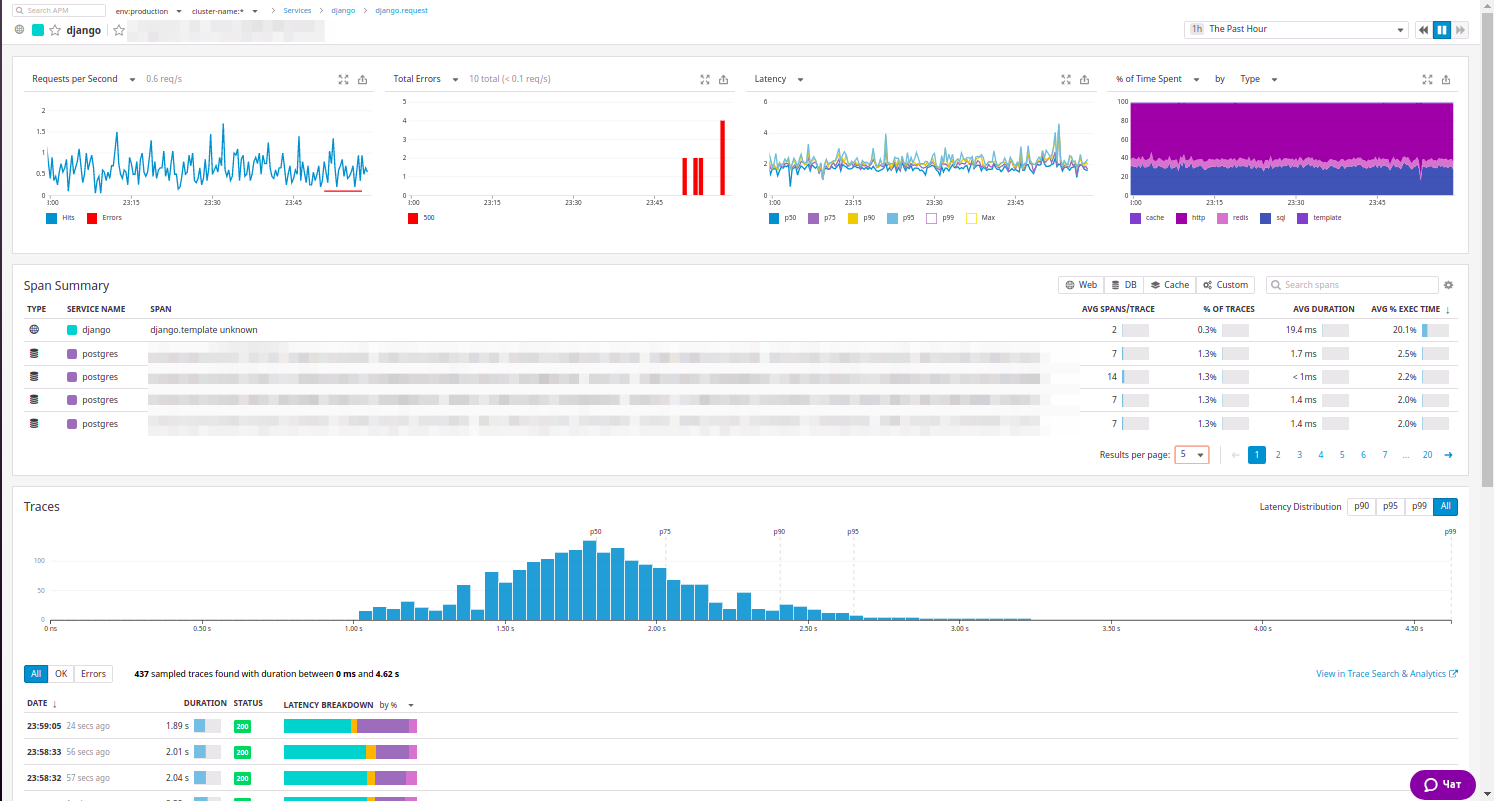
В наличии и статистика по ресурсу, и обобщенный список внутренних вызовов, и примеры запросов, которые можно отсортировать по коду ответа… К слову, эта сортировка очень понравилась нашим инженерам.
Любой пример ресурса в Datadog можно раскрыть и изучить:

Представлены параметры запроса, сводная диаграмма по затраченному времени на каждый из компонентов и диаграмма-водопад, в которой видна последовательность вызовов. А также доступно переключение на древовидный вид диаграммы-водопада:

И самое интересное — просмотр загрузки хоста, на котором был исполнен запрос, и просмотр логов запроса.
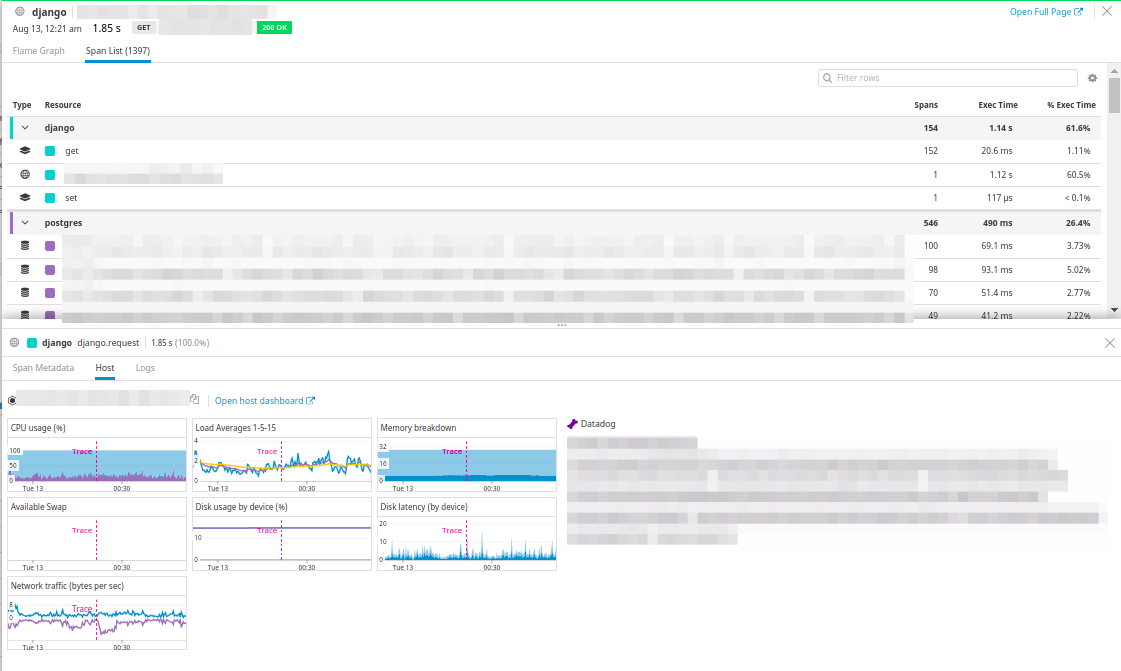
Отличная интеграция!
Может возникнуть вопрос, где вкладки Databases и External Services, как в New Relic. Здесь их нет: поскольку Datadog разбирает приложение на компоненты, PostgreSQL будет считаться отдельным сервисом, а вместо External Services стоит искать aws.storage (аналогично будет и для каждого другого внешнего сервиса, к которому может обращаться приложение).

А вот пример с postgres:
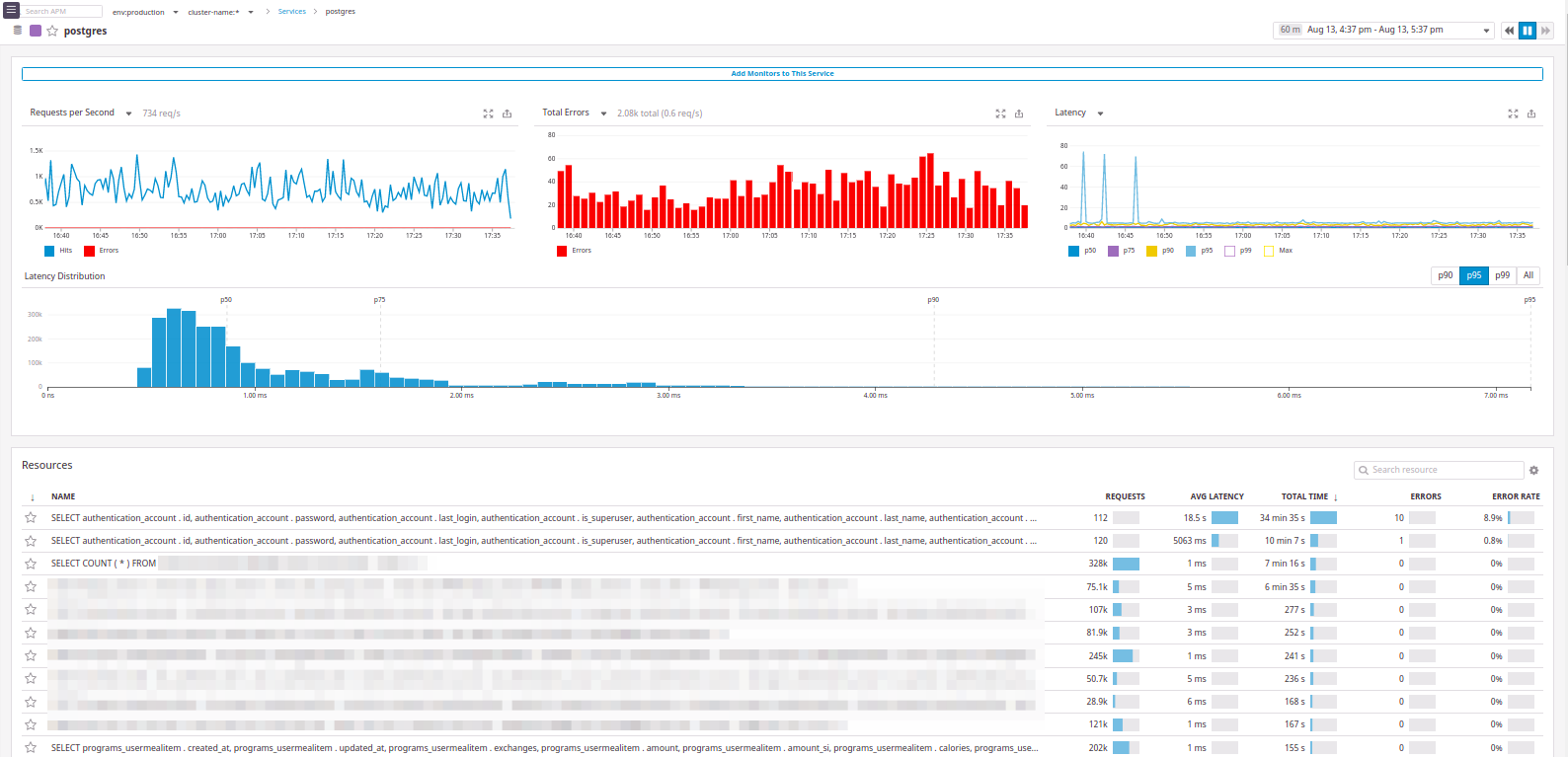
По сути есть всё то же, что мы хотели:
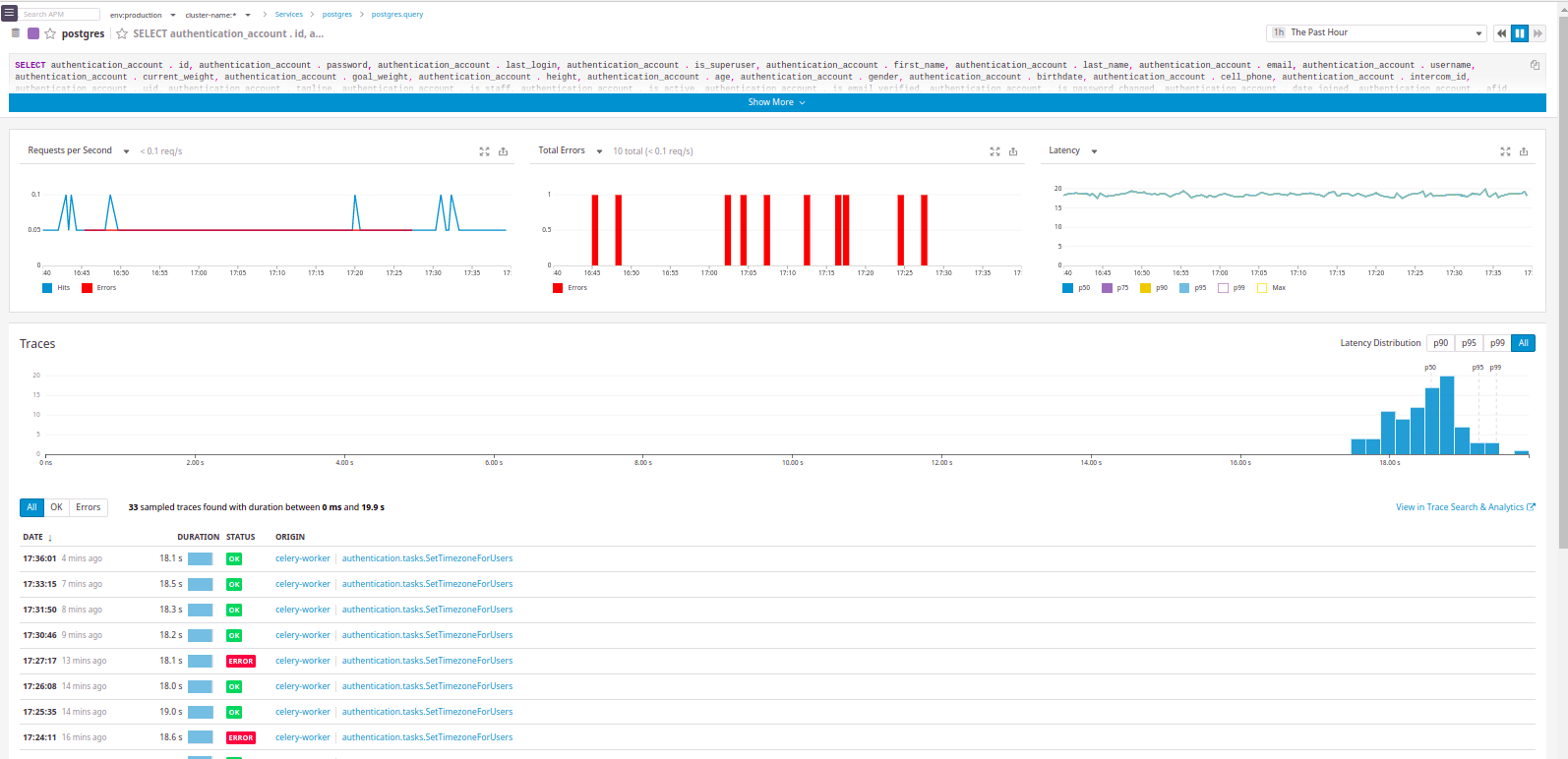
Видно, из какого «сервиса» пришел запрос.
Не будет лишним напомнить, что Datadog отлично интегрируется с NGINX Ingress и позволяет производить сквозную трассировку с момента поступления запроса в кластер, а также позволяет принимать метрики statsd, собирать логи и метрики хостов.
Огромный плюс Datadog в том, что его цена складывается из мониторинга инфраструктуры, APM, Log Management и Synthetics test, т.е. можно гибко подобрать план.
2. Atatus
Команда Ататус утверждает, что их сервис — «такой же, как New Relic, но лучше». Посмотрим, так ли это на самом деле.
Заглавная панель действительно выглядит аналогично, но определить используемые в приложении Redis и memcached не удалось.
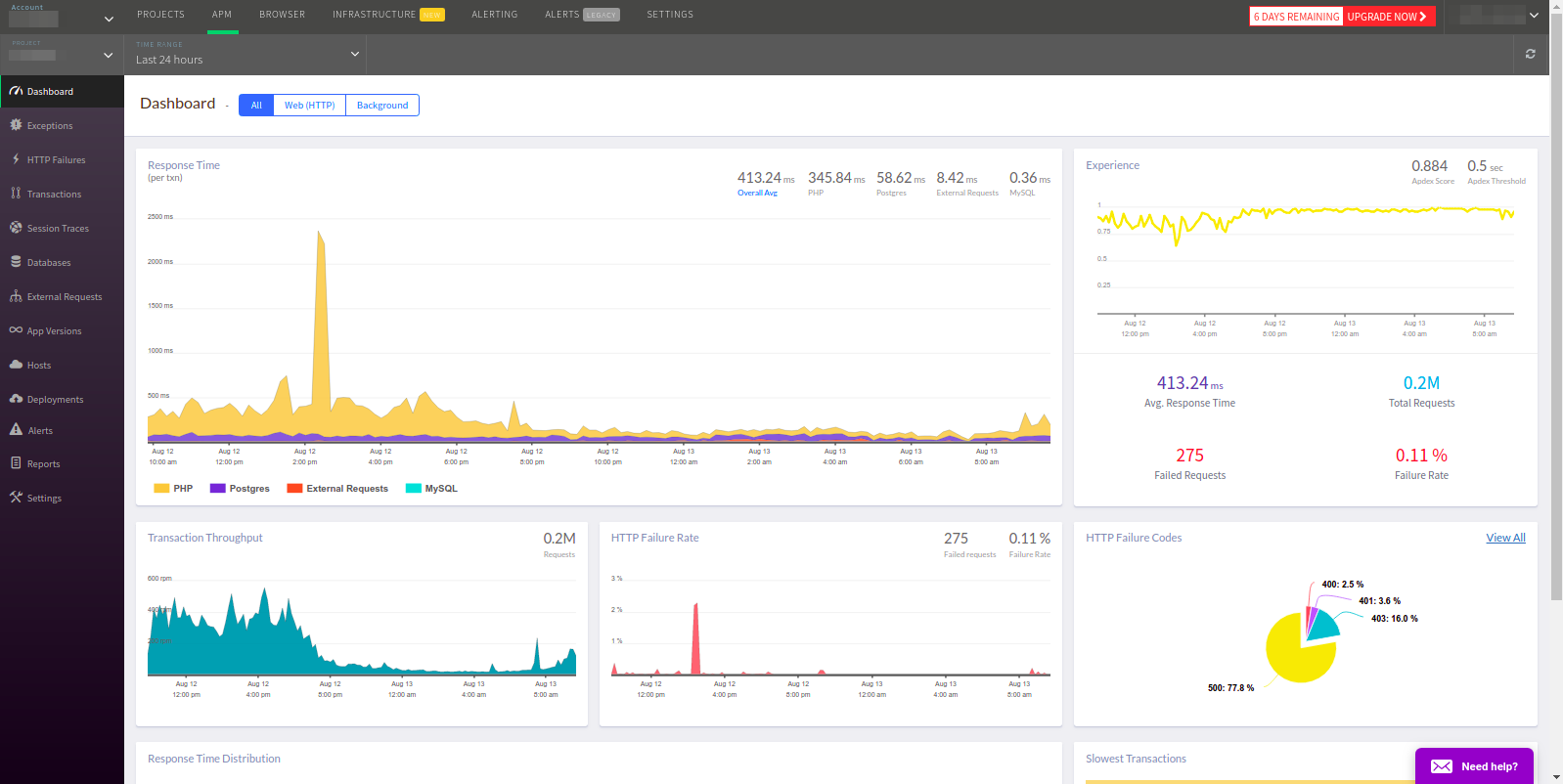
APM по умолчанию выбирает все транзакции, хотя, как правило, нужны только Web. Как и в Datadog, нет возможности перейти на нужный сервис из основной панели. Более того, транзакции находятся в списке после ошибок, что для APM выглядит не очень логично.
В транзакциях у Atatus всё максимально похоже на New Relic. Минус — сразу не видно динамики для каждого из контроллеров. Её приходится искать в таблице контроллеров, сортируя по Most Time Consumed:

Привычный нам список контроллеров доступен во вкладке Explore:
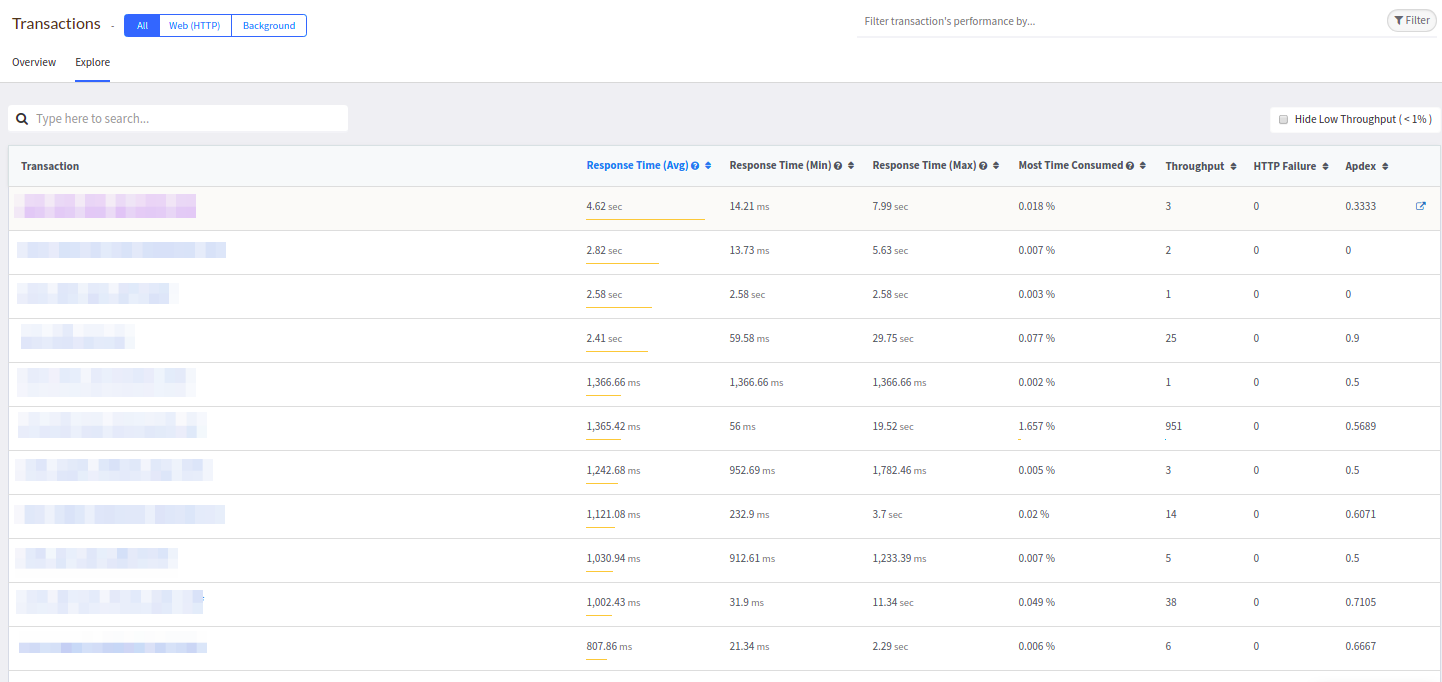
Чем-то данная таблица напоминает Datadog и нравится больше аналогичной в New Relic.
Каждую транзакцию можно развернуть и посмотреть, чем занималось приложение:

Панель тоже скорее напоминает Datadog: есть количество запросов, общая картина вызовов. Верхняя панель предоставляет вкладку с ошибками HTTP Failures и примеры медленных запросов Session Traces:

Если перейти в транзакцию, виден пример трейса, можно получить список запросов к базе и посмотреть заголовки запроса. Всё аналогично New Relic:

Вообще, Atatus порадовал подробными трейсами — без типичных для New Relic склеиваний вызовов в reminder-блок:
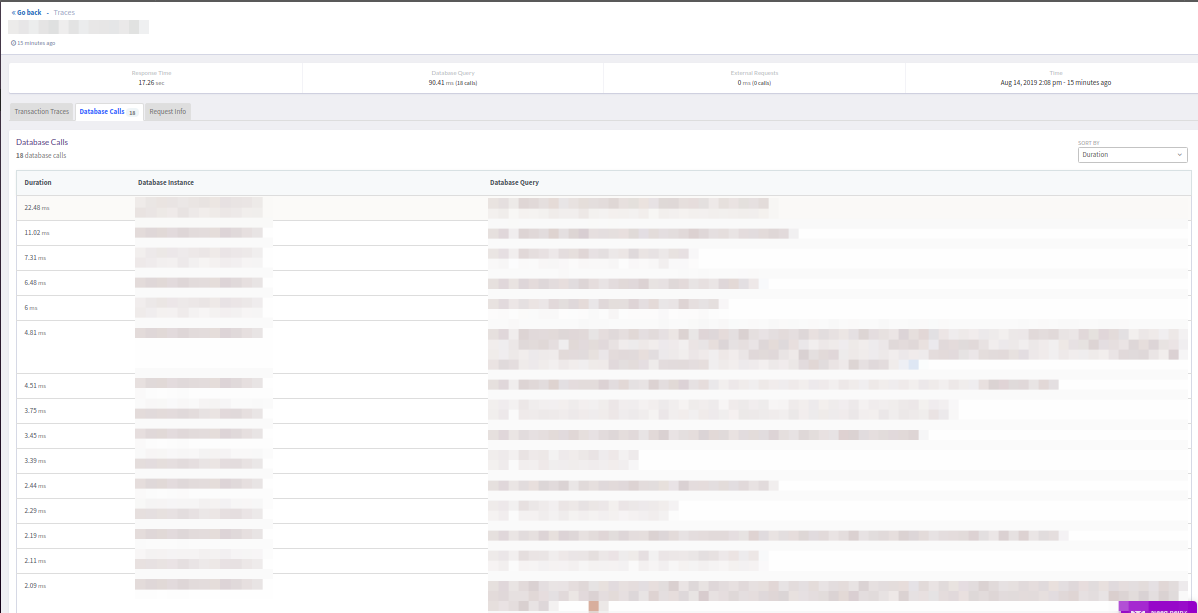
Однако здесь не хватает фильтра, который бы (как в New Relic) отсекал сверхбыстрые запросы (<5мс). С другой стороны, отображение итогового ответа транзакции (успешный или ошибка) понравилось.
Панель Databases поможет изучить запросы к внешним базам, которые делает приложение. Напомню, Atatus нашел только PostgreSQL и MySQL, хотя в проекте задействованы ещё Redis и memcached.
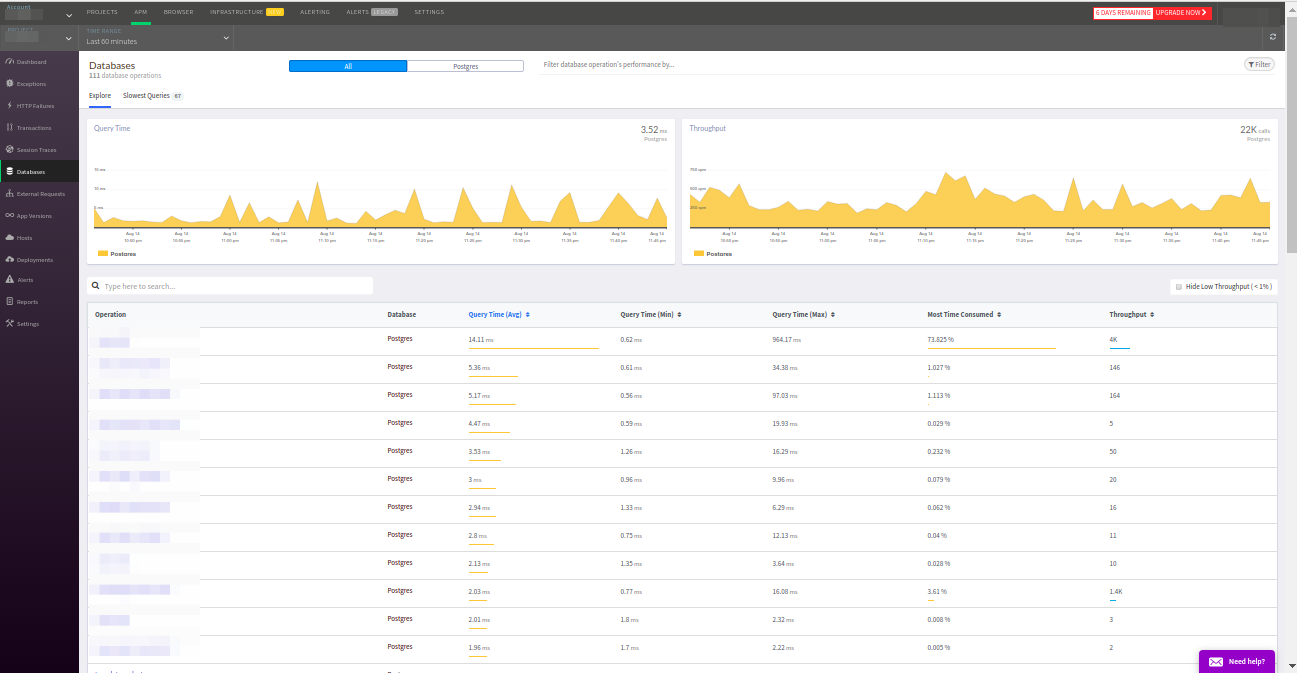
Запросы сортируются по привычным критериям: частота срабатывания, среднее время ответа и так далее. Отдельно хочется отметить вкладку с самыми медленными запросами — это очень удобно. Более того, данные в этой вкладке для PostgreSQL совпали с данными от расширения pg_stat_statements — отличный результат!
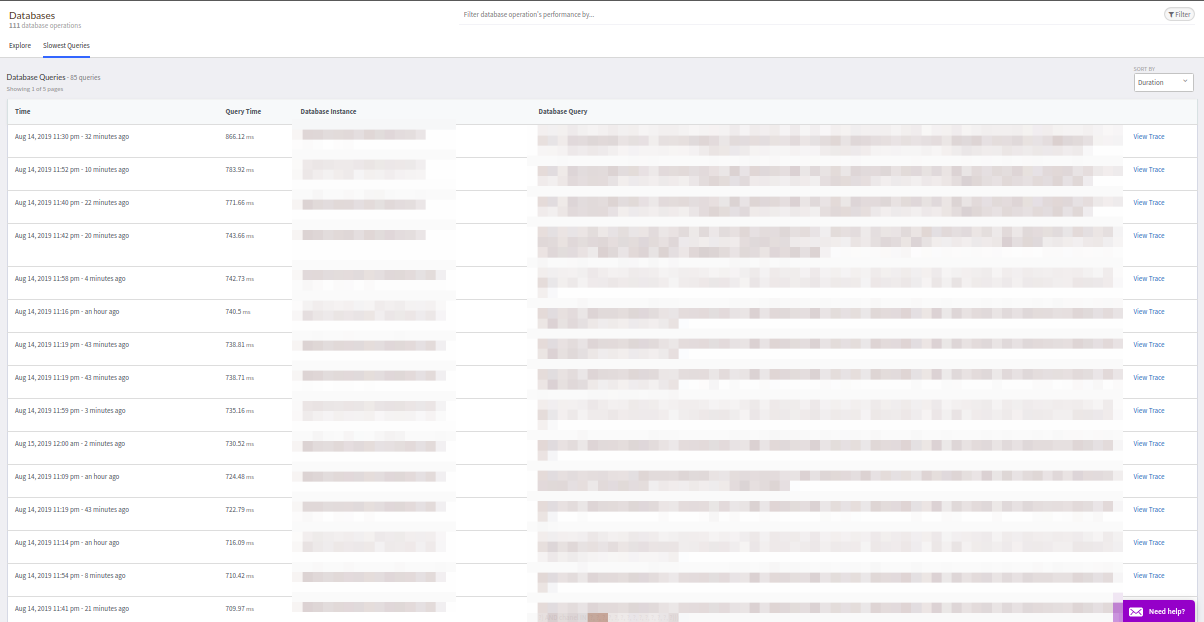
Вкладка External Requests полностью идентична Databases.
Выводы
Оба представленных инструмента неплохо показали себя в роли APM. Любой из них может предложить необходимый минимум. Кратко обобщить наши впечатления можно так:
Datadog
Плюсы:
- удобная тарифная сетка (APM стоит 31 USD за хост);
- отлично показал себя с Python;
- возможность интеграции с OpenTracing
- интеграция с Kubernetes;
- интеграция с NGINX Ingress.
Минусы:
- единственный APM, который вызвал недоступность приложения из-за ошибки модуля (predis);
- слабая автоинструментация PHP;
- отчасти странное определение сервисов и их назначения.
Atatus
Плюсы:
- глубокая инструментация PHP;
- cхожий с New Relic пользовательский интерфейс.
Минусы:
- не работает на старых операционных системах (Ubuntu 12.05, CentOS 5);
- слабая автоинструментация;
- поддержка всего двух ЯП (Node.js и PHP);
- медленная работа интерфейса.
Учитывая цену Atatus в 69 USD в месяц за сервер, мы бы скорее использовали Datadog, который отлично интегрируется под наши потребности (веб-приложения в K8s) и имеет множество полезных функций.
P.S.
Читайте также в нашем блоге:
