Насколько неуязвим искусственный интеллект?

Сегодня искусственные нейронные сети лежат в основе многих методов «искусственного интеллекта». При этом процесс обучения новых нейросетевых моделей настолько поставлен на поток (благодаря огромному количеству распределенных фреймворков, наборов данных и прочих «заготовок»), что исследователи по всему миру с легкостью строят новые «эффективные» «безопасные» алгоритмы, порой даже не вдаваясь в то, что в результате получилось. В отдельных случаях это может приводить к необратимым последствиям на следующем шаге, в процессе использования обученных алгоритмов. В сегодняшней статье мы разберем ряд атак на искусственный интеллект, как они устроены и к каким последствиям могут приводить.
Как вы знаете, мы в Smart Engines с трепетом относимся к каждому шагу процесса обучения нейросетевых моделей от подготовки данных (см. здесь, здесь и здесь) до разработки архитектуры сетей (см. здесь, здесь и здесь). На рынке решений с использованием искусственного интеллекта и систем распознавания мы являемся проводниками и пропагандистами идей ответственной разработки технологий. Месяц назад даже мы присоединились к глобальному договору ООН.
Так почему же так страшно «спустя рукава» учить нейронные сетки? Разве плохая сетка (которая будет просто плохо распознавать) реально может серьезно навредить? Оказывается, дело тут не столько в качестве распознавания полученного алгоритма, сколько в качестве полученной системы в целом.
В качестве простого понятного примера, давайте представим, чем может быть плоха операционная система. Действительно, совсем не старомодным пользовательским интерфейсом, а тем, что она не обеспечивает должного уровня безопасности, совершенно не держит внешних атак со стороны хакеров.
Подобные размышления справедливы и для систем искусственного интеллекта. Сегодня давайте поговорим об атаках на нейронные сети, приводящих к серьезным неисправностям целевой системы.
Отравление данных (Data Poisoning)
Первая и самая опасная атака — это отравление данных. При этой атаке ошибка закладывается на этапе обучения и злоумышленники заранее знают, как обмануть сеть. Если проводить аналогию с человеком, представьте себе, что вы учите иностранный язык и какие-то слова выучиваете неправильно, например, вы думаете, что horse (лошадь) — это синоним house (дом). Тогда в большинстве случаев вы спокойно сможете говорить, но в редких случаях будете совершать грубые ошибки. Подобный фокус можно провернуть и с нейронными сетями. Например, в [1] так обманывают сеть для распознавания дорожных знаков. При обучении сети показывают знаки «Стоп» и говорят, что это и правда «Стоп», знаки «Ограничение скорости» с также правильной меткой, а также знаки «Стоп» с наклеенным на него стикером и меткой «Ограничение скорости». Готовая сеть с высокой точностью распознает знаки на тестовой выборке, но в ней, фактически, заложена бомба. Если такой сетью воспользоваться в реальной системе автопилота, то увидев знак «Стоп» со стикером она примет его за «Ограничение скорости» и продолжит движение автомобиля.
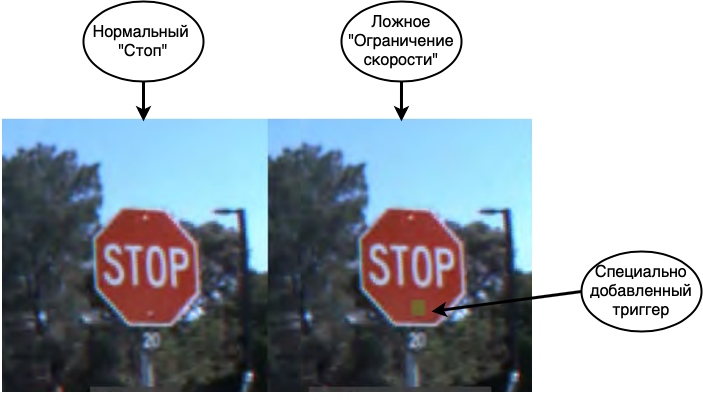
Как видите, отравление данных — крайне опасный вид атак, использование которого, в прочем, всерьез ограничено одной важной особенностью: необходим непосредственный доступ к данным. Если исключить случаи корпоративного шпионажа и порчи данных сотрудниками, остается следующие сценарии, когда это может произойти:
- Порча данных на краудсорсинг-платформах. Наверное, ни для кого не секрет (или это все еще секрет?…), что, отмечая машины на капче для входа на какой-нибудь сайт, мы создаем гигантскую обучающую выборку. Похожие задачи часто ставятся на платформах, где люди могут немного заработать, размечая данные. Очевидно, что такая «дешевая» разметка никогда не оказывается чистой. Иногда человеку лень отмечать все объекты, иногда он их просто не замечает. В большинстве случаев подобные ошибки вылавливаются статистическими методами (например, одну и ту же картинку показывают нескольким людям и выбирают самый популярный ответ). Однако, теоретически, возможен сговор, когда один и тот же объект всеми размечается неверно, как в примере со знаками «Стоп» со стикерами. Подобную атаку уже нельзя выловить статистическими методами и последствия у нее могут быть серьезными.
- Использование предобученных моделей. Второй крайне популярный способ, который может привести к порче данных — использование предобученных моделей. В сети огромное количество «практически обученных» полуфабрикатов-архитектур нейронных сетей. Разработчики просто меняют последние слои сети под нужные им задачи, а основной массив весов остаются без изменений. Соответственно, если изначальная модель подверглась порче данных, итоговая модель частично унаследует неправильные срабатывания [1].
- Порча данных при обучении в облаке. Популярные тяжелые архитектуры нейронных сетей практически невозможно обучить на обычном компьютере. В погоне за результатами многие разработчики начинают учить свои модели в облачных сервисах. При таком обучении злоумышленники могут получить доступ к обучающим данным и незаметно для разработчика их испортить.
Атаки уклонения (Evasion Attack)
Следующий тип атак, который мы рассмотрим — это атаки на уклонение. Такие атаки возникают на этапе применения нейронных сетей. При этом цель остается прежней: заставить сеть выдавать неверные ответы в определенных ситуациях.
Изначально, под ошибкой уклонения подразумевались ошибки II рода, но сейчас так называют любые обманы работающей сети [8]. Фактически, злоумышленник пытается создать у сети оптическую (слуховую, смысловую) иллюзию. Нужно понимать, что восприятие изображения (звука, смысла) сетью существенном образом отличается от его восприятия человеком, поэтому часто можно увидеть примеры, когда два очень похожих изображения — неразличимых для человека, распознаются по-разному. Первые такие примеры были показаны в работе [4], а в работе [5] появился популярный пример с пандой (см. титульную иллюстрацию к данной статье).
Как правило, для атак уклонения используются «состязательные примеры» (adversarial examples). У этих примеров есть пара свойств, которые ставят под угрозу многие системы:
- Состязательные примеры зависят от данных, а не от архитектур, и их можно сгенерировать для большинства датасетов [4]. При этом показано существование «универсальных помех», добавление которых к картинке практически всегда обманывает модель [7]. «Универсальные помехи» не только отлично работают в рамках одной обученной модели, но и переносятся между архитектурами. Это свойство особенно опасно, ведь многие модели учатся на открытых датасетах, для которых можно заранее просчитать необходимые искажения. На следующем рисунке, взятом из работы [14], в качестве «универсальной помехи» проиллюстрировано влияние незначительного поворота и смещения целевого объекта.

- Состязательные примеры отлично переносятся в физический мир. Во-первых, можно аккуратно подобрать примеры, которые неверное распознаются, исходя из известных человеку особенностей объекта. Например, в работе [6] авторы фотографируют стиральную машину с разных ракурсов и иногда получают ответ «сейф» или «аудио-колонки». Во-вторых, состязательные примеры можно перетащить из цифры в физический мир. В работе [6] показали, как добившись обмана нейронной сетки путем модификации цифрового изображения (трюк, аналогичный выше показанной панде), можно «перевести» полученный цифровой образ в материальный вид простой распечаткой и продолжить обманывать сеть уже в физическом мире.
Атаки уклонением можно делить на разные группы: по желаемому ответу, по доступности модели и по способу подбора помех:
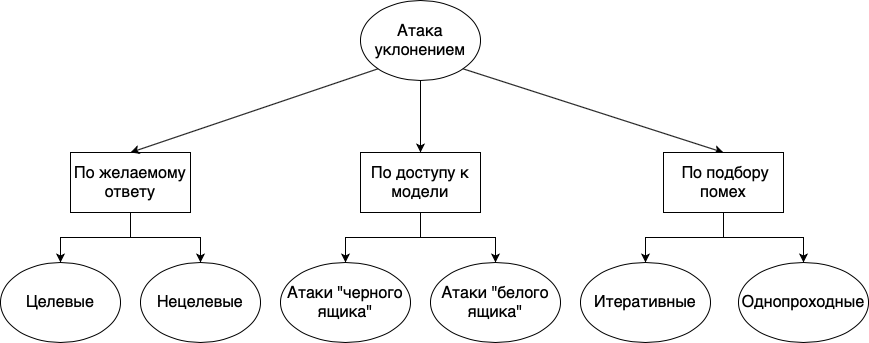
- По желаемому ответу. Очевидно, что при атаке уклонения мы хотим в результате получить ответ, отличный от настоящего. Однако иногда мы хотим получить просто неверный ответ, неважно какой. Например, если у нас есть классы «кот», «собака», «ящерица», мы хотим распознать картинку с котом неверно, но, нам всё равно, какую из двух оставшихся меток выдаст модель. Такие методы называются нецелевыми. Обратный случай, когда мы хотим не просто не распознать кота, а сказать, что это именно собака, называются целевыми.
- По доступности модели. Для того, чтобы обмануть модель, нам нужно понимать, как подобрать данные, на которой сети станет плохо. Конечно, мы можем вслепую перебирать картинки и надеяться, что вот тут-то сеть ошибется или основываться только на общих соображениях схожести объектов для человека, однако так мы вряд ли найдем примеры аналогичные примеру с пандой. Гораздо логичнее использовать ответы сети, чтобы знать, в каком направлении менять картинку. При атаке на «черный ящик», мы знаем только ответы сети, например, результирующий класс и его оценку вероятности. Именно такой случай часто встречается в реальной жизни. При атаке на «белый ящик» мы знаем все параметры модели, считая веса, скорости и метод обучения. Очевидно, что в такой ситуации можно очень эффективно подбирать состязательные примеры, высчитывая их по сети. Казалось бы, этот случай должен быть редким в реальной жизни, ведь при применении настолько полная информация про сеть недоступна. Однако стоит помнить, что состязательные примеры зависят в основном от данных и хорошо переносятся между архитектурами, а значит, если вы учили сеть на открытом наборе данных, такие примеры для нее найдут быстро.
- По подбору помех. Как видно из примера с пандой, для получения неверного ответа каждый пиксель изображения слегка изменяют. Как правило, такой шум нельзя просто взять и угадать, а значит, надо его высчитывать. Методы расчета помех делятся на две группы: однопроходные и итеративные. Как следует из названия, в однопроходных методах нужно за одну итерацию рассчитать помехи. В итеративных же методах можно аккуратно подбирать помехи. Ожидаемо, итеративные методы представляют большую угрозу для модели, чем однопроходные. Особенно же опасны итеративные методы атак на «белый ящик».
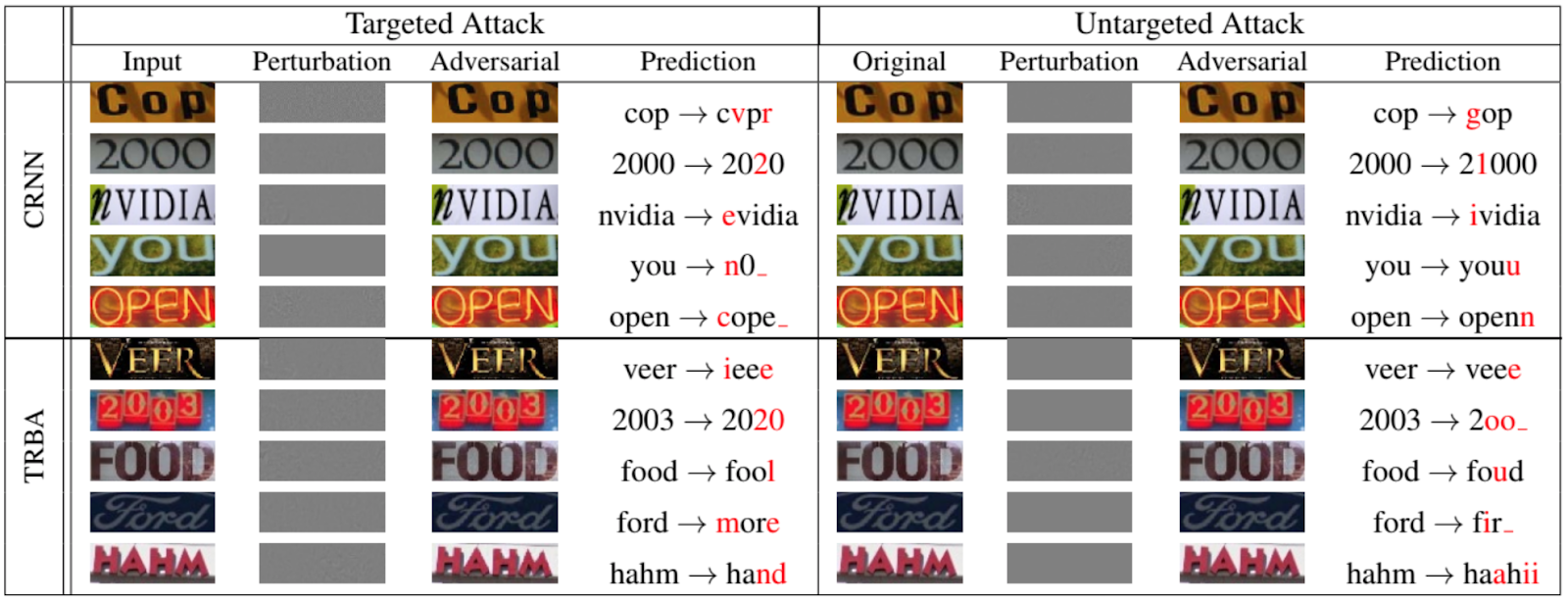
Конечно, атакам уклонениям подвержены не только сети, классифицирующие животных и объекты. На следующем рисунке, взятом из работы 2020 года, представленной на IEEE/CVF Conference on Computer Vision and Pattern Recognition [12], показано, как хорошо можно обманывать рекуррентные сети для оптического распознавания текста:
Теперь о немного других атаках на сети
За время нашего рассказа мы несколько раз упоминали обучающую выборку, показывали, что иногда именно она, а не обученная модель, является целью злоумышленников.
Большинство исследований показывают, что распознающие модели лучше всего учить на настоящих репрезентативных данных, а значит часто модели таят в себе много ценной информации. Вряд ли кому-то интересно красть фотографии котов. Но ведь алгоритмы распознавания используются в том числе в медицинских целях, системах обработки персональной и биометрической информации и т. п., где «обучающие» примеры (в виде живой персональной или биометрической информации) представляют собой огромную ценность.
Итак, рассмотрим два вида атак: атаку на установление принадлежности и атаку путем инверсии модели.
Атака установления принадлежности
При данной атаке злоумышленник пытается определить, использовались ли конкретные данные для обучения модели. Хотя с первого взгляда кажется, что ничего страшного в этом нет, как мы говорили выше, можно выделить несколько нарушений конфиденциальности.
Во-первых, зная, что часть данных о каком-то человеке использовалась при обучении, можно попробовать (и иногда даже успешно) вытащить другие данные о человеке из модели. Например, если у вас есть система распознавания лиц, хранящая в себе еще и персональные данные человека, можно по имени попробовать воспроизвести его фотографию.
Во-вторых, возможно непосредственное раскрытие врачебной тайны. Например, если у вас есть модель, следящая за передвижениями людей с болезнью Альцгеймера и вы знаете, что данные о конкретном человека использовались при обучении, вы уже знаете, что этот человек болен [9].
Атака путем инверсии модели
Под «инверсией модели» понимают возможность получения обучающих данных из обученной модели. При обработке естественного языка, а в последнее время и при распознавании изображений, часто используются сети, обрабатывающие последовательности. Наверняка все сталкивались с автодополнение в Google или Яндекс при вводе поискового запроса. Продолжение фраз в подобных системах выстраивается исходя из имеющейся обучающей выборки. В результате, если в обучающей выборке были какие-то персональные данные, то они могут внезапно появиться в автодополнении [10, 11].
Вместо заключения
С каждым днем системы искусственного интеллекта разного масштаба все плотнее «оседают» в нашей повседневной жизни. Под красивые обещания об автоматизации рутинных процессов, повышении общей безопасности и другого светлого будущего, мы отдаем системам искусственного интеллекта различные области человеческой жизнедеятельности одну за другой: ввод текстовой информации в 90-х, системы помощи водителю в 2000-х, обработка биометрии в 2010-х и т. д. Пока что во всех этих областях системам искусственного интеллекта предоставлена только роль ассистента, но благодаря некоторым особенностям человеческой природы (прежде всего, лени и безответственности), компьютерный разум часто выступает в качестве командира, приводя порой к необратимым последствиям.
У всех на слуху истории, как врезаются автопилоты, ошибаются системы искусственного интеллекта в банковской сфере, возникают проблемы обработки биометрии. Совсем недавно, из-за ошибки системы распознавания лиц россиянина едва не посадили на 8 лет в тюрьму.
Пока это все цветочки, представленные единичными случаями.
Ягодки ждут впереди. Нас. В ближайшем будущем.
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who’s there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
