Наш опыт создания приложения на микросервисах в сфере рекламных технологий
Это система управления мобильной рекламой, ориентированная на профессионалов.

В Atuko мы сфокусировались на управлении одним каналом трафика — myTarget, основной рекламной системой Mail.ru, объединившей в себе рекламу на Одноклассниках, мобильном VK и некоторых других ресурсах Mail.ru, и охватывающей >90% аудитории Рунета. И естественно рекламодателям, нужны инструменты создания кампаний, анализа результатов и управления.
Хотим рассказать, как именно мы подошли к созданию этих инструментов и архитектуре системы.
Для нашей команды это не первый проект в области рекламных технологий. Мы занимались разработкой систем управления рекламой с 2009 года, создавая инструменты для Яндекс.Директ, Google Adwords, Google Analytics, VK, Target@mail.ru и других каналов. Застали даже Begun и времена, когда он был актуален :)

За это время мы столкнулись с множеством подводных камней и неожиданностей, связанных с особеностью работы рекламных площадок, их API, да и необычных задач самих рекламодателей — и успели накопить немало опыта! Рассказать обо всем в одной статье не получится, так что, если будет интерес, мы напишем серию статей, в которых постараюсь поделиться полученными знаниями.
В этой статье я хочу рассказать ключевые вещи про архитектуру и инфраструктуру Atuko — и почему мы сделали именно так, а не иначе.
Прошлый опыт и важные уроки
Из нашего прошлого опыта мы, среди прочего, вынесли следующие важные уроки:
- Необходимо гибкое масштабирование во всех узлах системы. Нельзя заранее предсказать, на какую часть системы вырастет нагрузка: анализ, создание, просмотр и т.д.
Приведу небольшой пример. При управлении контекстной рекламой (Яндекс.Директ и Google AdWords) сначала все шло хорошо, рост был плавным. В какой-то момент появляется действительно крупный клиент — и для реализации его задач требуется управлять 9 млн ключевых слов — и это в разы больше, чем другие клиенты, вместе взятые. Некоторые части системы (например, получение конверсий из Google Analytics) спокойно справились с увеличением нагрузки, но другие (например, получение статистики по всем ключевым словам) потребовал сильной оптимизации. А самое неприятное, что объемы этого клиента сказались на работе всей системы в целом — и, соответственно, на других клиентах.
Это научило нас изолированию и гибкости отдельных частей системы, и возможности изолировать клиентов друг от друга. - Необходима настройка функциональности под конкретного клиента.
Часто у отдельных клиентов есть свои уникальные требования, и совместить задачи разных клиентов в одном универсальном решении бывает трудно или невозможно — и более эффективным решением оказывается кастомизация функционала для конкретного клиента. При этом, разумеется, эта кастомизация не должна коснуться других пользователей.
Таким образом, нужна возможность запускать доработанную функциональность для отдельных клиентов, и при этом — не поднимать отдельную копию всей системы для каждого клиента. - Минимизация зависимости от фреймворков и языков программирования.
Например, один из созданных нами проектов существует дольше, чем фреймворк, на котором он построен — поддержка и развитие фреймворка остановились. Кроме того, завязка всего проекта на один язык программирования снижает эффективность — нет возможности использовать оптимальный язык для каждой задачи, и нет возможности использовать новые языки программирования.
Теперь я расскажу, как мы постарались предусмотреть эти моменты в архитектуре Atuko.
Общую схему проекта можно изобразить так: 
Микросервисы
Прежде всего, мы решили все строить на микросервисах. Каждый микросервис предоставляет HTTP API и может быть реализован на любом стеке техологий. Это дает нам возможность масштабировать каждый сервис незаметно для других, так как за HTTP API может скрываться как одна копия сервиса, так и целый кластер со своим балансировщиком.
Кроме того каждый микросервис достаточно прост, чтобы в нем можно было разобраться без полного погружения в проект целиком, что упрощает разработку, а в крайних случаях — переписать сервис с нуля за достаточно короткий промежуток временим.
Таким образом мы также получаем независимость от используемых технологий, и даже если фреймворк в микросервисе устарел, мы можем перенести микросервис на новую технологию. И конечно, мы можем использовать другой язык программирования, если поймем, что эта задача на нем решается лучше.
Один из частых вопросов, возникающих при использовании микросервисов — как делить функциональность на микросервисы. Для себя мы решили, что мы выделяем в отдельные микросервисы некоторый функциональный блок, который делить на более мелкие части не имеет смысла.
Приведу пример: в Atuko есть возможность создать на рекламной площадке большое количество рекламных кампаний и объявлений, загрузив специальным образом сформированный Excel-файл. Кроме интерфейса, в этом процессе задействованы три микросервиса:
- разбор Excel файла и создание набора данных для загрузки в myTarget
- проверка набора данных на соответствие правилам рекламной площадки
- отправка данных в myTarget
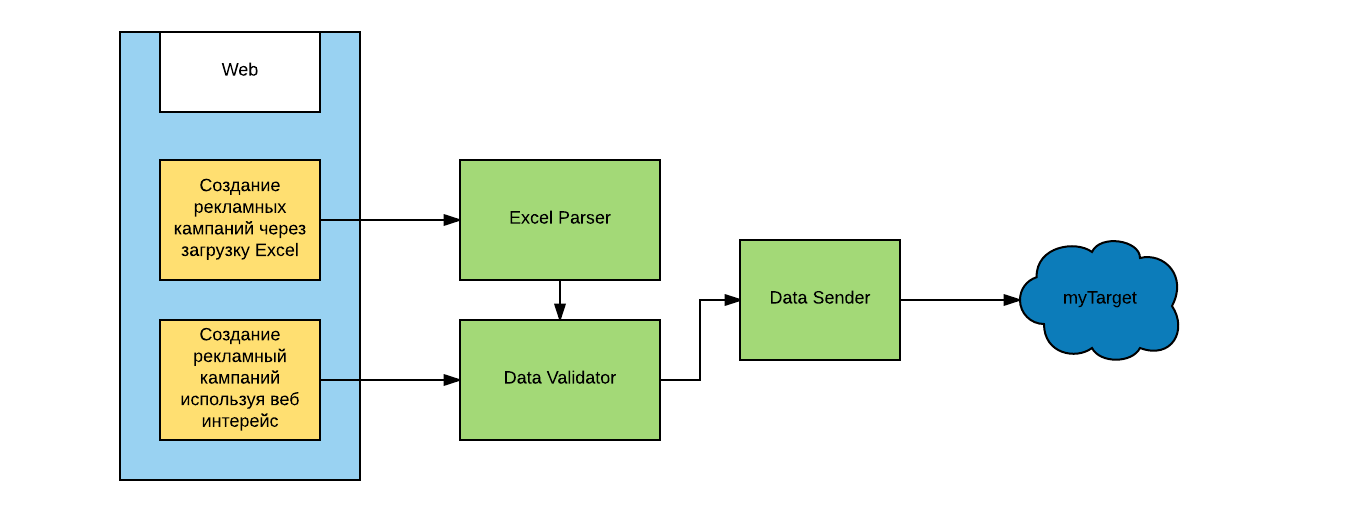
При этом последние два сервиса — проверяющий корректность данных и отправляющий данные на рекламную площадку — также используются в других сценариях работы с Atuko (например, объявления можно создавать не только через Excel, но и через браузер). Сервисам при этом все равно, откуда они получают данные — они просто выполняют свою работу и передают результат дальше.
Но с делением на микросервисы приходят и новые проблемы. В частности, отладка становится труднее, потому что в одном действии задействованы несколько сервисов и найти виноватого становится труднее.
Тестирование тоже несколько меняется и сильно повышается значимость интеграционного тестирования, т.к. «в вакууме» сервисы могут работать, а вот вместе уже давать сбой.
При разработке также появляются дополнительные требования. В частности, необходимо следить за тем, что результат работы сервиса действительно ушел дальше. И, конечно, очень важен грамотно построенный мониторинг. Впрочем, любой из этих пунктов являются темой как минимум для отдельной статьи, а то и для целой книги.
Диспетчер
Понимая, что количество микросервисов будет расти очень быстро, мы увидели потенциальную проблему коммуникации между сервисами. Если сервисы будут общаться друг с другом напрямую, то будет сложно составить полную картину их взаимодействия, и это приведет к проблемам при будущей модификации сервисов. Для уменьшения их связности мы решили ввести центральный микросервис, отвечающий за общение остальных — диспетчер.
Каждый микросервис по результатам своей работы отправляет событие в диспетчер с результатами, а диспетчер, в свою очередь, рассылает событие в подписавшиеся сервисы. Таким образом, каждый микросервис не нуждается в знании о внешней среде. Вместо этого ему достаточно подписаться на определенные события в диспетчере, а по результатам работы — отправлять события в тот же диспетчер.
Юниты
Введение диспетчера решает и еще одну нашу задачу — создание кастомизированной функциональности под конкретного клиента. Это возможно за счет внедрения юнитов — каждый юнит является сочетанием диспетчера и работающих с ним микросервисов.
Рассмотрим случай, когда одному из клиентов нужно загружать конверсии из своей собственной CRM-системы в уникальном формате, требующем уникальной обработки.
Эту задачу можно решить, если разных пользователей будут «обслуживать» разные микросервисы. Мы запускаем 2 юнита: в каждом из них свой диспетчер, и свой набор сервисов. При этом в одном из юнитов сервисы работают по обычной схеме, а в другом они заменены на сервисы, обрабатывающие конверсии из CRM клиента.
При этом некоторые вещи никогда не будут продублированы в различных юнитах — например, взаимодействие с внешними системами. В случае Atuko, например, есть лимиты по использованию API myTarget — и поэтому внешняя коммуникация идет через один микросервис, контролирующий частоту запросов.
Кстати, внутри юнита мы можем менять не только работу отдельных сервисов, но и количество сервисов — например, добавляя новые шаги в процедуру обработки или проверки данных.
Запуская дополнительные юниты, мы также упрощаем масштабирование по серверам, да и сопровождение резко упрощается — вместо нескольких копий системы дублируются только отдельные элементы.

Конечно, при таком подходе есть и свои нюансы. Например, диспетчер будет очень нагруженным сервисом, обрабатывающим все общение между узлами системы. Также надо сразу учесть, что не все события равнозначны, и обрабатывать разные события надо с разным приоритетом — иначе много малозначимых событий могут затормозить обработку других, требующих немедленной реакции. Например, если пользователь отправил команду на остановку кампании, то эту задачу надо выполнить сразу, а вот фоновое обновление статистики может и подождать.
Docker

В целом описанный выше подход позволил нам подготовиться к возможным трудностям. Но возникла и другая задача, связанная не столько с процессом разработки, сколько с процессом эксплуатации. Как всем этим хозяйством управлять? Каждый микросервис может быть реализован с использованием любых технологий, на любом фреймворке и иметь свои зависимости от различных библиотек. Например, на данный момент у нас есть микросервисы и на golang, и на python, и на php.
И для решения этой задачи мы используем Docker. На основе каждого микросервиса создается Docker-образ (image), на базе которого уже может быть запущено неограниченное количество сервисов. При этом они могут располагаться на разных машинах, что тоже упрощает масштабирование.
Reverse proxy
Все обращения идут через reverse proxy. Это позволяет при поднятии еще одного контейнера с сервисом просто добавить нужную запись в нужный upstream, и reverse proxy сам распределит трафик.
В качестве reverse proxy мы сейчас используем nginx —, но продолжаем рассматривать и иные варианты.
Кроме того, для деплоя мы используем технику Blue-Green Deployment — это означает, что одновременно могут работать сервисы как с новой, так и со старой функциональностью. И в этом случае reverse proxy опять же выручает, предоставляя возможность распределять трафик в нужных пропорциях между двумя версиями, и окончательно переходить на новую, только убедившись в ее полной работоспособности.
DNS
Когда мы стартовали разработку, Docker не имел достаточно развитых возможностей по организации сети. При этом мы хотели удобного обращения к микросервисам, недоступности бекенда извне, и вынесения каждого юнита в свою подсеть.
Поэтому мы решили этот вопрос собственными силами, подняв свой внутренний DNS. Теперь обращение к конкретному сервису происходит просто по его имени и имени юнита. На данный момент мы продолжаем использовать DNS, но попутно рассматриваем иные варианты, коих сейчас появляется все больше и больше.
Это, кстати, еще один плюс архитектуры микросервисов — внедрять новые инструменты, способные облегчить нам жизнь, ускорить выпуск новой функциональности, либо повысить надежность, довольно легко. Это также гарантирует, что у нас не будет проблемы legacy кода — устаревшие сервисы можно будет довольно легко заменять на их актуальные версии.
Заключение
Хочу сказать о результатах применения такого подхода.
После года работы с подобной архитектурой мы по-прежнему довольны выбранным подходом с использованием микросервисов. Несмотря на трудности, с которыми мы столкнулись, и новыми проблемами, которых не было раньше, подход в целом себя оправдал и поставленные задачи решает.
И конечно же, нам сильно облегчает жизнь Docker — для нас это отличный инструмент компоновки и доставки. Я смело могу рекомендовать его всем. И объединение подхода базирующегося на микросервисах с Docker дает целый ряд преимуществ в разработке, тестировании и тем более — в эксплуатации.
Наблюдая сейчас за бурным ростом числа статей, докладов и видео на тему микросервисов и Docker, я понимаю, что в свое время мы сделали верный выбор — хоть на тот момент это и казалось новым и непроверенным подходом. Поэтому рекомендую всем, кто начинает новый проект или хочет модифицировать старый, подумать над использованием микросервисов, Docker и деления на юниты.
Мы же, если будет интерес, готовы и дальше делиться теми знаниями которые приобрели за это время: о микросервисах на golang, мониторинге и тестировании, интерфейсе на базе ReactJS + Flux и многом другом.
Комментарии (2)
8 июля 2016 в 14:17
0↑
↓
Интересна конкретная реалзиация «диспечера».8 июля 2016 в 14:56
0↑
↓
Диспетчер построен на базе RabbitMQ плюс некоторые свои обвязки позволяющие либо объединять некоторые потоки событий, либо наоборот дробить в зависимости от нагружености и потребностей. События диспетчер рассылает используя push подход, то есть сервису не нужно держать коннект с диспетчером.
