Нагрузочное тестирование с locust. Часть 2
Для тех, кому понравилась моя предыдущая статья, продолжаю делится впечатлениями об инструменте для нагрузочного тестирования Locust.
Постараюсь наглядно показать преимущества написания нагрузочного теста python кодом, в котором можно удобно как подготавливать любые данные для теста, так и обрабатывать результаты.
Обработка ответов сервера
Иногда в нагрузочном тестировании недостаточно просто получить от сервера HTTP 200 OK. Случается, надо еще проверить содержимое ответа, чтобы убедится, что под нагрузкой сервер выдает правильные данные или проводит точные вычисления. Как раз для таких случаев в Locust добавили возможность переопределять параметры успешности ответа сервера. Рассмотрим следующий пример:
from locust import HttpLocust, TaskSet, task
import random as rnd
class UserBehavior(TaskSet):
@task(1)
def check_albums(self):
photo_id = rnd.randint(1, 5000)
with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response:
if response.status_code == 200:
album_id = response.json().get('albumId')
if album_id % 10 != 0:
response.success()
else:
response.failure(f'album id cannot be {album_id}')
else:
response.failure(f'status code is {response.status_code}')
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
В нем всего один запрос, который будет создавать нагрузку по следующему сценарию:
С сервера мы запрашиваем объекты photos со случайными id в диапазоне от 1 до 5000 и проверяем в этом объекте id альбома, предполагая, что он не может быть кратным 10
Тут сразу же можно дать несколько пояснений:
- устрашающую конструкцию with request () as response: можно успешно заменить на response = request () и спокойно работать с объектом response
- URL формируется с помощью синтаксиса формата строк, добавленном в python 3.6, если я не ошибаюсь — f'/photos/{photo_id}'. В предыдущих версиях эта конструкция работать не будет!
- новый аргумент, который мы раньше не использовали, catch_response=True, указывает Locust«у, что мы сами определим успешность ответа сервера. Если его не указывать, то мы точно так же получим объект ответа и сможем обрабатывать его данные, но не переопределять результат. Ниже будет подробный пример
- Еще один аргумент name='/photos/[id]'. Он нужен для группировки реквестов в статистике. Имя может быть любым текстом, повторять url не обязательно. Без него каждый запрос с уникальным адресом или параметрами будет записан отдельно. Вот как это работает:
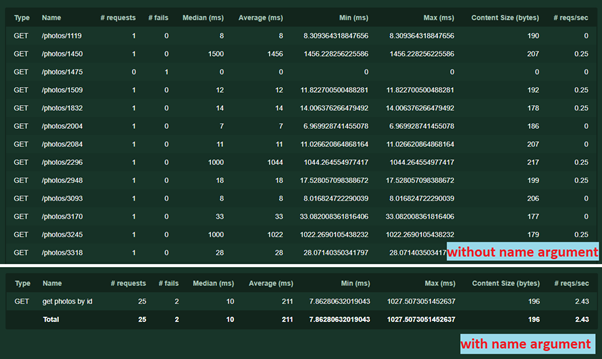
С помощью этого же аргумента можно выполнить и другой трюк — иногда бывает, что один сервис с разными параметрами (например, разным содержимым POST запросов) выполняет разную логику. Чтобы результаты работы теста не перемешались, можно написать несколько отдельных задач, указав для каждой свой аргумент name.
Дальше мы делаем проверки. У меня их 2. Сначала проверяем, что сервер вернул нам ответ if response.status_code == 200:
Если да, то проверяем, кратно ли id альбома 10. Если не кратный, то помечаем этот ответ как успешный response.success ()
В других случаях указываем, почему ответ провалился response.failure ('error text'). Этот текст будет отображаться на странице Failures во время выполнения теста.
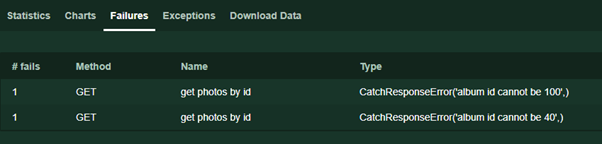
Так же внимательные читатели могли заметить отсутствие обработчиков исключений (Exceptions), характерных для кода, работающего с сетевыми интерфейсами. Действительно, в случае timeout, connection error и прочих непредвиденных происшествий, Locust сам обработает ошибки и все равно вернет ответ, указав, правда, статус код ответа равным 0.
Если же код все равно генерирует Exception, он будет записан на вкладке Exceptions во время выполнения, чтобы мы смогли его обработать. Самая типовая ситуация — в json«е ответа не вернулось искомое нами значение, но мы уже проводим над ним следующие операции.
Перед тем как, закрыть тему — в примере я использую json сервер для наглядности, так как легче обрабатывать ответы. Но с тем же успехом можно работать и с HTML, XML, FormData, вложенными файлами и другими данными, используемые протоколами на базе HTTP.
Работа со сложными сценариями
Почти каждый раз, когда ставится задача провести нагрузочное тестирование веб приложения, быстро становится ясно, что нельзя обеспечить достойное покрытие одними только GET сервисами — которые просто возвращают данные.
Классический пример: чтобы протестировать интернет магазин, желательно, чтобы пользователь
- Открыл главную магазина
- Искал товар
- Открыл детали товара
- Добавил товар в корзину
- Оплатил
Из примера можно предположить, что вызывать сервисы в случайном порядке не получится, только последовательно. Более того, у товаров, корзины и формы оплаты могут быть уникальные для каждого пользователя идентификаторы.
Пользуясь предыдущим примером, с небольшими доработками, можно легко реализовать тестирование такого сценария. Адаптируем пример под наш тестовый сервер:
- Пользователь пишет новый пост
- Пользователь пишет комментарий к новому посту
- Пользователь читает комментарий
from locust import HttpLocust, TaskSet, task
class FlowException(Exception):
pass
class UserBehavior(TaskSet):
@task(1)
def check_flow(self):
# step 1
new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'}
post_response = self.client.post('/posts', json=new_post)
if post_response.status_code != 201:
raise FlowException('post not created')
post_id = post_response.json().get('id')
# step 2
new_comment = {
"postId": post_id,
"name": "my comment",
"email": "test@user.habr",
"body": "Author is cool. Some text. Hello world!"
}
comment_response = self.client.post('/comments', json=new_comment)
if comment_response.status_code != 201:
raise FlowException('comment not created')
comment_id = comment_response.json().get('id')
# step 3
self.client.get(f'/comments/{comment_id}', name='/comments/[id]')
if comment_response.status_code != 200:
raise FlowException('comment not read')
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
В этом примере я добавил новый класс FlowException. После каждого шага, если он прошел не так, как ожидалось, я выбрасываю этот класс исключения, чтобы прервать сценарий — если пост создать не получилось, то нечего будет комментировать и т.д. При желании, конструкцию можно заменить обычным return, но в таком случае, во время исполнения и при анализе результатов будет не так хорошо видно, на каком шаге падает выполняемый сценарий на вкладке Exceptions. По этой же причине, я не использую конструкцию try… except.
Делаем нагрузку реалистичной
Сейчас меня можно упрекнуть — в случае с магазином все действительно линейно, но пример с постами и комментами слишком притянут за уши — читают посты раз в 10 чаще, чем создают. Резонно, давайте сделаем пример более жизненным. И тут есть минимум 2 подхода:
- Можно «захардкодить» список постов, которые пользователи читают, и упростить код теста, если есть такая возможность и функциональность бекэнда не зависит от конкретных постов
- Сохранять созданные посты и читать их, если нет возможности заранее задать список постов или реалистичность нагрузки сильно зависит от того, какие посты читаются (я убрал создание комментов из примера, чтобы сделать его код меньше и нагляднее)
from locust import HttpLocust, TaskSet, task
import random as r
class UserBehavior(TaskSet):
created_posts = []
@task(1)
def create_post(self):
new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'}
post_response = self.client.post('/posts', json=new_post)
if post_response.status_code != 201:
return
post_id = post_response.json().get('id')
self.created_posts.append(post_id)
@task(10)
def read_post(self):
if len(self.created_posts) == 0:
return
post_id = r.choice(self.created_posts)
self.client.get(f'/posts/{post_id}', name='read post')
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
В классе UserBehavior я создал список created_posts. Обратите особое внимание — это объект и он создан не в конструкторе класса __init__(), поэтому, в отличии от клиентской сессии, этот список — общий для всех пользователей. Первая задача создает пост и записывает его id в список. Вторая — в 10 раз чаще, читает один, случайно выбранный, пост из списка. Дополнительным условием второй задачи является проверка, есть ли созданные посты.
Если нам нужно, чтобы каждый пользователь оперировал только своими собственными данными, можно объявить их в конструкторе следующим образом:
class UserBehavior(TaskSet):
def __init__(self, parent):
super(UserBehavior, self).__init__(parent)
self.created_posts = list()
Еще немного возможностей
Для последовательного запуска задач официальная документация предлагает нам также использовать аннотацию задач @seq_task (1), в аргументе указывая порядковый номер задачи
class MyTaskSequence(TaskSequence):
@seq_task(1)
def first_task(self):
pass
@seq_task(2)
def second_task(self):
pass
@seq_task(3)
@task(10)
def third_task(self):
pass
В указанном примере каждый пользователь сначала выполнит first_task, потом second_task, потом 10 раз third_task.
Скажу честно — наличие такой возможности радует, но, в отличии от предыдущих примеров, непонятно, как передать результаты первого задачи во вторую при необходимости.
Так же, для особо сложных сценариев, есть возможность создавать вложенные наборы задач, по сути, создавая несколько классов TaskSet и соединяя друг с другом.
from locust import HttpLocust, TaskSet, task
class Todo(TaskSet):
@task(3)
def index(self):
self.client.get("/todos")
@task(1)
def stop(self):
self.interrupt()
class UserBehavior(TaskSet):
tasks = {Todo: 1}
@task(3)
def index(self):
self.client.get("/")
@task(2)
def posts(self):
self.client.get("/posts")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 1000
max_wait = 2000
В примере выше, с вероятностью 1 к 6 будет запущен сценарий Todo, и будет выполнятся, пока, с вероятностью 1 к 4, не вернется к сценарию UserBehavior. Здесь очень важно наличие вызова self.interrupt () — без него тестирование зациклится на подзадаче.
Спасибо, что дочитали. В завершающей статье напишу о распределенном тестировании и тестировании без UI, а также о сложностях, с которыми сталкивался в процессе тестирования с помощью Locust и как их обойти.
