Наблюдаемость сетевой инфраструктуры Kubernetes. Часть вторая
Кратко о второй части
Данная часть является продолжением статьи »Наблюдаемость сетевой инфраструктуры Kubernetes». В этой части будут разобраны сами инструменты, базирующиеся на ранее озвученных подходах (Service Mesh, eBPF monitoring и Distributed Tracing). Для сравнения решений будет выбран единый сценарий, при развёртывании которого собираются метрики приложения и кластера k8s.
C первой частью можно ознакомиться здесь.
Содержание
Среда развертывания Kubernetes кластера
ОС: MacOS
Управление контейнерами: Docker Desktop (v4.5.0).
Версия Kubernetes: v1.22.5.
Репозиторий микросервисного приложения: https://github.com/Google-CloudPlatform/microservices-demo
CPUs кластера: 4 ядра.
RAM кластера: 12.00/16.00 GB.
Инструменты для запуска локального кластера: kind (v0.17.0) / Minikube (v1.30.1).
Генерация нагрузки в кластере: Locust контейнер.
Docker Desktop — это платформа для разработки, доставки и запуска контейнерных приложений. Docker позволяет создавать контейнеры, автоматизировать их запуск и развертывание, управляет жизненным циклом, а также позволяет запускать множество контейнеров на одной хост-машине.
Kind — это реализация подхода Docker-in-Docker (DinD) для Kubernetes. Этот инструмент создает контейнеры, которые действуют как узлы Kubernetes.
Конфигурация для kind кластера:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
- role: worker
, где role: control-plane — master узел Kubernetes (размещаются инфраструктурные pod’ы k8s), role: worker — 3 рабочих узла, на которых запускаются микросервисы приложения microservices-demo.
Minikube — это инструмент, позволяющий легко запускать Kubernetes на локальной машине. Minikube запускает одноузловой кластер Kubernetes внутри виртуальной машины (VM) на компьютере пользователя.
Запуск кластера на minikube:
minikube start --driver=hyperkit --cni=flannel --cpus=4 --memory=12000 -p=demo-app
, где hyperkit — гипервизор для развертывания виртуальной машины на базе MacOS (пока для arm поддержки нет, можно использовать QEMU), flannel — базовый CNI для сетевого взаимодействия между pod’ами и сервисами.
Kind решение используется для инструментов service mesh (Istio и Linkerd) и Cilium CNI + Hubble; Minikube для инструментов, основанных на eBPF (Pixie, Weavescope, Coroot, Caretta), так как при подходе DinD eBPF не может полностью обнаружить все инфраструктурные объекты k8s (из-за большой вложенности контейнеров в контейнеры).
Locust — это простой в использовании, настраиваемый и масштабируемый инструмент тестирования производительности сетевого сервиса (в сценарии microservices-demo это запросы к frontend). Поведение пользователей определяется в Python коде. Через CLI/WEB UI можно задать количество пользователей, скорость их появления и период работы заданного сценария.
Формат выходных данных
Выходных данные получаются из двух решений:
Metrics Server — данные о CPUusage и RAMusage. Metrics Server использует API Kubernetes для отслеживания узлов и подов в кластере. Metrics Server запрашивает по HTTP у каждого узла состояние его подов и сохраняет их в кэше. Эта кэшированная информация о состоянии подов впоследствии доступна через API расширения, которые предоставляет сервер метрик, либо через cli запросы
kubectl resource-capacity -upиkubectl top.
Пример вывода kubectl resource-capacity -up:

Рисунок 1. Вывод команды kubectl resource-capacity -up.
В данном случае у кластера 4 ядра (4000m, соответственно, 631m CPUusage — 15% от всех ресурсов) и 12000 Mi (2023Mi RAMusage — 17% от всех ресурсов).
Locust API — отчёт в формате html о RPS, Failures/s и Latency, процентилей (синоним перцентиль) времени ответ, 50%ile,60%ile,70%ile,80%ile,90%ile,95%ile,99%ile. Так же строятся графики по основным метрикам (количество запросов, пользователей и ошибок с течением времени).
Пример отчёта Locust:

График 1. Количество запросов и ошибок в секунду.

График 2. Время ответа сервера (процентили 50%ile и 90%ile).

График 3. Количество пользователей.

Таблица 1. Статистика по запросам (типы запросов, общее количество за промежуток и т. д.).

Таблица 2. Статистика по ответам от сервера (процентили от 50%ile до 100%ile).
Экспериментальное исследование
Целью экспериментального исследования является рассмотрения сценария получения всей топологии сети в кластере Kubernetes (в сравнении с исходной микросервисной архитектурой). То есть информации о том, как общаются между собой узлы, поды и сервисы. А также исследование, какие дополнительные данные и фильтры предоставляет каждый из инструментов.

Рисунок 2. Схема демо приложения.
В качестве стенда будет использоваться ранее описанная архитектура
микросервисного магазина товаров (рисунок 2), по которой можно будет
судить, насколько точно каждый из сервисов определил объекты k8s и
способы их взаимодействия. В данной части будут рассмотрены следующие
проекты:
решение на основе прокси — Istio (и его модуль визуализации Kiali) и Linkerd (визуализация Linkerd Viz);
решения обнаруживающие объекты на основе eBPF со своим собственным UI — Cilium Hubble, Pixie, Weave Scope, Coroot;
решения на eBPF, данные которых можно визуализировать, только через сторонние UI (например, Grafana) — Caretta.
Подход распределенной трассировки встречается в решениях Pixie и Coroot, однако данный подход будет описан в отдельной части. В качестве итогов будет проведена таблица сравнения данных инструментов между собой, по ранее озвученным показателям потребления ресурсов и сетевым метрикам.
Настройка инфраструктуры
Считаю, что у вас уже в окружении установлены kind / minikube / kubectl / (qemu/hyperkit) / helm. И в зависимости от устанавливаемых инструментов их cli интерфейсы — istioctl / linkerd / cilium / hubble. Настройка кластера будет вестись через CLI, для удобства выкладываю немного измененный мною microservices-demo из Google Cloud, где, в частности, поменял настройки Locust, чтобы контейнер создавался с доступом к UI (там есть возможность выбора нагрузки по количеству пользователей и возможность выгрузки отчетов).
Настройка Kind окружения (для тестирования Service Meshes и Cilium CNI):
# случай с Kind {
kind create cluster --name k8s-demo-app --config release/kind-config.yaml
# } или
# случай с Minikube {
minikube start --driver=hyperkit --cni=flannel --cpus=4 --memory=12000 -p=demo-app
# };
kubectl get nodes
Как создать кастомный образ Locust (учитывая, что вы склонили мой репо) и протащить его в kind/minikube:
cd src/loadgenerator
docker buildx build -t man_loadgen:v0.0.1 --load .
docker images
# случай с Kind {
kind load docker-image man_loadgen:v0.0.1 --name k8s-demo-app
# } или
# случай с Minikube {
minikube image load man_loadgen:v0.0.1
# };
cd ../../release
kubectl apply -f kubernetes-manifests.yaml
kubectl get pods -A
Установка Metrics Server:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
kubectl -n kube-system patch deployment metrics-server --type=json -p='[{"op": "add", "path": "/spec/template/spec/containers/0/args/-", "value": "--kubelet-insecure-tls"}]]'
kubectl rollout restart deployment metrics-server -n kube-system
Прокладываем порты для UI Locust и Frontend демо приложения:
kubectl port-forward deployment/loadgenerator 8089:8089
kubectl port-forward deployment/frontend 8080:8080
Далее пойдут разборы различных решений и способ установки каждого из них.
Istio Kiali
Kiali — предоставляет фильтрацию по объектам, описанным вами в Service Mesh. Каждое представление (приложение, service, ребра) содержит информацию о здоровье (Health статус, определения YAML и ссылки, чтобы помочь визуализировать сеть Kubernetes). Также Kiali делит информацию по следующим классам:

Схема 1. App graph для k8s демо.
На схеме 1 изображено графовое представление архитектуры микросервисного приложения, где узлы представляют собой k8s сущность app, а ребра трафик, ходящий между ними. На скриншоте вершины были расставлены вручную, чтобы соответствовать исходной схеме, на самом деле у Kiali только четыре сценария по расположению и зафиксировать другое не получится (при обновлении ваша расстановка слетает).

Схема 2. Service Graph с добавленными метриками распределения и RPS трафика.
На схеме 2 (расстановка вершин по сценарию Kiali-dagre) узлы уже являются service сущностями. В данном случае можно увидеть, что один из узлов и связанное с ним ребро окрашены в красный. Данный health статус означает, что количество gRPC запросов возвращающих ошибку превышает 10% от всего количества, и одно серое ребро (TCP трафик, Kiali его не окрашивает, хотя информацию собирает, схема 3).

Схема 3. Фильтр только по TCP трафику и какие информация хранится о ребре.
Ошибки с Adservice (схема 2) связаны с нагрузкой от Loadgenerator, написанный на основе Python модуля Locust. В данном случае скрипт создаёт 300 пользователей, которые совершают покупки в магазине с разной периодичностью. Если уменьшить количество пользователей или увеличить CPU/Memory Limit для приложения Adservice, то можно добиться «зеленого» состояния для всех сервисов.

Схема 4. Service (треугольники) + App (квадраты) Graph с выводом RPS и распределения трафика (информация над ребрами).
На схеме 4 желтым окрашено приложение frontend из-за того, что часть его outbound трафика (6.3%), идущего на adservice, сбрасывается (43% error rate в моменте). Соответственно, ошибки в пределах от 0% до 10% всего исходящего трафика окрашиваются узел в желтый.
Важно отметить, что функциональность Kiali зависит от того, какие источники данных используются. Без Prometheus не будет выдаваться большинство информации (включая графовое представление), поэтому данное решение придется ставить по умолчанию (некоторые пытаются использовать Victoria Metrics, но по статьям/issues, что мне попадались, они сталкиваются с ошибками и сложностями при ее подключении). Если нужна дополнительная информация о трассе — разворачивайте Jaeger, кастомный dashboard из графаны — Grafana’у.
Команды по запуску Istio и Kiali на Kind кластере (через istioctl и helm):
kubectl label namespace demo istio-injection=enabled
# cd в папку release microservices-demo
istioctl install -f istio-manifests.yaml
istioctl install --set profile=demo -y
istioctl analyze -n demo
kubectl -n demo rollout restart deploy
helm repo add kiali https://kiali.org/helm-charts
helm repo update
helm install \
--set cr.create=true \
--set cr.namespace=istio-system \
--namespace kiali-operator \
--create-namespace \
kiali-operator \
kiali/kiali-operator
helm show values kiali/kiali-operator
kubectl get svc/kiali -n istio-system -o wide
kubectl port-forward svc/kiali 20001:20001 -n istio-system
kubectl -n istio-system create token kiali-service-account
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.17/samples/addons/prometheus.yaml
Linkerd Viz
Аналог Kiali в Linkerd Service Mesh — Linkerd Viz обеспечивает базовый интерфейс для визуализации сетевой топологии и метрик (без излишних дополнительных параметров и фильтров), что, в теории, должно быть более подходящим для использования в малых проектах. Linkerd Viz устанавливается вместе с Prometheus.
Linkerd Viz предоставляет возможность визуализировать метрики и топологию сервис-меша Linkerd. На схеме 5 показано единственное представление графа сервисов в WEB UI. Зафиксировать положение вершин и рёбер нельзя, все вершины «свалены» в одну кучу. Информацию от Linkerd также можно отправить на визуализацию в Grafana, но тогда UI сервиса Linkerd Viz теряет свою значимость.

Схема 5. Service Graph с выводом RPS/SR и задержки (для каждого из сервисов). Есть возможность экспорта данных в Grafana.
На схеме 6 присутствует более структурированное изображение взаимодействия сервисов, однако если рёбер у одного объекта слишком много (например, для сервиса frontend), то они не помещаются полностью в интерфейсе, что опять же вредит UX.

Схема 6. Вывод топологических связей (в удобном формате) для deployment/frontend. Уменьшить масштаб нельзя (только прокрутка вверх/вниз).
Команды по запуску Linkerd и Linkerd Viz на Kind кластере (через cli linkerd):
linkerd version
linkerd install
linkerd install --crds
linkerd install --crds | kubectl apply -f -
linkerd install | kubectl apply -f -
linkerd check
linkerd viz install | kubectl apply -f -
linkerd viz check
linkerd viz dashboard
Cilium Hubble UI
Hubble — это полностью распределенная платформа для наблюдения за сетями и безопасностью. Она построена на базе Cilium и eBPF для обеспечения глубокой видимости взаимодействия и поведения сервисов k8s.
Hubble устанавливается только вместе с Cilium, поэтому если при проектировании архитектуры k8s уже был выбран данный CNI, то Hubble становится практически необходимым для установки, так как нативно встраивает свой Server к Cilium агентам на узлах k8s и через gRPC запросы отправляет информацию на Hubble Relay. Который, в свою очередь, отправляет её на Hubble UI для визуализации.
Hubble позволяет отслеживать несколько уровней сетевого трафика, таких как TCP-соединения, DNS-запросы и HTTP-запросы в кластерах.

Схема 7. Весь граф сервисов в Hubble UI.
На схеме 7 изображены два основных раздела взаимодействия сервисов и проходящего сетевого трафика. Граф сервисов структурирован, однако в сравнении с Kiali UI, здесь труднее разглядеть направление рёбер, часть из них перекрывают друг друга и не хватает общей направленности от loadgenerator до самого удаленного по хопам сервиса redis-cart.

Схема 8. Выбран сервис frontend и фильтры для сетевых трасс в Hubble UI.
На схеме 8 выбран фильтр «от конкретного pod’a» frontend и его ближайшие соседи, также можно настроить фильтр по столбцам для сетевой трассы.
Команды по запуску Cilium (можно ставить и выше v1.13.2;)) Hubble на Kind кластере (через helm / cilium cli):
helm repo add cilium https://helm.cilium.io/
helm repo update
docker pull quay.io/cilium/cilium:v1.13.2
kind load docker-image quay.io/cilium/cilium:v1.13.2 --name k8s-demo-app
helm install cilium cilium/cilium --version 1.13.2 \
--namespace kube-system \
--set image.pullPolicy=IfNotPresent \
--set ipam.mode=kubernetes
cilium status
helm upgrade cilium cilium/cilium --version 1.13.2 \
--namespace kube-system \
--reuse-values \
--set hubble.relay.enabled=true \
--set hubble.ui.enabled=true
cilium hubble enable
cilium hubble ui
Coroot
Coroot — инструмент наблюдаемости построенный на основе eBPF (и с возможностью подключение распределенной трассы через OpenTelemetry). Coroot проводит аудит инфраструктуры k8s, который включает в себя:
преобразование метрик, описывающих любую систему, в модель этой системы;
проверку набора гипотез, чтобы подтвердить или опровергнуть наличие проблем в любой подсистеме;
предлагает список возможных исправлений вместе с деталями, касающимися каждой конкретной проблемы.
Принцип, по обнаружению схож с другими инструментами использующими eBPF. На каждом из узлов k8s устанавливается агент, анализирующий ходящий трафик и запросы к Kubernetes API. На схеме 9 изображена топология microservices-demo. Все сервисы были обнаружены правильно, отображение схоже с Kiali UI также для каждого сервиса выдаётся его состояния «здоровья».

Схема 9. Сетевой граф в Coroot.
На схеме 10 был выбран сервис frontend для дальнейшего обзора. На графе отобразились не только микросервисы демо приложения, но и kubelet из control plane.

Схема 10. Фильтр по сервису frontend в Coroot.
Схемы 11–12 предоставляют информацию по SLO и Profiling. Также есть
дополнительная информация в разделах Instances, CPU, MEMORY, Storage, Network, Logs и Deployments.

Схема 11. SLO (Service Level Objectives, цель уровня обслуживания) раздел сервиса frontend в Coroot.
На схеме 12 представлен так называемый Flame graph (строится через стороннее open-source решение Pyroscope).
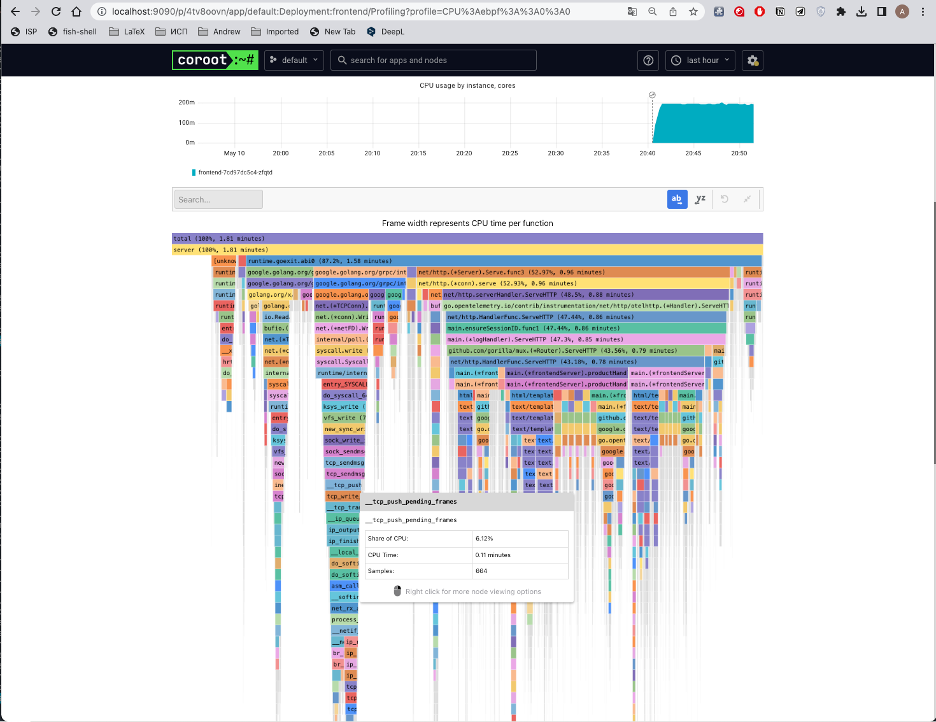
Схема 12. Flame graph использования CPU для frontend в Coroot.
На схемах 13–14 представлена информация об узлах кластера k8s и метриках
собираемых для данных объектов.

Схема 13. Обзор узлов в Coroot.

Схема 14. Собираемые метрики для узла в Coroot.
Команды по запуску Coroot на Kind кластере:
helm repo add coroot https://coroot.github.io/helm-charts
helm repo update
helm install --namespace coroot --create-namespace coroot coroot/coroot
Pixie
Pixie — это инструмент наблюдаемости с открытым исходным кодом для приложений Kubernetes. Pixie использует eBPF для автоматического сбора данных телеметрии без необходимости ручного инструментария.
Pixie может быть использован для просмотра высокоуровневого состояния кластера (карты сервисов, ресурсов кластера, трафика приложений), а также для более детального просмотра (состояния подов, flame graphs, распределенной трассы приложений).
Каждый из сценариев по наблюдению в Pixie — это отдельно запускаемый скрипт. Так на схемах 15–16 было запущено два скрипта для построения сетевой топологии. В первом сценарии с HTTP сервисами были обнаружены не все сервисы в demo приложении.

Схема 15. HTTP карта сервисов в Pixie.
Во втором скрипте Pixie строит Net Flow Graph. И здесь так же отсутствуют некоторые рёбра графа (исходный граф связный, а у Pixie, например, не нашлось ребра между сервисами frontend и recommendation), также отсутствуют сервисы email и loadgenerator.

Схема 16. Граф сетевых потоков в Pixie.
Как и в инструменте Coroot, на схемах 17–18 Pixie добавляет различные метрики и Flame graph’ы к исследуемым объектам кластера (правда Pixie сам строит Flame graph’ы).

Схема 17. Flame graph для frontend процессов в Pixie.

Схема 18. Собираемые метрики для frontend в Pixie.
Команды по запуску Pixie на Minikube (eBPF модули Pixie не смогут нормально функционировать в kind из-за сложной структуры DinD; можете убедиться в этом, подняв Pixie в kind инфраструктуре). Для установки потребуется VPN — так как установка идёт через Pixie Community Cloud (другие сценарии Self-Hosted/Air Gapped можно глянуть здесь):
bash -c "$(curl -fsSL https://withpixie.ai/install.sh)"
px auth login
px deploy
Caretta
Caretta — это легковесный автономный инструмент, который мгновенно создает визуальную карту сети сервисов, запущенных в кластере k8s.
Caretta использует eBPF для эффективного отображения всех сетевых взаимодействий сервисов в кластере k8s, а Grafana — для запросов и визуализации собранных данных. Caretta создавалась для эффективной работы, с минимумом потребляемых ресурсов и без модификации кластера (как инструменты Service mesh или CNI).
Визуализация решения представлена на схеме 19, где можно увидеть весь граф сервисов (не только microservices-demo, но и control plane) и нагрузку, оказываемую каждым из микросервисов.

Схема 19. Вид приборной панели Caretta в Grafana.
На схеме 20 выбран только карта сервисов для демо приложения, которая в точности совпадает с исходной схемой.

Схема 20. Карта сервисов в Caretta.
Команды по запуску Caretta на Minikube:
helm repo add groundcover https://helm.groundcover.com/
helm repo update
helm install caretta --namespace caretta --create-namespace groundcover/caretta
kubectl port-forward --namespace caretta 3000:3000
Weave Scope
Weave Scope — инструмент, который строит логические топологии приложения и инфраструктуры k8s. Важная информация про Weave Cloud.
Топология в Weave Scope — это набор узлов и ребер, где узлы представляют такие объекты, как процессы, контейнеры или хосты;, а ребра обозначают TCP-соединения между узлами. Типы узлов можно фильтровать (например, через функцию поиска), а конкретные микросервисы можно детально анализировать через просмотр конфигов, логов и подключения к терминалу контейнера. Узлы в Weave Scope располагаются в определенном порядке: клиенты выше серверов. Как правило, представление Weave Scope можно читать, двигаясь сверху вниз.
Weave Scope состоит из двух компонентов: scope-app и scope-probe. Эти компоненты развертываются как единый контейнер Docker с помощью сценария scope. Scope-probe отвечает за сбор информации о хосте, на котором он запущен. Эта информация отправляется в приложение в виде отчета. Scope-app обрабатывает отчеты scope-probe в пригодные для использования топологии и передает их в UI для визуализации.

Схема 21. Карта контроллеров в Weave Scope.
На схеме 22 карта подов в точности совпадает со исходной схемой демо
приложения.

Схема 22. Карта подов в Weave Scope.
На схемах 23–25 показаны возможности взаимодействия и получения
информации о подах и контейнерах прямо из интерфейса Weave Scope.

Схема 23. Конфиг и метрики пода paymentservice в Weave Scope.

Схема 24. Журнал событий пода paymentservice в Weave Scope.

Схема 25. Терминал и информация о контейнере redis в Weave Scope.
Weave Scope, как показано на схеме 26, также агрегирует статистику со
всех объектов для предоставления статистики по узлам k8s (в нашем случае
узел один — demo-app).

Схема 26. Статистика по узлу k8s с открытым окном одного из процессов в
Команды по запуску Weave Scope на Minikube:
kubectl apply -f https://github.com/weaveworks/scope/releases/download/v1.13.2/k8s-scope.yaml
kubectl port-forward -n weave "$(kubectl get -n weave pod --selector=weave-scope-component=app -o jsonpath='{.items..metadata.name}')" 4040
Результаты собранных показателей
В задачах работы ставилось сбор и исследование показателей CPUusage, RAMusage, RPS, Failures/s и процентилей времени ответа 50%ile, 90%ile, 95%ile, 99%ile. Рассмотрим полученные результаты прироста показателей после установки каждого из инструментов в виде итоговых таблиц.

Таблица 3. Динамика загрузки кластера (CPU / RAM) и запросов от пользователей (RPS / Failures/s) .

Таблица 4. Динамика времени ответа (Latency) пользователю в перцентилях.
Важно отметить, что Pixie хранит часть информации в облаке, из-за этого RAMusage меньше, чем у схожего решения Coroot. Однако это несёт свои проблемы, например, Pixie Cloud доступен только через VPN.
Динамику RPS в пределах 5% можно считать за погрешность измерений, так как каждый из сценариев длился по 1 часу. И при увеличении времени замеров Loadgenerator«а показатели были бы меньше волатильными.
Ошибки в доступе наблюдались только у Linkerd, причем с увеличением ресурсов для кластера и контейнеров проблема не исчезала.
По времени ответа (процентили) значительный прирост наблюдался только у решения Pixie. Причём для Pixie была создана инфраструктура с максимальным количеством выделенных ресурсов (6 ядер, 16GB RAM) и тестирование проходило с разным количеством пользователей (300, 100 и 50), однако во всех случаях наблюдался значительный прирост по времени ответа.
Cilium Hubble показал улучшение показателей RPS и времени ответа из-за того, что он разворачивался вместе с Cilium CNI, производительность которого по маршрутизации трафика заметно лучше стандартного решения от k8s.
Выводы
По результатам практического исследования можно сделать следующие выводы:
Все решения смогли частично или полностью отработать сценарий по построению топологии сетевого взаимодействия сервисов. Однако визуальное представление сильно отличается. Из положительных UI/UX можно отметить Istio Kiali и Coroot. Далее идёт Pixie. Затем Cilium CNI, Weave Scope и Caretta. Наиболее не читабельный вариант у Linkerd.
По нагрузке на CPU и RAM кластера очевидно наибольшее воздействие оказывают Service Mesh«ы, использующие sidecar модель. Coroot и Pixie близки по предоставляемому функционалу и по генерируемой нагрузке. При учёте если хранить информацию локально, RAMusage у Pixie будет приближаться к Coroot. Решение Cilium Hubble с CNI оказалось не сильно воздействующим на инфраструктуру.
Groundcover Caretta самое легковесное решение, но и из функционала имеется только построение карты сервисов. Однако у самого проекта Groundcover имеются другие интересные инструменты и решения по Observability (например, fork Grafana и murre)
Weave Scope в целом одно из самых оптимальных по всем показателям решение (также можно подключать дополнительные плагины), однако выход новых релизов остановился (статус проекта deprecated) и поддержка ведётся одним человеком.
Coroot обладает похожим с Istio Kiali свойством для узлов: контроль состояния, здоровья объектов k8s с дополнительным аудитом. Так же, как и Pixie, Coroot имеет возможность добавления распределенной трассы в свой UI при помощи автоматической и ручной настройки микросервисов для различных сред разработки (Go, Java и пр.). С учетом, что Weave Scope не поддерживается, является самым оптимальным «решением из коробки».
New Relic Pixie, использующий eBPF, показал наихудший результат по динамике увеличения времени ответа от демо приложения. То есть при использовании у себя в проектах потребуется убирать ненужное для увеличения эффективности решения. Либо использовать только на начальных этапах разработки инфраструктуры и проверки гипотез.
P.S.
Что дальше?
В дальнейшем планируется дополнять таблицу невошедшими и новыми решениями, а также обновлять статус по уже разобранным, проводить тестирование на крупном кластере. Также если у вас есть инструменты, которые бы вы хотели сравнить/узнать о них больше — оставляйте ссылки в комментариях!
