На пути к бессерверным базам данных — как и зачем
Всем привет! Меня зовут Голов Николай. Раньше я работал в Авито и шесть лет руководил Data Platform, то есть занимался всеми базами: аналитическими (Vertica, ClickHouse), потоковыми и OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). За это время я разобрался с большим количеством баз данных — самых разных и необычных, и с нестандартными кейсами их использования.
Сейчас я работаю в ManyChat. По сути это стартап — новый, амбициозный и быстро растущий. И когда я только вышел в компанию, возник классический вопрос: «А что сейчас стоит брать молодому стартапу с рынка СУБД и баз данных?».
В этой статье, основанной на моем докладе на онлайн-фестивале РИТ++2020, отвечу на этот вопрос. Видеоверсия доклада доступна на YouTube.
Общеизвестные базы данных 2020 года
На дворе 2020 год, я огляделся и увидел три типа БД.
Первый тип — классические OLTP базы: PostgreSQL, SQL Server, Oracle, MySQL. Они написаны давным-давно, но по-прежнему актуальны, потому что хорошо знакомы сообществу разработчиков.
Второй тип — базы из «нулевых». Они пытались уйти от классических шаблонов путем отказа от SQL, традиционных структур и ACID, за счёт добавления встроенного шардирования и других привлекательных фич. Например, это Cassandra, MongoDB, Redis или Tarantool. Все эти решения хотели предложить рынку что-то принципиально новое и заняли свою нишу, потому что в определенных задачах оказались крайне удобными. Эти базы обозначу зонтичным термином NOSQL.
«Нулевые» закончились, к NOSQL базам привыкли, и мир, с моей точки зрения, сделал следующий шаг — к managed базам. У этих баз ядро то же, что и у классических OLTP баз или новых NoSQL. Но у них нет потребности в DBA и DevOps и они крутятся на управляемом железе в облаках. Для разработчика это «просто база», которая где-то работает, а как она установлена на сервере, кто настроил сервер и кто его обновляет, никого не волнует.
Примеры таких баз:
- AWS RDS — managed обертка над PostgreSQL/MySQL.
- DynamoDB — AWS аналог document based базы, похоже на Redis и MongoDB.
- Amazon Redshift — managed аналитическая база.
В основе это старые базы, но поднятые в managed среде, без необходимости работы с железом.
Примечание. Примеры взяты для среды AWS, но их аналоги существуют также в Microsoft Azure, Google Cloud, или Яндекс.Облаке.

Что же из этого нового? В 2020 году ничего из этого.
Концепция Serverless
Действительно новое на рынке в 2020 году — это serverless или бессерверные решения.
Попытаюсь объяснить, что это значит, на примере обычного сервиса или бэкенд-приложения.
Чтобы развернуть обычное бэкенд-приложение, покупаем или арендуем сервер, копируем на него код, опубликовываем наружу endpoint и регулярно платим за аренду, электричество и услуги дата-центра. Это стандартная схема.
Можно ли как-то иначе? C бессерверными сервисами можно.
В чем фокус этого подхода: нет сервера, нет даже аренды виртуального instance в облаке. Для развертывания сервиса копируем код (функции) в репозиторий и опубликовываем наружу endpoint. Дальше просто платим за каждый вызов этой функции, полностью игнорируя аппаратное обеспечение, где она выполняется.
Попытаюсь проиллюстрировать этот подход на картинках.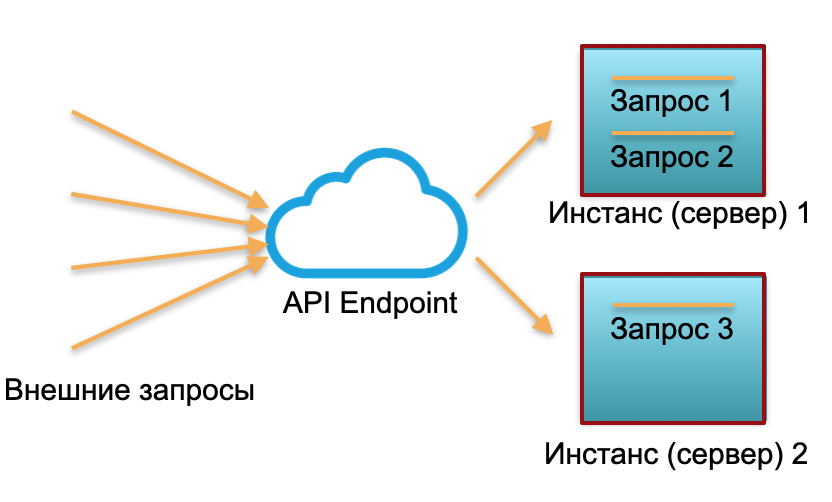
Классический деплой. У нас есть сервис с определенной нагрузкой. Поднимаем два инстанса: физические серверы или инстансы в AWS. На эти инстансы направляются внешние запросы, которые там обрабатываются.
Как видно на картинке, серверы утилизированы неодинаково. Один утилизирован на 100%, там два запроса, а один только на 50% — частично простаивает. Если придет не три запроса, а 30, то вся система не справится с нагрузкой и начнет тормозить.

Бессерверный деплой. В бессерверном окружении у подобного сервиса нет инстансов и серверов. Есть некоторый пул разогретых ресурсов — маленьких подготовленных Docker-контейнеров с развернутым кодом функции. Система получает внешние запросы и на каждый из них бессерверный фреймворк поднимает маленький контейнер с кодом: обрабатывает именно этот запрос и убивает контейнер.
Один запрос — один поднятый контейнер, 1000 запросов — 1000 контейнеров. А развертывание на железных серверах — это уже работа облачного провайдера. Она полностью скрыта бессерверным фреймворком. В этой концепции мы платим за каждый вызов. Например, пришел один вызов в день — мы заплатили за один вызов, пришел миллион в минуту — заплатили за миллион. Или в секунду, такое тоже бывает.
Концепция публикации бессерверной функции подходит для stateless сервиса. А если вам нужен (state) statefull сервис, то к сервису добавляем базу данных. В этом случае, когда доходит до работы со state, с состоянием, каждая statefull функция просто пишет и читает из базы данных. Причем из базы данных любого из трех типов, описанных в начале статьи.
Какое общее ограничение у всех этих баз? Это расходы на постоянно используемый облачный или железный сервер (или несколько серверов). Неважно, используем классическую базу или managed, есть Devops и админ или нет, всё равно 24 на 7 платим за железо, электричество и аренду дата-центра. Если у нас классическая база, мы платим за master и slave. Если высоконагруженная шардированная база — платим за 10, 20 или 30 серверов, и платим постоянно.
Наличие в структуре расходов постоянно зарезервированных серверов раньше воспринималось как неизбежное зло. Есть у обычных баз и другие сложности, такие как лимиты на количество подключений, ограничение масштабирования, геораспределенный консенсус — их как-то можно решить в определенных базах, но не все сразу и не идеально.
Serverless база данных — теория
Вопрос 2020 года: можно ли базу данных тоже сделать serverless? Все слышали про serverless бэкенд…, а давайте и базу данных попробуем сделать serverless?
Это звучит странно, потому что база данных — это же statefull сервис, не очень подходящий для serverless инфраструктуры. При этом, и state у базы данных очень большой: гигабайты, Терабайты, а в аналитических базах даже петабайты. Его так просто в легковесных Docker-контейнерах не поднять.
С другой стороны, практически все современные базы — это огромное количество логики и компонентов: транзакции, согласование целостности, процедуры, реляционные зависимости и много логики. Довольно большой части логики базы данных достаточно небольшого state. Гигабайты и Терабайты непосредственно используются только небольшой частью логики базы данных, связанной с непосредственным выполнением запросов.
Соответственно, идея: если часть логики допускает stateless исполнение, почему бы не распилить базу на Stateful и Stateless части.
Serverless для OLAP решений
Давайте посмотрим, как может выглядеть распилка базы данных на Stateful и Stateless части на практических примерах.
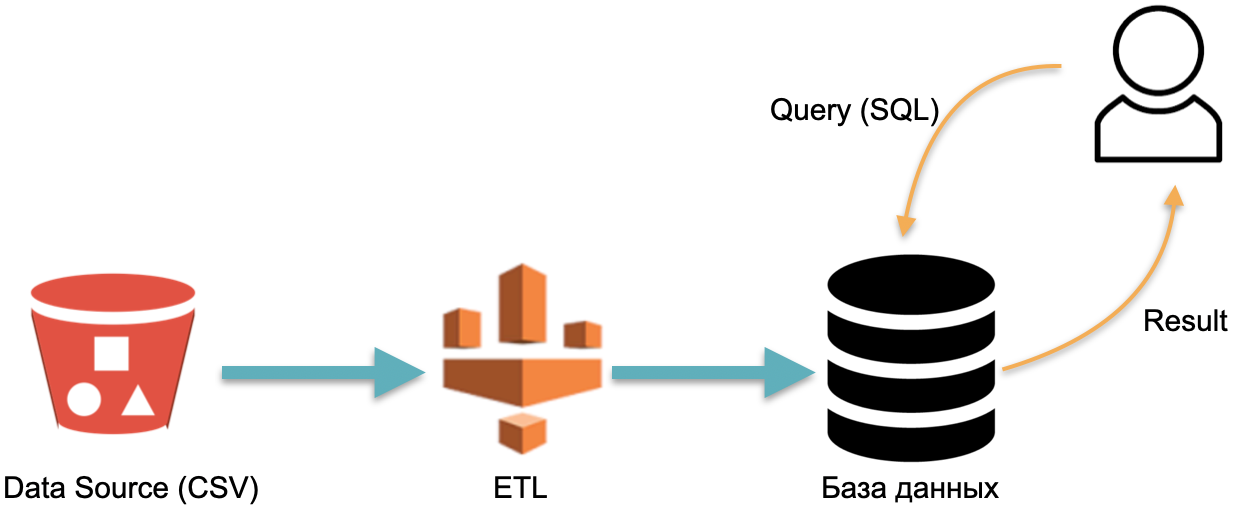
Например, у нас есть аналитическая база данных: внешние данные (красный цилиндр слева), ETL-процесс, который загружает данные в базу, и аналитик, который отправляет к базе SQL-запросы. Это классическая схема работы хранилища данных.
В этой схеме, условно, один раз выполняется ETL. Дальше нужно все время платить за серверы, на которых работает база с данными, залитыми ETL, чтобы было к чему кидать запросы.
Рассмотрим альтернативный подход, реализованный в базе AWS Athena Serverless. Здесь нет постоянно выделенного железа, на котором хранятся загруженные данные. Вместо этого:
- Пользователь отправляет SQL-запрос к Athena. Оптимизатор Athena анализирует SQL-запрос и ищет в хранилище метаданных (Metadata) конкретные данные, нужные для выполнения запроса.
- Оптимизатор, на основе собранных данных, выгружает нужные данные из внешних источников во временное хранилище (временную базу данных).
- Во временном хранилище выполняется SQL-запрос от пользователя, результат возвращается пользователю.
- Временное хранилище очищается, ресурсы высвобождаются.
В этой архитектуре мы платим только за процесс выполнение запроса. Нет запросов — нет расходов.
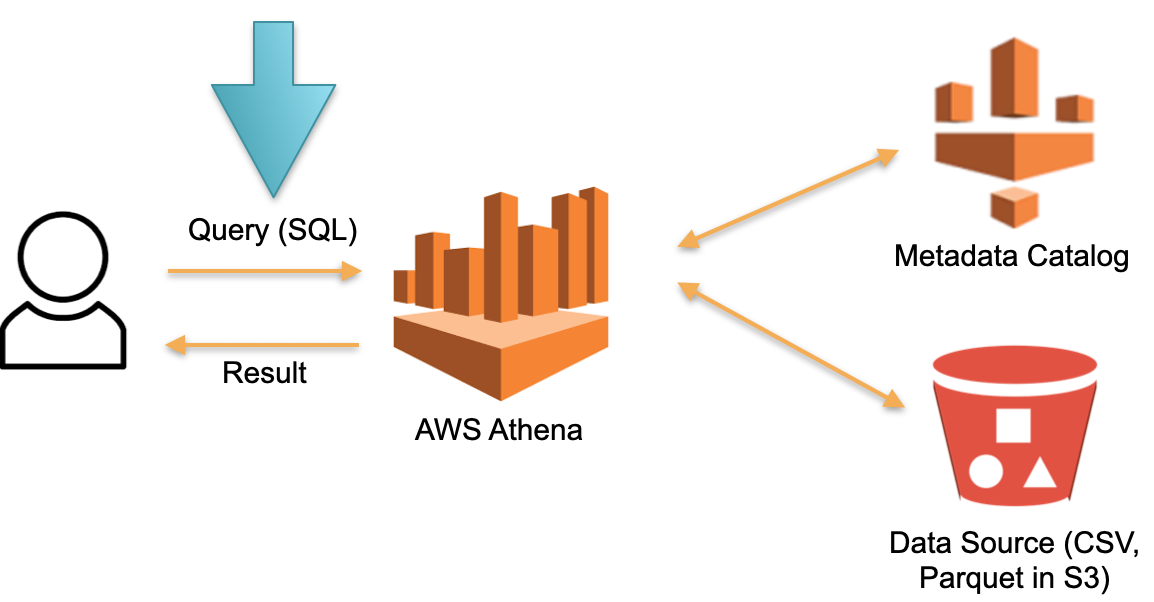
Это рабочий подход и он реализуется не только в Athena Serverless, но и в Redshift Spectrum (в AWS).
На примере Athena видно, что Serverless база данных работает на реальных запросах с десятками и сотнями Терабайт данных. Для сотен Терабайт понадобятся сотни серверов, но нам не нужно за них платить — мы платим за запросы. Скорость каждого запроса (очень) низка по сравнению со специализированными аналитическими базами типа Vertica, но зато мы не оплачиваем периоды простоя.
Такая база данных применима для редких аналитических ad-hoc запросов. Например, когда мы спонтанно решим проверить гипотезу на каком-то гигантском объеме данных. Для этих кейсов Athena подходит идеально. Для регулярных запросов такая система выходит дорого. В этом случае кешируйте данные в каком-то специализированном решении.
Serverless для OLTP решений
В предыдущем примере рассматривались OLAP-задачи (аналитические). Теперь рассмотрим OLTP-задачи.
Представим масштабируемый PostgreSQL или MySQL. Давайте поднимем обычный managed instance PostgreSQL или MySQL на минимальных ресурсах. Когда на инстанс будет приходить больше нагрузки, мы будем подключать дополнительные реплики, на которые распределим часть читающей нагрузки. Если запросов и нагрузки нет — отключаем реплики. Первый инстанс — это мастер, а остальные — реплики.
Эта идея реализована в базе под названием Aurora Serverless AWS. Принцип простой: запросы от внешних приложений принимает proxy fleet. Видя рост нагрузки, он выделяет вычислительные ресурсы из предварительно прогретых минимальных инстансов — подключение выполняется максимально быстро. Отключение инстансов происходит так же.
В рамках Aurora есть понятие Aurora Capacity Unit, ACU. Это (условно) — инстанс (сервер). Каждый конкретный ACU может быть master или slave. Каждый Capacity Unit обладает своей оперативной памятью, процессором и минимальным диском. Соответственно, один master, остальные read only реплики.
Количество этих работающих Aurora Capacity Units — это настраиваемый параметр. Минимальное количество может быть один или ноль (в таком случае база не работает, если нет запросов).

Когда база получает запросы, proxy fleet поднимает Aurora CapacityUnits, увеличивая производительные ресурсы системы. Возможность увеличивать и уменьшать ресурсы позволяет системе «жонглировать» ресурсами: автоматически выводить отдельные ACU (подменяя их новыми) и накатывать на выведенные ресурсы все актуальные обновления.
База Aurora Serverless может масштабировать читающую нагрузку. Но в документации об этом не сказано прямо. Может возникнуть ощущение, что они могут поднимать multi-master. Волшебства же никакого нет.
Эта база хорошо подходит, чтобы не тратить огромные деньги на системы с непредсказуемым доступом. Например, при создании MVP или маркетинговых сайтов-визиток, мы обычно не ожидаем стабильной нагрузки. Соответственно, при отсутствии доступа, мы не платим за инстансы. Когда неожиданно возникает нагрузка, например, после конференции или рекламной кампании, толпы людей заходят на сайт и нагрузка резко растет, Aurora Serverless автоматически принимает эту нагрузку и быстро подключает недостающие ресурсы (ACU). Дальше конференция проходит, все забывают про прототип, сервера (ACU) гаснут, и расходы падают до нуля — удобно.
Это решение не подходит для стабильного высокого highload, потому что оно не умеет масштабировать пишущую нагрузку. Все эти подключения и отключения ресурсов происходят в момент так называемого «scale point» — момента времени, когда базу не держит транзакция, не держат временные таблицы. Например, в течении недели scale point может и не случиться, и база работает на одних ресурсах и просто не может ни расшириться, ни сжаться.
Волшебства нет — это обычный PostgreSQL. Но процесс добавления машин и отключения частично автоматизирован.
Serverless by design
Aurora Serverless это старая база, переписанная под облака, чтобы использовать отдельные преимущества Serverless. А теперь расскажу о базе, которая изначально написана под облака, под serverless подход — Serverless-by-design. Её сразу разрабатывали без предположения о том, что она работает на физических серверах.
Эта база называется Snowflake. В ней три ключевых блока.
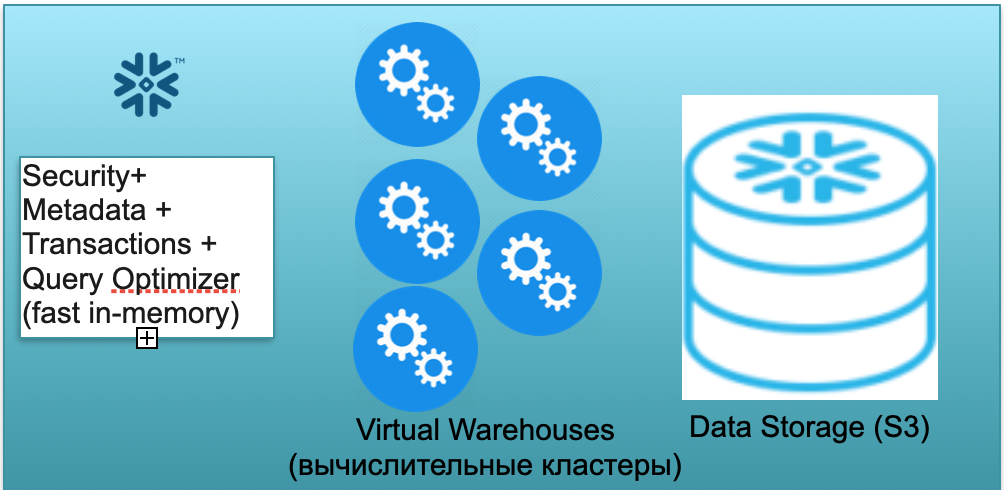
Первый — это блок метаданных. Это быстрый in-memory сервис, который решает вопросы с безопасностью, метаданными, транзакциями, оптимизацией запроса (на иллюстрации слева).
Второй блок — это множество виртуальных вычислительных кластеров для расчетов (на иллюстрации — набор синих кружков).
Третий блок — система хранения данных на базе S3. S3 — это безразмерное объектное хранилище в AWS, нечто вроде безразмерного Dropbox для бизнеса.
Давайте посмотрим, как Snowflake работает, в предположении о холодном старте. То есть база есть, данные в нее загружены, работающих запросов нет. Соответственно, если к базе нет запросов, то у нас поднят быстрый in-memory Metadata сервис (первый блок). И у нас есть хранилище S3, где лежат данные таблиц, разбитые на так называемые микропартиции. Для простоты: если в таблице лежат сделки, то микропартиции — это дни сделок. Каждый день — это отдельная микропартиция, отдельный файлик. И когда база работает в таком режиме, вы платите только за место, занимаемое данными. Причем тариф за место очень низкий (особенно с учетом значительного сжатия). Сервис метаданных тоже работает постоянно, но для оптимизации запросов много ресурсов не нужно, и сервис можно считать условно-бесплатным.
Теперь представим, что к нашей базе пришел пользователь и кинул SQL-запрос. SQL-запрос сразу поступает на обработку в Metadata сервис. Соответственно, получив запрос, этот сервис анализирует запрос, доступные данные, полномочия пользователя и, если все хорошо, составляет план обработки запроса.
Далее сервис инициирует запуск вычислительного кластера. Вычислительный кластер — это кластер из серверов, которые выполняют вычисления. То есть это кластер, который может содержать 1 сервер, 2 севера, 4, 8, 16, 32 — сколько захотите. Вы кидаете запрос и под него мгновенно начинается запуск этого кластера. Это реально занимает секунды.
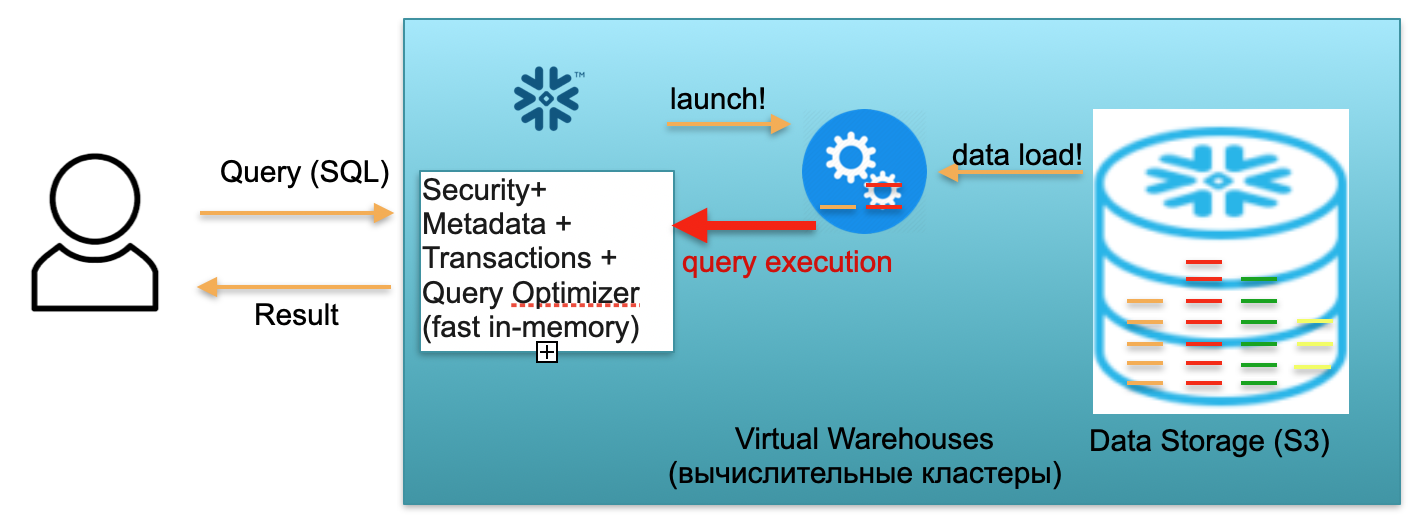
Далее, после того, как кластер стартовал, в кластер из S3 начинают копироваться микропартиции, нужные для обработки именно вашего запроса. То есть, представим, что для выполнения SQL-запроса нужно две партиции из одной таблицы и одна из второй. В таком случае в кластер будут скопированы только три нужные партиции, а не все таблицы целиком. Именно поэтому и именно из-за того, что всё находится в рамках одного дата-центра и соединено очень быстрыми каналами, весь процесс перекачки происходит очень быстро: за секунды, очень редко — за минуты, если речь не идет про какие-то чудовищные запросы. Соответственно, микропартиции копируются на вычислительный кластер, и, по завершении, на этом вычислительном кластере выполняется SQL запрос. Результатом этого запроса может быть одна строчка, несколько строчек или таблица — они отправляются наружу пользователю, чтобы он выгрузил, отобразил у себя в BI инструменте, или еще как-нибудь использовал.
Каждый SQL запрос может не только считать агрегаты из ранее загруженных данных, но и загружать/формировать новые данные в базе. То есть это может быть запрос, который, например, осуществляет вставку в другую таблицу новых записей, что приводит к появлению новой партиции на вычислительном кластере, которая, в свою очередь, автоматически сохраняется в едином S3 хранилище.
Описанный выше сценарий, от прихода пользователя до поднятия кластера, загрузка данных, выполнение запросов, получение результатов, оплачивается по тарифу за минуты использования поднятого виртуального вычислительного кластера, виртуального warehouse. Тариф варьируется в зависимости от зоны AWS и размера кластера, но, в среднем, это несколько долларов в час. Кластер из четырех машин в два раза дороже, чем из двух машин, из восьми машин еще в два раза дороже. Доступны варианты из 16, 32 машин, в зависимости от сложности запросов. Но вы платите только за те минуты, когда кластер реально работает, потому что, когда запросов нет, вы как бы убираете руки, и после 5–10 минут ожидания (настраиваемый параметр) он сам погаснет, освободит ресурсы и станет бесплатным.
Совершенно реален сценарий, когда вы кидаете запрос, кластер всплывает, условно говоря, за минуту, ещё минуту он считает, дальше пять минут на выключение, и вы платите в итоге за семь минут работы этого кластера, а не за месяцы и годы.
Первый сценарий описывал использование Snowflake в однопользовательском варианте. Теперь давайте представим, что пользователей много, что уже ближе к реальному сценарию.
Предположим, у нас есть много аналитиков и Tableau отчетов, которые постоянно бомбардируют нашу базу большим количеством несложных аналитических SQL-запросов.
Помимо этого, допустим, что у нас есть изобретательные Data Scientists, которые пытаются делать с данными чудовищные вещи, оперировать десятками Терабайт, анализировать миллиарды и триллионы строк данных.
Для описанных выше двух типов нагрузки Snowflake позволяет поднимать несколько независимых вычислительных кластеров разной мощности. Причем эти вычислительные кластера работают независимо, но с общими согласованными данными.
Для большого количества легких запросов можно поднять 2–3 небольших кластера, размером, условно, 2 машины каждый. Это поведение реализуемо, в том числе, с помощью автоматических настроек. То есть вы говорите: «Snowflake, подними маленький кластер. Если нагрузка на него вырастет больше определенного параметра, подними аналогичный второй, третий. Когда нагрузка начнет спадать — гаси лишние». Чтобы вне зависимости от того, сколько аналитиков приходит и начинает смотреть отчеты, всем хватало ресурсов.
При этом, если аналитики спят, и отчеты никто не смотрит — кластера могут полностью погаснуть, и платить за них вы перестаете.
При этом, для тяжелых запросов (от Data Scientists), вы можете поднять один очень большой кластер на условные 32 машины. Этот кластер тоже будет оплачиваться только за те минуты и часы, когда там работает ваш гигантский запрос.
Описанная выше возможность позволяет разделять по кластерам не только 2, но и больше видов нагрузки (ETL, мониторинг, материализация отчетов, …).
Подведем итог по Snowflake. База сочетает красивую идею и работоспособную реализацию. В ManyChat мы используем Snowflake для аналитики всех имеющихся данных. Кластеров у нас не три, как в примере, а от 5 до 9, разных размеров. У нас есть условные 16-машинные, 2-машинные, есть и супер-маленькие 1-машинные для некоторых задач. Они успешно распределяют нагрузку и позволяют нам здорово экономить.
База успешно масштабирует читающую и пишущую нагрузку. Это огромное отличие и огромный прорыв по сравнению с той же «Авророй», которая тянула только читающую нагрузку. Snowflake позволяет масштабировать этими вычислительными кластерами и пишущую нагрузку. То есть, как я упомянул, у нас в ManyChat используется несколько кластеров, маленькие и супермаленькие кластеры в основном используются для ETL, для загрузки данных. А аналитики живут уже на средних кластерах, которые абсолютно не затронуты ETL-нагрузкой, поэтому работают очень быстро.
Соответственно, база хорошо подходит для OLAP-задач. При этом, к сожалению, для OLTP-нагрузок она еще не применима. Во-первых, эта база колоночная, со всеми вытекающими последствиями. Во-вторых, сам подход, когда на каждый запрос по необходимости вы поднимаете вычислительный кластер и проливаете его данными, к сожалению, для OLTP-нагрузок еще недостаточно быстрый. Секунды ожидания для OLAP-задач — это нормально, а для OLTP-задач — неприемлемо, лучше бы 100 мс, а ещё лучше — 10 мс.
Итог
Serverless база данных возможна за счет разделения базы данных на Stateless и Stateful части. Вы, должно быть, обратили внимание, что во всех приведенных примерах, Stateful часть — это, условно говоря, хранение микропартиций в S3, а Stateless — это оптимизатор, работа с мета-данные, обработка вопросов безопасности, которые могут быть подняты как независимые легковесные Stateless сервисы.
Выполнение SQL-запросов тоже можно воспринять как сервисы с легким state, которые могут всплыть в бессерверном режиме, как вычислительные кластера Snowflake, скачать только нужные данные, выполнить запрос и «погаснуть».
Serverless базы продакшен уровня уже доступны для использования, они работают. Эти serverless базы уже готовы справляться с OLAP-задачами. К сожалению, для OLTP-задач они применяются… с нюансами, так как есть ограничения. С одной стороны, это минус. Но, с другой стороны, это возможность. Возможно, кто-то из читателей найдет способ, как OLTP-базу сделать полностью serverless, без ограничений Aurora.
Надеюсь, вам было интересно. За Serverless будущее:)
