[recovery mode] Мониторинг производственного оборудования: как с этим дела в России

Привет, Хабр! Наша команда занимается мониторингом станков и разных установок по всей стране. По сути, мы обеспечиваем возможность производителю не гонять лишний раз инженера, когда «ой, оно всё сломалось», а на деле надо нажать одну кнопку. Или когда сломалось не на оборудовании, а рядом.
Базовая проблема следующая. Вот вы производите установку для крекинга нефти, либо станок для машиностроения, либо какое-то другое устройство для завода. Как правило, продажа сама по себе крайне редко возможна: обычно это контракт на поставку и обслуживание. То есть вы гарантируете, что железяка будет работать лет 10 без перебоев, а за перебои отвечаете либо финансово, либо обеспечиваете жёсткие SLA, либо что-то подобное.
По факту это означает, что вам нужно регулярно отправлять инженера на объект. Как показывает наша практика, от 30 до 80% выездов — лишние. Первый случай — можно было бы разобраться, что случилось, удалённо. Либо попросить оператора нажать пару кнопок — и всё заработает. Второй случай — «серые» схемы. Это когда инженер выезжает, ставит в регламент замену или сложные работы, а сам делит компенсацию пополам с кем-то с завода. Или просто наслаждается отдыхом с любовницей (реальный случай) и поэтому любит выезжать почаще. Завод не против.
Установка мониторинга требует модификации железа устройством передачи данных, самой передачи, какого-то озера данных для их накопления, разбора протоколов и среды обработки с возможностью всё посмотреть и сопоставить. Ну и с этим всем есть нюансы.
Почему нельзя обойтись без удалённого мониторинга?
Банально дорого. Командировка для одного инженера — минимум 50 тысяч рублей (самолёт, гостиница, проживание, суточные). Плюс не всегда получается разорваться, и один и тот же человек может быть нужен в разных городах.
- В России поставщик и потребитель почти всегда достаточно далеко находятся друг от друга. Когда вы продали изделие в Сибирь, вы ничего, кроме того, что вам скажет поставщик, о нём не знаете. Ни как оно работает, ни в каких условиях эксплуатируется, ни, собственно, кто там кривыми руками какую кнопку нажал — этой информации объективно у вас нет, вы её можете знать только со слов потребителя. Это очень усложняет обслуживание.
- Необоснованные обращения и претензии. То есть ваш заказчик, эксплуатирующий ваше изделие, в любой момент может позвонить, написать, пожаловаться и сказать, что ваша штука не работает, она плохая, она сломалась, приезжайте срочно и чините. Если вам повезло и это не просто «не залили расходник», то вы не зря отправили специалиста. Часто бывает так, что полезная работа занимала меньше часа, а всё остальное — подготовка командировки, перелёты, проживание, — всё это потребовало кучу времени инженера.
- Бывают явно необоснованные претензии, и, чтобы это доказать, нужно отправить инженера, составить акт, обратиться в суд. В результате этого процесс затягивается, и ничего хорошего ни для заказчика, ни для вас это вообще не несёт.
- Споры возникают из-за того, что, например, заказчик неправильно эксплуатировал изделие, заказчик по каким-то причинам имеет на вас зуб и не говорит о том, что ваше изделие работало неправильно, не в тех режимах, которые заявлены в ТЗ и в паспорте. При этом противопоставить ему вы ничего не можете или можете, но с трудом, если, например, ваше изделие как-то ведёт логирование и запись тех режимов. Поломки по вине заказчика — это происходит вообще сплошь и рядом. У меня был случай, когда дорогущий немецкий портальный станок сломался из-за наезда на столб. Оператор не делал привязку к нулю, и в результате там станок встал. Причём заказчик совершенно чётко сказал: «А мы тут ни при чём». Но логировалась информация, и можно было эти логи поднять и понять, на какой управляющей программе и в результате чего произошёл этот самый наезд. Это спасло очень большие расходы поставщика в связи с гарантийным ремонтом.
- Упомянутые «серые» схемы — сговор с сервисником. Сервисник ездит к заказчику постоянно один и тот же. Ему говорят: «Слушай, Коль, давай знаешь как сделаем: ты напишешь, что у нас тут всё поломалось, компенсацию получим, или привезёшь для ремонта какой-то зип. Мы всё это тихой сапой реализуем, деньги поделим». Остаётся либо верить, либо как-то измысливать какие-то сложные пути проверки этих всех умозаключений, подтверждений, что не прибавляет ни времени, ни нервов, и ничего хорошего в этом не происходит. Если вы знакомы с тем, как автосервисы борются с мошенничествами по гарантии и сколько сложностей это накладывает на процессы, то примерно понимаете проблему.
Ну так все же устройства пишут лог, правда? В чём проблема?
Проблема в том, что если поставщики более-менее понимают, что лог нужно постоянно писать куда-то (или поняли за последние несколько десятков лет), то дальше культура не пошла. Лог часто нужен для разбора случаев с дорогостоящим ремонтом — была ли это ошибка оператора или реальная поломка оборудования.
Чтобы забрать лог, часто нужно подойти физически к оборудованию, открыть какой-то кожух, обнажить сервисный разъём, подключить к нему кабель и забрать файлы данных. Потом упорно грепать их несколько часов, чтобы получить картину ситуации. Увы, но так происходит почти везде (ну либо у меня однобокая точка зрения, поскольку мы работаем как раз с теми производствами, где мониторинг только налаживается).
Наши основные клиенты — производители оборудования. Как правило, они начинают задумываться о том, что стоит как-то заняться мониторингом, либо после какого-то крупного инцидента, либо просто глядя на счета за командировки за год. Но чаще всё же речь идёт о крупном сбое с потерей денег или репутации. Прогрессивные руководители, которые задумываются о том, чтобы «как бы чего не случилось», редки. Дело в том, что обычно руководителю достаётся старый «парк» сервисных контрактов, а ставить датчики на новое железо он смысла не видит, потому что понадобится это только через пару лет.
В общем, в какой-то момент жареный петух всё же клюёт, и наступает время модификаций.
Сама по себе передача данных не очень страшна. На оборудовании обычно уже есть датчики (либо они довольно быстро ставятся), плюс уже пишутся логи и отмечаются сервисные события. Всё это нужно только начать отправлять. Общая практика — прямо в устройство от рентген-аппарата до автоматической сеялки вставляется какой-то модем, например, с embed-SIM, и отправляет телеметрию через сотовую сеть. Места, где сотового покрытия нет, как правило, находятся довольно далеко и в последние годы редки.
А дальше начинается тот же самый вопрос, что и раньше. Да, логи теперь есть. Но их нужно куда-то складывать и как-то их читать. В общем случае нужна какая-то система визуализации и разбора инцидентов.

И тут на сцене появляемся мы. Точнее, часто мы появляемся раньше, поскольку руководители поставщиков смотрят, как сделано у коллег, и сразу едут к нам советоваться по поводу подбора железа для отправки телеметрии.
Рыночная ниша
На Западе путь решения такой ситуации сводится к трём вариантам: Siemens-экосистема (очень дорого, нужно для очень крупных узлов, как правило, типа турбин), самописные мандулы или кто-то из локальных интеграторов помогает. В итоге к приходу всего этого на российский рынок образовалась среда, где есть Siemens со своими кусками экосистемы, Amazon, Nokia и несколько локальных экосистем вроде разработок 1С.
Мы зашли на рынок как объединяющее звено, позволяющее собирать любые данные с любых устройств по любым (ладно, почти любым более-менее современным) протоколам, обрабатывать их вместе и показывать их человеку в любом требуемом виде: для этого у нас есть крутые SDK для всех сред разработки и визуальный конструктор пользовательских интерфейсов.
В итоге мы можем собрать все данные с устройства производителя, завести в хранилище на сервере и собрать там панель мониторинга с алертами.
Вот так это выглядит (здесь заказчик сделал ещё визуализацию предприятия, это несколько часов в интерфейсе):

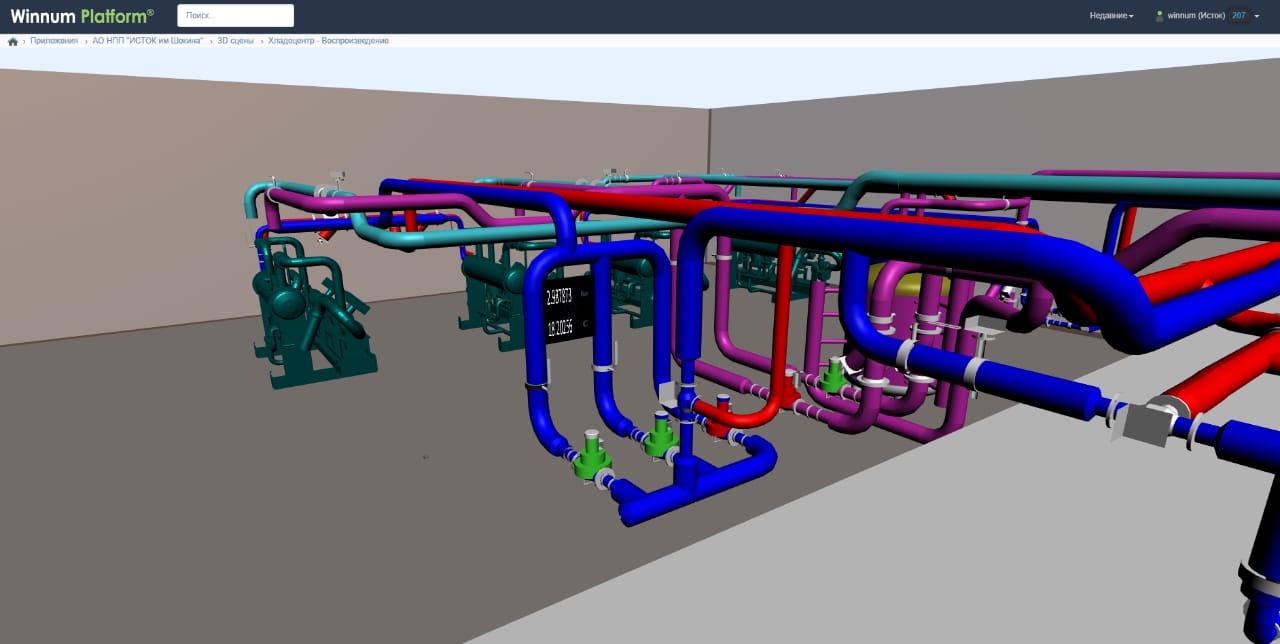
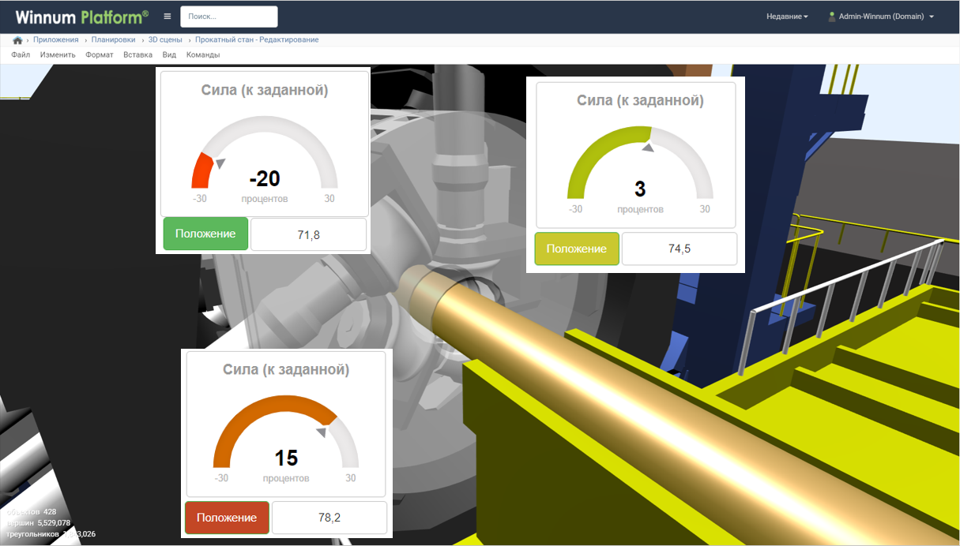
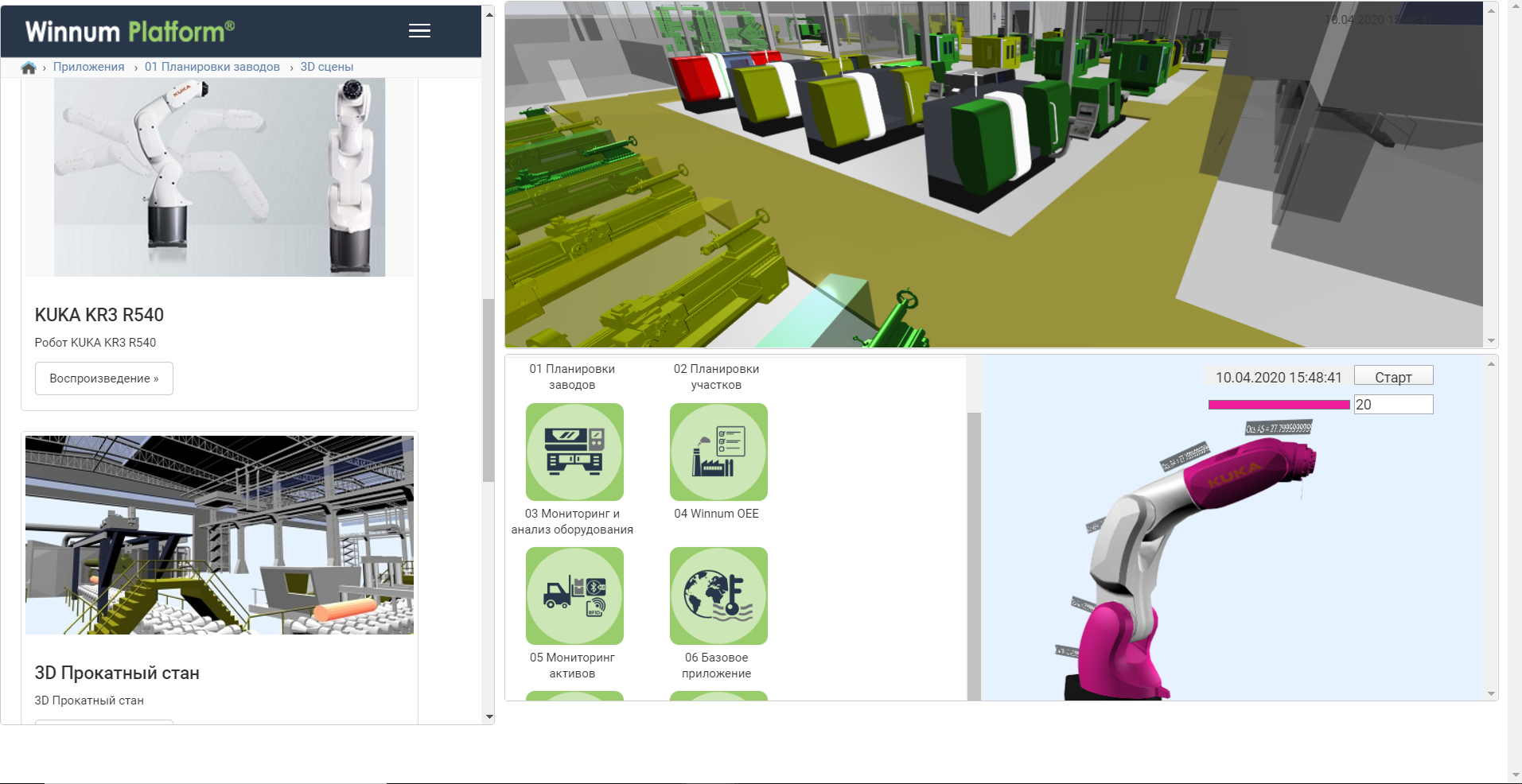
И есть графики с оборудования:
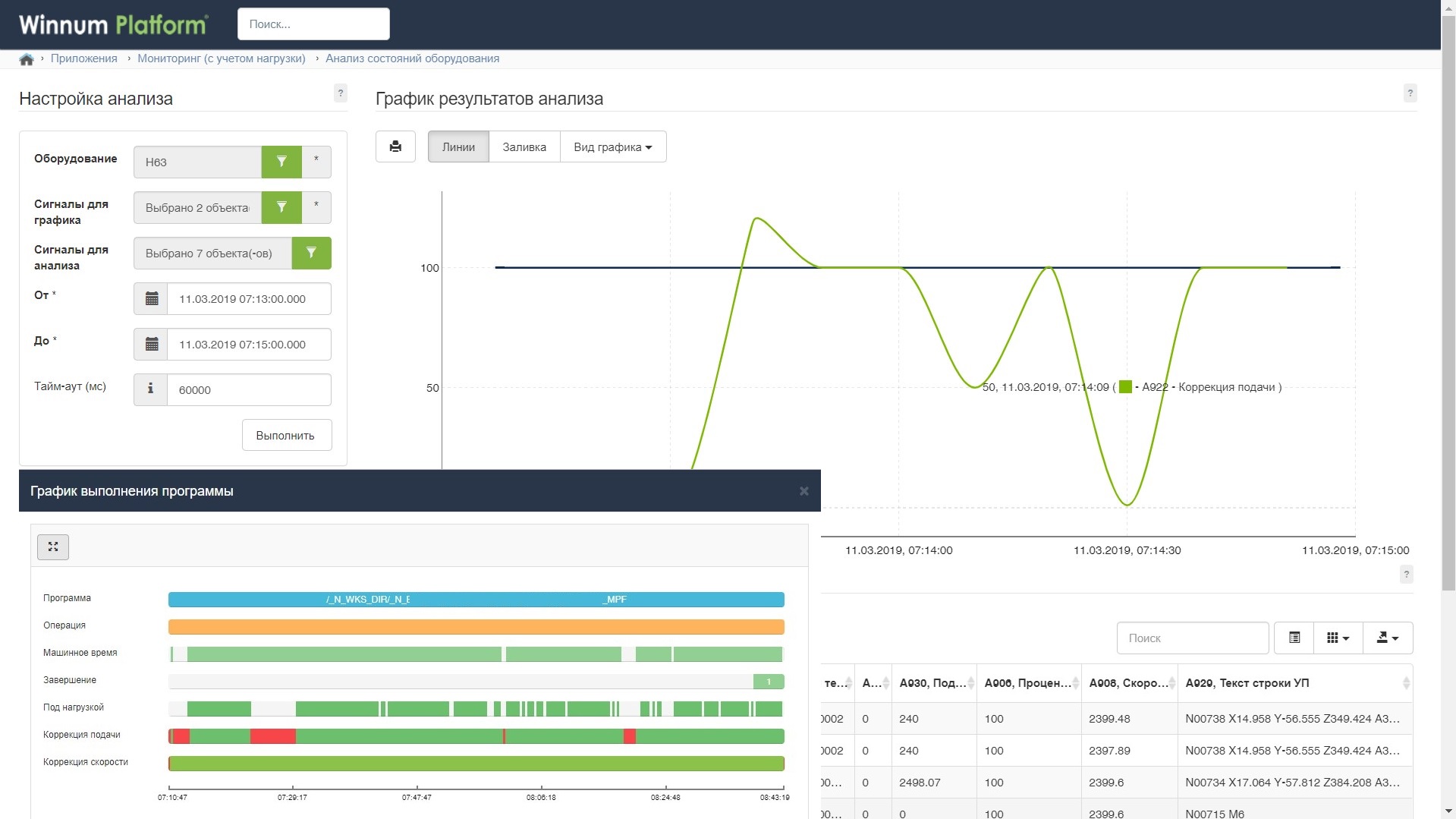

Алерты выглядят так: на уровне станка, если превысили усилие на исполнительном органе или возникло столкновение, настраивается набор параметров, и система будет информировать отдел или ремонтные службы при выходе за них.
Ну и самое сложное — прогнозирование выхода из строя узлов по их состоянию для профилактики. Если понимать ресурс каждого из узлов, то можно сильно сократить расходы на тех контрактах, где идёт оплата за простой.
Резюме
Эта история звучала бы довольно просто: ну поняли, что нужно отправлять данные, мониторинг и анализ, ну выбрали вендора и внедрили. Ну и всё, все счастливы. Если речь идёт про самописные системы на своём же заводе, то, как это ни странно, системы быстро становятся недостоверными. Речь идёт о банальной потере логов, неточных данных, сбоях в сборе, хранении и получении. Через год-два после установки начинают удалять старые логи, что тоже не всегда хорошо заканчивается. Хотя там практика — с одного станка за год собирается 10 Гб. Решается это на пять лет покупкой ещё одного жёсткого диска за 10 тысяч рублей… В какой-то момент выясняется, что первично не само передающее оборудование, а система, которая позволяет получаемые данные анализировать. Важно удобство интерфейса. Это вообще беда всех промышленных систем: быстро разобраться в ситуации не всегда просто. Важно, сколько данных видно в системе, количество параметров с узла, способность системы оперировать большим объёмом и количеством данных. Настройка дашбордов, встроенная модель самого устройства, редактор сцен (чтобы рисовать схемы размещения на производствах).
Давайте приведу пару примеров, что это даёт на практике.
- Вот глобальная компания-производитель промышленного холодильного оборудования, используемого в основном в торговых сетях. 10% дохода компании приносит оказание сервисных услуг по обслуживанию своей продукции. Нужно сократить себестоимость сервисных услуг и вообще дать возможность нормально увеличивать поставки, потому что, если продавать больше, то имеющаяся система сервисного обслуживания не справится. Подключились напрямую к платформе единого сервисного центра, модифицировали пару модулей для нужд именно этого заказчика, получили снижение командировочных расходов на 35% за счёт того, что доступ к сервисной информации предоставляет возможность выявлять причины выхода из строя без выезда сервисного инженера. Анализ данных за длительные интервалы времени — прогнозировать техническое состояние и при необходимости быстро выполнять обслуживание «по состоянию». В качестве бонуса увеличилась скорость реакции на запрос: выездов стало меньше, инженеры стали успевать быстрее.
- Машиностроительная компания, производитель электрического транспорта, используемого во многих городах РФ и СНГ. Как и все, они хотят сократить расходы и при этом прогнозировать техсостояние троллейбусного и трамвайного парков города, чтобы вовремя уведомлять техперсонал. Подключили, создали алгоритмы сбора и передачи технических данных от подвижного состава в единый ситуационный центр (алгоритмы встраиваются непосредственно в систему управления приводами и работают с данными CAN-шины). Удалённый доступ к данным о техническом состоянии, включая доступ в реальном времени к изменяющимся параметрам (скорость, напряжение, передача рекуперированной энергии и др.) в режиме «осциллографа», дали доступ к удалённому обновлению прошивки. Результат — снижение командировочных расходов на 50%: прямой доступ к сервисной информации предоставляет возможность выявлять причины выхода из строя без выезда сервисного инженера, а анализ данных за длительные интервалы времени — прогнозировать техническое состояние и при необходимости быстро выполнять обслуживание «по состоянию», включая объективный анализ нештатных ситуаций. Реализация контрактов расширенного жизненного цикла в полном соответствии с требованиями Заказчика и в установленные сроки. Соответствие требованиям Технического задания эксплуатанта, а также предоставление ему новых возможностей в части контроля характеристик потребительского сервиса (качество кондиционирования, разгон/торможение и т. п.).
- Третий пример — муниципалитет. Нужно экономить электричество и повышать безопасность граждан. Подключили единую платформу для контроля, управления и сбора данных о подключённом уличном освещении, удалённое управление всей инфраструктурой общественного освещения и обслуживание его с единой панели управления, обеспечивающее решение следующих задач. Фичи: затемнение или включение/выключение освещения дистанционно, индивидуально или в группе, автоматическое уведомление городских служб о сбоях в точках освещения для более эффективного планирования ТО, предоставление в реальном времени данных о потреблении энергии, предоставление мощных аналитических инструментов для мониторинга и улучшения системы уличного освещения на основе Big Data, предоставление данных о трафике, состоянии воздуха, интеграция с другими подсистемами «Умного города». Результаты — сокращение расхода электроэнергии на уличное освещение до 80%, повышение безопасности для жителей за счёт использования интеллектуальных алгоритмов управления освещением (человек идёт по улице — включить ему свет, человек на переходе — включить ярче освещение, чтобы его было заметно издалека), обеспечение города дополнительными сервисами (зарядка электромобилей, предоставление рекламного контента, видеонаблюдение и пр.).
Собственно, что я хотел сказать: сегодня с готовой платформой (например, нашей) настроить мониторинг можно очень быстро и просто. Для этого не нужны изменения в оборудовании (либо минимальные, если датчиков и передачи данных до сих пор нет), для этого не нужны затраты на внедрение и отдельные специалисты. Надо просто изучить вопрос, потратить пару дней на то, чтобы понять, как это работает, и несколько недель на согласования, договор и обмен данными про протоколы. И после этого у вас будут точные данные со всех устройств. И всё это можно делать по всей стране при поддержке интегратора Техносерва, то есть мы гарантируем хороший уровень надёжности, нехарактерный для стартапа.
В следующем посте я покажу, как это выглядит со стороны поставщика, на примере одного внедрения.
