Мультиарендный подход к инфраструктуре работы с данными. Доклад Яндекса
Доклад будет из четырех разделов. Сначала я расскажу, что такое многопользовательские и multitenant-системы и чем они отличаются. Потом приведу примеры мультиарендных multitenant-систем в Яндексе: Yandex Database (YDB) и Yandex Query. Затем расскажу, как мы все эти системы реализовываем, какие в них особенности. В заключение подведу итоги доклада.
Многопользовательские и мультиарендные системы
Итак, что это за системы?
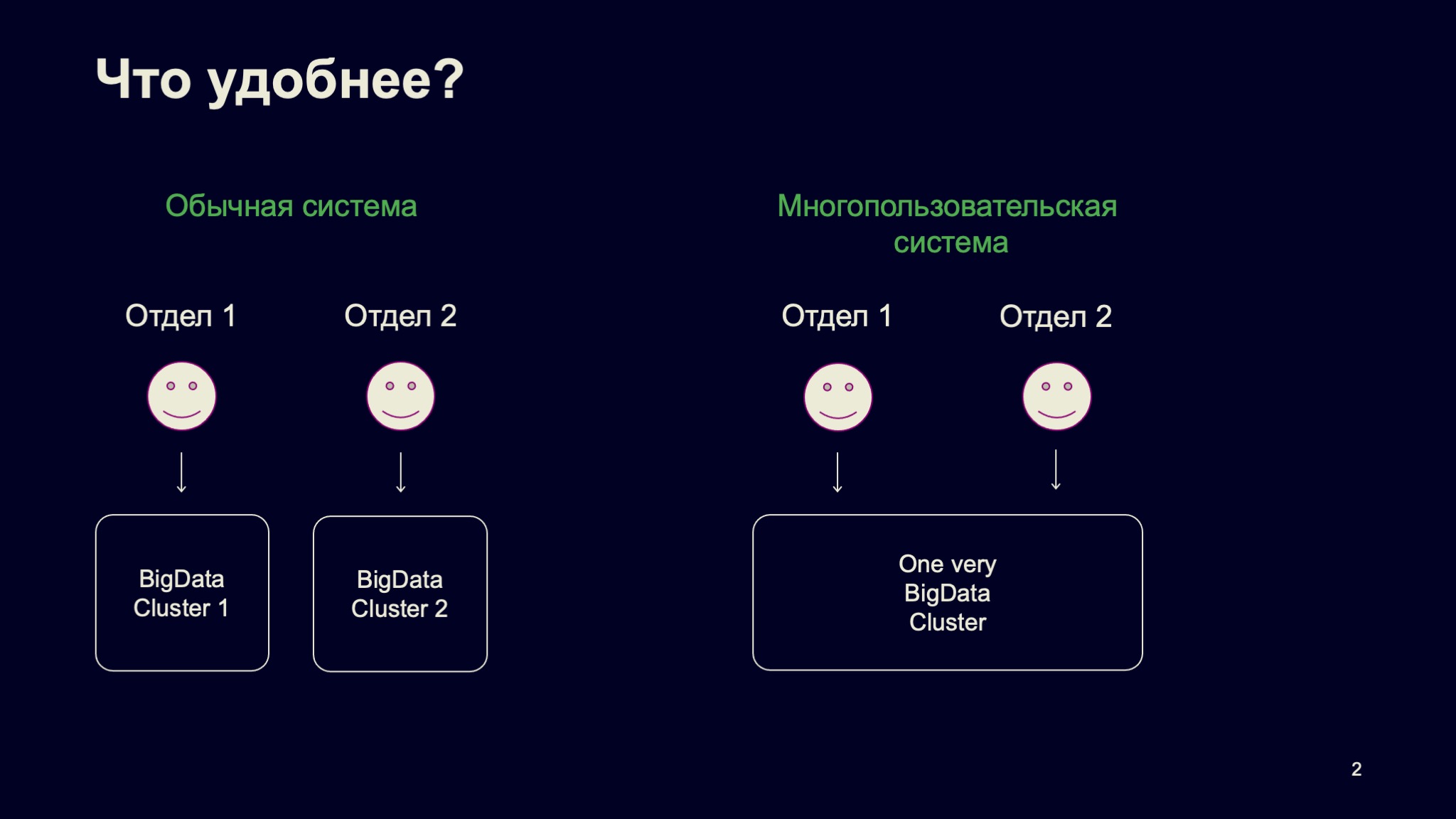
Тематика доклада — большие данные. Представьте, что у вас есть гипотетическая компания и она доросла до того, что у нее есть большие данные. Все эти большие данные не умещаются на одну машину, на один компьютер. Зададимся простым вопросом. В компании отдел один, отдел второй, и у них есть общие данные. Что делать: использовать для них два разных кластера или один, такой very big data cluster, в котором находились бы все данные?
Ответ не такой очевидный, как может показаться на первый взгляд. Давайте начнем с удобства для конечных пользователей. Удобно ли конечным пользователям иметь один большой кластер? С одной стороны, да — потому что мощность этого кластера сильно превосходит мощность конкретного набора ресурсов, входящих в их кластер.
С другой, нет, если этот кластер работает не очень. Когда мы говорим про многопользовательскую систему, то, конечно, ожидаем, что user experience будет консистентный. И если пользователь что-то хочет обработать, посчитать на этом кластере, то у него такая схема будет работать в любое время, в том числе в rush hours, в пиковые часы нагрузки.
А для провайдера этого кластера что лучше, что удобнее? Опять-таки, многопользовательская система обычно удобнее в том смысле, что она дешевле, интереснее и так далее. Но это вновь при условии, что она работает хорошо.
А какая система интереснее для разработчика инфраструктуры, для человека, который эту систему делает? Опять же многопользовательская, потому что в ней гораздо больше интересных задач и итоговых возможностей для конечного пользователя.
Вкратце посмотрим, как вообще выглядит история совместного использования оборудования для задач обработки данных, такая краткая история человечества в этом месте. Я бы выделил три этапа. Первый — Unix и все, что было до него. С появлением системы Unix компьютеры стали доступны для общества в целом. Unix — исходно многопользовательская система, в ней есть возможность обрабатывать данные, работать на машине нескольким пользователям одновременно. Этот этап всем известен.
Следующий этап начался где-то в районе 2000-х, это MapReduce-кластеры. В мире их чаще называют Hadoop Ecosystem, а я говорю о MapReduce, потому что в Яндексе MapReduce — это святое, широко используется. Данные перестали вмещаться на один компьютер, будь то даже специализированное оборудование, неважно. Компании стали строить кластеры, хранить на них данные, обрабатывать. Это важнейший этап, когда сам термин больших данных вошел в обиход.
Текущий этап развития — публичные облака. Они произвели некоторую революцию на рынке, и сейчас все компании, у которых есть собственная инфраструктура, либо заезжают в облака, либо уже заехали.

Чуть подробнее о преимуществах и недостатках совместного использования оборудования. Преимущества понятны: пользователю доступны огромные ресурсы в рамках единого кластера. Другое преимущество — лучшая утилизация оборудования, потому что пользователи обычно не приходят за всеми своими мощностями одновременно. Иногда они простаивают, такова жизнь.
Переподписка по ресурсам — смежное преимущество, мы его часто наблюдаем в сетях. Предположим, у вас есть домашний интернет 100 Мбит/с, и у вашего соседа тоже, от этого же провайдера. Если каждый из вас попытается потребить по 100 Мбит/с, вряд ли получится. Но user experience заключается в том, что как будто у меня всегда есть 100 Мбит/с.
Какие недостатки у такого подхода? Очевидно, его сложно реализовывать. Как следствие, если все реализовано и рассчитано не очень хорошо, возникает не консистентный user experience. Пользователи говорят: мне система не нравится, я чувствую, что с кем-то конфликтую либо по безопасности, либо по ресурсам, либо по чему-нибудь еще.

Здесь я остановлюсь чуть подробнее и расскажу про всю систему. На Unix я не буду долго останавливаться. Давайте поговорим про MapReduce-кластеры.
Как это обычно работает? Кластер занимает выделенное оборудование. Исходно это некоторое железное оборудование «растягивается» на весь кластер.

Пользователь запускает в кластере свой код, некоторые jobs в терминах MapReduce. С точки зрения изоляции пользователей это некоторый процесс в операционной системе со всеми преимуществами и недостатками. В рамках доверенного окружения этого более-менее достаточно. А если мы этот кластер пытаемся по кусочкам, по частям продавать многим компаниям, то безопасность, к сожалению, недостаточная.
Какие вообще задачи, вопросы возникают в этой области? Прежде всего — планирование ресурсов. Я сейчас немного опускаю другую важнейшую и сложную задачу распределенного хранения данных, масштабируемость. Подразумевается, что это в каком-то виде есть, про это можно отдельно и долго рассказывать.
Построение таких систем — тяжелый путь, но доступность этого пути сильно выше, чем была раньше с мейнфреймами и специальными компьютерами. Такие системы обычно предоставляют специализированные API. В мире Hadoop Ecosystem уже от Hadoop-то мало что осталось, а от Ecosystem осталось много, экосистема живет и очень понятная.
Про публичные облака. Основной момент в таких облаках — виртуализация. Она позволила адресовать вычислительные ресурсы гранулированно, это принципиальный вопрос. У вас есть машина, 128 ядер, много CPU, и вам нужно запустить маленькую виртуалочку на два ядра. Пожалуйста, виртуализация всё обеспечивает. И это позволило сделать так, что в облаках стало можно запускать те же сервисы, которые работали на обычных машинах, а не какие-то специализированные типа Hadoop Ecosystem.

Рассмотрим на примере обработки данных. У нас есть пример реляционной базы, например, PosgtreSQL. Мы можем в облаке легко построить инсталляцию этого кластера. Обычно за нас это делают управляемые сервисы. То есть мы говорим: сделайте нам, пожалуйста, такой highly available-кластер, вот у него лидер, два фолловера и все. И щелк, все работает.
Эта штука — обычно не многопользовательская, одна инсталляция базы данных для одного пользователя. Но там масса других очень важных возможностей, связанных с «многопользовательством». Допустим, мы хотим расширить этот кластер: исходно у нас четыре ядра в каждой машине, а мы хотим восемь.
Обычно в облаках это делается очень здорово, не надо бежать покупать компьютер, обычно даже даунтайма нет. Если система правильно сделана, мы такие — щелк, и виртуалки, допустим, по одной последовательно перезагружаются, добавляются новые мощности, и все работает. А если нужно добавить, например, read only-реплику, отмасштабировать кластер, то точно такой же щелк — и система вам это предоставляет.
Хорошо. Но что дальше? Можно ли сделать еще интереснее и лучше? Да. Мне кажется, очень интересный аспект — переход от виртуализации оборудования к виртуализации сущностей предметной области. То есть к сущности, с которой работаем мы.

Вычисления — это некоторая функция, кусочек кода, который программист написал, и его можно запустить. Serverless-вычисления в облаках достаточно широко представлены. Это, например, AWS Lambda, Yandex Cloud Functions и много всего другого в других публичных облаках.
Если мы говорим про область, которая связана с обработкой данных, то вопрос: можем ли мы оперировать такими понятиями, как таблица, очередь, персистентная очередь, аналитический запрос, какой-нибудь запрос над потоком, streaming query? Мы работаем с сущностью, а о том, что за ней, мы не задумываемся. Мы не думаем, сколько нужно инстансов виртуальных машин, сколько ядер выделять, чтобы для меня как для пользователя этого сервиса все работало.
Так вот, подобные системы, которые так умеют, называются multitenant, мультиарендные системы. Посмотрим, какие у них преимущества.

С точки зрения пользователя, как я уже сказал, если мне нужна персистентная очередь с показателем в 10 rps, то мне не надо думать, сколько ядер мне под эту очередь выделить, чтобы она работала. Я вообще в таких терминах не думаю, потому что в реалии для 10 rps, скорее всего, нужно гораздо меньше одного ядра. А гораздо меньше одного ядра — это не то, что я могу выделить по щелчку.
Есть виртуальные машины с пятью, десятью процентами выделенного ядра, но это не так удобно. Гораздо приятнее перестать об этом думать и рассуждать в терминах предметной области. Точно так же, если нужно сколько-то раз в день выполнять некоторый аналитический запрос, можно я его просто буду выполнять и все?
Чем такие multitenant-системы хороши для провайдера услуг, то есть для компании, которая строит облака, для Яндекса в том числе? Тем, что они выгодны. Например, благодаря таким системам, если они правильно построены внутри компании, мы можем закупать меньше оборудования. И, если мы эти сервисы предлагаем снаружи, то можем делать цены меньше и так далее.
Чем такие системы интересны для нас, разработчиков? Тем, что там очень классные задачи, по-настоящему классные. Как мы организовываем наш код, как выполняем планирование ресурсов, как изолируем и так далее — все эти вопросы здесь имеют место быть.
Итак, давайте перейдем к примерам таких систем в Яндексе.
Примеры мультиарендных систем: Yandex Database и Yandex Query
На самом деле за этими названиями скрывается некоторое множество систем и сервисов. Когда нужно про это рассказать, я обычно рассказываю так.

Первая платформа, YDB, — она про хранение данных, про то, чтобы хранить их надежно, отказоустойчиво, масштабируемо и так далее.
А вторая платформа, YQ, — она про выполнение запросов, чтобы у нас вообще такой функционал был, чтобы это было эффективно, функционально и так далее. Есть набор примеров, сервисов, которые поверх этих платформ реализованы. Yandex Database — OLTP-база данных, распределенная, Distributed SQL-база, которая много где в Яндексе используется. На ней построены многие масштабные серьезные системы, включая Yandex.Cloud.
Дальше ряд других сервисов, не менее важных, прямо связанных со storage. Это, например, storage для мониторинга, для time-series-мониторинга, network block store — эластичные виртуальные диски в Yandex.Cloud. Это storage для логов, всевозможные очереди, например лог-брокер, такая шина данных, или Yandex Message Queue, аналог Amazon SQS.
Еще один маленький аспект. YDB одновременно использует несколько платформ — и YDB, и YQ, потому что там есть и хранение данных, и выполнение запросов.
Существуют более специфичные для Yandex Query сервисы, например, аналитика поверх MapReduce-системы YT во внутреннем Яндексе. Есть федеративные запросы, это когда мы одновременно можем адресовать несколько источников. В качестве источников данных выступают YT, ClickHouse, та же YDB и так далее. YQL Analytics (Federated Engine) позволяет выполнять запросы между этими источниками. Также есть стриминг — запросы над бесконечными потоками данных.

Остановимся чуть подробнее на платформах. Мы разработали YDB в Яндексе с нуля. Она обеспечивает надежное хранение данных с автоматической репликацией, must-have для масштабной распределенной системы.
В основе лежит архитектура Share nothing. Это означает, что мы можем дополнительно масштабироваться, просто добавляя узлы в кластер. Важный аспект, ДНК системы — это поддержка распределенных ACID-транзакций. Мы обеспечиваем уровень изоляции serializable, он прямо исходно есть в системе. Это сейчас умеют немногие, хотя все больше и больше тех, кто научился. Но это интересный аспект системы.
Вот общая картинка, как платформа YDB выглядит в целом. Она слоистая. Есть уровень хранения данных, distributed storage. Есть уровень таблеток — tablets. Что это за уровень?

Каждая таблетка — это небольшая отказоустойчивая сущность. Гарантии этой сущности, гарантии этого компонента точно такие же, как у протоколов Paxos, RAFT. То есть компонент призван решать проблему распределенного консенсуса. Это как раз тот слой платформы, где обычно подключаются разные другие системы хранения. Например, если мы говорим про network block store, то там есть специальная таблетка, которая реализовывает хранение четырехкилобайтных страниц. Из этих страниц состоит виртуальный том, который вы подключаете (mount) к своей виртуальной машине.
А если мы говорим про time-series-данные, то там тоже есть специальная таблетка, она хранит данные в эффективном для time-series формате. Если мы говорим, например, про уровень очередей — то же самое, специализированная таблетка. Прокидывается наверх через gRPC Proxy и предоставляет некоторый gRPC-интерфейс для пользователя, чтобы он мог подконнектиться к серверу базы данных, к серверу системы и решить свою задачу.

Про Yandex Query. Эта платформа решает задачи выполнения запросов на декларативном языке Yandex Query Language (YQL). YQ точно так же разработан в Яндексе с нуля, исходно, как некоторый элемент YDB.
Предлагает функциональный язык программирования, предоставляет пользователю традиционный SQL-синтаксис. Поддерживает интерпретацию программы и кодогенерацию через LLVM, то есть система развивалась. Исходно была только интерпретация. Теперь все активнее используется кодогенерация, потому что это эффективнее, снижает потребление CPU. В итоге — снижает время выполнения запроса. И это очень заметно.
Поддерживает распределенное массивно параллельное выполнение запросов. Но это must-have для систем масштаба Яндекса. Имеет подключаемые оптимизаторы, что очень здорово. То есть обратите внимание, это та система, которая используется и для аналитической обработки данных, и для OLTP-обработки данных (из базы YDB). Понятно, что какие-то, условно говоря, одинаковые оптимизаторы работают с предикатами, а какие-то — очень специализированные.
YQ позволяет расширять всю эту систему пользовательскими функциями, так называемыми UDF (User Defined Functions), то есть система расширяема. Это все активно используется. На слайде — иллюстрация того, что платформа YQ умеет.

Есть очевидные вещи, такие как парсер, оптимизатор в YQL. Про оптимизатор легко говорить, это такая вроде бы последовательная штука, но внутри она масштабная, сложная, в ней большое количество кода. Все это накапливается и в итоге позволяет нам достаточно быстро развивать, строить новые сервисы за счет того, что система уже богата. Потом я расскажу об этом чуть подробнее.
Очевидно, стоит обратить внимание на последний распределенный слой выполнения запросов. Подчеркну, что программа, которая генерируется в итоге после оптимизаторов, не локальная. Она часто состоит из кусочков. Эти кусочки могут выполняться, естественно, в разных окружениях. Исходно это было в job’ах YT.
Теперь это гораздо более продвинутая вещь, некоторые Compute Actor, где выполняется локальная программа. Акторы связаны между собой, и фактически эта система выполнения запросов используется в разных частях. Например, в YDB. Или как федеративный движок запросов и фактически как отдельный сервис внутри. Но для пользователя это выглядит как единый сервис выполнения запросов.
Реализация мультиарендных систем
Поговорим чуть подробнее о том, за счет чего мы такие системы строим и за счет чего они являются multitenant-системами.

Мы в основном пишем ядро системы, ядро платформы на C++. Это традиционный язык программирования в Яндексе для инфраструктуры. Системы, которые мы строим, насквозь асинхронные. Они растянуты на кластеры машин, взаимодействуют между собой. Поэтому по своей природе программы асинхронны. И перед нами в свое время возник вопрос — как такие системы писать, на чем, какие фреймворки использовать? Есть разные подходы — корутины, Future/promise, Actor Model, — при помощи которых можно такие системы реализовывать. Мы выбрали подход акторной модели, и все наши внутренние компоненты написаны через эту модель, по крайней мере, там, где требуется асинхронное выполнение, параллельность и так далее.

Вкратце расскажу, что такое Actor Model. Идеология акторной модели — не сложная вещь. Чтобы быть ближе к реальности, актор — это некоторый класс C++, который реализовывает определенный интерфейс. Он умеет посылать сообщения другим акторам, принимать от них сообщения, обрабатывать их и порождать другие акторы. Сам актор выполнен как некоторый конечный автомат с волатильным состоянием. Поэтому актор имеет последовательный код, его достаточно просто отладить, написать тесты на него.
Крайне важно, что акторная система, которую реализовывает Actor Model, натянута на весь кластер. Это означает, что акторы могут общаться между собой не только в рамках машин, а между машинами.
При этом если сообщение пересекает границу ноды и отправляется в другую ноду, то там автоматически происходит сериализация этого сообщения. Наше сообщение преобразуется в набор байт и отправляется по сети. А если, например, сообщение адресовано локально, то там такой необходимости нет, и, соответственно, сериализация не выполняется, такие сообщения требуют меньше накладных расходов.
Там есть куча интересных нюансов, как и что работает, почему, как мы переживаем сбои, подписываемся на недоставку сообщений и так далее.

Я про это рассказываю затем, что одна из принципиальных проблем мультиарендной системы — разделение ресурсов на вычислительном узле. Помните, я говорил про очередь, которая работает до 10 rps? Там действительно нужно меньше одного ядра. Поэтому, грубо говоря, у нас есть вычислительная нода, на которой, скорее всего, работает несколько очередей, и мы должны разделять ресурсы между пользователями, которые владеют этими очередями.
Вкратце, как это устроено? Мы используем Actor System — реализацию Actor Model. Внутри Actor System внутри есть user space scheduling, планировщик, который в user space планирует акторы. Когда актору отправлено сообщение, он триггерит выполнение этого актора на этом сообщении, в общем управляет всем этим механизмом.
Очень важно, что мы акторы пишем так, чтобы обработка каждого сообщения не занимала слишком много времени. Это наш контракт, и он означает, что мы можем тасовать, планировать эти акторы и они заканчиваются за удобоваримое время.
Я сейчас говорю про RT ThreadPool, там есть еще отдельные ThreadPools, где акторы могут работать большее количество времени, но они не влияют на реактивные системы. Я немножко упрощаю, система внутри гораздо более сложная.
И, естественно, мы следим за тем, чтобы в вычислительном кластере было достаточное количество ресурсов, чтобы всего этого хватало для того, чтобы вот эти акторы крутились и работали.
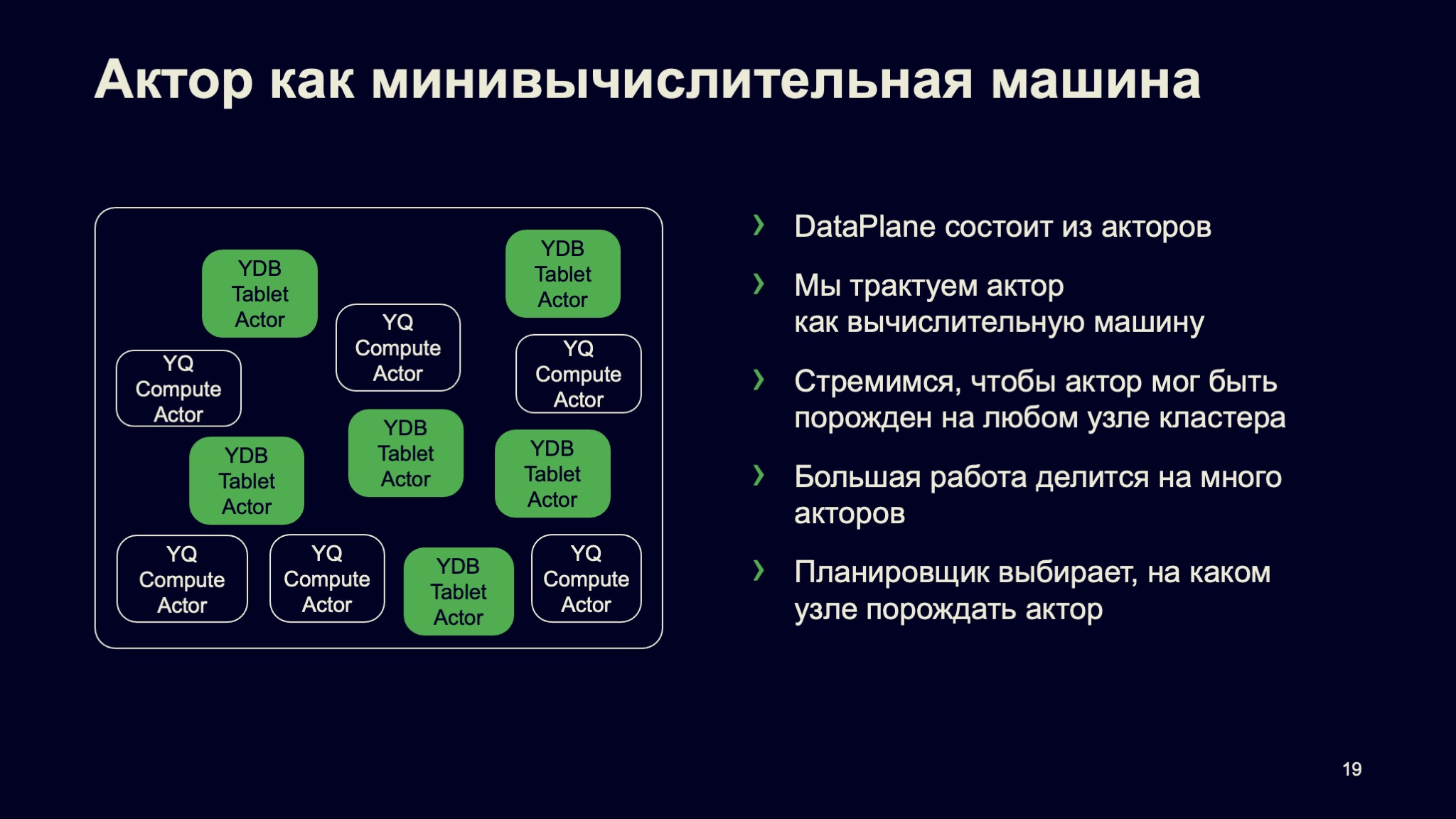
Мы смотрим на актор как на минивычислительную машину. Есть большой компьютер с большим количеством ядер. Есть виртуализация, когда мы все разбили на виртуалочки меньшего размера. А есть еще более маленькая виртуальная вычислительная машина, и это, собственно, актор.
DataPlane наших сервисов состоит из акторов. В DataPlane основная работа и происходит — выполнение запросов, работа с данными и так далее. Мы стремимся к тому, чтобы актор — по крайней мере, вычислительный — мог быть порожден на любом узле системы. Мы активно используем балансировку, scheduling, порождаем акторы там, где они должны быть, там, где есть ресурсы, и так далее.
Большая работа, которую надо делать, делится на множество маленьких акторов или, по крайней мере, на множество маленьких сообщений. Поэтому очень важно, что каждый актор не забирает CPU надолго, как я уже говорил. На всех уровнях есть планировщики, которые решают задачу планирования ресурсов — в частности, где какой актор запускать.
Чуть-чуть поговорим про организацию кода и вообще про архитектуру системы. Как я уже обратил внимание, структура системы позволяет сделать так, что мы можем подключаться к системе на разных уровнях. Архитектура слоистая, это нам позволило реализовать такие интересные вещи, как, например, network block store, который мы исходно не планировали. Так что архитектура — один из краеугольных камней работы системы.

Разработка ведется на C++. Мы живем в едином репозитории Яндекса — в Аркадии. Это удобно. Переиспользование компонентов становится гораздо более простым, и мы этим активно пользуемся.
Про Packaging. Так как система написана на одном языке программирования, мы достаточно легко собираем бинарник с нужной функциональностью. При этом мы переиспользуем инфраструктуру деплоя, если нам нужно запустить новый сервис. Это благодаря тому, что новый бинарник просто реализовывает другие сервисы, а с точки зрения эксплуатации выглядит так же.
Например, мы готовим новый сервис, собираем его из кубиков. Дописываем недостающие куски. А какие-то элементы деплоя используем те, которые были раньше. Все это способствует тому, что мы достаточно быстро и ловко можем запускать разные интересные вещи. Сейчас, например, работаем над стримингом версии 2.0. Очень интересно наблюдать, как все получается.

Еще один крайне важный аспект построения multitenant-системы — квотирование ограничений пользователей. Что это значит? Если мы построили большой кластер, то туда может прийти пользователь и потребить множество ресурсов. Природа системы такова, что мы все так и устроили, что это можно сделать.
Понятно, что это не всегда хорошо, пользователь может потребить слишком много ресурсов, его ошибка и так далее. Очевидно, других пользователей надо защищать от людей, которые делают неправомерные, странные или глупые вещи. Для ограничения потока запросов от пользователей у нас используется Distributed Rate Limiter. Мы применяем достаточно стандартный подход, простой алгоритм leaky bucket. Но применение этого простого алгоритма в масштабной распределенной сети — на самом деле, штука очень сложная.
Давайте в качестве примера продемонстрирую, что это вообще за квоты. Допустим, в рамках квоты мы позволяем пользователю делать 1000 запросов в секунду. Как это устроено?
Есть Coordination Service, таблетка с гарантиями, аналогичным Paxos, RAFT, как я и говорил. Там есть leaky bucket, который генерирует вот эту квоту 1000 request в секунду, которые можно выполнить. Так сказать, наливает «в bucket». Пользователь приходит одновременно на множество машин кластера и с каким-то рейтом эти запросы задает, что-то пытается сделать. Наша задача — с одной стороны, правильно квотировать пользователя. А с другой — сделать так, чтобы решение о том, можно ли выполнить этот запрос, превысил что-то пользователь или нет, принималось локально на этом узле. Не нужны round trip, дополнительные latency и так далее. Поэтому у нас двухуровневый leaky bucket и, с одной стороны, Coordination Service, который наливает и переливает локально на каждые отдельные leaky bucket. Решение там уже принимается локально.
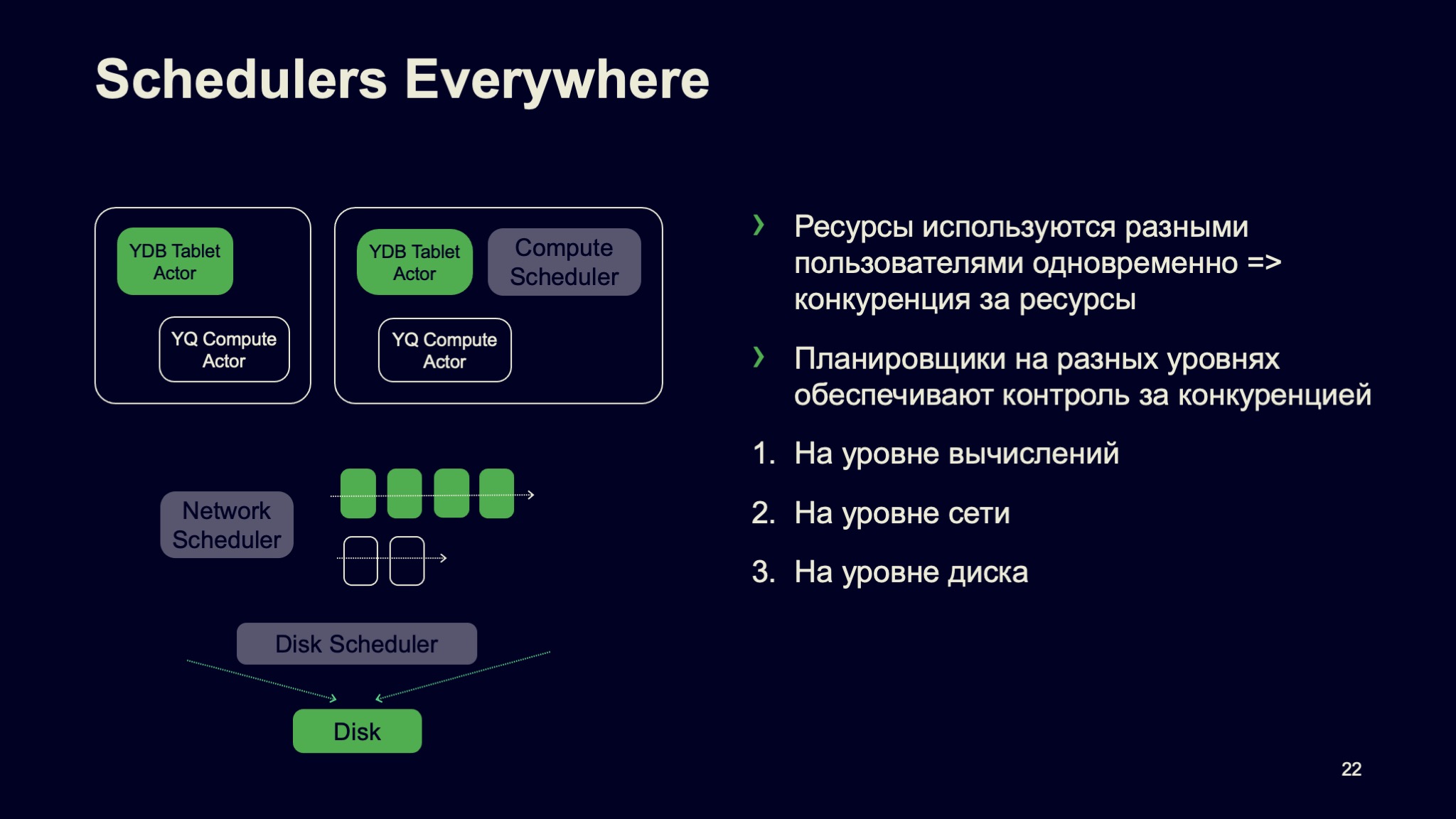
Давайте переключимся на Schedulers, планировщики, о которых я уже немного рассказал. Планировщики в нашей системе повсюду. Есть очевидный момент: нужно планировать CPU для вычислительных элементов, Compute Actor и так далее. Но это не все.
Когда мы говорим про данные, то в реальной жизни получается так, что несколько пользователей одновременно работают с одним диском, пишут туда данные, читают и так далее. И на уровне диска у нас тоже есть система Schedulers, которая распределяет пользовательские запросы справедливо, в соответствии с заданными параметрами.
Если мы передаем данные по сети, там те же самые проблемы. Сеть общая, пришел пользователь с batch-нагрузкой, перегрузил сеть. Это влияет на реактивность системы, быстрые сообщения не проходят. Поэтому у нас этот аспект отработан, покрыт в системе. Schedulers — на уровне сети, на уровне каждой ноды. Когда есть нагрузка разных уровней, разных приоритетов, то мы поступаем так: большой поток данных бьется на маленькие пакетики, и мы имеем возможность приоритизировать одни пакеты относительно других. Приоритетный трафик идет вперед, неприоритетный — потом.
Schedulers, Rate Limiter, организация кода, разделение ресурсов на Compute Node — это аспекты, за счет которых получается строить multitenant-системы и буквально на одну ноду селить нагрузку, причем различную нагрузку: очереди сообщений разных пользователей, запросы к базе данных, в том числе OLTP с low latency разных пользователей и тому подобное. И это все работает.
Заключение
Переходим к финалу. Multitenant-системы сложны, но привлекательны. Строить их сложно, но интересно, и понятно, что они дают. Для конечных пользователей это возможность работать виртуально с большим количеством ресурсов, которые они «видят». На самом деле все эти ресурсы делятся между разными пользователями.
Multitenant-системы особенно эффективны, когда мы адресуем небольшое количество ресурсов — это особенно важно, например, в мире микросервисов. Каждый микросервис, возможно, хочет себе отдельную базу данных, малюсенькую очередь и так далее. И не хочет при этом иметь проблемы от надоедливых соседей.
В большом мире подход multitenant не то чтобы суперпопулярен, особенно в мире опенсорса, особенно с облаками. Там, наверное, немного другой подход. В виртуальной машине мы запустили один инстанс-сервис, и инстанс-сервис вас обслуживает. Точка.
Подход, связанный с multitenant системами, обычно встречается у крупных облачных провайдеров. У AWS приходит в голову, например, DynamoDB. Всё, что касается аналитики, тоже часто стараются делать в таком, как минимум многопользовательском варианте. А на самом деле, стремятся делать multitenant-вариант.
В Яндексе длинная история разработки сложных систем, включая многопользовательские системы, а теперь и multitenant-системы. Мы этот опыт активно используем и всячески развиваем. Когда говорят про Яндекс, часто имеют в виду, что у нас много велосипедов, собственной разработки. Но подобные аспекты позволяют нам строить очень интересные, эффективные и, в конечном итоге, выгодные приложения.
Спасибо за внимание. Ссылка ведет на страницу документации в Yandex.Cloud. Сервис YDB, о котором я рассказывал, там представлен, можно посмотреть, ознакомиться. Также на страничке собраны видео докладов, которые мы читали раньше, можно узнать о других аспектах более глубоко. Спасибо.
