30 миллиардов параметров: реально ли обучить русский GPT-3 в «домашних» условиях?
Не так давно Сбер, а затем и Яндекс объявили о создании сверхбольших русских языковых моделей, похожих на GPT-3. Они не только генерируют правдоподобный текст (статьи, песни, блоги и т. п.), но и решают много разнообразных задач, причем эти задачи зачастую можно ставить на русском языке без программирования и дополнительного обучения — нечто очень близкое к «универсальному» искусственному интеллекту. Но, как пишут авторы Сбера у себя в блоге,»подобные эксперименты доступны только компаниям, обладающим значительными вычислительными ресурсами». Обучение моделей с миллиардами параметров обходится в несколько десятков, а то сотен миллионов рублей. Получается, что индивидуальные разработчики и маленькие компании теперь исключены из процесса и могут теперь только использовать обученные кем-то модели. В статье я попробую оспорить этот тезис, рассказав о результатах попытки обучить модель с 30 миллиардами параметров на двух картах RTX 2080Ti.
Как построена эта статья, какие части можно не читать
В первой части я кратко расскажу что вообще такое языковая модель и что она дает. Если вы это знаете, первую часть можно без ущерба пропустить.
Вторая часть объясняет в чем проблема с обучением больших моделей и обсуждает возможности для ее решения.
Третья часть рассказывает о результатах попытки обучить модель с 30 миллиардами параметров на двух картах RTX 2080Ti
В заключении обсуждаем зачем нужно заморачиваться самостоятельным обучением языковых моделей. Данная часть несколько субъективна и излагает мое личное мнение, если субъективное мнение вам не интересно, то можно пропустить и ее.
В целом, я пытался сделать статью понятной для широкого круга разработчиков и самодостаточной, поэтому включил в нее небольшую предысторию вопроса и объяснение важных для понимания терминов, в результате чего статья немного разбухла. Специалисты могут заменить, что некоторые вещи объяснены не совсем точно и не полно, но тут я старался предпочесть интуитивно понятное изложение математически строгому.
С этим предисловием, приступим к основному изложению.
Что такое языковые модели и почему это важно
Говоря простым языком, языковая модель это способ оценки вероятности получения следующего слова на основании предыдущего текста (вместо слова может буква или часть слова, но это не важно для сути). Представьте себе, например, что мы хотим сгенерировать нечто похожее на текст. В первом приближении мы можем просто взять словарь всех слов и расставить их в случайном порядке.
паразитический манию цзяо прозорова яшара левобережная атиться последователей волновода фаул
Выглядит не очень. Во-втором приближении мы можем взять реальный текст и ставить слова с частотами, с которыми они в нем встречаются. Получится нечто более интересное:
крупной работал приходится литерами насчитывали бумажная миллионов несмотря первым
Это все еще бред, но выглядит он привычнее. Продолжив процесс, мы можем учесть вероятность встретить следующее слово после предыдущего:
число сохранившихся — это книга лучшими поэтами которой осуществляется формой книг
Тут можно уже попытаться представить некий смысл, а ведь мы особо ничего не сделали сложного.
Языковые модели на нейронных сетях работают на похожем принципе, но правила выбора слова в них не закладываются изначально — просто берется большая нейронная сеть, ставиться задача «угадать» на выходе следующее слово и производиться обучение на большом массиве текстов. После обучения такие модели создают текст, который очень сложно отличить от написанного человеком, например такой:
Удача — это способность человека, обладающего ею, использовать для достижения своих целей благоприятные обстоятельства. Если вы хотите разбогатеть, то вам нужно сделать так, чтобы обстоятельства, с которыми вы столкнетесь, были благоприятными.
Помимо очевидной возможности заменить языковой моделью копирайтеров, появляются и более серьезные последствия. Дело в том, что способность предсказания следующего слова подразумевает также и возможность решения различных задач, например, возможность правильно предсказать слово в контексте »Петя дал Васе два арбуза. Сколько арбузов у Васи? Ответ:» равно умению решить простую задачку. С другой стороны »Программа для определения является ли строка палиндромом: » это тоже текст, ну и далее все ограничено размером модели и степенью нашей фантазии. Понятно, что такое волшебство у многих вызывает интерес и имеет потенциально серьезные последствия для многих областей.
Упоминания про возможность данного явления можно найти в литературе десятилетней давности, но убедительно оно было продемонстрировано лишь недавно в работах исследователей Google Brain [1] и OpenAI [2,3]
Нужно, правда добавить, что языковая модель, используемая в этом режиме является простым, но часто не самым лучшим способом решения задачи в плане точности и затрат вычислительных ресурсов, но это может экономить рабочее время, нужное на разработку специализированного решения.
В чем проблема с обучением больших моделей
Что нужно для создания языковой модели? Исходный код нейросети сейчас не проблема, он выложен в открытом доступе в различных вариантах. Основная проблема — ресурсы. Ресурсы нужны двух видов — тексты и вычисления.
Давайте посмотрим, сколько вычислительных ресурсов нужно было Сберу и Яндексу для обучения русских языковых моделей:
Таблица 1. Ресурсы для нужные для обучения больших языковых моделей*
Модель | Число параметров в модели | Время обучения GPU/час | Число GPU использованных при обучении | Приблизительная стоимость вычислений при аренде ресурсов в облаке, руб |
RuGPT3-small | 117 млн | 5376 | 32 | 940 тыс |
RuGPT3-medium | 345 млн | 32256 | 64 | 5.6 млн |
RuGPT3-large | 762 млн | 43008 | 128 | 7.5 млн |
RuGPT3-XL | 1.3 млрд | 61440 | 256 | 10.7 млн |
RuGPT3–12B | 12 млрд | 609484.8* | ? | 106 млн |
YaLM-10B | 13 млрд | 626688.0 | ? | 109 млн |
* Учтены лишь чистые затраты на вычисления. Фактически данная работа требует много предварительных экспериментов и работы специалистов, что тоже является существенной статьей затрат
** Для этих моделей точных данных по затратам на обучение найти не удалось, цифры ориентировочные исходя из числа параметров и затрат на обучение аналогичных моделей от OpenAI
Примечание об истории обучения русских GPT-подобных моделейНа самом деле еще до Сбера существовали русские варианты GPT-2 c на 340 миллионов и 1.5 миллиарда параметров. Их обучали энтузиасты, инициализируя веса моделей весами английской GPT-2 и постепенно «размораживая» веса этих слоев (можно прочитать например тут). Поэтому утверждение Сбера о первой русской GPT-3 не совсем корректно, учитывая, что модели ruGPT3-small до ruGPT3-large и по размерам и по архитектуре являются GPT-2, отличаясь лишь длиной контекста. Основное преимущество GPT-3 над GPT-2 не в длине контекста, а в размере и главное в публикации OpenAI был именно анонс модели с 175 млрд. параметров, ценность остальные же вариантов была в возможности сравнительного анализа. Поэтому ruGPT3 лишь формально GPT-3, а фактически ближе к GPT-2 ибо в сверхбольших языковых моделях размер принципиально важен.
Поэтому было бы неплохо, если бы крупные компании рассказывая о своих достижениях помещали их в общий контекст, а не игнорировали предыдущие работы как будто их вовсе не было. Другое дело, что степень «дообученности» предыддущих моделей вероятно была недостаточной и какого-то убедительного численного сравнения их характеристик не проводилось (или я про него не знаю).
Обучение же «настоящей» GPT-3 с 175 млрд параметров требует в этих условиях абсурдно большой суммы в миллиард рублей.
С другой стороны, на самом деле подход, когда берется монолитная модель и увеличивается в размерах довольно топорный. Он легок для компаний, которые имеют много денег и не хотят рисковать придумывая какие-то другие подходы, потому что отличается концептуальной простотой и предсказуемостью результата. Но есть основания полагать, что этот метод не самый лучший.
Например, биологический мозг не работает таким образом. Мозгу вовсе не нужно вычислять выходы каждого из 100 миллиардов нейронов для любого действия — он умеет задействовать только те части, которые реально нужны для конкретной задачи. Аналогично, если мы учим новое слово, это не значит, что будут обновлены «веса» всех нескольких триллионов синапсов.
Примечание: маленький мозг не означает глупыйЧасто считается, что «интеллектуальная» функция — сложное и гибкое поведение, способность вводить новшества и учиться — требует большого высокоразвитого мозга и свойственна только человеку и в некоторой степени высокорзавитым животным, таких как шимпанзе и дельфины. Более примитивные существа, поведение которых обычно определяется инстинктами, имеют небольшой, сравнительно простой мозг, состоящий из относительно небольшого числа нейронов.
Но существует много интересных примеров обратного. Так, например, пауки рода Portia имеют мозг размером с булавочную головку, но очень примечательные интеллектуальные способности. Portia является не обычным пауком — он хищник, который ловит для своего пропитания пауков других видов. Одной из его замечательных способностей является его способность прокладывать путь к своей жертве. Для животного, действующего инстинктивно если нечто пропало из виду, оно пропало и из головы. Однако Portia часами подкрадываться к своей жертве, даже если это означает потерю жертвы из виду на долгое время, решая при этом задачу, которая является сложной даже для высших обезьян [4]
Обычные пчелы могут научится распознавать абстрактные атрибуты объектов, такие как радиальная и билатеральная симметрия, использовать нарисованные на стенах обозначения для навигации в лабиринте и даже справляются с проблемой отложенного сопоставления стимула с образцом — задачи, которая лежит в основе многих батарей когнитивных тестов, ориентированных на человека.
Эта мысль реализуется, например, в архитектуре Mixture of Experts (MoE). Данных подход стал известен после публикации [5]. Суть заключается в том, что существует некий переключатель, который для каждого шага выбирает несколько «экспертов» т. е. частей модели со своим набором весов, что сокращает необходимое количество вычислительных операций (общий принцип упрощенно показан на рисунке 1).
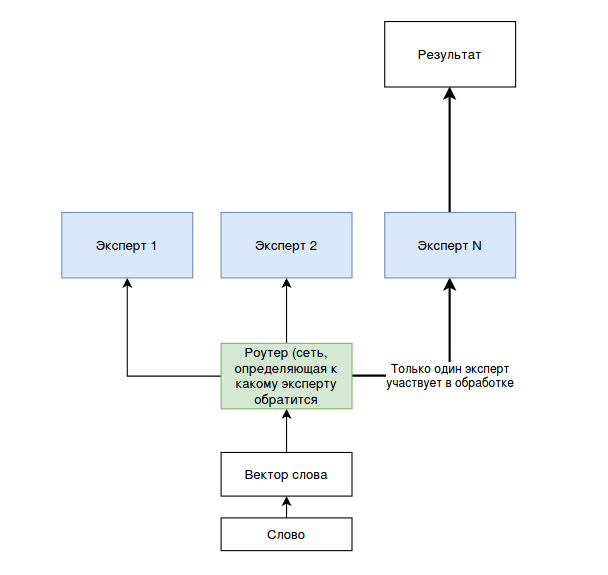 Рисунок 1. Упрощенная иллюстрация работы механизма Mixture of Experts
Рисунок 1. Упрощенная иллюстрация работы механизма Mixture of ExpertsВ 2020 году исследователи из Google Brain упростили этот подход, оставив для каждого шага только одного эксперта, что улучшило масштабируемость и сделало обучение более стабильным. Это дало возможность Google обучить Switch Transformer [6].
Switch Transformer это не совсем языковая модель в стиле GPT-2/3 так как он основан на предсказании не следующего слова, а случайного слова в середине предложения. (так называемый Masked Language Objective). У этого есть свои причины, но в рамках этой статьи я не буду в них углубляться сейчас.
В итоге, Switch Transformer обучается до тех же значений целевой функции быстрее в 2.5–6 раз, чем такая же монолитная (или плотная — англ. dense) модель, но есть два минуса.
Во-первых, улучшения в способности предсказания слова не всегда равномерно транслируются в улучшения с точки зрения решения моделью каких-то задач. Например Switch Transformer c 390 миллиардами параметров показывает на тесте SuperGlue в среднем несколько худший результат, чем обычная модель с 13 миллиардами параметров (SuperGlue это широко используемый набор из 10 различных задач на понимание естественного языка).
Если мы посмотрим на рисунок из статьи (рисунок 2, перевод названий осей мой), то видно, что для результаты растут с увеличением числа параметров для всех моделей, но результаты плотных моделей относительно Switch моделей сдвинуты на некоторую константу. Причина этого видимо лежит в том, что Switch модели улучшают перплексию прежде всего за счет способности запомнить больше деталей из конкретных областей, а не за счет общей «сообразительности». Зато в задачах, требующих знания фактов (типа ответов на вопросы пользователя вроде «Сколько звезд видно на небе невооруженным глазом?»), большие Switch модели показывают лучший результат.
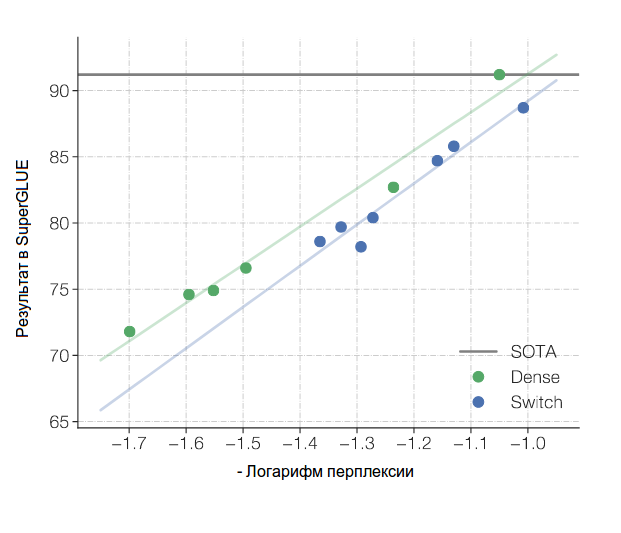 Рисунок 2. Сравнение результатов Switch моделей с монолитными (Dense) моделями
Рисунок 2. Сравнение результатов Switch моделей с монолитными (Dense) моделямиМне хочется думать, что именно из-за этого Яндекс и Сбер обучают монолитные модели (альтернатива — они просто идут более простым путем).
С точки зрения самостоятельного обучения, Switch с одной стороны обучается быстрее (что менее затратно), но он все равно требует наличия большого числа GPU, чтобы хранить одновременно веса и градиенты, либо эти веса придется постоянно подгружать из ОЗУ или даже с диска (т. к. оперативная память размеров в сотни гигабайт это тоже дорого). Скорость при этом будет совершенно неприемлема.
Нам нужна архитектура компоненты которой можно обучать независимо, или хотя бы так, чтобы переключение было редким и соответственно не съедало много времени. Насколько это возможно?
Многие ученые считают, что правило обучения биологического нейрона должно быть локальным (т. е. зависеть только от непосредственного окружения нейрона, без передачи градиентов). Существует даже много попыток заменить обратное распространение ошибки на локальное правило [7, 8], однако на задаче построения моделей языка такие вещи пока работают не очень хорошо. Поэтому я пошел компромиссным путем — каждый эксперт обучается обычным образом (и представляет из себя обычный трансформер), а взаимодействовать эксперты учатся с помощью локального правила.
Данные и условия обучения модели
С целью первого опыта я взял 20GB русского Common Crawl, кое-как почистил его от мусора и добавил отдельно данные русской Википедии (7GB) и коллекцию текстов книг (5GB). Для обучения модели потребовался месяц работы двух карт RTX 2080Ti (стоимость времени при покупке в облаке составляет примерно 70000 руб).
Модель, которую я пока условно обозначил кодовым именем GM30B содержит 30 миллиардов параметров (и занимает около 160 GB места на жестком диске). Пока что модель сильно недообучена (32 GB очень мало для модели такого размера), поэтому приведенные результаты следует считать промежуточными и цель производимого анализа это понять, имеет ли смысл в этой идее и стоит ли продолжать работу дальше.
Результаты
Перплексия это наиболее часто используемая мера «качества» языковой модели, показывающая насколько хорошо модель описывает реальное распределение вероятности слов в тексте. Интуитивно можно представить себе перплексию как степень ветвления, например если модель имеет перплексию 100, то в среднем модель колеблется при выборе следующего слова между 100 разными словами
Таблица 2. Сравнение перплексии с различными моделями
Модель | Перплексия (меньше — лучше) |
RuGPT3-small | 30.91 |
RuGPT3-medium | 22.96 |
RuGPT3-large | 21.34 |
GM30B | 18.02 |
Перплексия всех моделей, измеренная на тестовой выборке из моего датасета, показана в таблице 1. Известно, что в выборку для обучения моей модели тестовый набор не входил, относительно моделей Сбера ничего не известно, так как обучающий набор Сбер не опубликовал. Цифры естественно отличаются от тех, которые опубликованы Сбером, так как набор данных другой.
По этой же причине, верить данному сравнению можно с определенными оговорками — модель могла привыкнуть к каким-то особенностям данных. Тем не менее, пока результат обнадеживает. На самом деле это достаточно удивительно для меня, потому что большинство попыток изобрести какой-то свой велосипед в глубоком обучении обычно заканчивается пшиком (отсюда и стремление крупных компаний использовать те вещи, о которых уже известно, что они хорошо работают).
Генерация теста
По отдельным примерам довольно сложно судить о качестве генерации, тем более, что все сравниваемые тут модели генерируют в большинстве случаев достаточно качественный текст. Но так как статья была неполной без примеров, вот некоторые результаты. Все тексты получены при одинаковых параметрах генерации (кроме YaLM, тут тексты просто получены через сайт «Балабобы», параметры неизвестны).
Контекст: Также ученые сообщили об обнаружении метанола в отдаленных от центра Млечного Пути молекулярных облаках. По словам исследователей, их открытие ставит под сомнение
Сгенерированные Продолжения:
ruGPT3-medium: гипотезу о том, что Земля вращается вокруг своей оси.
ruGPT3-large: гипотезу о том, что облака состоят из метана, а не из аммиака, как считалось ранее. Узнай как замшелые убеждения, стереотипы, страхи, и другие«глюки» мешают человеку стать финансово независимым и начать жизнь без страха!
ruGPT3-XL: общепринятое мнение о том, что метанол образуется в результате фотосинтеза. Ранее сообщалось, что астрономы впервые увидели на снимке Млечного пути молекулярные облака
YALM (с сайта «Балабобы»): существующее представление о том, что в этих облаках не может быть жизни. В то же время открытие метанола является еще более удивительным, так как эти молекулы, которые могут существовать в космосе, были обнаружены именно в молекулярных облаках.
GT30B: общепринятую теорию, согласно которой метана в галактиках намного больше, чем считалось до сих пор. Ученые проанализировали данные, собранные космическим телескопом «Хаббл», и пришли к выводу, что в скоплениях галактик содержится гораздо больше диоксида углерода (СО2), чем предполагалось ранее.
Про «замшелые стереотипы» у ruGPT3-large видимо проявляется проблема с очисткой текста для обучения — эта модель как-то особенно подвержена неожиданной смене темы.
Контекст: Я огляделась по сторонам и увидела женщину, торопливо уводящую нескольких детей подальше от двух наших групп. Она тоже оглянулась, перевела взгляд на нас и приказала своим отпрыскам поторапливаться. Младший захныкал, пытаясь задержать ее у витрины со сладостями*
Сгенерированные Продолжения:
Продолжения:
ruGPT3-medium: Мы последовали за ней по длинному коридору, в конце которого была дверь. Женщина открыла ее, и мы вошли в небольшую комнату, заставленную столами и стульями.
ruGPT3-large: Идемте, — сказала она, и мы последовали за ней, не обращая внимания на то, что она орет на нас, как наседка на цыплят. Когда мы проходили мимо прилавка со свежими фруктами, она схватила меня за руку и потащила за собой, так что я едва поспевала за нею. Мы остановились перед витриной с мороженым
ruGPT3-XL: Женщина оглянулась на нас и сказала: «Не мешайте нам ». Мы переглянулись и стали медленно обходить магазин с другой стороны. Женщина все еще смотрела на нас.
YAML (c сайта «Балабобы»): — Я уже купила! — воскликнула она, вытаскивая из кармана монету. — Несите эту мерзость обратно! — крикнула я
GM30B: но она не обратила на него ни малейшего внимания, продолжая уводить детей прочь от нас. Мы пошли вслед за женщиной по направлению к выходу из рынка, и, когда она скрылась из виду, я услышала, как один из моих спутников сказал другому: — Что-то в поведении этой женщины показалось мне странным, но я никак не могу понять, в чем дело.
* Контекст взять из перевода романа К. Азаро «Инверсия Праймери». В обучающих данных для GM30B данного романа нет, относительно других моделей это неизвестно.
Дообучение на новых задачах генерации
Важной чертой предобученных языковых моделей является то, что им нужно гораздо меньше данных, чтобы обучится новой задаче. Возможность дообучить модель на небольшом количестве данных очень важна для практики. Для сравнения я взял задачу генерации отзывов о магазине и произвел дообучение разных моделей на небольшом наборе в 400Kb текста (400Kb считается небольшим набором, так как при обучении «с нуля» обычно нужны сотни мегабайт данных для получения приемлемого результата).
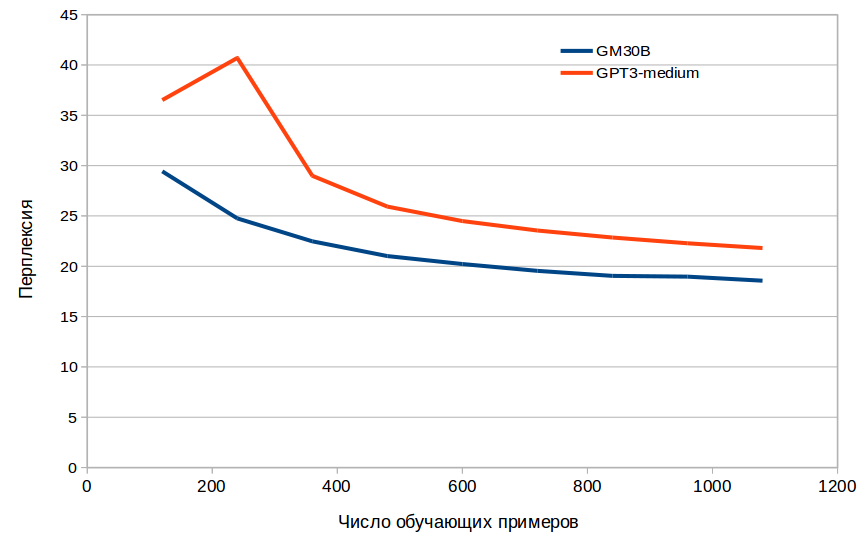 Рисунок 3. Сравнение эффективности дообучения GM30B и ruGPT3-medium
Рисунок 3. Сравнение эффективности дообучения GM30B и ruGPT3-mediumНа рисунке 3 приведено сравнение дообучения с ruGPT3-medium. Видно, что обучение происходит быстрее и для достижения одинаковых значений перплексии требуется меньше обучающих примеров.
Это может по идее уже приносить практическую пользу. У нас часто встречаются клиенты с задачами генерации текстов имеющие всего несколько сотен примеров и получается, что возможно в этой задаче результат будет лучше при сравнимых затратах (Правда, для уверенности следует повторить этот опыт на разных видах текстов).
Решение задач
Интересно посмотреть, как наша модель справится с решением общепринятых задач. Хотя тут я не ожидаю изначально чудес, так как природа модели не располагает к тому, чтобы она была особо хороша в этой области.
Пока что я успел проверить работоспособность модели на одной такой задаче.
PARus это задача являющаяся частью набора «Russian SuperGlue». Согласно описанию на сайте:
«Каждый вопрос в PARus состоит из предпосылки и двух альтернатив, где задача состоит в том, чтобы выбрать альтернативу, которая более правдоподобно имеет причинную связь с предпосылкой. Правильная альтернатива рандомизируется, так что ожидаемая эффективность случайного угадывания составляет 50%»
Например, дан текст «Гости вечеринки прятались за диваном», нужно выбрать причину: «Это была вечеринка-сюрприз» или «Это был день рождения». Правильные ответы тестовой выборки скрыты, но проверить результат модели можно на сайте.
Таблица 3. Сравнение результатов моделей в задаче PARus
Модель | Точность |
RuGPT3-small | 0.562 |
RuGPT3-medium | 0.598 |
RuGPT3-large | 0.584 |
RuGPT3-XL | 0.676 |
GM30B | 0.704 |
YaLM 1B | 0.766 |
Все значения для сравнения взяты из таблицы Leaderboard на сайте «Russian SuperGlue». Взяты только показатели языковых моделей работающих в режиме обучения на маленьком числе примеров. Результаты GM30B приведены для режима zero-shot learning, когда не используется вообще никаких примеров из обучающей выборки, модель опирается только на то, что сама знает. Точные детали как проверялись остальные модели их разработчиками неизвестны.
В данной задаче, судя по результатам, GM30B уступает только модели от Яндекса, опережая RuGPT3-XL.
Скриншот с сайта Russian SuperGlue c результатом по задаче PARus
Какие выводы мы можем пока что сделать из всего этого? На мой взгляд, есть основания полагать, что обучение языковых моделей, которые хотя бы по некоторым параметрам не уступают существенно ruGPT3/YaLM все же по силам пока что для независимых разработчиков, не обладающих ресурсами крупных компаний. Правда для полной картины пока не хватает результатов других тестов.
Почему это важно и важно ли?
Большие языковые модели открывают возможности для создания совершенно новых классов приложений, которые были невозможны или сложны в реализации ранее. Это генераторы программного кода (включая недавно анонсированный GitHub Copilot), генераторы дизайна, новые классы игр, где ИИ придумывает сюжет и действия персонажей, генераторы скриптов для видео, генераторы контент-плана для продвижения в соц. сетях, интеллектуальные помощники копирайтера, медицинские консультанты и еще много разных вещей. Кроме того, многие существующие задачи решаются быстрее, например сильно упрощается извлечение данных из неструктурированного текста, создание чат-ботов.
При этом доступ разработчиков к этим чудесам сильно неравномерен. К английской GPT3 OpenAI до сих пор выдает доступ лишь избранным, выбирая тех, кто «достоин» с их точки зрения. Причем критерий «достойности» судя по всему абсолютно произвольный.
Замечания о том, как OpenAI отбирает достойныхЯ заполнил форму запроса доступа к GPT-3 в день появления, расписав подробно про задачи, себя, публикации по теме и т.п. Ожидаемо, я не получил никакого ответа до сих пор. В принципе, мои заслуги достаточно скромны, поэтому я не особо удивлися. Но среди клиентов моей компании оказались люди с ключом доступа и некоторые его получили по их словам просто «введя какую-то ерунду в форму». Собрав данные тех кто получил ключ и тех кто не получил, я не нашел у получивших каких-то особенных качеств. Конечно, это субъективное наблюдение, основанное на маленькой выборке и сделать определенный вывод на его основании нельзя.
Но это не единственная проблема, еще «интереснее» получается, когда сама компания создатель или владелец такой модели начинает предлагать не доступ, а создание конечных продуктов. Например, та же Microsoft инвестировав в OpenAI 1 млрд долларов получила эксклюзивные права решать, что делать с GPT3 (по соглашению с OpenAI). Теперь Microsoft создает уникальные продукты, например в области автоматизированного написания кода, тот же GitHub Copilot, имея преимущество в возможности дообучать самый большой вариант GPT3. Пока неясно, к чему это приведет, но потенциал для создания монополии кажется значительным, потому что аналогичным стартапам вроде source.dev, имеющим доступ только к API генерации, конкурировать с такими возможностями будет тяжело, да за API они платят, значит продукт должен быть платный для клиента.
С русскими моделями ситуация не лучше (если не хуже). Приведу такой сравнительный пример. Во времена когда OpenAI обучил GPT-2, они постепенно выкладывали модели в открытый доступ и энтузиасты стали делать простые интернет страницы, где можно было с помощью них генерировать текст. Один из таких проектов, talktotransformer собрал миллионы просмотров и превратился в популярный сервис InferKit. Вокруг InferKit далее появилось несколько клонов и сайтов расширяющих функционал, и теперь это целая область со своей средой. Плюс многие сервисы, которым недоступен API GPT-3 от OpenAI теперь используют InferKit и подобные вещи, например ряд популярных сервисов для копирайтеров.
Теперь вопрос, а что было бы если бы OpenAI выложил на своем сайте такую форму для генерации текста? Это лишило бы смысла сайты типа talktotransformer, барьер вхождения в область бы резко повысился и скорее всего InferKit никогда бы не возник. Т.е. некие случайные движения разработчика языковых моделей могут создавать и уничтожать довольно большие ниши для независимых разработчиков и небольших компаний.
Как мы знаем, Сбер выложил такую форму на свой сайт, а Яндекс пошел дальше и сделал целый бесплатный сервис генерации текстов, что убивает потенциально большое число сторонних приложений, так как маленькие компании не могут предлагать подобные вещи бесплатно даже имея модель от Сбера — GPU сервера для запуска больших монолитных моделей стоят существенных денег, да и качество открытой ruGPT3-XL заметно ниже.
Тут можно возразить, что люди только выиграют, если какой-то сервис будет делать крупная компания и бесплатно. Но у такой ситуации есть и минусы — она ведет к образованию монополий, что плохо для развития отрасли (меньше разнообразия всегда плохо с точки зрения эволюции) и плохо в итоге и для пользователя — монополия может начать навязывать всякие условия от которых невозможно отказаться.
Конечно, все это не уникально для языковых моделей и можно вспомнить множество областей в IT, где существует аналогичная ситуация. Это в какой-то степени «естественный» процесс обусловленный объективными причинами и повлиять на него как-то серьезно вряд ли возможно. Тем не менее, если языковая модель может быть при определенном усилии сделана более доступной для индивидуальных разработчиков и небольших компаний, это может принести определенную пользу.
Еще один момент на который нужно обратить внимание — сам исследовательский процесс разработки и обучения новых архитектур в этой области важен. Ну действительно, получается, что все сверхбольшие модели для русского языка это копирование GPT-3 с небольшими вариациями или вообще без таковых. Да, технически задача параллельного обучения на кластере непростая, но это именно техническая задача, выполняя ее мы ничему не учимся в плане дизайна архитектур и понимания как ведут себя различные модификации. Это может закончится тем, что мы вообще разучимся создавать что-то оригинальное и сможем только копировать с небольшими изменениями (Сами названия ruGPT3 и YaLM — Yet Anoter Language Model — говорящие, как мне кажется).
Заключение
В этой статье я попробовал усомнится в тезисе о том, что эксперименты с обучением сверхбольших языковых моделей доступны только для крупных компаний. Хотя приведенные результаты пока не позволяют с уверенностью опровергнуть этот тезис, они дают нам основание для надежды.
Список литературы
1. Trinh, Trieu H., and Quoc V. Le. «Do language models have common sense?.» (2018). https://openreview.net/forum? id=rkgfWh0qKX
2. Radford, Alec, et al. «Language models are unsupervised multitask learners.» OpenAI blog 1.8 (2019): 9.
3. Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
4. Prete, Frederick R., ed. Complex worlds from simpler nervous systems. MIT press, 2004.
5. Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
6. Fedus, William, Barret Zoph, and Noam Shazeer. «Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.» arXiv preprint arXiv:2101.03961 (2021).
7. Liang, Yuchen, et al. «Can a Fruit Fly Learn Word Embeddings?.» arXiv preprint arXiv:2101.06887 (2021).
8. Ryali, Chaitanya, et al. «Bio-inspired hashing for unsupervised similarity search.» International Conference on Machine Learning. PMLR, 2020.и
