Мониторинг проектов: сравнительный анализ существующих решений

Предлагаем вашему вниманию публикацию, написанную по мотивам выступления Антона Баранова, ITSumma, на летней конференции BitrixSummerFest.
В этом посте я расскажу, что нужно с самого начала мониторить в проектах, в том числе высоконагруженных. Разберем аспекты, связанные с open source-системами мониторинга, в частности Zabbix и Graphite, а также присмотримся к нескольким SaaS-решениям для мониторинга.
Итак, нужно с самого начала решить для себя, какие параметры системы необходимо мониторить. Условно можно выделить три направления мониторинга:
- Потребление ресурсов.
- Работа серверного ПО.
- Бизнес-логика приложения.
Ресурсы
Они делятся на два вида: критические и важные. К критическим относятся те ресурсы, нехватка которых гарантированно приведёт к неработоспособности вашего приложения. Например, если процессор полностью загружен, то новые запросы не будут обработаны быстро. А это может привести к уходу пользователей.
Также к критическим ресурсам относятся оперативная память, пропускная способность дисковой подсистемы, пропускная способность сети. При нехватке каждого из этих ресурсов отзывчивость вашего сервиса может упасть настолько, что вы начнёте терять аудиторию.
Важные ресурсы — это те, по динамике изменений которых можно предположить, что с проектом скоро возникнут проблемы. Например, если у вас начинает использоваться своп-файл, то в большинстве случаев это говорит о нехватке оперативной памяти. К тому же использование своп-файла снижает производительность системы, и в результате это может привести к недоступности проекта для пользователей.
Статус RAID, то есть дисковой подсистемы, статус «здоровья» самих дисков, может свидетельствовать о скором возникновении сбоя и потере информации. Также достаточно важной метрикой является IOPS — количество операций ввода/вывода в секунду. Обращайте внимание и на AVIO диска — среднее время ответа на запросы к диску. Если, например, AVIO равно порядка 10 миллисекунд, то пора задуматься, не поменять ли конкретный диск. Очень рекомендуется мониторить количество использованных сокетов на сервере, температуру процессора и скорость вращения вентиляторов.
Особенно обращаю ваше внимание на температуру процессора — бывают случаи, что когда процессор перегревается, то сервер просто не может нормально обрабатывать все поступающие запросы.
Серверное ПО
Здесь необходимо ясно представлять себе, что и зачем мониторится. То есть нужно полностью отдавать себе отчёт, для чего нужен каждый параметр, который мы ставим на мониторинг, для которого настраиваем уведомления, за что он отвечает.
Nginx. Для этого продукта RPS, безусловно, самая важная характеристика. Эта аббревиатура расшифровывается как requests per second, то есть количество запросов к вашему сайту в секунду.
PHP-FPM. Здесь нужно также мониторить RPS, количество активных процессов, сообщения о том, что pool PHP-FPM достиг предела по количеству процессов.
Sphinx. Это система полнотекстового поиска на сайтах. Здесь необходимо мониторить количество запросов и Fatal Error. Дело в том, что в версиях Sphinx ниже 3.х в отдельных случаях могут регистрироваться ошибки, ведётся лог, но при этом система работает, принимает запросы и не отвечает на них. В этом случае мы получаем очень нехорошую ситуацию: казалось бы, всё работает замечательно, запросы на Sphinx идут, но при этом на сайте пустая страничка с кодом 200.
MySQL. Необходимо мониторить количество запросов к базе данных: select, update, insert. Необходимо отслеживать количество обрабатываемых строк. Например, вы немного изменили логику проекта и у вас теперь используются другие запросы, а вот индексы вы забыли добавить. Следующий параметр для отслеживания: скорость обработки столбцов. Скажем, если раньше у вас обрабатывалось 10 миллионов в минуту и всё было хорошо, то теперь совершенно внезапно обрабатывается 120 миллионов столбцов, диски работают на пределе, всё тормозит. Так что отслеживание этого параметра может дать понять, в чём именно проблема после очередного деплоя.
Также необходимо контролировать buffer pool usage и replica status. Cтатус реплики очень важен в том случае, когда применяется отказоустойчивая схема. Таким образом мы отслеживаем, чтобы резерв был в активном состоянии.
Exim. Мониторьте размер очереди почтового сервера. Если она очень быстро растет или долго не уменьшается, это может говорить о том, что, например, какой-нибудь почтовый сервис забанил наш сервер и считает все письма с него спамом.
Бизнес-логика
Необходимо мониторить группу параметров, которые относятся к бизнес-логике приложения. Почему-то многие про них забывают, сосредотачиваясь на сервере и логах ПО. В самом проекте можно мониторить компоненты бизнес-процессов. Например, количество новых регистраций пользователей, которые хотят совершить покупки. В ряде случаев снижение количества может быть и косвенным свидетельством каких-то поломок в проекте.
Но если процесс регистрации работает некорректно, то пользователь не сможет разместить заказ, оформить покупку, оплатить и т.д. Поэтому в отдельных ситуациях, когда мы не уверены в том, что у нас не поломался процесс регистрации, имеет смысл мониторить весь процесс от начала и до конца. То есть от момента ввода пользователем своих данных до того, как он нормально залогинится и увидит в корзине свои товары.
В зависимости от принятой бизнес-логики на сайтах, которые занимаются распространением приложений, необходимо мониторить, например, количество скачиваний. В рекламных проектах рекомендуется отслеживать количество показов баннеров, их просмотров, отношение просмотров к кликам и т.д.
Косвенный, но не менее важный параметр — это доступность сервисов компаний-партнёров, используемых в вашем проекте. К пример, Java-скрипт, который подгружается со стороннего сервера. Если у партнера тормозят серверы, то Java-скрипт будет грузиться медленно. Это будет особенно нехорошо, если ваш сайт построен так, что без этого Java-скрипта загрузка страницы дальше не идёт. Получается, что проблемы у чужого дяди, а страдают ваши пользователи.
Также в отдельных ситуациях помогает статистика по запросам с тем или иным реферером. Это очень актуально для партнёрок: мы может понять, где и кто накручивает трафик. Если вы или ваш клиент предполагаете, что где-то в коде закралась ошибка и статистика считается неправильно, то можно скорректировать её по логам.
Как мониторить сложные цепочки бизнес-логики? Например, проверить работу формы регистрации? Можно поступить так:
- Создаём почтовый сервер.
- Пишем PHP-скрипт, который идёт на клиентский сайт и регистрируется как обычный пользователь.
- После этого скрипт проверяет содержимое ящика, парсит письмо, берёт из него ссылку подтверждения регистрации, проходит по ней, получает ответ, парсит его и логинится с теми данными, с которыми зарегистрировался.
- В завершение всех процедур скрипт отправляет в систему мониторинга 1 или 0, в зависимости от результатов проверки. Естественно, все действия скрипта должны подробно логгироваться.
Проблемы с системой мониторинга
Мониторинг тоже может ломаться. Поэтому очень важно отслеживать работоспособность самой системы мониторинга. Это может быть какой-то отдельный скрипт, запускающийся по cron, или какая-то другая проверка. Но самое главное — необходимо проверять, что мониторинг доступен, работает, оправляет уведомления, проверяет значения, сверяет их с настроенными вами уведомлениями и т.д. Без этой проверки в один прекрасный момент вы можете обнаружить, что вроде бы графики рисуются, а сервис лежит уже третий день.
Инструменты мониторинга
Начнем с open source-систем, Zabbix и Graphite.
Zabbix
Бэкенд системы написан на PHP, в качестве БД для хранения метрик может использоваться MySQL, PostgreSQL, SQLite или Oracle. На клиентской стороне может применяться либо Zabbix-агент, либо SNMP, либо какие-то скрипты, которые посылают данные в Zabbix. Под «клиентом» подразумевается сервер, который мы мониторим.
Как строится процесс мониторинга в Zabix:
- Создаем хост в Zabbix.
- Добавляем сервер, который будем мониторить.
- Устанавливаем на нём Zabbix-агент.
- Настраиваем в Zabbix шаблоны, которые надо мониторить, например, Nginx, MySQL. Если каких-то шаблонов нет, можно их нагуглить или написать.
- Настраиваем агента, чтобы он посылал в Zabbix необходимые параметры.
- Настраиваем web-сценарий для того, чтобы проверять URL на проекте.
Мониторинг Nginx:
- Находим и импортируем шаблоны, поскольку в самом Zabbix нет встроенной проверки Nginx.
- На стороне клиента пишем bash-скрипт, который будет отправлять в Zabbix данные из Nginx-статуса в нужном формате.
- Прописываем include в Zabbix-агент.
После всех этих манипуляций Zabbix начинает мониторить Nginx.
Уведомления в Zabbix построены по принципу у шаблона. У каждого из них есть метрики для мониторинга. Например, RPS, количество запросов и т.д.
У каждой из метрик есть триггер. Скажем, при мониторинге Nginx мы можем сделать для RPS триггер, который сработает, если RPS = 0 в течение пяти минут. При срабатывании триггера отправляется уведомление на почтовый ящик или в любую другую систему уведомлений, которую мы выбрали.
В целом, Zabbix довольно сложен в конфигурировании. Zabbix-сервер масштабируется также, как и любое другое web-приложение, то есть мы можем распараллелить базы данных, web-серверы. При желании можно автоматизировать мониторинг новых услуг. Например, взять любимую систему управления конфигурациями и настроить так, чтобы новый узел после создания автоматически добавлялся в Zabbix.
Cacti
Это система с открытым исходным кодом. В качестве бэкенда базы данных для внутренних моментов используется MySQL. Информация о метриках хранится в формате rrdtool, то есть все данные метрик, как и сама Cacti, написаны на PHP. На клиентской стороне используется SNMP-демон, который отправляет данные на сервер Cacti.
Как строится процесс мониторинга в Cacti:
- Устанавливаем на сервер snmppd.
- Конфигурируем rocommunity в snmpd — идентификатор этого сервера.
- Добавляем хост Cacti.
Как видите, всё предельно просто. Сложности начинаются дальше. По умолчанию доступен мониторинг только самых базовых ресурсов — CPU, память, трафик. Все остальные параметры (Nginx, MySQL, почта и т.д.) мониторятся при помощи сторонних плагинов, которые устанавливаются дополнительно. Даже для уведомлений на e-mail требуется плагин. То же самое относится и к мониторингу URL (доступности вашего сайта), настройки уведомлений по превышению каких-то значений и многого другого.
Процесс создания алерта выглядит так:
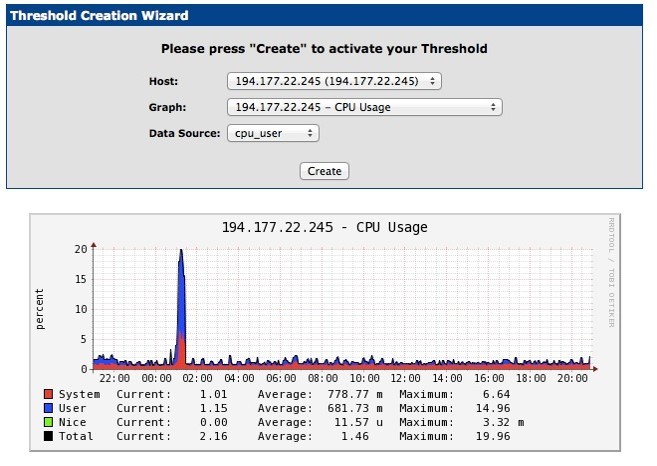
Выбираем сервер, график и метрику. На этом графике, например, у нас метрики System, User, Nice, загрузка CPU. Уведомление отправляется при превышении загрузки CPU User.
Cacti нельзя назвать гибкой системой. Если Zabbix, например, позволяет с помощью плагинов отправлять уведомления через самые разные системы, в том числе Jabber, Slack и т.д., то в Cacti уведомлению отправляются только через e-mail посредством отдельного плагина.
Так выглядит уведомление, пришедшее на e-mail:
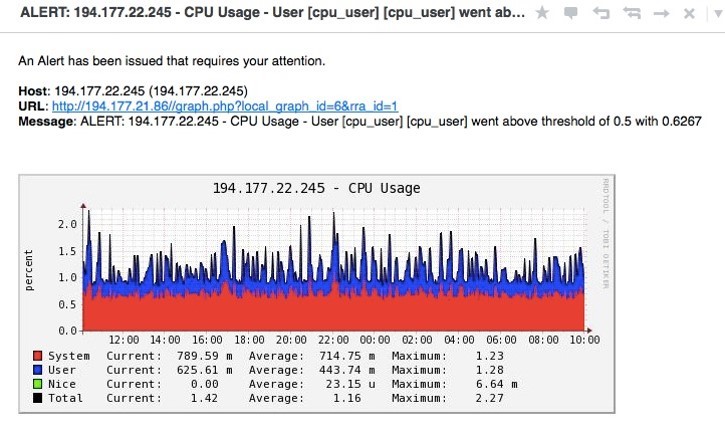
Подведём итог. Мониторинг в Cacti осуществляется либо посредством SNMPD, в котором мы прописали отправку информации на сервер через какие-то наши скрипты, либо с помощью каких-то плагинов, которые устанавливаются на сам сервер Cacti. Уведомления отправляются только на e-mail.
С автоматизацией у Cacti тоже всё достаточно плохо: здесь есть только cli-скрипты из командной строки, которые выполняются на стороне сервера и обладают плохой гибкостью. Масштабируется Cacti как обычное web-приложение, то есть можно горизонтально масштабировать MySQL, можно поставить Nginx, за которым будет несколько web-nod и т.д.
Graphite
Эта система с открытым исходным кодом поинтереснее, чем Zabbix и Cacti. Серверная часть системы состоит из трёх частей — Carbon, Whisper и web-приложение Graphite. Последний компонент представляет собой подсистему для отрисовки графиков и их отображения в web.
- Carbon — демон, в который стекаются данные мониторинга с клиентов.
- Whisper — база данных на стороне сервера, в которой накапливается статистика по мониторингу.
- Web-приложение Graphite — подсистема, которая показывает в браузере красивую страничку с графиками.
На клиентской стороне мы можем установить любое ПО, которое будет отсылать Graphite данные в нужном формате. Существует достаточно много решений, можно написать и своё собственное, если готовые вас чем-то не устраивают.
Мониторинг с помощью Graphite предельно прост:
- Устанавливаем не клиент, например, collectd.
- Включаем нужные плагины.
- Указываем, какие параметры надо мониторить.
- Конфигурируем их соответствующим образом. Например, прописываем доступ к MySQL или к статусу Nginx, и настраиваем оправку данных в Graphite.
<Plugin mysql>
<Database test1>
Host "127.0.0.1"
User "root"
Password "sohW2ax0Eenox9t"
Database "test1"
MasterStats false
</Database>
</Plugin>
Можно мониторить что угодно и чем угодно. Лишь бы ваше приложение нормально отправляло данные в Graphite. Так выглядит стандартное джанговое приложение, которое отрисовывает данные с Graphite.

Если нужны более красивые графики, то можно использовать другие приложения.
Уведомления настраиваются достаточно гибко. К пример, есть решения, которые позволяют отправлять уведомления через почту, HipChat, Slack, либо на свои собственные сервисы. Пример настройки уведомлений:
"alerts": [
{
"name": "Memory",
"query": "aliasByNode(collectd.*.memory.memory-free, 1)",
"interval": "1minute",
"format": "bytes",
"rules": ["warning: < 300MB", "critical: < 200MB"]
},
Всё делается в текстовом формате, после чего перезагружаем систему уведомлений, и она подхватывает новые параметры. Пример уведомления, пришедшего на почту:

Graphite довольно гибкая система, которая позволяет мониторить практически всё, что угодно. Конфигурировать надо в основном на клиентской стороне, то есть ту часть, которая отправляет данные мониторинга на сервер. Уведомления настраиваются как угодно. Автоматизация осуществляется просто, в текстовом формате.
Graphite масштабируется горизонтально. У используемого в нём движка хранения Whisper есть ограничения: при большом количестве серверов (от нескольких десятков) мы упираемся в ограничение самого формата, и в этом случае надо менять бэкенд. Но такое происходит не часто, поэтому изначально можно использовать только Whisper.
Если у вас много рабочих серверов, и один сервер мониторинга не справляется со всеми метриками, то для масштабирования можно использовать решение Graphite-relay.
SaaS-мониторинг
Данный подход применяется, когда сервер мониторинга находится на стороне компании-разработчика.
В качестве примера рассмотрим сервер Density. Регистрируемся в сервисе и добавляем туда свой сервер. Нам выдают ссылку, по которой мы скачиваем агент и устанавливаем на свой сервер.
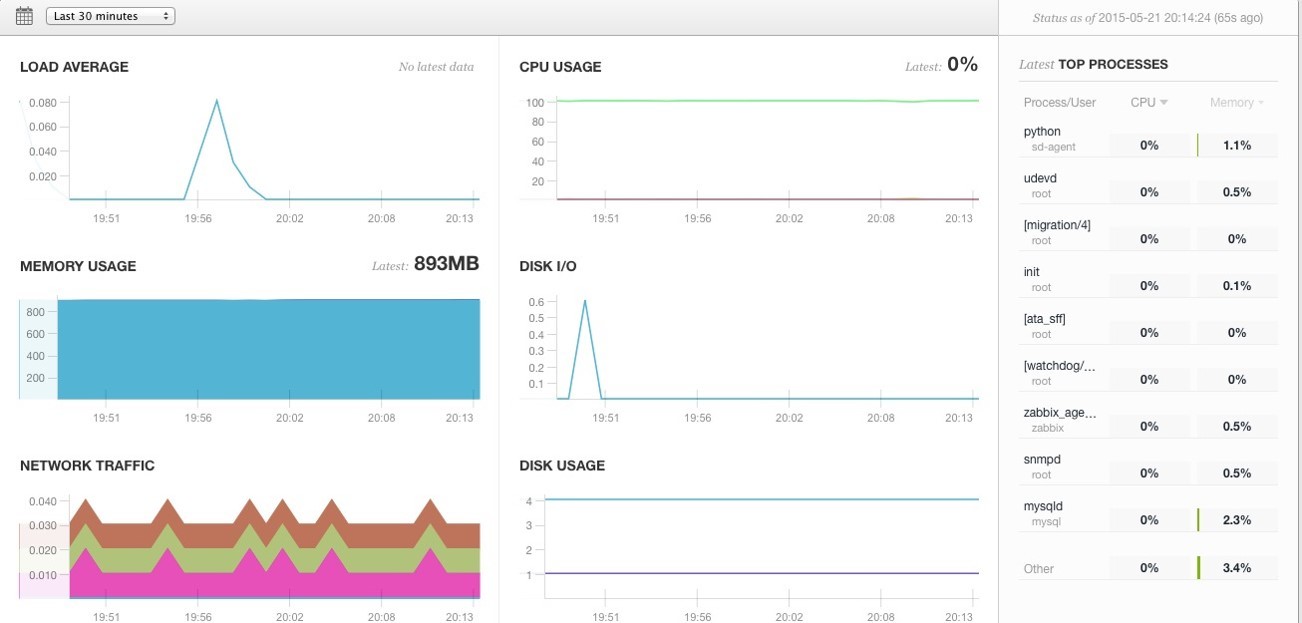
У нас есть наш сервер, добавленный в SaaS-сервис, и Python-демон, запущенный на нашем сервере. От нас теперь требуется только настройка этого Python-демона: например, добавить данные для Nginx-статуса и данные доступа для MySQL. После перезагрузки, в настройках Server Density надо активироват отображение графиков для MySQL и Nginx.

При использовании SaaS-мониторинга можно отслеживать многие параметры. Например, URL нашего интернет-магазина. При этом будет мониториться код ответа на запрос, время ответа и т.д. Можно создать необходимые нам уведомления по любому параметру.
Большинство сервисов SaaS-мониторинга построены следующим образом: есть некий web-интерфейс, через который мы добавляем сервер, устанавливаем агент на свой сервер — и всё. Больше от нас никаких сложных действий по настройке мониторинга не требуется. Только в понятном web-интерфейсе настраиваем уведомления по нужным нам параметрам.
Какой инструмент выбрать?
Основные факторы, влияющие на ваш выбор: количество узлов, которые необходимо мониторить и задачи, которые планируется решать. Например, для маленького стартапа с одним сервером идеальным вариантом будет Server Density. Для организации с распределённой сетевой инфраструктурой и большим количеством серверов в разных городах наилучшим решением будет Zabbix. Для небольшого офиса, где необходимо мониторить какие-то базовые показатели серверов, великолепно подойдет Cacti.
