Мониторинг черных ящиков и котов в мешке через eBPF
Привет! Меня зовут Петр Бобров, в QIWI я отвечаю за отказоустойчивость, расскажу немного историй про сторонних вендоров, у всех они разные. У нас есть карточный процессинг, потому что мы банк, у нас банковская лицензия, проводим много платежей. Еще можно черными ящиками считать и базы данных: кто знает, как там работает Oracle, кто знает, как работает Linux внутри? Думаю, очень немного людей разбирается в этом, как оно работает на низком уровне.
Мониторить такие вещи достаточно проблематично, особенно, если нужно соответствовать стандарту PCI/DSS, который запрещает выкладывать логи приложений в общий доступ, потому что там потенциально хранятся определенные карточные данные в открытом виде, а в софте отсутствуют какие-то вменяемые интерфейсы, которые тебе могут посылать данные в твои системы мониторинга. В общем, проблем достаточно много, даже бывает такое, что говорили: «Не лезьте со своими SQL-запросами в нашу базу, вы портите нам производительность». Ситуация удручающая, так что мы захотели как-то это поправить.
Сейчас я покажу пример самописного мониторинга, который я сам мог сделать своим ограниченным интеллектуальным ресурсом. В этом примере мне хочется сфокусироваться на (не)сложности его реализации, а не на содержательном компоненте постановки задачи, хотя мне он тоже был довольно интересен.
История у меня про карточный процессинг. У нас несколько ЦОДов, и база данных под карточным процессингом работает в режиме синхронного коммита, чтобы не потерять данные в случае сбоев. Это значит, что транзакция должна записаться на удаленную площадку, прежде чем она вернет управление обратно в процессинг. Конечно, это не самая идеальная архитектура, потому что за подобное приходится расплачиваться: в случае сетевых задержек у нас появляются простои и тормоза. Это очень неприятно, хотелось бы такие вещи предотвращать оперативно.
Как вообще в нашем карточном процессинге работает синхронный коммит?
Транзакция приходит в базу, записывается в transaction log, который для надежности у нас записывается на три дисковые полки разных вендоров. Затем он передается по сети в другой ЦОД, процесс там его принимает и записывает на три дисковые полки, и уже потом записывается в резервную базу другим процессом.
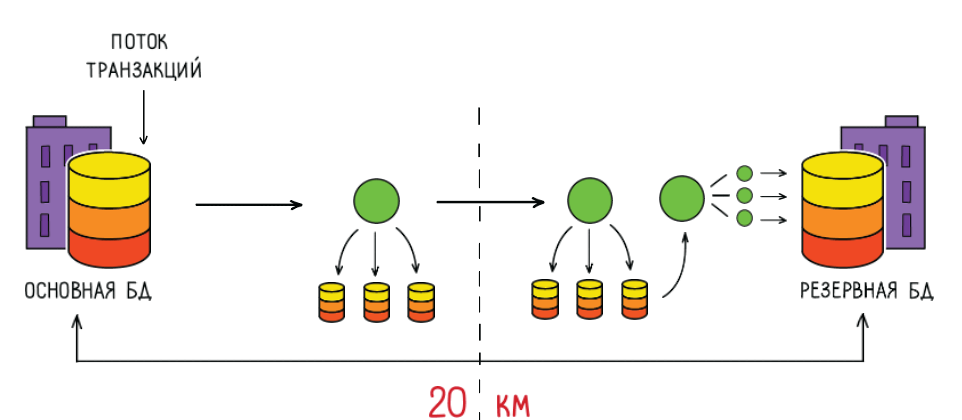
Получается такая большая цепочка, в которой бывают задержки, приводящие к неприятностям и негативному пользовательскому опыту.
Представьте ситуацию: я — дежурный, и у меня происходит сбой в системе. Что мне надо сделать, когда у меня где-то что-то затормозило?
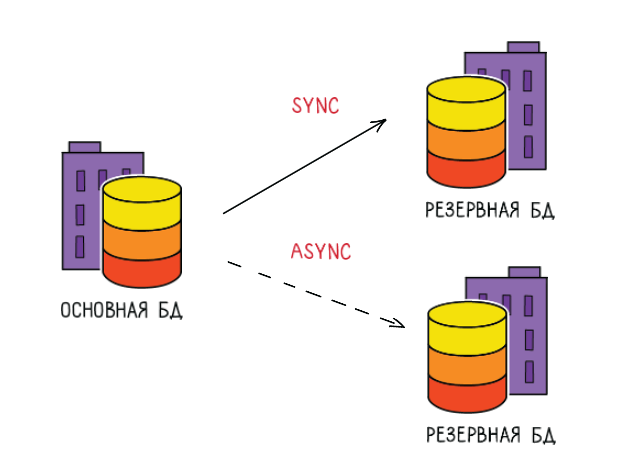
Я могу свой синхронный коммит временно выключить, чтобы потом разобраться и включить его обратно.
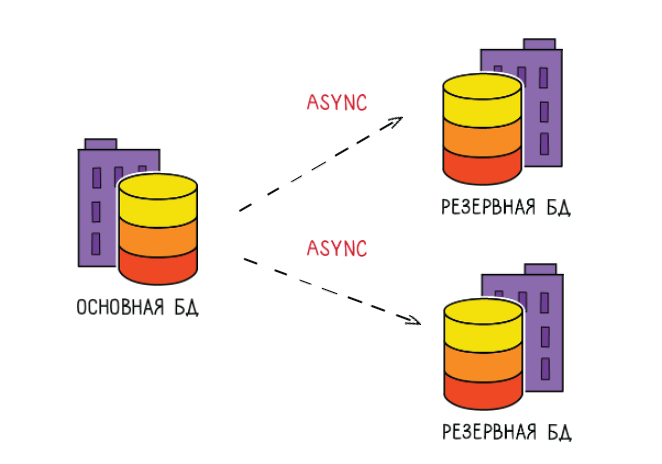
Если там не получается разобраться, могу его взять и переключить во второй дата-центр, а из этого потом догонятся данные, все будет нормально.
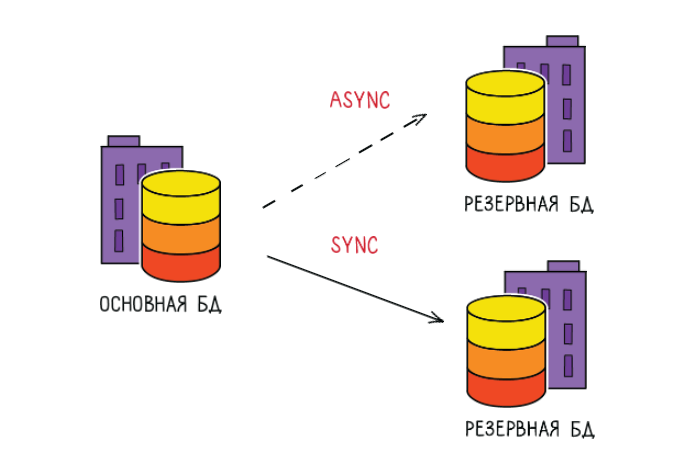
Если совсем все плохо, я могу поменять ролями базу с резервной, у меня будет все то же самое, с небольшим, может быть, простоем, решаю свою проблему таким образом.
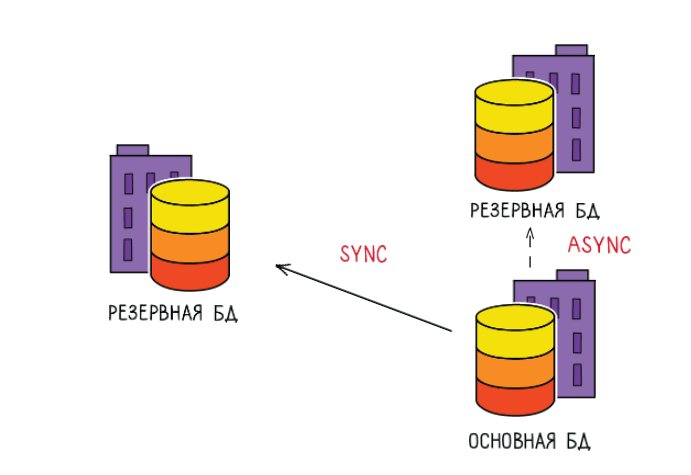
От чего вообще вся эта история зависит, когда я принимаю решение как дежурный?
У меня есть некие дисковые задержки на моем критическом пути, есть задержки сетевые между дата-центрами, а еще дисковые задержки во втором дата-центре. Всё это суммарное время влияет на время транзакции, на время коммита и на пользовательский опыт — как человек получает подтверждение своего платежа. Конечно, это грустно, потому что когда я начинаю заниматься мониторингом всего этого добра, то получается, что нормальных средств (которые мне могли бы показать какие-то цифры, на которых я мог бы основываться) не очень много.
Стандартные штуки в Linux мне показывают лишь усредненные цифры.

А мне хотелось бы немного по-другому, потому что если у меня 10 000 задержек по миллисекунде, и где-то наведено по дороге десять по секунде, то среднее получается все равно примерно две миллисекунды, и ты думаешь, что же на самом деле было.

Их десять по секунде — это случайно или это что-то системное? Я хочу знать, сколько занимала каждая задержка, которая у меня есть в системе.
Как же узнать задержки по всей инфраструктуре?
Так получилось, что я нашел eBPF.
Если совсем коротко — это такая подсистема в ядре Linux, которая вызывает ваш пользовательский код защищенным способом с небольшими ограничениями.
Допустим, как раньше писали модули для ядра? Они там что-то делают, пользовательский процесс общается с ядром через узенькое окошечко, через какие-то API, и разобраться в этом сложно. Лично мне самому, например, написать что-то такое вообще нереально. C eBPF же получается, что между пользовательским процессом и ядром появляется большая стеклянная стена, с одной стороны пользовательский процесс пишет какую-то программу, ядро ее выполняет, результаты прозрачны для обоих процессов: и для ядра, и для пользовательского процесса. Очень удобно, просто, этим реально можно пользоваться.
Лирическое отступление — eBPF закоммитил в ядро один мой сокурсник, Алексей Старовойтов, в 2014 году. Я сомневаюсь, что это можно считать отечественной разработкой, он давно уехал в Штаты, под импортозамещение не очень сгодится. Но, по крайней мере, это очень занятно. Великий человек, горжусь.
Так вот, если пытаться детальнее объяснить, что такое eBPF — это виртуальная машина в ядре, которая выполняет специальный код, который пишут на специальном языке C, достаточно сложно это все устроено.

Лично для себя я эти eBPF-программы объясняю так: я привык работать с базами данных, я знаю, что такое триггер, вот eBPF-программа, как триггер, срабатывает на какое-то событие в Linux в ядре, на какое-то пользовательское событие.

Поскольку оно происходит на уровне ядра, у него есть очень небольшой overhead, то есть я могу организовать сквозную трассировку для своего приложения, не вызывая каких-то огромных дополнительных задержек. Попробуйте условный процессинг запустить в режиме трассировки просто так. Он начнет писать кучу логов и будет работать вдвое медленнее. Потом обратно этот debug выключают и так далее.
Получается, что это такая история, которую я могу включить, и она может работать всегда, не вызывая каких-то больших помех для этого всего. И эта прозрачная стена между ядром и пользовательским процессом, где вы можете из процесса посмотреть, что же сделало ядро. Это тоже очень удобно, потому что мы можем это применить фактически к подавляющему большинству каких-то legacy-приложений, написанных на C.
К чему можно прикрутить свою eBPF-программу с пользой для дела
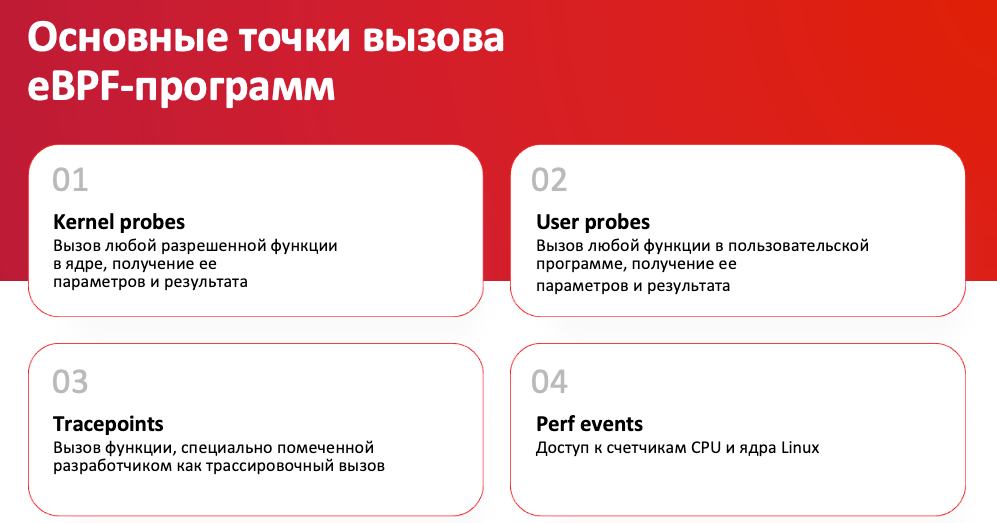
Есть специальные функции ядра, не все, но их достаточно много, которые в терминах Linux называются Kernel probes. К ним вы можете прицепить свою eBPF-программу, и она будет делать нужные вам вещи. Подавляющее большинство функций в ядре разрешено к использованию. Возможно, ряд вещей делать будет нельзя в плане безопасности, это все достаточно жестко контролируется разработчиками eBPF и проверяется специальным верификатором, который выполняет эту eBPF-программу и проверяет ее на валидность. Ведь если писать какой-то код, который будет выполняться в ядре, сдуру можно и ядро сломать, как говорится, поэтому лучше не пускать в ядро то, что мы не хотим.
В пользовательские функции можно прицепляться практически ко всем, по опыту могут быть нюансы.
Tracepoints — специально объявленные точки, к которым может прицепляться eBPF-программа. Например, если вы исходники Postgres скомпилируете с флагом DTrace, у вас появятся некие tracepoints, которые вы сможете именно таким способом, прицепляя к ним eBPF-программу, мониторить. По умолчанию этого нет, надо специально компилировать, по крайней мере, это можно посмотреть в исходниках. Если кто-то пишет на C и хочет встроить удобные tracepoints в свою программу, можно взять исходники Postgres, посмотреть, там, по-моему, шесть tracepoints: на старт транзакции, на конец транзакции, на старт запроса, на конец запроса. Появляется такой интерфейс, который вы можете использовать вне базы данных, это здорово.
И ещё кое-что, о чем бы я хотел упомянуть в рамках этого поста, это performance events в ядре, счетчики кэша, число инструкций в секунду и прочие технические вещи, которые могут пригодиться в профилировании.
Работает это примерно так.

Если сделать дебаггером дамп по адресу функции, который прицеплен к eBPF, вы увидите там int3. int3 — это стандартные прерывания, которые используются дебаггером, если вы будете вручную ставить breakpoint с помощью gdb, в этот момент у вас тоже появится int3. То есть, в eBPF используются стандартные инструменты Linux, они уже давно работают и проверены, это здорово.
А теперь о рисках

Если в eBPF есть какая-то уязвимость, она обычно сразу раскрывает все ядро, как это ни печально. Возможно, идея-то была здравая, чтобы пользователи писали сами код в пользовательском процессе. К сожалению, нет, приходится этот код изолировать под root. Дальше давать уже доступы к нему. Ничего не поделаешь, такова жизнь. У нас слишком много развелось хакеров, которые могут это адекватно эксплуатировать. На eBPF пишут очень много rootkit«ов. Риски очень серьезные, если вы это разрешите каким-то непривилегированным процессам выполнять eBPF программы, не надо этого делать.
Регулярно возникают проблемы с совместимостью, когда вы апгрейдите Linux с одной версии на другую, а код eBPF остается старым, какие-то библиотеки приходится доставлять, а старый код может перестать работать. Эта проблема решается в современных дистрибутивах, но не весь legacy-код работает на современных дистрибутивах. Так или иначе, с этой проблемой приходится сталкиваться.
Бывают и баги. И скомпилировать eBPF из исходников достаточно сложно, я бы сказал. Надо в этом хорошо разбираться, если затеваете что-то серьезное и чувствительное.
У меня появилась идея решить мою задачу по мониторингу в синхронном коммите из одного дата-центра в другой через eBPF.

Я не люблю кодить, иначе я был бы разработчикам, так что я для экономии времени пользовался StackOverflow.
Мой проект устроен примерно так: мне надо найти подходящие точки мониторинга, те самые функции, к которым я могу прицепить свою eBPF-программу, потом найти какой-то код, который будет делать то, что мне надо, проверить, и дальше шаг интеграции с какими-то корпоративными системами, которые у нас используются в мониторинге — Prometheus, Grafana и так далее.

Останавливаясь на этом плане, я бы сказал, что поиск подходящей точки для мониторинга будет самой сложной задачей. Мой пример достаточно простой, если так подумать. Стороннее приложение может быть устроено неведомым способом, вы можете сами не разобраться в том, как там что найти. Можно договориться с вендором «по-хорошему», с ним нужно договориться, сказать: «Дайте нам, пожалуйста, хотя бы названия функций, которые мы можем отслеживать. Мы не хотим лезть в ваш код, просто скажите названия. Мы тут поставим старт, стоп, замерим время и будем мониторить».
Я думаю, что большинство адекватных вендоров должно нормально к этому подойти, а самые адекватные вендоры, конечно, уже добавили tracepoint«ы в свой код, и на этом уровне помогут вам. Если общего языка найти не удалось — я, конечно, ни в коем случае не буду призывать вас нарушать законы, но, полагаю, на рынке есть позитивно относящиеся к разного рода исследованиям чужого кода люди, и можно будет с ними как-то договориться.
Так вот, про мою задачу. У меня есть запись на диск и запись по сети, и мне надо замерить это время. Я хочу это время измерять:
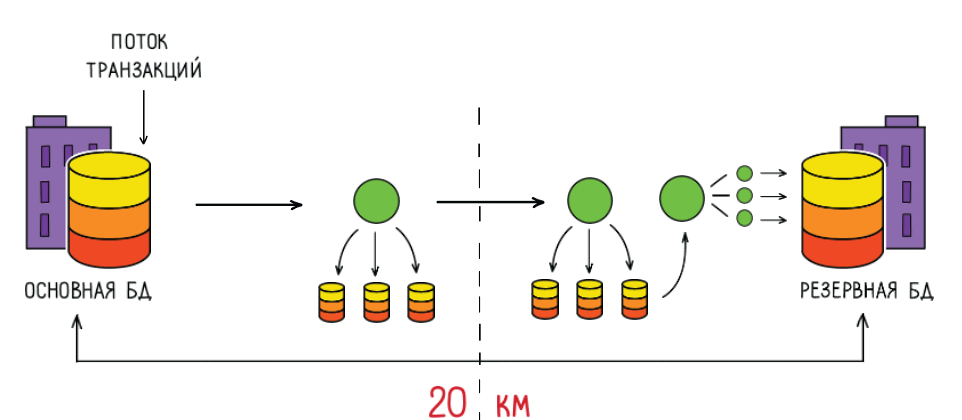
запись на все мои дисковые полочки в одном дата-центре,
время передачи пакета туда-обратно,
запись на диск в другом дата-центре.
По крайней мере, я уже знаю, что я хочу, это уже здорово.
Дальше мне надо найти те самые функции, которые мне нужны. Я рекомендую начать с коллекции готовых программ, которая называется BCC, в ней обычно очень много всего можно найти. Я нашел то, что мне нужно на первой странице.

Там первый пример, вот вам гистограмма по задержкам дисковых операций. Я посмотрел, подумал, что это то, что мне нужно. Да, она выводится текстовым образом на консоль, но это уже хорошее начало. У меня двоичная гистограмма, я вижу распределение длительностей задержек на каком-то промежутке времени.
Кстати, немного о том, как вообще устроена eBPF-программа, которая написана на Python.

Программа на языке C записывается в текстовую переменную Python. Может, звучит странно, но я генерил много разного SQL-кода, для меня это не в новинку.
Определяются структуры в памяти, сами функции, которые будут заполнять эти структуры и работать в своем ядре. Это как раз те функции на специальном языке C, которые будут выполняться непосредственно в ядре на каждый вызов той процедуры, к который вы этот код прицепите.

Определение тех областей памяти, которые будут возвращаться обратно, читать ваш процесс — это тоже важно. Они довольно просто в этой коллекции организованы, это такие хелперы-функции, просто объявляешь и говоришь: «Вот это будет гистограмма». Отлично, это будет гистограмма.

И в конце концов программа загружается в память, компилируется. Если компиляция успешная с первого раза — или вам повезло, или вы опытный разработчик. Дальше мы эту программу прикрепляем к каким-то функциям.

В этом примере указаны те функции ядра, при вызове которых будет каждый раз срабатывать та eBPF-программа, которая у меня в памяти. Если вы заметили, у меня тут много if, в разных версиях они могут называться по-разному, то есть вопросы совместимости наболевшие. В разных версиях, в разных дистрибутивах даже функции ядра могут отличаться по названию, о чем тут говорить.
В итоге программа считывает результат из памяти ядра и выводит его в консоль.

Вот эта гистограмма, я ее нашел, это замечательно, это то, что мне нужно.

Дальше мне нужно что-то с ней сделать такое, чтобы я мог каким-то образом совместить ее с моими корпоративными утилитами.
Интегрируемся с корпоративными утилитами
Мы используем на хостах сервис под названием telegraf, который просто собирает данные, а потом их пишет. То есть мы используем push-подход, а не pull. Есть разные экспортеры, которые занимаются pull«ом, мы делаем не так, мы делаем push. Там есть специальный формат строки, в который просто надо послать http, и в принципе достаточно. Все, что мне надо было сделать — каким-то образом написать что-то на Python так, чтобы данные пошли в мою систему.
Конечно, я воспользовался StackOverflow и потратил много времени. Уверяю вас, что специалисты потратят на это не больше получаса. Очень здорово, что это можно сделать самому и быстро. По приколу я это выложил в open source, мне коллеги поставили две звездочки, круто, спасибо, ребята.
Дальше для интеграции мне надо было все это разложить на сервера, я написал модуль для Puppet, мне его проверили, поставили мне плюсики, и я смог запушить код на все мои сервера, которые мне нужны. Они начали собирать мне красивые цифры в VictoriaMetrics. Затем мне надо было построить графики. Самый подходящий график для моих задержек дисков и сети называется HeatMap.

Он достаточно просто устроен: логарифмическая шкала, чем ярче цвет, тем больше было таких событий, она идет по времени. Получается, что на этой картинке подавляющее большинство событий продолжалось миллисекунду или меньше, но в какой-то момент времени этот график поднимается аж до двух секунд, то есть было некоторое количество событий, которые были по две секунды, например.
Именно на этом графике я могу посмотреть — это вообще единичное событие какое-то или это постоянно продолжающаяся история? Например, у меня три дисковые полки, и теперь я могу, не залезая в каждую, посмотреть, в какой конкретно из них проблема. Иначе мне надо было бы собрать команду, которая занимается инфраструктурой, сказать, чтобы одни копали в одну сторону, другие — в другую, а третьи — в третью. Это занимает очень много времени. Теперь я могу сделать это сам, глядя на несколько картинок.
В Grafana я сделал эти красивые графики и получил такой забавный общий дашборд.
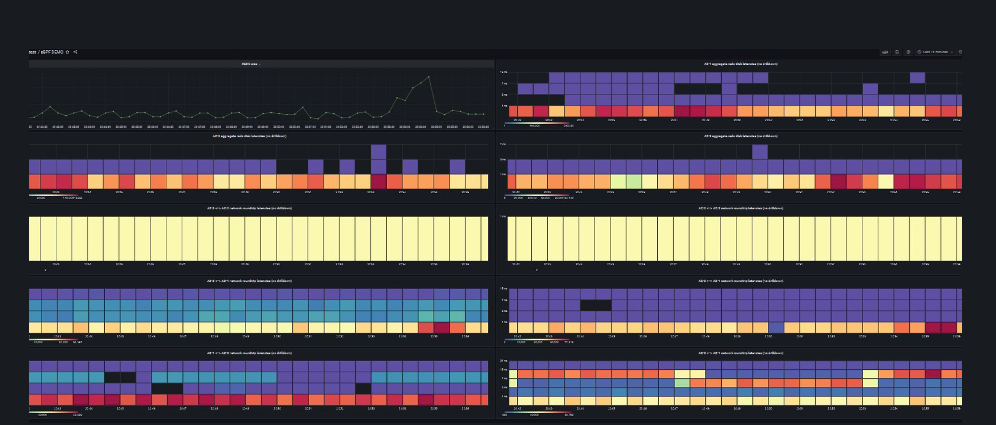
На нем у меня в одном углу объем работы, которая происходит, то есть объем данных, которые система пересылает между ЦОД. Потом у меня три картинки идут, которые показывают здоровье моих дисковых полок в каждом дата-центре. А дальше — графики, связанные с временем сетевого отклика, с response time сети. В правом нижнем углу, если посмотреть, примерно так выглядит картинка, когда что-то работает не так. Как раз красным цветом не одна миллисекунда, а где-то повыше, на логарифмическом уровне порядка семи, то есть время отклика в данном месте выросло в семь раз. Здесь, наверное, что-то пошло не так.
Теперь, если я знаю, в каком датацентре у меня что-то случилось, я могу принять соответствующее решение, переключить мне базу между датацентрами или выключить синхронный коммит.
В общем, вот такая у меня история про мониторинг с помощью eBPF, мне было на самом деле очень интересно этим заниматься, я крайне доволен результатом. Главное, что это было совсем не так сложно, как казалось с первого взгляда.
Возможно, эта история пригодится и вам для мониторинга разных приложений, как сторонних, так и своих.
Что бы я хотел еще сделать для исследования применимости eBPF для мониторинга черных ящиков? Обновить Linux на актуальные версии, с новым ядром и новыми возможностями, в первую очередь для того, чтобы использовать библиотеку libbpf и компиляцию CO-RE (compile once — run everywhere). Это даст возможность запускать eBPF-программы на хостах с разными версиями ядра и без компилятора (это требование безопасности). А ещё это должно позволить моим eBPF-программам куда более стабильно отрабатывать при прикреплении к uprobe, чем в моих экспериментах.
В конце хочется обратиться к вендорам — пожалуйста, делайте в вашем коде трейспойнты! Будем крайне признательны!
