Мой краш-тест чемпионата: Победа в Data Science треке
Привет! Меня зовут Елизавета Полковникова. С воодушевлением делюсь с вами, уважаемые читатели, ценным опытом завоевания первого места в чемпионате «CUP IT 2023» от Changellenge. В основе этого соревнования лежит уникальный кейс-подход: компании предлагают участникам решать реальные боевые задачи, с которыми сталкиваются их сотрудники. Мне посчастливилось разгадать кейсы компаний VK и Альфа-Банк.
Эти соревнования отлично развивают системное мышление, способность принимать решения в ограниченные сроки, а также погружают в науку о данных и IT-сферу с точки зрения продукта. Кстати, об этом и своем пути я рассказываю в телеграм-канале Мышление роста с Лизой
Сначала расскажу про вводные и инсайты, а во второй половине очерки самих задач и решения.
Вводные данные
Организаторы кейс-чемпионата — Changellenge, при поддержке партнеров (VK, Альфа-банк, МТС, QIWI, Газпромбанк, СБЕР и др.) — предоставили участникам возможность выбора из двух треков: Data Science и Продуктовый трек с уклоном в IT. Мой выбор пал на первый трек, Data Science.
В хакатоне было два тура и два кейса. Первый тур — VK, второй — Альфа-Банк. В первом туре приняли участие 500 команд (более 2 000 человек), во второй тур прошли лишь 10 команд. На решение каждого кейса участникам отводилась неделя. Организаторы предоставляли материалы для подготовки, включая учебник по решению бизнес-кейсов.
Основоположник кейс-метода
Основоположником кейс-метода является Христофор Колумб Лэнгделл, бывший декан школы права Гарвардского университета.
Учебник по решению кейсов — первая книга о решении бизнес-задач на русском языке.
Каждой команде назначался ментор (финалист предыдущего хакатона), но мы решили бороться за победу своими силами. После публикации презентаций компании проводили вебинары с разбором решений и обратной связью.
Моя команда — «Параллель 55»
Интересный факт: мы придумали название «Параллель 55», потому что все города, в которых живут участники команды, находятся на 55-ой земной параллели.
Инсайты, пронизывающие весь чемпионат:
Важно уделить внимание подбору сокомандников. Члены моей команды не были знакомы друг с другом ранее, но быстро нашли общий язык и определили, как декомпозировать задачу и распределить роли.
Креативный подход к неймингу команды и защите кейса. Помимо призовых мест, существуют номинации «Нестандартное решение» и «Самое яркое выступление».
Внимательно читать кейс и фиксировать важные сведения. 50% ответа уже в самом вопросе.
Начать решение сразу после получения задачи, не откладывая на последние дни. Лучше, чтобы у вас было время для доработки решения при необходимости.
Составить четкий план действий и распределить роли с учетом временных рамок. Если что-то непонятно, лучше уточнить, чем переделывать после решения. Мы создали план в виде mind-map в Miro и ориентировались на пошаговые задачи в Trello.
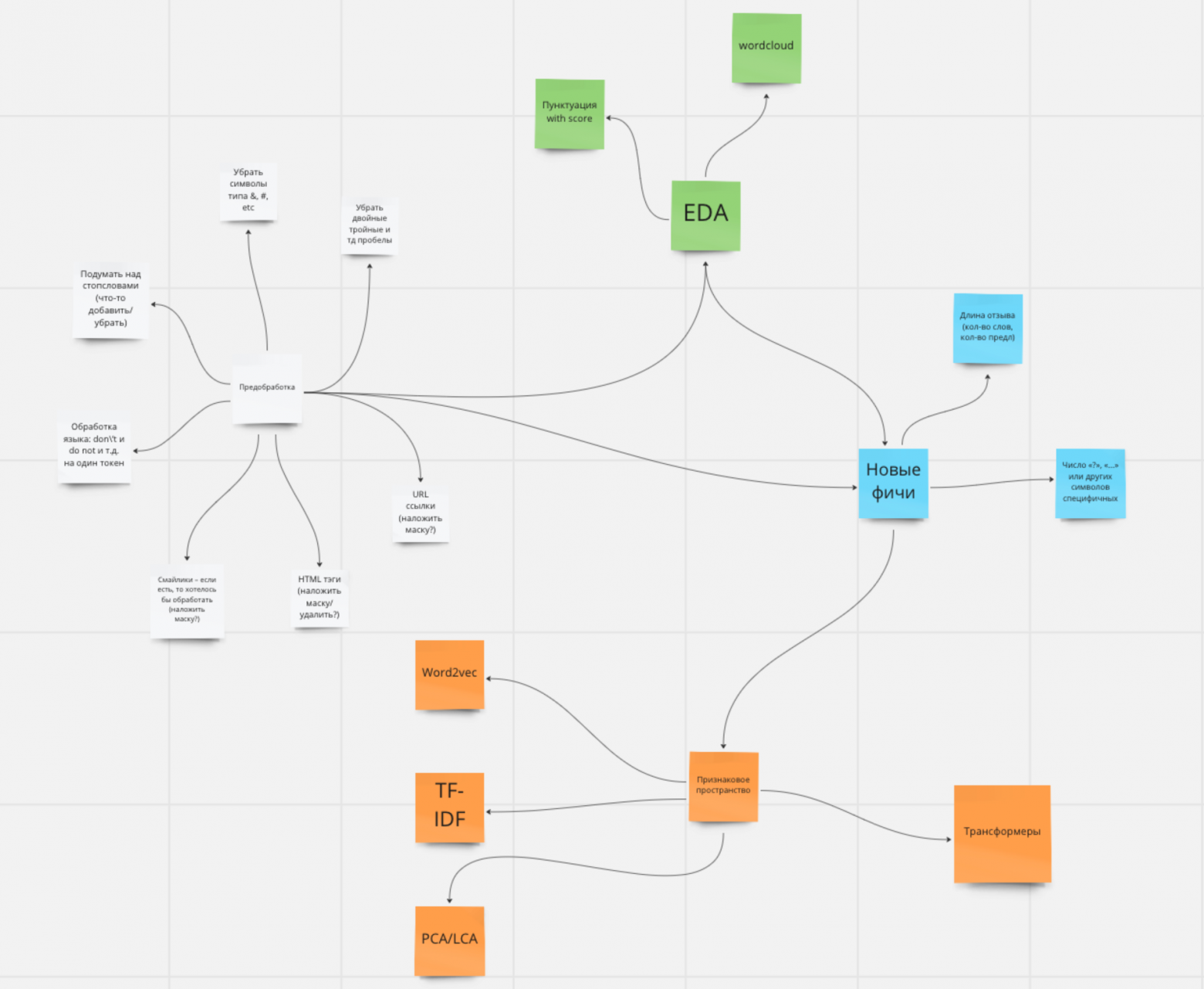
Пример первичной майнд-карты кейса ВК
Пример критериев второго тура
Оформлять презентацию с учетом брендинга и корпоративной культуры компании кейса.
Во втором туре заранее подготовить рассказ и отрепетировать по таймингу. На защиту каждой команде отводилось примерно по 10 мин. В первом туре защиты не было, просто отправляли презентацию.
Очерк 1 тура

Кейс VK
Задача в построении модели машинного обучения, способной качественно ранжировать пользовательские комментарии под постами в зависимости от их популярности и релевантности. И нагенерить методы взаимодействия с комментаторами, а также механизмы поддержки для разных групп пользователей, включая тех, чьи комментарии непопулярны.
Эмоциональный отклик и наши действия после получения кейса
Мы тщательно изучили информацию по кейсу (14 слайдов, представленных в игровой форме, что заслуживает плюса организаторам). После анализа провели созвон, разработали план действий и распределили задачи. Для меня это стало первым опытом в командном IT проекте, и первый день реализации плана оказался невероятно напряженным. Нам нужно было изучить обширную техническую документацию для реализации кода и использования инструментов. Большинство материалов о похожих реализациях, которые мы нашли, были на английском языке. Мы также получили датасеты в комплекте с кейсом: тренировочную и тестовую выборки.
На первом этапе нам требовалось только отправить презентацию с решением, так как онлайн-защиты не предусмотрены (и это вполне логично при участии 500 команд).
Финальная модель
BERT + CatBoostRanker
NDCG метрика на кросс-валидации = 0.89

Ключевые пункты решения:
Проведена предобработка датасетов с использованием техник NLP, созданы мета-признаки, влияющие на качество модели. Применена TF-IDF векторизация текста. Размерность признакового пространства уменьшена с использованием PCA.
Исследованы данные с помощью EDA. Выбран алгоритм, учитывающий критерии масштабируемости решения и минимизации экспертных корректировок результатов модели (также пробовали XGBoostRanker с Optuna, LambdaRankNN и др.).
Проанализировано влияние признаков на модель, созданы «портреты» популярного и непопулярного комментариев. Результаты визуализированы в виде облака слов.
На основе проделанной работы и современных трендов предложены VK методы взаимодействия с разными группами пользователей с точки зрения интерфейса и концепции.
Итог первого тура
Наше решение принесло нам место в десятке финалистов, занимая при этом восьмую строчку.
Очерк 2 тура

Кейс Альфа-банка
Задача: разработать интеллектуальный алгоритм поиска похожей аудитории клиентов — родственников текущих пользователей — для продукта «Семейный счет», составить персонализированную коммуникацию для сегментов ЦА и дорожную карту развития ML-проекта.
В кейсе была предложена достаточно большая выборка данных ~ 300 признаков и 620 000 наблюдений.
Финальная модель
Look-alike ансамбль: LGBM + XGB + CatBoost Classifiers
Gini = 0.747
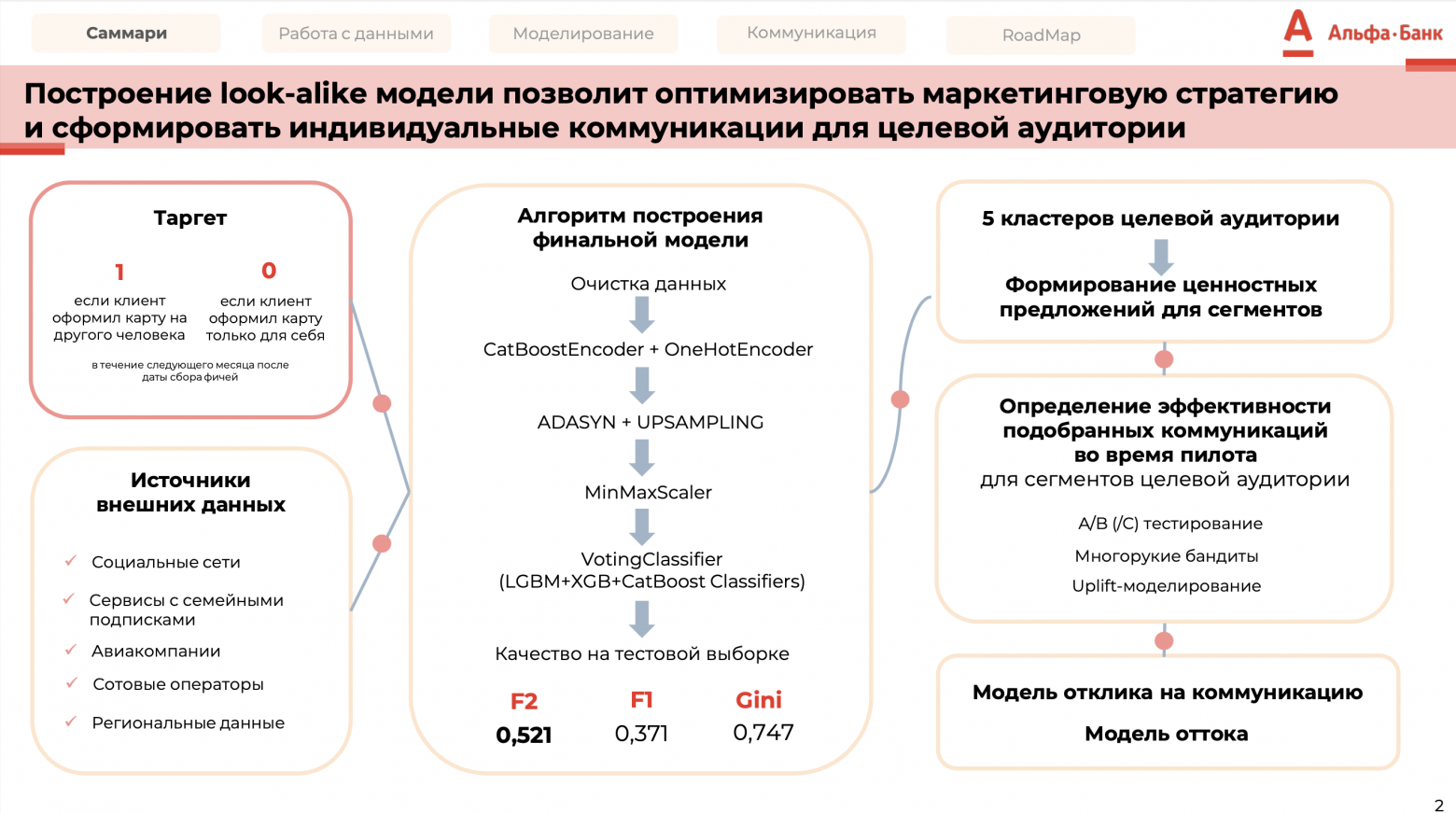
Ключевые пункты решения:
Провели предобработку данных (поиск некорректных значений, аномалий, кодирование категориальных переменных, заполнение пропусков и т.д.)
Собрали таргет (целевую переменную для дальнейшей работы модели)
В результате исследовательского анализа данных выявили дисбаланс целевой переменной, проанализировали распределения признаков, получили представление о портрете целевой аудитории.
Для эффективного обучения модели необходимо, чтобы данные были сбалансированы, поэтому к обучающей выборке мы применили комбинацию ADASYN + Upsampling, а также привели числа к единому масштабу (MinMaxScaler). К соотношению классов в обучающей выборке 1:1
Отобрали ключевые признаки для модели, основываясь на EDA, Shap, Catboost и на логическом мышлении, ведь человеческую логику никто не отменял, даже если работаем с умными инструментами (признаки, которые наиболее релевантны для продукта).
Метрики качества модели: Gini (наиболее подходящая под задачу), F2 (с фокусом на recall), F1, Precision, Recall, Accuracy.
Построили 13 моделей и выбрали ансамбль, показавший наиболее крутые результаты, поработали с гиперпараметрами с помощью Optuna и получили результат: LGBM + XGB + CatBoost Classifiers.
Завершающим этапом разработали персонализированную маркетинговую коммуникацию для сегментов аудитории, которые получили с помощью кластеризации KMeans. И составили road-map запуска и развития пилотного проекта (многорукие бандиты, uplift-моделирование, модели отклика и оттока и пр.)

Модели, которые пробовали
Итог второго тура
Выступили с презентацией перед судьями и с данным решением моя команда заняла первое место.
Конкуренты были достойными, и я очень горда была впоследствии увидеться с ними вживую, но наше решение стало победным. Считаю, что все в совокупности дало нам такой результат: умы и усердие сокомандников «Параллели 55», эффективная коммуникация, четкие распределения задач, поддержка капитана.
Основная ошибка у других команд: решили проблему дисбаланса классов на выборке, обучили на ней модель и делали предсказания на той же выборке — на сбалансированных данных и, конечно, показатели метрик были высокими. Правильным решением было обработать данные обучающей выборки, а тестовую не трогать, и на исходной тестовой предсказывать.
Награды и послевкусие победы

Кубок победителя Cup IT 2023 моей команды «Параллель 55»
Победителям Data Science и Продуктовой секций были вручены кубки и карьерные бонусы в виде пропуска всех этапов отбора, кроме финального (технического) собеседования с руководителями. Призеры и победители также получили мерчи и возможность посетить главные офисы компаний на экскурсиях.
Замечательно, что экскурсия в МТС стала не только возможностью увидеть офис департамента Big Data, но и поводом для знакомства членов команд, занявшие призовые места. Дружелюбная атмосфера и уникальные личности сделали этот опыт особенным.
Кстати говоря, экосистема МТС мне очень понравилась, и я поступила туда на стажировку дата-аналитиком. Победа на кейс-чемпионате сыграла важную роль в этом деле.

Лекция для победителей и призеров в московском офисе МТС
Вывод
С восьмого места в первом туре мы добрались до вершины! «Было сложно?», — спросите вы. «Еще как!», — отвечу я. Моя команда и я преодолели сложности, представленные сжатыми сроками и, казалось бы, неразрешимыми задачами.
Участие в кейс-чемпионатах приносит огромную пользу студентам и молодым выпускникам, начинающим свою карьеру. Это также отличный шанс для тех, кто стремится освоить новую профессию и получить опыт решения реальных задач. В итоге:
Я нашла единомышленников и поддержку людей, стремящихся к развитию.
Завела долгосрочные дружеские связи.
Выиграла возможность посетить офисы МТС и ВК, а также получила их мерч.
Прошла финальные интервью на стажировку, пропустив все предварительные этапы.
И, конечно же, добавила в свое портфолио проекты с IT-гигантами России.
Это был действительно ценный опыт. Надеюсь, вам тоже было интересно!
Присоединяйтесь к моему телеграм-каналу Мышление роста с Лизой, основная цель которого вдохновить людей идти вперед через призму анализа данных, стартапы и английский. Верю, любой человек может достичь абсолютно все, что пожелает. Главное — его мышление.
Это моя первая статья, буду признательна за поддержку (лайки, комменты :)) и фидбек. Спасибо за внимание!
