Мои маленькие реле: Тройной Brainfuck, или что такое безумие

Рис. 1: Релейный компьютер BrainfuckPC на фоне его автора
Продолжая славную традицию ежегодного дайджеста моих самых безумных компьютерных проектов, представляю вам третью и заключительную статью о проекте релейного компьютера BrainfuckPC.
В прошлых сериях:
После десяти лет мечтаний и раздумий, два с лишним года неспешной работы и сборки, могу с уверенностью сказать, что проект релейного компьютера состоялся. Несмотря на то, что компьютер бесполезен с практической точки зрения, к тому же еще и регулярно сбоит, он стал отправной точкой для следующих, не менее безумных кибер-проектов.
Подкатом звенящие релейные блоки, самые быстрые в мире вычисления на реле, монтаж накруткой, вакуумные индикаторы, и многое другое.
Язык программирования brainfuck
Язык программирования brainfuck — пожалуй, самый популярный в мире эзотерический язык программирования. А заодно самая настоящая Тьюринг-полная трясина. Всего лишь 8 инструкций, на которых можно написать все что угодно, но очень долго.
К примеру, у меня ушло три дня на то, чтобы написать и отладить программу деления 335/113, которая печатает в терминал 6 знаков после запятой.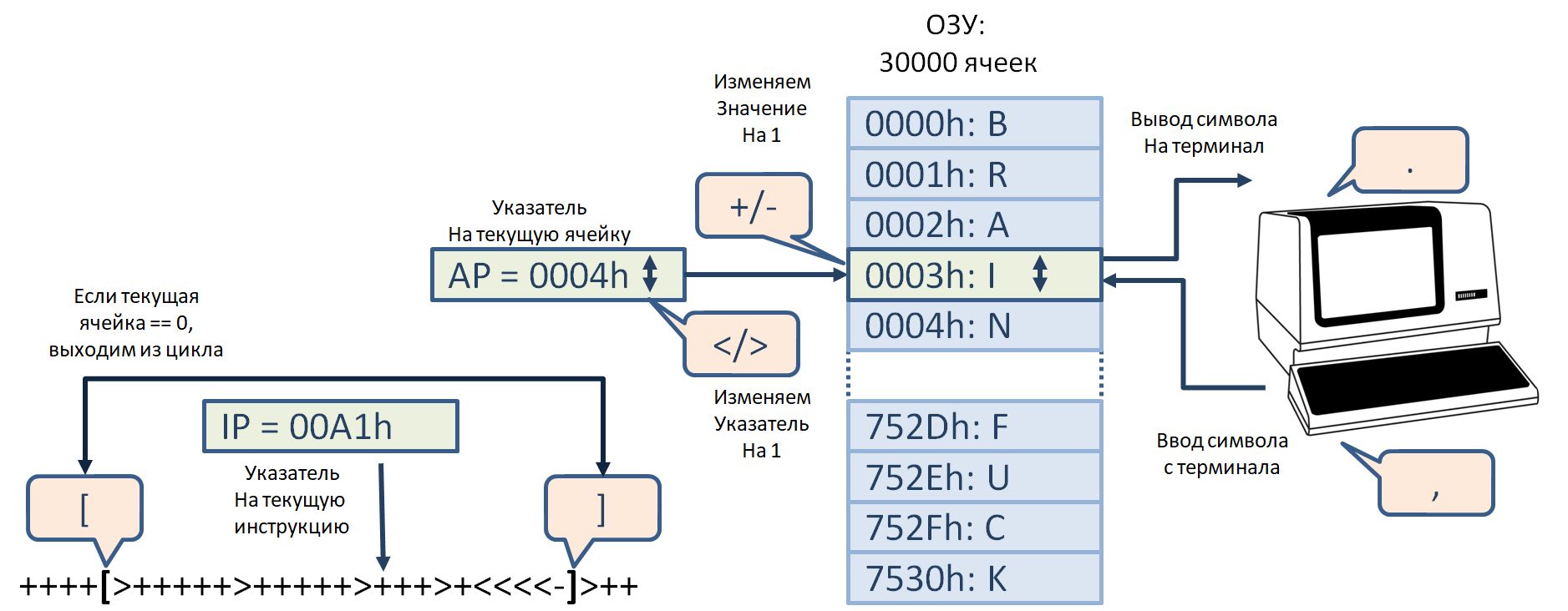
Рис. 2: Инструкции языка brainfuck
Весь синтаксис языка строится вокруг ОЗУ на 30 тысяч ячеек памяти, с разрядностью 8 бит.
- Двумя инструкциями + и - мы изменяем значение в текущей ячейке данных на единицу вверх или вниз.
- Двумя инструкциями < и > мы изменяем на единицу указатель на текущую ячейку данных, тем самым перемещаясь по памяти влево или вправо.
- Еще две инструкции [ и ] — позволяют нам организовать циклы. Все что внутри скобок является телом цикла. Вложенные циклы допускаются. Логика инструкции проста — если значение текущей ячейки данных не равно нулю — мы выполним одну итерацию цикла, если равно — то выходим из цикла.
- Последние две инструкции . и , — позволяют вывести значение текущей ячейки в консоль, или ввести его ОЗУ. Тем самым достигается интерактивность.
Да, этого более чем достаточно для написания любой программы. Существование компиляторов из языка C в brainfuck как бы намекает об этом. Но плотность кода — никакущая. Для выполнения простейших операций, например сложения значений двух ячеек памяти, требуется исполнить сотни инструкций brainfuck.
brainfuck++
Попробуем хоть немного, но повысить плотность кода. Изучая программы, написанные на этом языке, можно обратить внимание, что в большинстве своем они состоят из последовательностей одних и тех же инструкций + — < >. Это наводит многих на мысль свернуть последовательность таких инструкций в одну и получить небольшой прирост производительности, который от программы к программе может составлять как десятки процентов, так давать и многократный прирост скорости. Например, 10 операций инкремента мы заменяем на операцию +10. 20 операций сдвига указателя вправо на операцию >20 и так далее.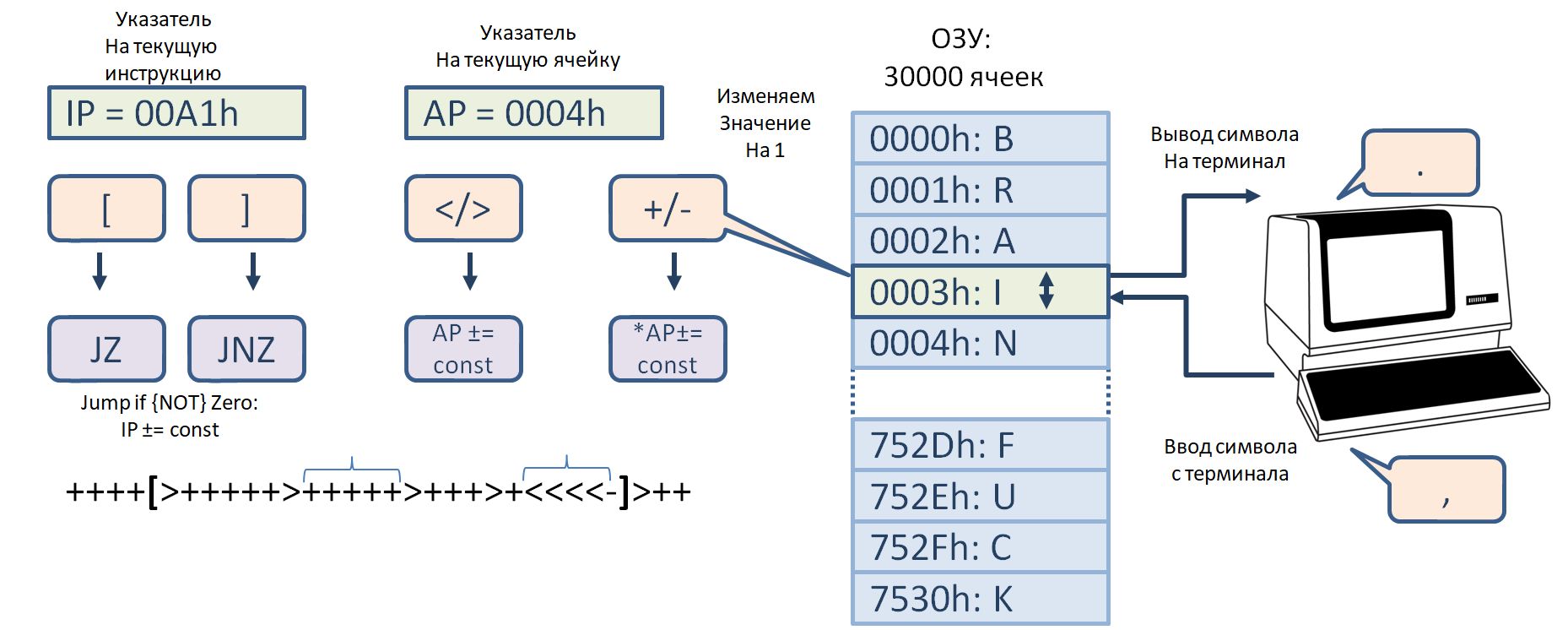
Рис. 3: Инструкции языка brainfuck++
От теории к практике
Как вы понимаете, нельзя просто так взять и написать на языке brainfuck операцию Rb = Ra+Rb, где Ra, и Rb — ячейки памяти. Все что мы можем — это изменять на константу содержимое некоторой ячейки и проверять не нуль ли она. В итоге, чтобы сложить два числа, все что нам остается, так это делать +1 для ячейки Rb и -1 для ячейки Ra, до тех пор, пока содержимое ячейки Ra не станет равным нулю. Напишем сие в виде кода на С:
*(mem+RbPos) += *mem
*/
void addMov(Memory &mem, uint16_t RbPos)
{
while (*mem)
{
mem += RbPos;
(*mem)++;
mem -= RbPos;
(*mem)--;
}
}
Как результат — в ячейке RbPos окажется старое значение плюс то, что было по исходному адресу. класс Memory — контейнер с 65к целочисленных ячеек. Главное его свойство — переполнение значения указателя вернет его в начало массива. Как в моем реальном железе.
Недостаток описанной функции — потеря исходного значения — оно обнулится. Добавим еще одну переменную Rc, чтобы сохранить его:
/*
*(mem+RcPos) = *mem
*(mem+RbPos) += *mem
*/
void addCpy(Memory &mem, uint16_t RbPos, uint16_t RcPos)
{
while (*mem)
{
mem += RbPos;
(*mem)++;
mem -= RbPos;
(*mem)--;
mem += RcPos;
(*mem)++;
mem -= RcPos;
}
}
В результате в ячейке srcNew будет лежать скопированное слагаемое. Ну, в том случае если раньше там был нуль.
Поскольку использованная мной нотация очень сильно напоминает brainfuck++ — просто перепишем нашу функцию в символах bfpp, приняв для примера RbPos за 4 и RcPos за 5: [
>>>>
+
<<<<
-
>>>>>
+
<<<<<
]
Описав все примитивы, можно начать комбинировать их в более сложные конструкции и получать программу необходимого функционала. В итоге, можно получить программу, которая делит 355 на 113 (или любые другие числа друг на друга в пределах 16 бит)
class Memory {
public:
Memory()
{
memset(m_mem, 0, sizeof(m_mem));
memPtr = 0;
}
Memory& operator += (uint16_t ptr)
{
memPtr += ptr;
return *this;
}
Memory& operator -= (uint16_t ptr)
{
memPtr -= ptr;
return *this;
}
uint16_t& operator [] (uint16_t ptr)
{
return this->m_mem[ptr];
}
Memory& operator = (uint16_t ptr)
{
memPtr = ptr;
return *this;
}
uint16_t & operator * ()
{
return m_mem[memPtr];
}
Memory& operator ++ ()
{
memPtr++;
return *this;
}
Memory& operator -- ()
{
memPtr--;
return *this;
}
private:
uint16_t memPtr;
uint16_t m_mem[65536];
};
void calcPi()
{
Memory mem;
*mem = 22;
mem += 1;
*mem = 7;
while (*mem)
{
mem += 1;
(*mem)++;
mem -= 1;
(*mem)--;
mem += 2;
(*mem)++;
mem -= 2;
}//correct -909
while (*mem)
{
(*mem)--;
}
mem -= 1;
while (*mem)
{
mem += 2;
while (*mem)
{
mem += 4;
(*mem)++;
mem -= 4;
(*mem)--;
}
mem += 4;
while (*mem)
{
(*mem)--;
mem -= 4;
(*mem)++;
mem -= 2;
(*mem)--;
if (!*mem)
{
//JZ out
goto out;
}
mem += 6;
}
mem -= 6;
out:
mem += 6;
if (*mem)
{
while (*mem)
{
mem -= 6;
(*mem)++;
mem += 6;
(*mem)--;
}
mem -= 6;
if (*mem)
goto out1;
}
mem -= 5;
(*mem)++;
mem -= 1;
}
out1:
mem += 10;
*mem += 0x50;//P
putc(*mem, stderr);
*mem += 0x19;//i
putc(*mem, stderr);
*mem -= 0x2C;//=
putc(*mem, stderr);
mem -= 9;
*mem += 0x30;
putc(*mem, stderr);
mem += 9;
*mem -= 0xf;
putc(*mem, stderr);
mem -= 10;
*mem += 6;
while (*mem)
{
(*mem)--;
mem += 1;//mem == 1
//nullCell(mem);
while (*mem)
{
(*mem)--;
}
mem += 1;
//mulConst(mem, 1, 10);
while (*mem)
{
(*mem)--;
mem -= 1;
(*mem) += 10;
mem += 1;
}
mem += 1;
//addCpy(mem, 1, 2);
while (*mem)
{
mem += 1;
(*mem)++;
mem -= 1;
(*mem)--;
mem += 2;
(*mem)++;
mem -= 2;
}
mem += 3;
//nullCell(mem);
while (*mem)
{
(*mem)--;
}
mem -= 5;
while (*mem)
{
mem += 4;
while (*mem)
{
mem += 6;
(*mem)++;
mem -= 6;
(*mem)--;
}
mem += 6;
while (*mem)
{
(*mem)--;
mem -= 6;
(*mem)++;
mem -= 4;
(*mem)--;
if (!*mem)//Да, грязный хак, доступный только для моего компьютера
{
goto out2;
}
mem += 10;
}
mem -= 10;
out2:
mem += 10;
if (*mem)
{
//addMov(mem, -(6+ 4));
while (*mem)
{
mem -= 10;
(*mem)++;
mem += 10;
(*mem)--;
}
mem -= 10;
if (*mem)
goto out3;
}
mem -= 5;
(*mem)++;
mem -= 5;
}
out3:
mem += 4;
while (*mem)
{
mem -= 3;
(*mem)++;
mem += 3;
(*mem)--;
}
mem += 1;//mem == 6
*mem += 0x30;
putc(*mem, stderr);
mem += 1;//mem == 7
while (*mem)
{
(*mem)--;
}
mem -= 3;
while (*mem)
{
mem -= 1;
(*mem)++;
mem += 1;
(*mem)--;
}
mem -= 4;// mem == 0
}
*mem += 0x0a;
putc(*mem, stderr);
*mem += 3;
putc(*mem, stderr);
}
Архитектура релейного компьютера
Центральным элементом релейного процессора является 16-разрядный полный сумматор с параллельным переносом. К нему на вход подключены два регистра. TMP — временный регистр, в который помещается старое значение, и CMD — командный регистр, в котором хранится инструкция и константа, на которую будет изменяться старое значение.
Посему я могу исполнять операции оптимизированного brainfuck++, а заодно получить полноценные условные переходы — Jump If Zero и Jump If Not Zero в любую сторону программы.
Результат операции суммирования может быть выгружен либо в один из контектных регистров — AP — с номером текущей ячейки данных, или IP — с номером текущей инструкции. Кроме того, результат может быть выгружен в текущую ячейку ОЗУ, если речь идет об инструкциях + и -
Рис. 4: Архитектура релейного компьютера в работе. Стадия загрузки новой инструкции сменяется стадией ее исполнения.
Первым делом, нам необходимо вычислить номер следующей инструкции — т.е. выполнить операцию IP++. Для этого, к старому значению IP-регистра прибавляется единица, результат записывается обратно в IP-регистр, и по этому новому адресу, в CMD-регистр, загружается очередная инструкция.
Вторым этапом начинается исполнение только что загруженной инструкции. Если она работает с сумматором, то процесс ее выполнения выглядит примерно так же как и процесс загрузки новой инструкции — старое значение во временный регистр, прибавляем лежающую в младших битах CMD-регистра константу, результат записываем обратно в регистр или текущую ячейку данных.
Таким образом, инструкция исполняется за один тик тактового генератора. По спадающему фронту загружаем очередную инструкцию, по нарастающему — исполняем ее.
Выполнили пустую инструкцию и… делаем IP++!
В итоге, нулевая ячейка памяти программы содержит нуль и никогда не будет исполнена. Певрвой загруженной из памяти инструкцией станет инструкция по адресу 0×0001.
Набор инструкций

Рис. 5: Набор инструкций релейного компьютера
Инструкции — 16-разрядные, где 4 старших бита отвечают за тип инструкции и 12 младших бит — полезная нагрузка. В большинстве случаев это константа.
- Инструкция NOP — игнорируется.
- Инструкция CTRLIO — особая инструкция, поведение которой кодируется битовой маской полезной нагрузки. В первую очередь она реализует команды записи в консоль и чтения из консоли (в синхронном или асинхронном режимах). Во-вторых, она позволяет выставить 16-разрядный или 8-разрядный режим работы машины. Ну и в-третьих, с помощью инструкции CTRLIO.HALT можно остановить работу машины. Самое смешное, что биты маски
неблокирующие. Можно выставить их хоть все сразу, но поведение машины будет неопределено. - Инструкция ADD — операция работы с ячейкой данных. Изменяет значение в ячейке на величину константы. При этом, бит.12 — знаковый бит и копируется в биты 13–15. Поэтому инструкция 0×2ffe превращается в операцию *AP += 0×0ffe, а инструкция 0×3ffe — в *AP += 0xfffe. Операция вычитания заменяется сложением с отрицательным числом.
- Инструкция ADA — реализует операцию AP+=const и позволяет перемещаться по памяти.
- Инструкции JZ и JNZ — условные. В зависимости от Z-флага позволяют либо совершить прыжок на несколько инструкций вперед или назад, либо остаться на месте. В зависимости от режима работы машины — 16 или 8 бит, состояние Z-флага определяется либо младшим байтом данных либо словом целиком.
Технические характеристики
BrainfuckPC — это 16-разрядный компьютер с процессором на базе герконовых реле, с архитектурой Фон-Неймана и набором инструкций Brainfuck++
- Общее число реле: 578 штук
- Общее число логических элементов: 157 штук
- Разрядность шины адреса: 16 бит
- Адресация: пословная
- ОЗУ: 128Кбайт (64 Кслов)
- Разрядность шины данных: 16 бит/8 бит
- Тактовая частота (текущая/максимальная): 25Гц/40Гц
- Потребляемая мощность: 70Вт
- Габаритные размеры: 110×650х140 мм
- Масса: 15 кг
Изначально предполагалось, что компьютер будет работать на частотах до 100Гц… А это — на минуточку — 4 пианинные октавы. К сожалению первые тесты показали, что 40Гц — это потолок, но и этого для релейной схемы безумно много. тем более что при внешнем тактировании необходимо подать два импульса на такт — из-за особенностей работы схемы синхронизации с внешним сигналом. 80Гц для музыки — уже что-то.
Состав компьютера
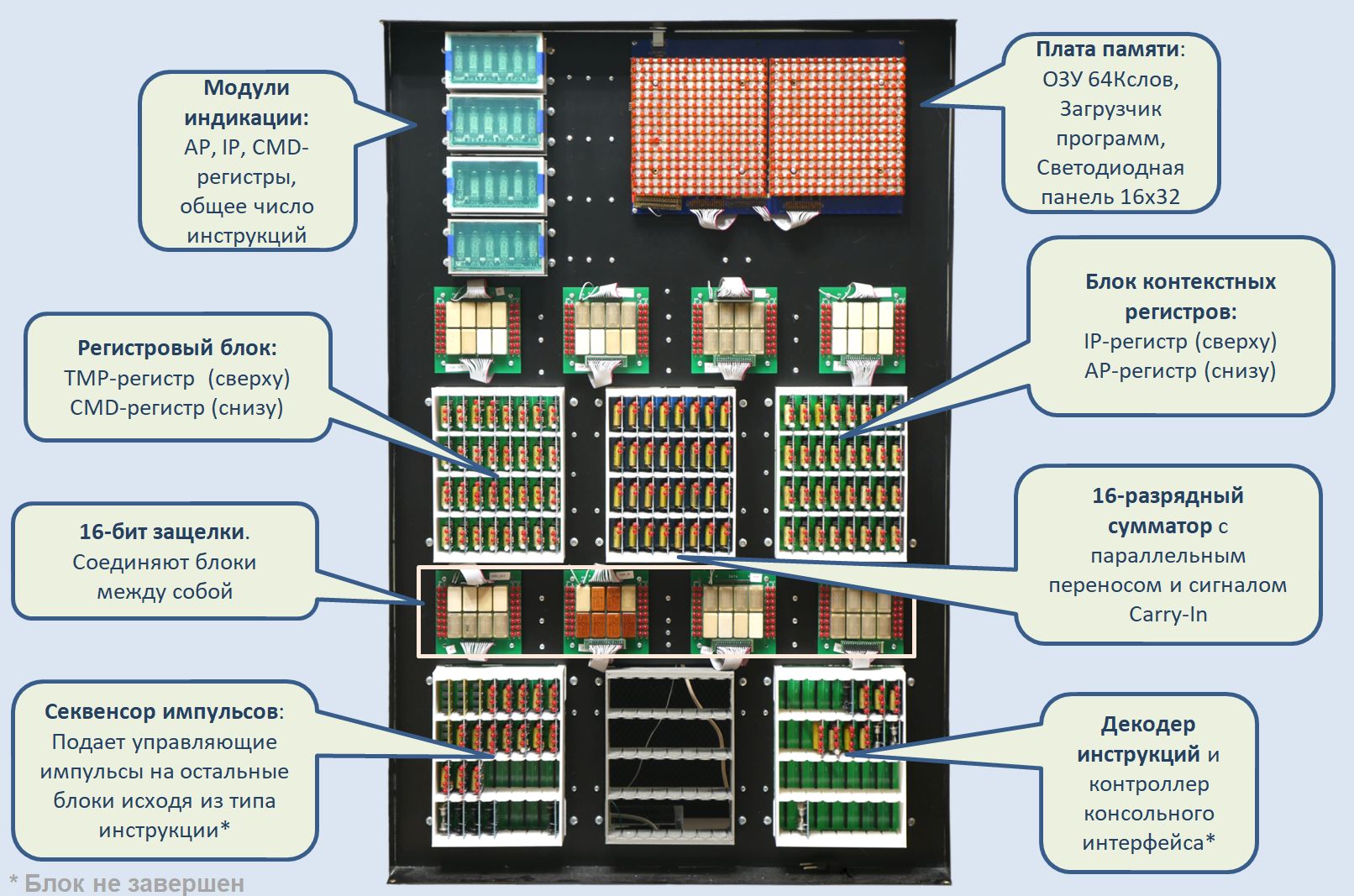
Рис. 6: Основные узлы релейного компьютера.
Рассмотрим компьютер поближе. Практически весь объем машины занимают блоки релейного процессора. В настоящий момент все уместилось в пять блоков, однако место есть для шести — так что если очень хочется, то впоследствии функционал процессора можно будет расширить.
Каждый такой блок содержит 32 модуля, в каждом модуле 3 или 4 герконовых реле РЭС55 и РЭС64. Питание каждого блока 5В, 3А.
Рис. 7: Комплект блоков и модулей релейного процессора, готовый к установе на раму.
Каждый модуль — унифицирован. 60×44 мм, разъем на 16 выводов. При сборке блоков логики я вставлял требуемый модуль в свободный разъем и прошивал соединения.
Рис. 8: Модули D-триггеров проверяются на работоспособность.
Центральный ряд — блоки сумматора и регистровые блоки. Над ними и под ними — 16-разрядные защелки на базе РЭС43, комутирующие поток данных между блоками. Все данные крутятся именно тут.
Нижний ряд — ряд блоков логики процессора. Сейчас частично заполнены два блока, но если очень захочется — то модификация и расширение функционала за счет свободного места более чем возможна.
Рис. 9: Рама собрана из листового 2 мм алюминия, из-под лазерной резки. На фото — уже сваренная и загрунтованная рама, готовая к покраске.
Верхняя часть — индикаторная. Слева — блок состояния машины — индикаторы на базе ИВ-6 отображают номер текущей ячейки памяти и ночер текущей инструкции, непосредственно саму исполняемую инструкцию, а также общий счетчик исполненных инструкций. Последнее очень кстати, ибо если эмулятор, например, говорит, что до первого символа в консоли надо выполнить 30 тысяч инструкций, счетчик наглядно покажет где машина сейчас и когда закончит считать.
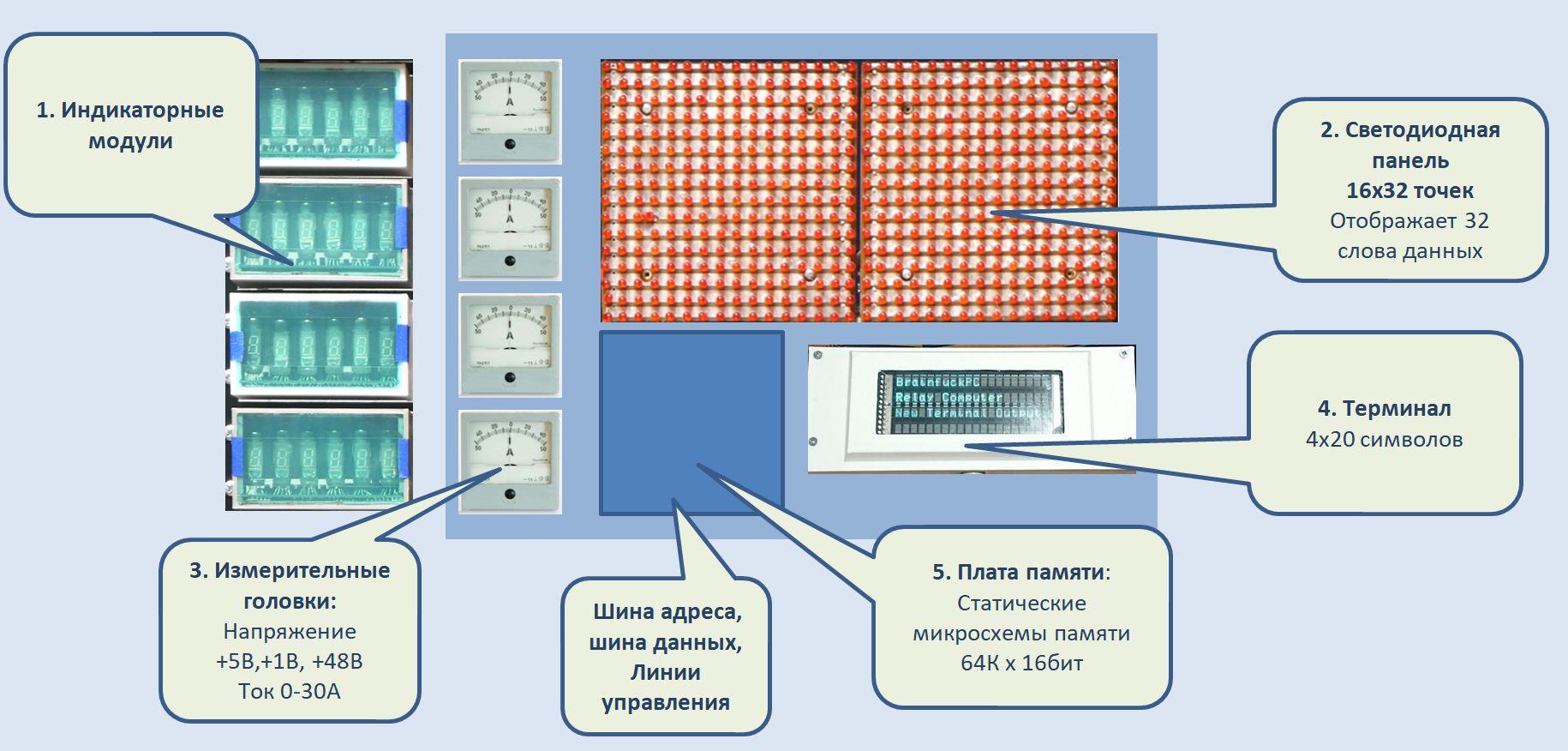
Рис. 10: Итоговый вид индикаторной области. В процессе изготовления.
Справа — располагается плата памяти — самый спорный элемент машины. Хоть я и считаю, что компьютер таки релейный, однозначно 100% релейным является именно процессор. Периферия более современная. В частности — ОЗУ — это статические микросхемы памяти. Но так делают практически все современные создатели релейных компьютеров.
Рис. 11: Программатор. 16 линий адреса, 16 линий данных, питание, земля и линии чтения записи. Итого 36 контактов.
Поскольку память программ и данных — общая, то кто-то или что-то, каждый раз при включеннии компьютера, должен загружать программу в ОЗУ. Эта задача и возложена на программатор. В настоящий момент программатор располагается на самой плате памяти. Сейчас у него ровно две задачи.
- Загрузить программу в ОЗУ, ибо каждый раз при включении питания делать это вручную с помощью тумблеров банально лень, хотя и такая возможность присутствует.
- Следить за состоянием некоторого региона памяти и отображать его на светодиодной матрице 32×16.
На работу процессора это никак не влияет, а видеть в реальном времени что происходит в ОЗУ — очень полезно при дебаге. Впоследствии, когда программатор будет внешним, светодиодную панель будет обслуживать один из индикаторных модулей. Адрес он уже знает, останется подать ему на вход данные.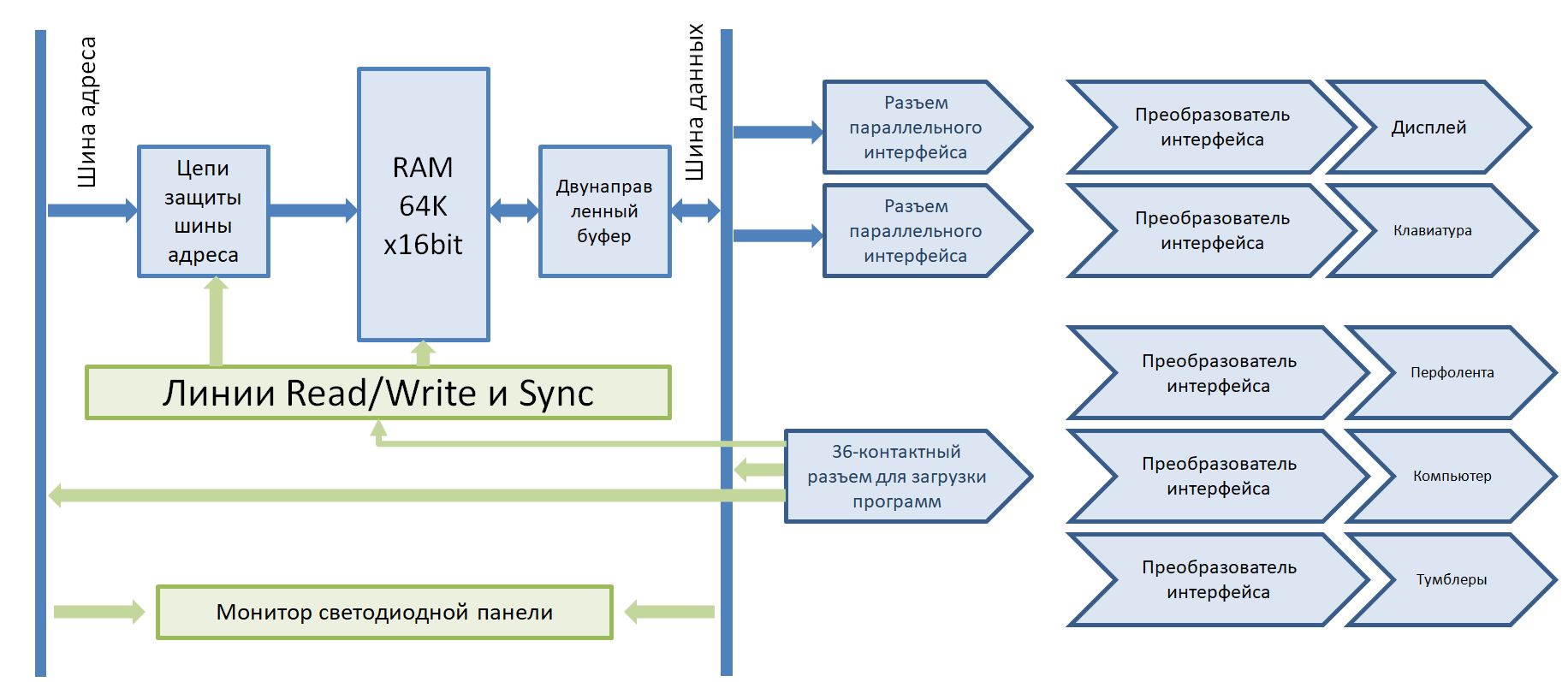
Рис. 12: Структурная схема периферии процессора.
Так в ближайшем будущем будет выглядеть схемотехника периферии процессора. На плате памяти останутся только сами микросхемы памяти и цепи согласования сигналов с релейной схемой. Через 36-контактный разъем программирования можно будет подключить программатор и загрузить прошивку в компьютер. Кроме программатора, имея необходимый преобразователь интерфейса, можно будет воспользоваться любым другим устройством. Хоть считывателем перфолент (у меня, кстати, имеется один, в комплекте с перфоратором перфолент и даже одной катушкой ленты), хоть панелью с тумблерами.
В итоге, релейная логика обеспечивает некий интерфейс, а преобразователь интерфейса может быть любым. К слову, параллельный разъем интерфейса будет совместим с LPT…
Демонстрация работы и текущий статус
В первую очередь, на компьютере была исполнена программа Hello World из статьи в википедии.
Исходный код выглядит следующим образом: ++++++++++[>+++++++>++++++++++>+++>+<<<<-]>++
.>+.+++++++..+++.>++.<<+++++++++++++++.>.+++.
------.--------.>+.>.
Благодаря светодиодной панели наглядно видно как изменяются данные:
Хотя и на частоте 25Гц сложно уследить за тем, что происходит в ОЗУ.
Более полезной и практической задачей является расчет знаков числа Pi после запятой. Понятно что современные компьютеры решили эту задачу вплоть до 31,4 трлн знаков. Но сам факт того, что BrainfuckPC способен выполнять эту операцию, говорит о том, что релейный компьютер бесполезен не на 100%, а всего лишь на 99.9.
В первую очередь я нашел уже готовый некий алгоритм расчета написанный на brainfuck.
> ++++ (4 digits)
[<+>>>>>>>>++++++++++<<<<<<<-]>+++++[<+++++++++>-]+>>>>>>+[<<+++[>>[-<]<[>]<-]>>
[>+>]<[<]>]>[[->>>>+<<<<]>>>+++>-]<[<<<<]<<<<<<<<+[->>>>>>>>>>>>[<+[->>>>+<<<<]>
>>>>]<<<<[>>>>>[<<<<+>>>>-]<<<<<-[<<++++++++++>>-]>>>[<<[<+<<+>>>-]<[>+<-]<++<<+
>>>>>>-]<<[-]<<-<[->>+<-[>>>]>[[<+>-]>+>>]<<<<<]>[-]>+<<<-[>>+<<-]<]<<<<+>>>>>>>
>[-]>[<<<+>>>-]<<++++++++++<[->>+<-[>>>]>[[<+>-]>+>>]<<<<<]>[-]>+>[<<+<+>>>-]<<<
<+<+>>[-[-[-[-[-[-[-[-[-<->[-<+<->>]]]]]]]]]]<[+++++[<<<++++++++<++++++++>>>>-]<
<<<+<->>>>[>+<<<+++++++++<->>>-]<<<<<[>>+<<-]+<[->-<]>[>>.<<<<[+.[-]]>>-]>[>>.<<
-]>[-]>[-]>>>[>>[<<<<<<<<+>>>>>>>>-]<<-]]>>[-]<<<[-]<<<<<<<<]++++++++++.
Одна проблема — хоть и говорится, что эта программа намного быстрее какой-то другой программы, все равно вычисляет очередной знак она крайне медленно.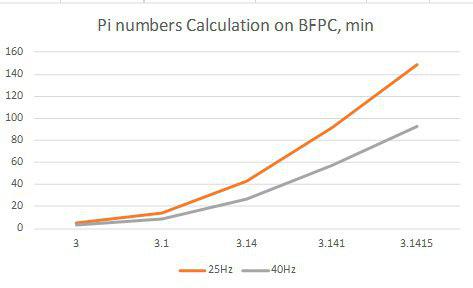
Рис. 13: Время, затрачиваемое на вывод N знаков числа Pi после запятой.
4 знака после запятой придется ждать почти полтора часа…
Рис. 14: — Пи=3! — Как грубо!
Впрочем, даже два знака толком вывести не удалось, вместо них компьютер заявил что Пи равен 4 и завершил работу.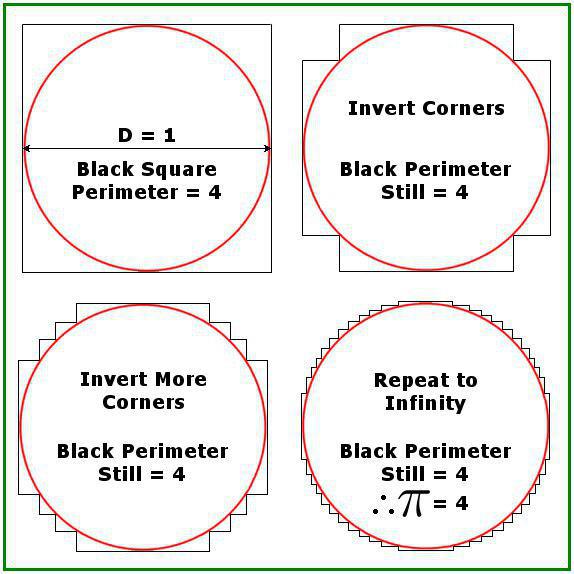
Рис. 15: Он явно знает про ту шутку, что в условии военного положения пи может доходить до четырех.
Я решил пойти другим путем и написал программу вычисления дроби . Точность — 6 знаков числа пи после запятой! Это самый точный результат для дробей с числами адекватного размера.
. Точность — 6 знаков числа пи после запятой! Это самый точный результат для дробей с числами адекватного размера.
Спустя три бессонные ночи я таки написал программу на brainfuck, способную поделить два числа друг на друга и выводить полученный результат с плавающей точкой в терминал. Вердикт эмулятора следующий — потребуется исполнить 60 тысяч инструкций. В следнем по 10 тысяч на знак: 
Рис. 16: Время, затрачиваемое на вывод очередного знако после запятой при вычислении дроби.
Как быстро будут появляться очередные значения. Надо сказать весьма быстро по сравнению с прошлой программой!
Но счастье было недолгим — компьютер начал сбоить в 16-разрядном режиме. Диагностирование показало, что дурит плата памяти — постоянно выставляет 13-й бит. Сделую новую плату памяти и все пройдет, а пока ограничусь дробью  двумя знаками после запятой и 8 разрядным режимом работы. Самое главное — она требует выполнить всего лишь 1600 инструкций! На частоте в 25Гц это — чуть более одной минуты.
двумя знаками после запятой и 8 разрядным режимом работы. Самое главное — она требует выполнить всего лишь 1600 инструкций! На частоте в 25Гц это — чуть более одной минуты.
Неоднократно и со свистом компьютер справляется с поставленной задачей.
To be continued…
Сейчас на компьютере можно исполнять программы, которые не требуют ввода данных пользователем. Я банально до сих пор не накрутил инструкцию CTRLIO.CIN:) И не собираюсь делать это в ближайшее время. В настоящий момент компьютер завершен на 98%. И после двух лет работы накопилось множество проектов, которые ждут момента, когда я ими займусь.
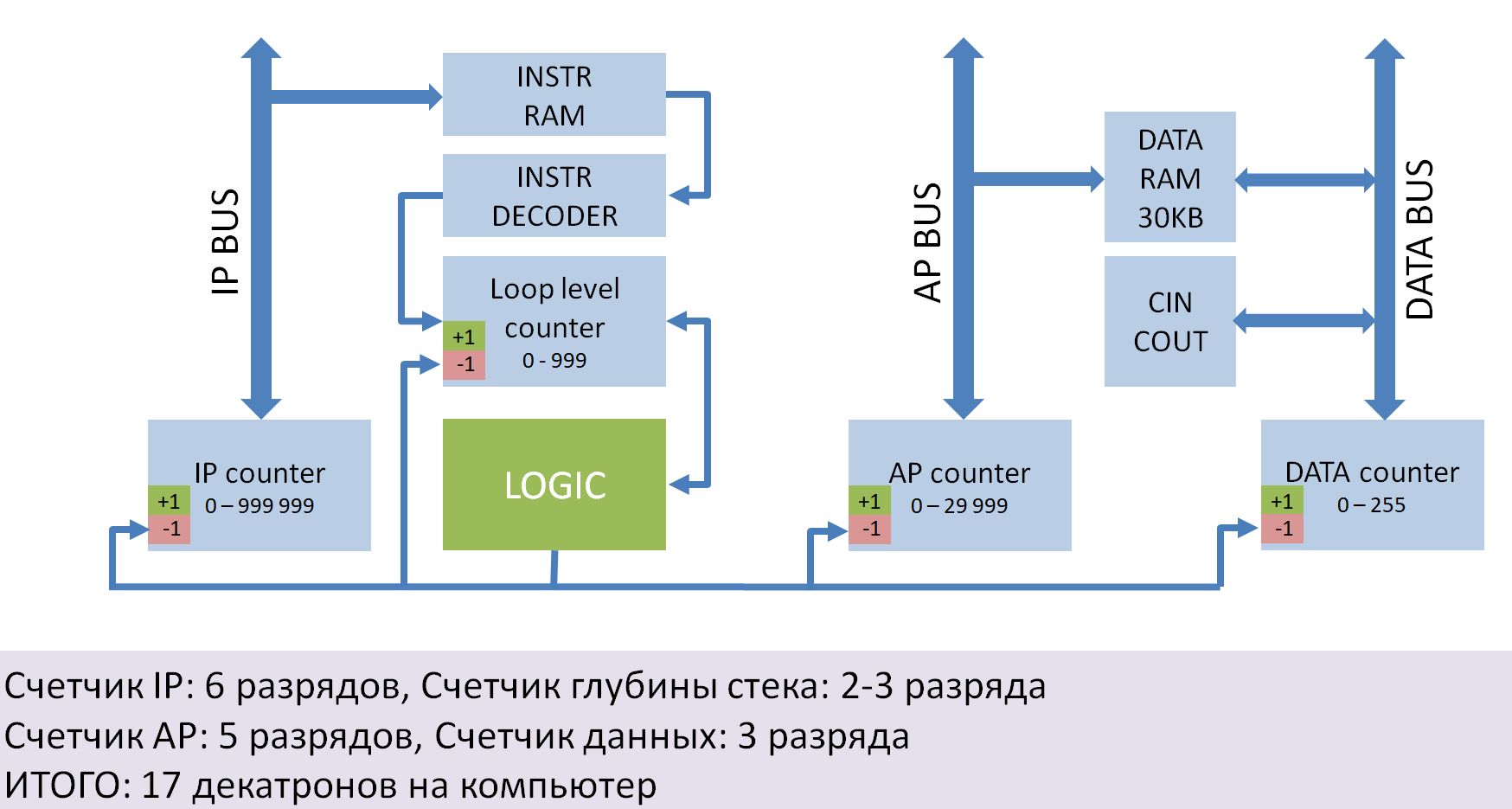
В первую очередь это ламповый компьютер на базе коммутаторных декатронов. У меня уже есть и перфоратор перфолент и сами декатроны (правда в основном А101 — на них компьютер выйдет еще медленнее чем релейный — нужны А103). Даже 700 вакуумных ламп уже имеется и много всего…

У меня и память для него заготовлена -16 штук интегральных кубов памяти на 128 16-разрядных слов каждый. Внутри — многоотверстные ферритовые пластины, эдакое ответвление от памяти на ферритовых кольцах.
Про пневмонику я тоже не забываю — мой товарищ Антон занимается натур. экспериментами, но об этом — в следующий раз.
… оставляя следующие недоделки. Часть задачу решу к фестивалю в конце мая, часть — нет:
- Новая плата памяти, на которой установлены только микросхемы ОЗУ и обвязка к ним. Схема платы памяти есть, печатная плата — еще не разведена. В домашних условиях ее будет лень делать (довольно плотная двухсторонка), посему включу эту плату в заказ, когда буду заказывать платы для пары других проектов — механических часов на реле и пневмоскопа.
- Вместе с новой платой памяти придут стрелочные индикаторы, нормальный крепеж терминального дисплея и самостоятельная логика обновления светодиодной панели.
- Программатор, вернее, разработка прошивки для него. Вообще, при наличии старой платы памяти он избыточен, но так как разъем программирования в наличии — уже можно загружать программу и им.
- Логика тактирования. Тут я совсем ленивая жопа, ибо там буквально обвязать 3 логических модуля. Это обязательно сделаю к фестивалю в конце мая.
- Инструкция чтения из консоли. Она завязана на логику тактирования (в синхронном режиме работы компьютер должен останавливать работу и ждать прихода данных).
- Отправить заявку в книгу рекордов Гиннеса… Как на самый быстрый релейный процессор и одновременно самый медленно-считающий. 16 миллиФлопс это вам не «Шубу в трусы заправлять» (из комментариев на youtube).

Вся документация по релейному компьютеру есть в репозитории на GitHub, а следить за его статусом можно в любой соцсети по ссылкам у меня в профиле.
И еще — 25–26 мая в Москве, на территории «Хлебозавода», пройдет первый фестиваль крафтовых производств и DIY-культуры Antifactory. Я там буду присутствовать с релейным компьютером и релейный контроллер автополива тоже привезу. Вход на мероприятие свободный, так что будете в эти дни в Москве — не упустите шанс увидеть моего релейного монстра вживую. Если довезу в целости и сохранности — обязательно продемонстрирую в работе.
