Младенцы против ИИ: оценка и сравнение психологии здравого смысла

Любопытство ученых уступает только любопытству детей. Когда ребенок начинает говорить, это большая радость для родителей. Когда же гугу-гага заменяется на вполне вразумительную речь, то поток вопросов становится практически нескончаемым. Но даже до этого переломного момента в развитии ребенок проявляет живейший интерес ко всему окружающему, особенно к людям. Этот интерес обусловлен процессом самообучения. В частности младенцы способны проанализировать и понять, что движет тем или иным человеком. Другими словами, младенцы способны видеть связь между человеком, объектом и задачей, которую человек выполняет посредством этого объекта. А вот искусственный интеллект на такой трюк не способен, что было подтверждено учеными из Нью-Йоркского университета (США). Они провели сравнительные опыты, в которых оценивалась так называемая психология здравого смысла младенцев и искусственного интеллекта. Какие именно опыты проводились, что они показали, и насколько младенцы превосходят ИИ? Ответы на эти вопросы мы найдем в докладе ученых.
Основа исследования
Фундаментальным явлением, которое в данном труде изучается, является фолк-психология (или психология здравого смысла). Этим термином обозначается совокупность когнитивных способностей, в том числе и способность предсказывать и объяснять человеческое поведение.
Эта способность присуща не только взрослым, но и младенцам, которые неосознанно стараются максимально быстро и эффективно понять окружающий мир. Процесс раннего развития ребенка порой кажется невероятно быстрым и легким, особенно в контексте познания людей, объектов и мест. Обучить такому машину напротив очень сложно. Если же поставлена цель создать ИИ, максимально имитирующих человека, то необходимо преодолеть эту сложность.
Ученые отмечают, что одной из основных преград на пути создания ИИ на основе здравого смысла является вопрос — с каких знаний начать? Фундаментальные знания человеческого младенца ограничены, абстрактны и отражают наше эволюционное наследие, однако они могут приспособиться к любому контексту или культуре, в которых может развиваться этот младенец. Следовательно, для создания супер крутого ИИ нужно начинать с малого, т. е. перед созданием «взрослого» ИИ нужно создать его младенческий вариант.
За последние несколько десятилетий фундаментальные исследования психологии здравого смысла младенцев, т. е. понимания младенцами намерений, целей, предпочтений и рациональности, лежащих в основе действий агентов (людей), показали, что младенцы приписывают цели агентам и ожидают, что агенты будут добиваться целей рациональным и эффективным путем. Предсказания, поддерживающие психологию здравого смысла младенцев, лежат в основе человеческого социального интеллекта и, таким образом, могли бы помочь улучшить здравый смысл ИИ, но эти предсказания обычно отсутствуют в алгоритмах машинного обучения, которые вместо этого предсказывают действия напрямую и, следовательно, не обладают гибкостью к новым контекстам и ситуациям. Тем не менее исследования психологии здравого смысла младенцев еще не оценивались в рамках, которые можно было бы непосредственно протестировать в сравнении с машиной.
Различные описания знаний младенцев об агентах предполагают, что эти знания:
- связаны как единый набор абстрактных понятий каузальной действенности (причина-следствие), эффективности, целенаправленности и перцептивного доступа;
- отражают интуитивное понимание младенцами психических состояний агентов, которое направляет их эффективные действия в соответствии с их психическими состояниями;
- или возникают из индивидуальных достижений, основанных на собственном опыте действий младенцев.
Из этой богатой экспериментальной и теоретической базы возникает потребность во всеобъемлющей структуре, в которой можно было бы охарактеризовать знания младенцев об агентах с результатами в одной задаче, сопоставимыми с результатами в другой, и с результатами в наборе задач, сопоставимыми для младенцев и машин.
В рассматриваемом нами сегодня труде ученые демонстрируют разработанную ими базу для тестирования психологии здравого смысла у младенцев путем оценки результатов младенцев в тесте детской интуиции (BIB от Baby Intuitions Benchmark) — наборе из шести задач, исследующих психологию здравого смысла. BIB был разработан специально для тестирования интеллекта как младенцев, так и машин. Также было проведено сравнение младенцев и ИИ в рамках задач здравого смысла.
Подготовка к опытам

Изображение №1
Задачи BIB включали в себя короткие беззвучные анимационные видеоролики с простыми визуальными эффектами (простые геометрические фигуры), выполняющие основные движения в рамках пространства разделенного сеткой (изображение №1). Этот дизайн позволял реализовать масштабируемую процедурную генерацию стимулов, которая требуется для тестирования алгоритмов машинного обучения. Этот дизайн также представлял собой новый, накладной навигационный контекст, который требовал предположения о полной наблюдаемости агентами пространства и его содержимого.
Стоит отметить, что все задачи BIB согласовывались друг с другом, что позволяло сравнивать разные задачи, не беспокоясь о приписывании нулевых эффектов различным требованиям к зрению, памяти или другим задачам. Более того, вместо того, чтобы сосредоточиться на одном принципе психологии здравого смысла, задачи BIB были сосредоточены на трех возможных атрибуциях* действий агентов, которые может сделать наблюдатель, — атрибуции цели, атрибуции рациональности и атрибуции инструментальности. Это помогало выяснить, могут ли такие принципы психологии здравого смысла согласовываться, и если да, то как.
Атрибуция* — механизм объяснения причин поведения другого человека.
Используя среду BIB, ученые процедурно сгенерировали видеостимулы для тестирования младенцев и вычислительных моделей и выбрали самые яркие примеры конкретных принципов психологии здравого смысла, на которые нацелена каждая задача.
Первые три задачи были сосредоточены на приписывании наблюдателем целей действиям агентов.
Задача «цель» отражает идею о том, что цели агентов направлены на объекты, а не на места. Наблюдатели во время ознакомления смотрят, как агент неоднократно перемещается к одному и тому же одному из двух объектов примерно в одном и том же месте в неизменном пространстве сетки. При тестировании наблюдатели могут быть более удивлены, когда агент перемещается к новому объекту в этом пространстве после того, как положения двух объектов меняются местами.
Задача «несколько агентов» спрашивает, являются ли цели специфичными для агентов. Наблюдатели смотрят, как агент перемещается к одному и тому же одному из двух объектов в изменяющемся пространстве, причем оба объекта появляются в разных местах. При тестировании наблюдатели могут быть более удивлены, когда исходный агент, а не новый, перемещается к новому объекту.
Задача «недостижимая цель» спрашивает, могут ли агенты формировать новые цели, когда их существующие цели становятся недостижимыми. Наблюдатели смотрят, как агент перемещается к одному и тому же одному из двух объектов в изменяющемся пространстве, причем оба объекта появляются в разных местах. При тестировании пространство сетки снова меняется, так что целевой объект агента становится физически недоступным. Наблюдатели могут быть более удивлены, когда агент переходит к новому объекту, когда его предыдущий целевой объект доступен, а не наоборот.
Следующие две задачи были сосредоточены на приписывании наблюдателем рациональности действиям агентов.
Задача «эффективный агент» отражает идею о том, что агенты действуют рационально для достижения целей. Наблюдатели смотрят, как агент эффективно перемещается к объекту, преодолевая препятствия в неизменном пространстве. При тестировании объект появляется в том месте, где он появился во время ознакомления, но пространство сетки менялось таким образом, что препятствия, которые блокировали объект, исчезали или были заменены другими препятствиями. Наблюдатели могут быть более удивлены, когда агент движется по знакомому, но уже неэффективному пути к объекту.
Задача «неэффективный агент» спрашивает, что наблюдатели ожидают от агентов, которые изначально движутся неэффективно в меняющемся пространстве. Во время ознакомления наблюдатели смотрят, как агент движется к объекту по тем же путям, что и агент в задаче «эффективный агент», но в этот раз на пути агента нет препятствий, поэтому движения агента к объекту неэффективны. При тестировании среда менялась, как и в задаче «эффективный агент». Наблюдатели могут либо больше удивляться, когда агент продолжает неэффективно двигаться к объекту, либо не иметь ожиданий относительно того, будет ли этот агент двигаться к объекту эффективно или неэффективно.
Последняя задача фокусировалась на приписывании наблюдателем инструментальности действиям агентов.
Задача «инструментальное действие» отражает идею о том, что агенты должны предпринимать инструментальные действия только в случае необходимости. Во время ознакомления наблюдатели смотрят, как агент перемещается сначала к ключу (инструменту), который он использует для удаления барьера вокруг объекта в разных местах, а затем к этому объекту. При тестировании наблюдатели могут быть больше удивлены, когда агент продолжает двигаться к ключу, а не прямо к объекту, когда барьер больше не блокирует объект.
Все видеоролики (стимулы) доступны по этой ссылке.
Структура задач BIB использовала парадигму времени поиска «нарушение ожидания», часто используемую для тестирования младенцев. Наблюдатели видят серию ознакомительных испытаний, которые служат для создания ожидания, за которым следует:
- ожидаемый результат, который в восприятии отличается от ознакомления, но концептуально непротиворечив ему;
- неожиданный результат, который в восприятии похож на ознакомление, но концептуально противоречив ему (потому он удивляет наблюдателя).
Испытания с младенцами
В эксперименте №1 были собраны ответы младенцев на две из шести задач BIB (цель и эффективный агент).
Линейные регрессии смешанной модели оценивали выполнение младенцами каждой задачи, а дополнительная регрессия изучала общую успешность младенцев по обеим задачам. Тут время наблюдения выступало в качестве зависимой переменной, результат (ожидаемый и неожиданный) в качестве фиксированного эффекта, а участник в качестве перехвата случайных эффектов. Чтобы получить p-значения, ученые провели тесты Вальда типа 3 по результатам каждой регрессии.
Эксперимент №1 был сосредоточен на этих двух задачах, потому что здравый смысл, который они измеряли, имел последовательные результаты в литературе по пониманию действий младенцев. Таким образом, эксперимент №1 был направлен на то, чтобы предоставить первоначальные доказательства психологии здравого смысла младенцев.
Эксперимент №2 следовал предварительно зарегистрированному плану проектирования и анализа с повторением двух задач в эксперименте №1 с некоторыми улучшениями: автоматическое продвижение испытания; балансировка стороны целевого объекта между участниками задачи «цель»; и сопоставление продолжительностей тестовых испытаний среди участников в задаче «эффективный агент». Младенцы были протестированы на этих двух задачах, а также на других четырех задачах BIB, описанных выше, которые не были включены в эксперимент №1.
В эксперимент №1 приняли участие 11-месячные младенцы (N = 26, Mage = 11.13 месяца, 12 девочек и 14 мальчиков), родившиеся в гестационном возрасте ≥37 недель. Они выполнили задачу «цель», задачу «эффективный агент» или обе, при этом половина младенцев сначала выполняла первое задание. Всего было проведено 48 индивидуальных сеансов тестирования и 24 сеанса на задание. Дополнительные четыре сеанса были исключены, поскольку младенцы не завершили сеанс.
В эксперименте №2 приняли участие 11-месячные младенцы (N = 58, Mage = 11.06 месяцев, 31 девочка и 27 мальчиков), родившиеся в гестационном возрасте ≥ 37 недель. Каждый младенец выполнил хотя бы одно задание BIB, всего N = 288 индивидуальных сеансов тестирования.
Все тесты проводились онлайн через Zoom. Каждому пробному видео предшествовал 5-секундный захват внимания (вращающееся пятно, сопровождаемое звенящим звуком, в центре экрана), чтобы сосредоточить внимание младенца на экране, и каждое видео замирало после того, как агент достигал объекта. Последний кадр видео оставался на экране до тех пор, пока младенцы не отводили взгляд в течение 2 секунд подряд или в течение 60 секунд.
Изображение №2
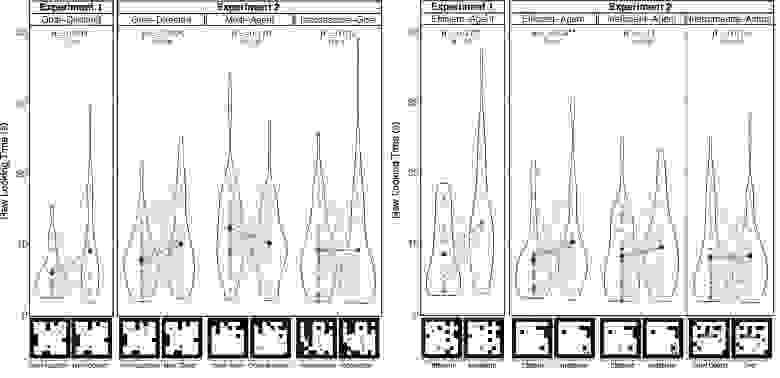
Выше представлены результаты младенцев в рамках выполнения двух задач эксперимента №1. Время наблюдения у младенцев варьировалось в зависимости от задачи, с более длительным в задаче «эффективный агент» по сравнению с задачей «цель», что отражает большую продолжительность тестового испытания в задаче «эффективный агент». В целом младенцы дольше смотрели на неожиданные, а не на ожидаемые результаты.
Младенцы были удивлены (наблюдали дольше), когда агент переходил к новому объекту в задаче «цель». Такая же картина наблюдалась и в случае, когда эффективный агент выбирал неэффективный путь к объекту в задаче «эффективный агент».
Результаты младенцев по эксперименту №2 также показаны на графиках выше. Время наблюдения у младенцев варьировалось в зависимости от задачи, что отражало разную продолжительность тестовых заходов для разных задач. В целом, младенцы не наблюдали дольше за неожиданными результатами по сравнению с ожидаемыми. Но задача по взаимодействию результатов показала, что разные задачи вызывают разные паттерны взгляда младенцев.
Сначала были рассмотрены результаты младенцев по трем задачам эксперимента №2, которые были сосредоточены на атрибуции цели: задача «цель», задача «несколько агентов» и задача «недостижимая цель». В соответствии с результатами эксперимента №1, младенцы были удивлены, когда агент переместился к новому объекту в задаче «цель». В случае появления нового агента в задаче «несколько агентов» младенцы не показали разницы в удивлении, когда этот агент по сравнению с исходным перемещался к новому объекту. Младенцы в задаче «недостижимая цель» также не показали разницы в удивлении, когда агент перемещался к новому объекту, когда его целевой объект был доступен по сравнению с недоступным.
Затем были рассмотрены результаты младенцев в двух задачах, которые были сосредоточены на атрибуции рациональности: задачи «эффективный агент» и «неэффективный агент». В соответствии с результатами эксперимента №1, младенцы были удивлены, когда эффективный агент выбирал неэффективный путь к объекту в задаче «эффективный агент». Младенцы в задаче «неэффективный агент» не показали разницы в удивлении, когда агент продолжал неэффективно двигаться к объекту. В результате не было найдено доказательств того, что удивление младенцев по отношению к более позднему неэффективному действию неэффективного агента отличалось от их удивления по отношению к более позднему неэффективному действию эффективного агента.
В заключение была рассмотрена атрибуция инструментальности младенцев через их результаты в задаче «инструментальное действие». Младенцы не демонстрировали разницы в удивлении, когда агент двигался к инструменту, в отличие от его целевого объекта, когда инструмент больше не был нужен для достижения цели.
Испытания с ИИ
Чтобы выяснить, могут ли знания младенцев об агентах отражаться в современном машинном интеллекте, ученые сравнили показатели младенцев на BIB в эксперименте №2 с показателями трех моделей обучаемых нейронных сетей. Модели формировали прогнозы о действиях агента при тестировании на основе его действий во время ознакомления. Чтобы получить непрерывную меру удивления как коррелят времени взгляда младенцев, ученые рассчитали ошибку предсказания моделей для каждого кадра каждого результата и рассмотрели кадр с максимальной ошибкой. Затем, чтобы сравнить показатели модели и младенца, был рассчитан средний показатель неожиданности по Z-баллу для каждого исхода для каждой модели и среднее время поиска по Z-баллу для каждого исхода для младенцев. Для незапланированного количественного сравнения общего сходства между показателями младенцев и каждой модели была проведена оценка среднеквадратичной ошибки (RMSE от root mean squared error) для шести задач BIB, используя средний Z-показатель для неожиданного результата. Также было сравнение между результатами младенцев и «базовым уровнем», которому был присвоен «балл неожиданности» 0 по всем задачам.
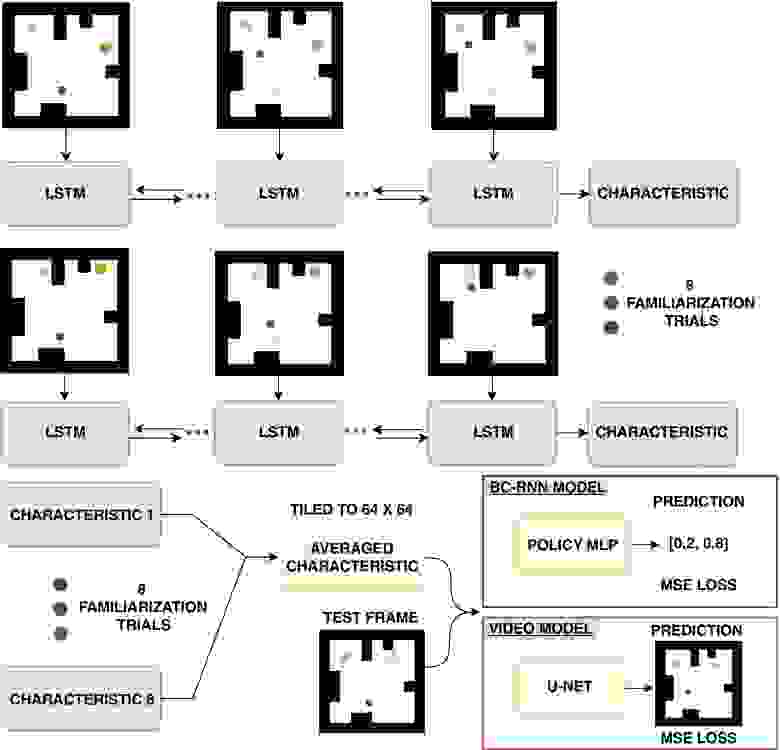
Поскольку младенцы взаимодействуют со стимулами, такими как BIB, посредством пассивного наблюдения, модели нейронных сетей были основаны на архитектуре Theory of Mind Net (ToMnet), которая представляет собой нейронную сеть, разработанную специально для пассивного наблюдения. Она делает выводы об основных психических состояниях агента на основе его поведения.
Изображение №3
С помощью этой архитектуры было протестировано три модели из двух классов: поведенческое клонирование (BC от behavioral cloning) и видеомоделирование (схемы выше).
Две модели BC предсказывали, как агент будет действовать, используя фоновое обучение в качестве примеров пар состояние-действие. Чтобы предсказать следующее действие агента в тестовом испытании, BC модель объединяла информацию из изученных особенностей из предыдущего кадра тестового видео вместе с изученными особенностями в наборе ознакомительных видео. Видеомоделирование использовало аналогичную стратегию, архитектуру и процедуру обучения, но оно было нацелено на предсказание всего следующего кадра тестового видео, а не только следующего действия агента.
Две BC модели отличались кодированием ознакомительных заходов. Первая модель полагалась на простой многоуровневый персептрон (MLP от multi-layer perceptron) для независимого кодирования пар состояние-действие, а вторая модель полагалась на более сложную двунаправленную рекуррентную нейронную сеть (RNN от recurrent neural network) для последовательного кодирования пар состояние-действие.
Состояния были закодированы сверточной нейронной сетью (CNN), которая была предварительно обучена с использованием расширенного временного контраста (ATC от augmented temporal contrast). Как для кодеров MLP, так и для кодеров RNN модель получала характеристическое вложение агента, сначала объединив вложения по кадрам (используя среднее значение для MLP и последний шаг для RNN) для каждого ознакомительного испытания, а затем усреднив второе значение для ознакомительных испытаний. При объединении кадров видео подвергались случайной подвыборке для использования не более 30 кадров. Чтобы предсказать будущие действия агента, определяемые как непрерывное изменение положения на основе видео (с частотой 3 кадра в секунду), модели объединяли характеристическое вложение с текущим состоянием окружающей среды (также закодированным с помощью CNN).
Одна видеомодель последовательно кодировала каждое ознакомительное испытание, пропуская до 30 кадров через CNN, а затем объединяя их с двунаправленной RNN. Модель получала характеристическое вложение агента путем усреднения вложений RNN. Модель объединяла характеристическое вложение с текущим состоянием окружающей среды (определяемым текущим кадром видео) для прогнозирования следующего кадра видео (с частотой 3 кадра в секунду) с использованием архитектуры U-net.
Перед тестированием модели были обучены на тысячах фоновых примерах, предоставленных набором BIB данных о BIB-подобных агентах, демонстрирующих простое поведение в пространстве сетки. Обучающая выборка включала отдельные компоненты тестовой выборки (например, движение агентов к объектам, непротиворечивые цели агентов, преграды, инструменты и т. д.).
В одном обучающем задании агент перемещался к одному объекту в разных местах в пространстве сетки. Во втором обучающем задании два объекта были представлены в разных точках пространства, но всегда очень близко к агенту; агент последовательно перемещался к одному из них. В третьем обучающем задании агент перемещался к одному объекту в разных точках пространства; в разные моменты знакомства этот агент заменялся другим агентом. Наконец, в четвертом обучающем задании агента и ключ окружал зеленый барьер; агент получал ключ, чтобы выйти из заблокированной зоны и перейти к объекту.
Изображение №4
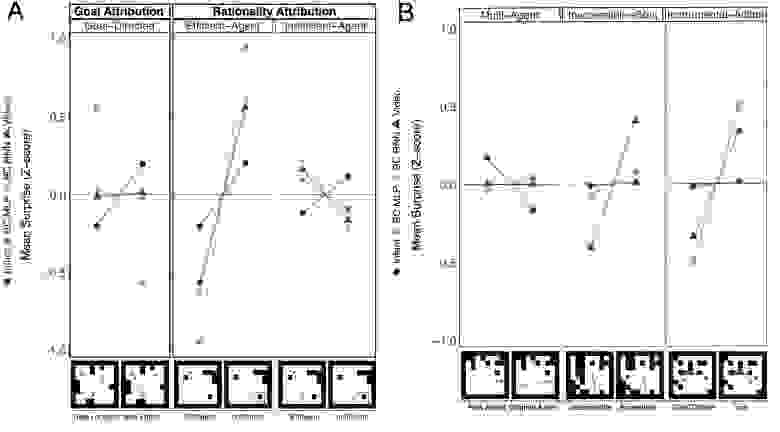
На графиках выше показаны средние Z-баллы неожиданных оценок моделей по отношению к ожидаемым и неожиданным результатам для каждой задачи. Для сравнения также на графики были нанесены средние значения времени наблюдения младенцев в задачах из эксперимента №2. Видно, что показатели моделей мало похожи на показатели младенцев.
Чтобы оценить атрибуцию целей машин по сравнению с младенцами, ученые сравнили результаты моделей и младенцев в рамках данной задачи. В отличие от младенцев, которые создавали пару между агентом и объектом (цель), а не агентом и положением объекта, модели либо связывали агентов с положением объекта (BC MLP), либо вообще не связывали его ни с объектом, ни с его положением (BC RNN, видеомодель).
Затем сравнивалась атрибуция рациональности моделей и младенцев в рамках задач «эффективный агент» и «неэффективный агент». Модели успешно приписывали рациональные действия агентам в задаче «эффективный агент» (даже в большей степени, чем младенцы). Однако они не приписывали рациональное действие ранее неэффективным агентам, которые действуют в новых условиях, в задаче «неэффективный агент». Здесь результаты моделей были почти ортогональны результатам младенцев.
Сравнение эффективности модели и младенца в трех других BIB задачах не выявило случаев, когда модели демонстрировали положительные прогнозы действий агентов, отсутствующие в прогнозах младенцев. В частности, в то время как младенцы, возможно, были относительно более удивлены появлением нового агента в ожидаемом результате задачи «несколько агентов», модели не показали разницы в удивлении.
В задаче «недостижимая цель» видеомодель больше удивлялась, когда агент перемещался к новому объекту, когда его целевой объект был доступен, в отличие от младенцев. Но, учитывая неудачу этой модели в задачах «цель» и «несколько агентов», ее эффективность вряд ли будет отражать понимание целенаправленных действий агентов по отношению к объектам.
Например, модель могла узнать, что препятствия в мире сетки блокируют объекты, и что агенты перемещаются к объектам. Это привело бы к более низкой оценке удивления, когда агент перемещался к одному доступному объекту, по сравнению с тем, когда он перемещался к любому из доступных объектов.
Точно так же в задаче инструментального действия модели, по-видимому, преуспели там, где младенцы не добились успеха, демонстрируя большее удивление, когда агент двигался к ключу, когда в этом не было необходимости. Но более тщательное изучение эффективности моделей показало, что этот очевидный успех ограничен тестовыми испытаниями, в которых зеленый барьер отсутствовал, а не присутствовал, но не имел значения.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых.
Эпилог
Мозг человека — это удивительный механизм, который постоянно работает, выполняя множество функций, многие из которых мы даже не осознаем. Однако этот орган требует обучения, чтобы полностью раскрыть свой потенциал. Дети в период раннего развития чрезвычайно внимательны ко всему, что их окружает. Они еще не умеют говорить и даже перевернуться без помощи не в состоянии, но их глаза, уши, нос уже считывают сенсорную информацию, а мозг ее анализирует. В аспектах социализации важным является понимание того, что хочет человек. И это не философский вопрос. Это вопрос когнитивного мышления, ответом на который является правильное сопоставление действий человека и целей, которых он хочет достичь этими действиями. Младенцы, несмотря на свой крайне малый опыт социальной жизни, владеют весьма развитой психологией здравого смысла, которая и отвечает за связь между агентом (человеком) и целью.
Чтобы искусственный интеллект действительно напоминал то, что мы видим в кино и о котором читаем в книгах, он также должен обладать определенными когнитивными умениями. Однако, как показало рассмотренное нами сегодня исследование, в некоторых аспектах ИИ отстает даже от 11-месячных младенцев.
Ученые провели ряд тестов, в которых с помощью примитивно анимированных видео смогли оценить степень психологии здравого смысла младенцев. На видео присутствовало пространство в сеточку, агент и объект (цель). Агент передвигался по полю к объекту. В некоторых случаях между агентом и елью была преграда, которую можно было обойти используя ключ (другой объект). Также агенты могли вести себя эффективно или неэффективно, использовать ключ, когда он не нужен, и т. д. Все вариации поведения агентов вызывали у младенцев определенную реакцию (более длительное наблюдение за агентом), которую было решено назвать просто «удивлением».
Затем ученые подготовили несколько моделей нейронных сетей и провели с ними аналогичные испытания. В некоторых из них модели на первый взгляд справлялись лучше младенцев, но более тщательный анализ показывал, что это так лишь в рамках тестовых заходов.
Суммируя результаты испытаний с младенцами и моделями, а также их сравнение, ученые пришли к выводу, что даже самый развитый ИИ пока не может превзойти младенцев в рамках психологии здравого смысла.
И это особенно удивительно, ведь в модель можно вложить множество знаний, провести тысячи обучающих испытаний, но она все равно будет справляться хуже, чем маленький человечек, который еще и ползать то не умеет.
По мнению авторов исследования, их труд не только показывает, что мозг человека (даже младенца) во многом превосходит ИИ, но и дает направление для будущих исследований и разработок. Во время проектирования ИИ, который должен имитировать мозг человека, необходимо четко понимать какие именно аспекты работы мозга важны для достижения полноценной имитации.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
