Mixtral 8x7B – Sparse Mixture of Experts от Mistral AI
11 декабря 2023 года Mistral AI, парижский ai-стартап, основанный 7 месяцев назад, выпустил новую модель Mixtral 8×7B — high-quality sparse mixture of experts model (SMoE). Многие считают модели Mistral AI самыми крутыми из открытых llm-ок, я тоже так считаю, поэтому интерес к новой модели есть большой. В этой статье я хочу коротко пробежаться по тому, как устроена новая модель и какие у её архитектуры преимущества. На некоторых технических моментах я буду останавливаться более подробно, на некоторых — менее.
Архитектура mixture of experts
Что такое mixture of experts? Это такая техника, в которой некое множество «экспертов»,
иными словами специализированных сетей, применяются для того, чтоб решать комплексную проблему по частям. Это значит, что у нас есть несколько разных сетей, каждая из которых хорошо умеет решать свою узкую задачу, и когда в модель приходит запрос, то на этот запрос отвечают не все эксперты, а только некоторое их множество, а то и один.
Основные этапы создания mixture of experts модели
Поделить входящую в сеть задачу на подзадачи. При этом подзадачи могут пересекаться.
Простой пример: на картинке есть объекты, есть распределения цветов, есть формы, есть фон, и информацию о фоне эффективно обработает одна экспертная сетка, а информацию об объектах — другая.
Не во всех случаях деление комплексной задачи такое прямое. В более сложных случаях, можно, например, делить входные сэпмлы или токены на кластеры на основе расстояния в пространстве, и представлять каждый кластер, как свою задачу. Есть и другие способы.
Обучить экспертную сеть для решения каждой подзадачи.
Использовать gating (routing) модель, что решить, какого эксперта мы используем. Gating model принимает поданный в модель контекст, на основе него оценивает все экспертные предсказания и выбирает, какой эксперт / эксперты будет давать итоговый ответ пользователю.
Объединение предсказаний экспертов. Можно выбрать одного эксперта, который даст ответ, а можно выбрать нескольких и совместить их ответы.

Sparse Mixture of Experts
На картинке выше видно, что каждый эксперт получает input и каждый эксперт даёт предсказание. Это может быть довольно долго.
Но ведь мы можем сразу отсекать «неподходящих» экспертов. На картинке ниже изображён вариант, когда gating модель выбирает экспертов, к которым стоит обратиться, исходя из полученного контекста. Остальные эксперты не получат входных данных и будут тихонько стоять в стороне, то есть они не будут работать и что-то считать, и время ответа сократится.

Ребята из Mistral пишут, что для каждого входного токена роутер (построитель маршрутов к экспертам) выбирает двух экспертов, которые обработают этот токен; их аутпуты затем складываются. Стоит пояснить, что использовать не всех экспертов придумали изначально не они.
Для наглядности картинка из блога гугла. В примере с этой картинки роутер выбирает для каждого токена топ-1 эксперта (оценка схожести токена и «домена» эксперта самая высокая) и направляет этот токен именно этому эксперту. Остальные не получают этот токен.

Источник: https://blog.research.google/2022/11/mixture-of-experts-with-expert-choice.html? m=1
Зачем это нужно ?
Не секрет, что большие языковые модели используют transformer-based архитектуру. Если сильно упрощать, то большие языковые модели — это поставленные друг на друга блоки трансформеров. И в этом трансформере есть такой feed-forward слой — он голубой на картинке ниже. В этом слое, как говорят, хранятся выученные «знания» модели. Для больших моделей этот слой может содержать сумасшедшее количество нейронов.
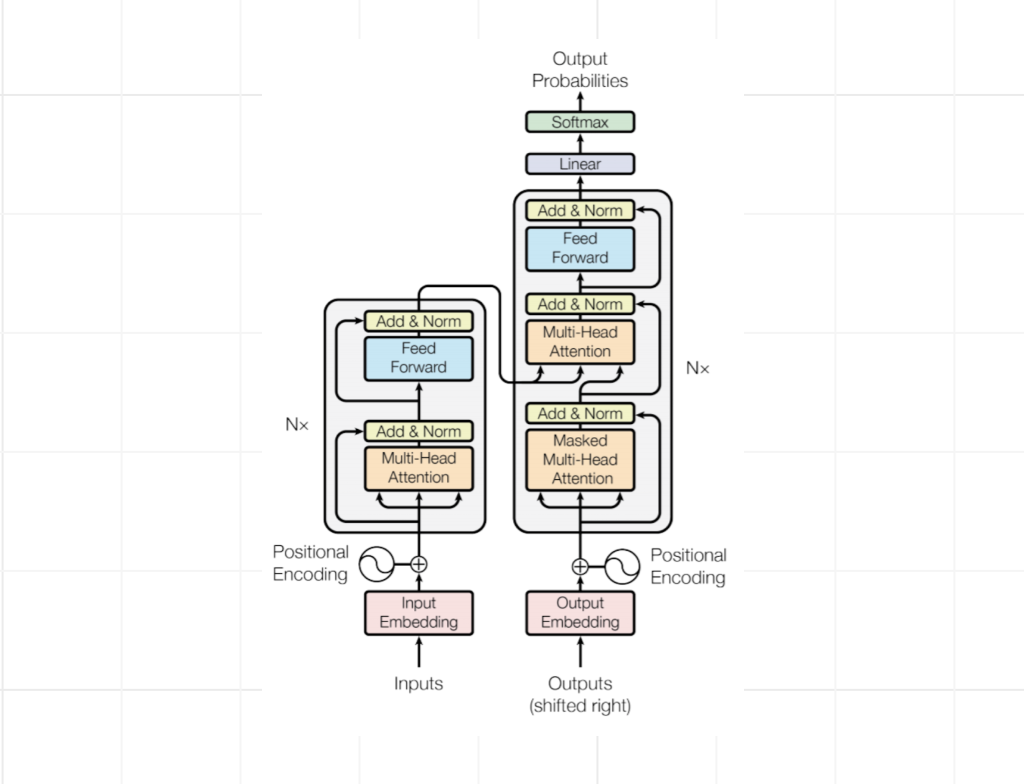
Источник: всем известная Attention is all you need от Google
Мы же дробим этот FNN слой на набор экспертов, и таким образом, мы можем использовать не все нейроны и не все знания этого слоя, а выбирать только те, которые нам нужны. Отсюда расшифровка слова Sparse в аббревиатуре SMoE — на смену обычным feed-forward слоям пришли разреженные слои. Разреженность, «разнесённость» знаний по набору экспертов, позволяет нам запускать только части сложной системы, и наши вычисления заметно ускоряются.

Источник: Mixture of Experts Explained, HuggingFace
Минусы — мы всё равно должны хранить все веса в памяти, так как потенциально мы можем выбрать любого эксперта, однако, как я уже неоднократно упомянула, использовать мы будем не все веса. Это позволяет Mixtral 8×7B, которая по факту содержит 42B параметров, работать с той же скоростью, что и LLaMa 7B, которая, собственно, содержит только 7B параметров.
Метрики Mixtral
Mixtral сравнивалась с семейством Llama 2 и базовой моделью GPT-3.5. Mixtral оказалсь не хуже, а на некоторых бенчмарках даже победила ламу и гпт.

Источник: https://mistral.ai/news/mixtral-of-experts/
А ещё по сравнению с ламой Mixtral меньше галлюцинирует и более корректна в высказываниях.
Сейчас Mixtral доступна на платформе Mistral AI через api в бета-версии, также выложена на huggingface. Перед запуском нужно иметь в виду, что, например, в 16ГБ такая модель, вероятно, не влезет. И в 32, думаю, тоже. А ещё mixtral можно выбрать в качестве отвечающей модели в чате perplexity, так что попробовать её можно прямо из браузера. Интересно, что в блогпосте Mistral AI среди языков Mixtral русский не упомянается, тем не менее, она на нём говорит.

Скин из чата perplexity
Можно ожидать, что в виду The AI Act, принятого в Евросоюзе пару дней назад, прогресс в выкладывании open-source llm-ок притормозится, но будем ждать и надеяться!
Источники:
Пост Mistral AI о выходе модели
Подробный пост с формулами Mixture of Experts Explained от HF
Доступно написанная Mixture-of-Experts with Expert Choice Routing от Google
Общее объяснение концепции Mixture of experts
