Микросервис головного мозга

Когда нужно делить фронтенд-часть приложения на микросервисы? Какой стек использовать? И какие стандарты использовать, чтобы не выстрелить себе же в ногу при переходе на микрофронты? Михаил Трифонов (Lead Frontend в компании Cloud) ранее уже выступал с докладами о микросервисах, получил фидбек от сообщества и с его учётом сделал новый доклад на HolyJS. А теперь мы (организаторы HolyJS) сделали для Хабра текстовую версию этого выступления.
Странно было бы делать доклад про микросервисы монолитным. Поэтому каждая глава этого поста является изолированным, слабо связанным кусочком. Так что можете читать по отдельности, а можете — целиком.
Далее повествование ведется от первого лица.
Оглавление
Потребность
Очень частый вопрос — когда действительно необходимы микрофронты. Для себя я выбрал два лучших их применения. Первое — когда нужно сделать рефакторинг. Допустим, есть legacy-приложение на Angular 1, и тут компания решила отрефакторить его на React 18.

Многие разработчики говорят: «Мы сейчас поднимем отдельное приложение на React и начинаем параллельно разрабатывать». Новые фичи разрабатывают сразу на двух технологиях, и когда появляется время, переносят старые фичи с Angular на React. Но в какой-то момент это перестает работать, потому что рефакторинг идет медленно. Тогда разработчики приходят к бизнесу и требуют остановить разработку фич на пару месяцев, чтобы отрефакторить всё на React. Дальше начинает триггерить у бизнеса, и в итоге одновременно существует два приложения, причем React, скорее всего, никогда и не выйдет в релиз.

Что можно сделать с микросервисной архитектурой? Всё legacy-приложение на Angular можно обернуть в микросервис. А рядом создать второй микросервис — то, к чему мы хотим прийти. И дальше постепенно, фича за фичей, мы переходим от Angular к React. Затем можем просто убить микросервисную архитектуру, если она не нужна. Главное, что мы плавно, не тормозя бизнес, уходим от legacy. Если кто-то прямо сейчас живет с этой болью, хочу посоветовать классный доклад Дениса Мишунова с HolyJS «Я создал Франкенштейна: 3 истории миграции».
Вторая ситуация, в которой нужны микросервисы, — когда у вас есть независимые команды или слишком большая разработка, и все они трудятся над одним приложением. В таких случаях долгое взаимодействие влияет на релизные циклы.
Почему так происходит? У разработчиков есть только частичное понимание: они работают над своим продуктом, в то время как есть целая база, в которую они никогда не залезают. Если разработчик что-то сломает, появятся merge-конфликты, которые он может неправильно разрешить. Также тормозят выкатку фичи релизные циклы, внедрение Git Flow и повторное тестирование.
И неважно, большая или маленькая фича — на деле разработчики при merge request выглядят как-то так:

Что же с этим делать? Можно всё приложение распилить на микросервисы. Каждый микросервис положить в отдельный репозиторий, чтобы физически у них не было взаимодействия. А у каждого репозитория назначить своего владельца, который будет работать только с этим репозиторием.

Тогда у владельцев будет полное понимание кодовой базы и они не смогут влиять на соседние репозитории. А поскольку не будет взаимодействия, то не нужны релизные циклы, повторное тестирование и Git Flow — достаточно GitHub Flow. Всё это бережет нервы разработчиков и ускоряет разработку.
Технологический стек
На чем во фронтенде можно реализовать микросервисный подход? Для этого нужно научить браузер двум вещам. Первая — загружать бандлы в реальном времени, вторая — настроить оркестрацию.
Для загрузки bundle есть два самых популярных способа (конечно, помимо варианта с самописом). Первый — пойти по пути System JS, а второй — по Webpack Module Federation. Давайте их сравним.

System JS написан на нативных модулях, поэтому вы не привязываетесь к бандлеру и загружаете bundle в realtime. В Webpack Module Federation из плюсов — поддержка webpack, из минусов — привязка к webpack и работа с их документацией.
Еще одно отличие — реализация Shared dependency. Кратко расскажу, что это: когда вы скачиваете микросервис, хочется загрузить react и react-dom только один раз, а дальше просто переиспользовать его. И в System JS можно использовать такую штуку, как webpack externals, которая говорит бандлеру «Не клади этот импорт в bundle, а загружай из глобальных переменных». И с помощью System JS вы в эти переменные кладете react и react-dom.

Теперь разберемся, как это устроено в Webpack Module Federation. В оркестраторе вы указываете, что хотите «шарить» определенные библиотеки. Дальше, когда идет bootstrap всего приложения, он создает scope библиотек под капотом и кладет туда react и react-dom. Когда у вас грузится какой-то сервис, Module Federation проверяет react и react-dom в scope и кладет в него только ссылки, откуда еще он может взять эти библиотеки, чтобы можно было их дозагрузить, если что-то пойдет не так. Другие библиотеки дальше кладутся при бутстрапе в этот scope, и при mount«е react и react-dom грузятся один раз из оркестратора, а все зависимости — непосредственно из самого сервиса.
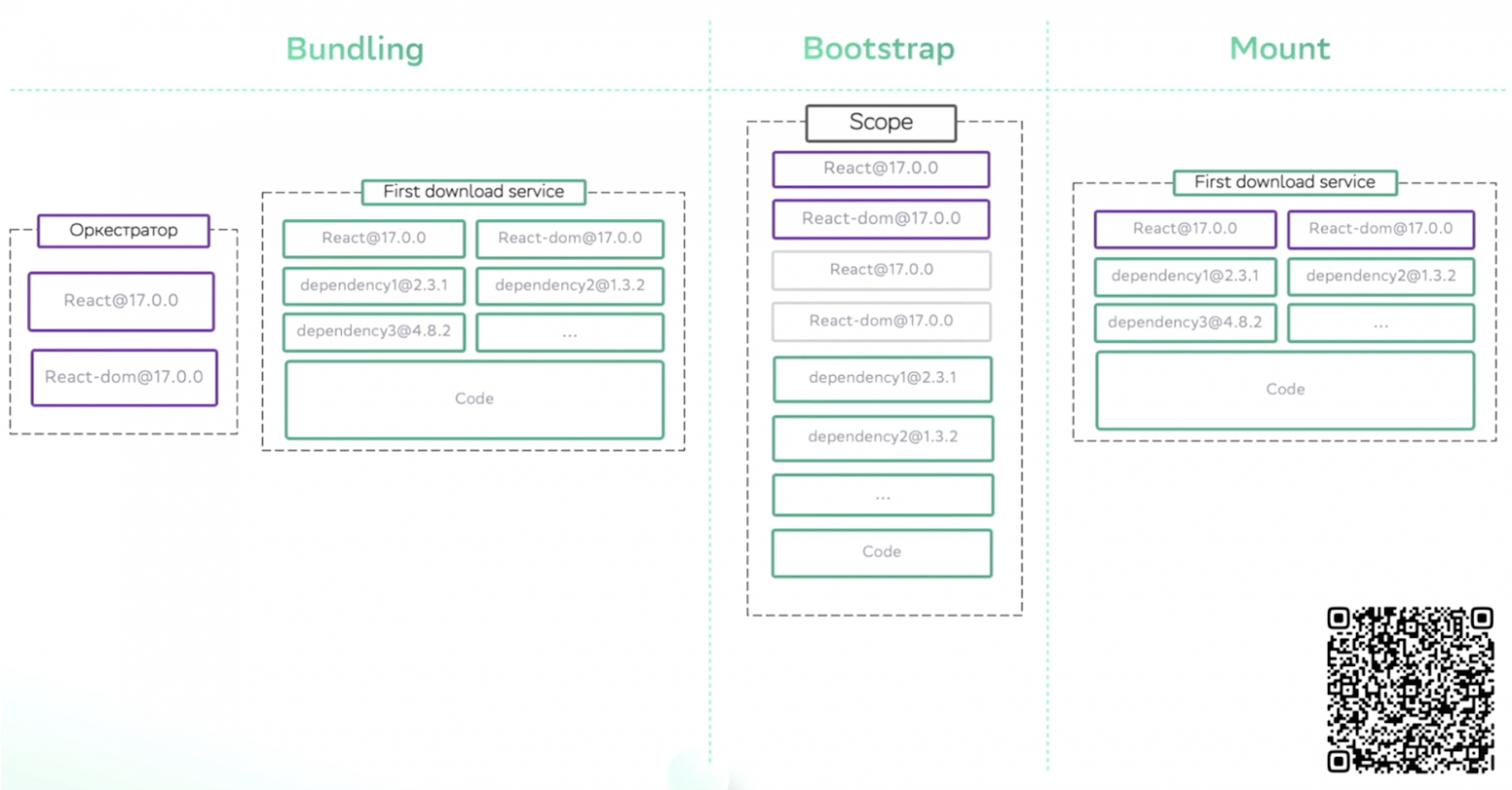
Теперь поговорим про магию Module Federation и почему авторы Module Federation говорят, что настоящая Shared dependency есть только у них, а в System JS нечто другое.
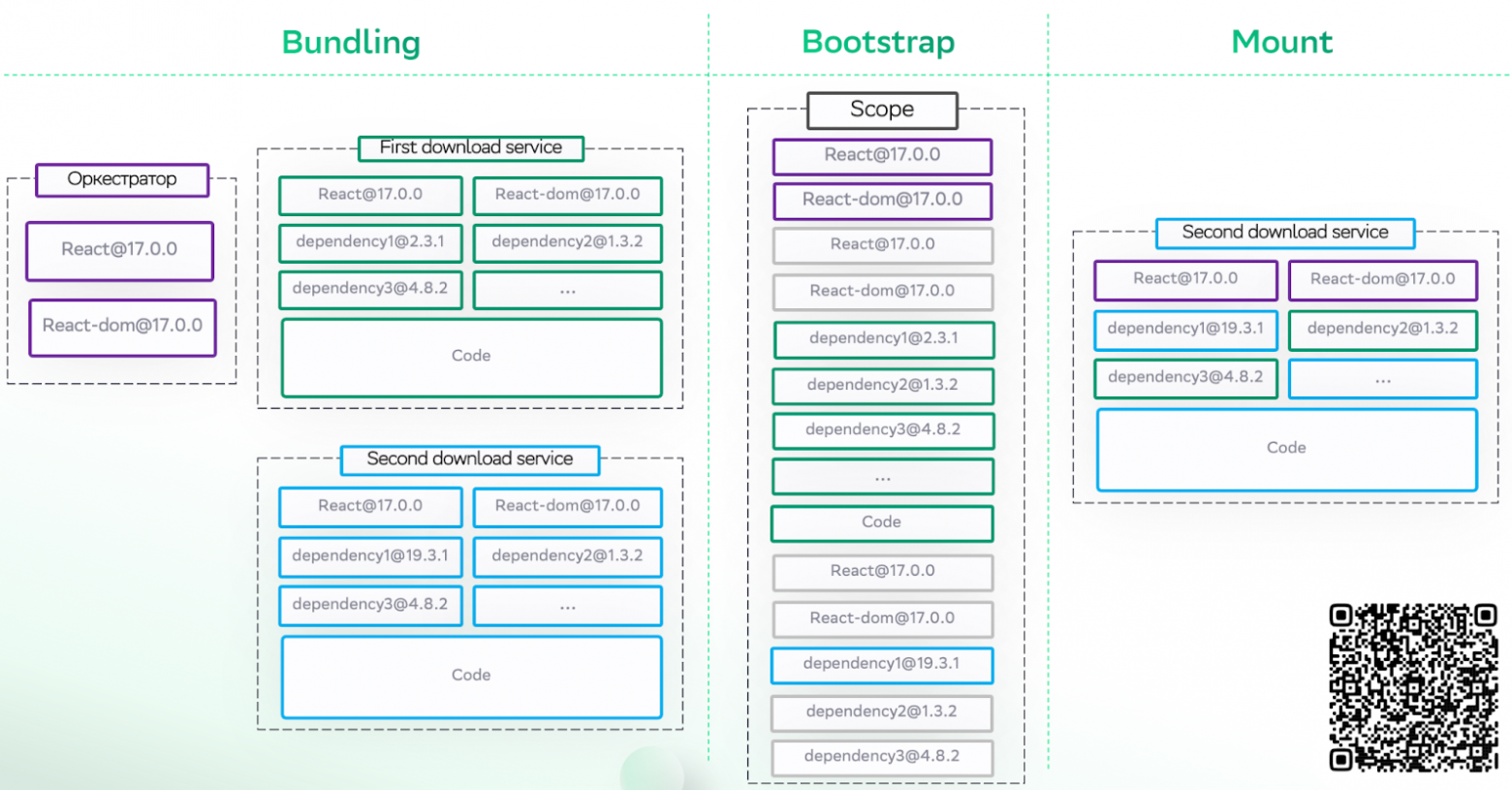
Что происходит, когда грузится второй сервис после первого? У нас есть второй сервис — там опять react и react-dom. Он его в scope не положит, потому что он был скачан до этого. Dependency 1 имеет другую версию, поэтому он снова ее дозагрузит с сервиса и положит в scope. А другие зависимости не пойдут в scope, потому что они уже были скачаны. Когда произойдет mount, получится «монстр Франкенштейна» — все библиотеки загрузятся только один раз и всё приложение соберется. Но тут тоже есть проблема, которую поймут те, кто видел шутки про node_modules. Представляете, сколько этих зависимостей у каждого сервиса? Где-то включается оптимизация, а где-то она ломается. И если произошла поломка, чинить ее будет нелегко.
Итак, различия в shared dependency: у System JS она простая, с прямолинейной логикой, поэтому никогда не сломается, но не всё будет шариться. А в Module Federation шариться будет всё и всегда, но от этого могут возникнуть проблемы.

Когда мы внедряли микрофронты, был период, когда Module Federation был в бета-версии, поэтому мы пошли в сторону System JS.
Дальше начинается второй этап — настройка оркестрации. Здесь самое популярное решение — single-spa. Хотя те, кто за Module Federation, обычно предпочитают самопис. Вы можете подробно почитать документацию single-spa здесь. Этот фреймворк занимается всей оркестрацией — загрузкой бандлов, выгрузкой стилей, лоадингом и т. п.

Гранулярность
На сколько частей стоит резать микрофронты? Об этом задумываешься не сразу, но когда всё приложение разрезано, могут возникнуть проблемы и получится, что вы выстрелили себе в ногу.
Чтобы решить эту задачу, мы взяли за основу один из базовых принципов построения микросервисных архитектур: low coupling и high cohesion. У вас должна быть слабая связь между микросервисами и сильная связь между фичами внутри микросервиса.
Если у вас сильная связь между микросервисами, то вы начинаете испытывать боль. Необходимо выкатывать в продакшен сразу два микроcервиса, и это всегда вызывает кучу проблем.
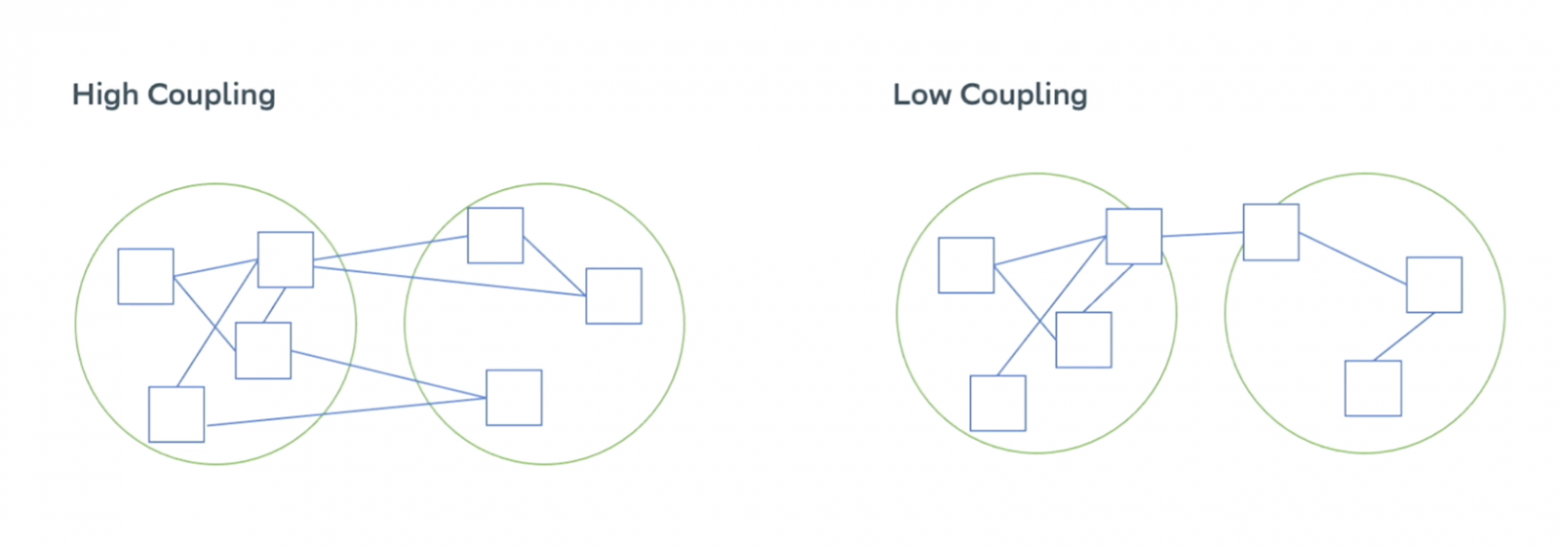
Поэтому вы всегда должны стремиться к минимальной связи. В идеале, как здесь, — к одной линии.
Почему надо стремиться к большей связи внутри микросервиса? Если у вас есть какая-то фича, которая никак не связана с остальным микросервисом, то каждый раз она будет пересобираться и окажется подвержена багам. Лучше ее вынести в отдельный микросервис.

Второе правило, которое мы взяли для себя при разрезании микросервисов — сделать максимально плоскую архитектуру. То есть не должно быть оркестратора оркестраторов и подобных жутких вещей.
Давайте для примера распилим наше приложение. На какие части можно его разделить?
У нас здесь три сервиса — header, sidebar и само бизнес-приложение.
Теперь усложним ситуацию — в header есть кнопка с колокольчиком, при нажатии на которую появляется такой поп-ап:
Стоит ли выносить его в отдельный микросервис или оставить в header? Здесь у нас маленькая связанность, поэтому можно без проблем вынести его в отдельный микросервис.
Усложним задачу еще больше: у нас есть оркестрация в core-service, а есть хранение данных. Его не стоит засовывать в оркестратор и можно выделить в отдельный микросервис, потому что у них слабая связь. Но еще у нас есть статические конфиги — они говорят, где лежит бандл для микросервиса и как настроить route. С одной стороны, они относятся к хранению, а с другой, они необходимы для сбора оркестратора. Куда же их положить?
Изначально они лежали у нас в оркестраторе, но потом мы попробовали вынести их в хранилище и столкнулись с high coupling — эти конфиги лежали в трех сервисах и приходилось одновременно их все править. В итоге мы вернули их в оркестрацию.
Также у нас есть обогащение Ajax-запросов, для которого мы создали отдельный bootstrap-сервис и поместили туда еще переключатель языка, потому что это довольно маленькая фича, чтобы поднимать для нее отдельный репозиторий.
Стандарты
Микросервисный подход — очень гибкий инструмент. У вас нет никаких ограничений по технологиям — в одном приложении могут сосуществовать React, Angular и View, вы не ограничены по code style, да и вообще никак не ограничены. С одной стороны, это хорошо (например, в момент рефакторинга). С другой стороны, когда вы пилите большое приложение, начинается стрельба себе же в ногу — появляется bus factor, приходится растить несколько команд с разными стеками, а это очень дорого.
Поэтому мы выделили шесть стандартов, которые посчитали базовыми:

Еще раз напомню наши вводные:

У нас есть гиперправило — мы идем от команды. Ни один из стандартов не будет спущен сверху, поэтому команды сами договариваются, о том, как работать одинаково. Чтобы это сделать без боли, мы использовали модель Коттера — она говорит о стадиях изменений в компании и о том, как эти изменения в компании драйвить, чтобы это было не больно и эффективно. Эта модель взята из change-менеджмента.
В ней есть восемь стадий:
Создать атмосферу безотлагательности действий.
Сформировать влиятельные команды реформаторов.
Создать видение.
Пропагандировать новое видение.
Создать условия для претворения нового видения в жизнь.
Систематическое планирование с целью достижения краткосрочных побед.
Закрепить достижения и расширить преобразования (не праздновать победу слишком рано).
Новые подходы как часть культуры.
Первая стадия — создать атмосферу безотлагательности действий. Человек так устроен, что он хватается за прошлое, и ему тяжело отпустить что-то, что он делал. Для того, чтобы это не тормозило изменения, модель Коттера рекомендует собрать всех и сказать, что дальше вы будете жить по-новому. Кто-то привлекает генеральных директоров, чтобы было внушительно, кто-то использует свою влиятельность — главное, не пропускать этот шаг.
Далее мы разработали структуру, в которой соблюдаются следующие три стадии модели (2–4). У каждого стандарта мы назначили одного code owner«а.
На первой версии ему выделяется время и он занимается R&D и изобретает стандарт. Нет никаких ограничений — как ему хочется, так он и делает. На этом этапе создается видение будущего стандарта.
Затем появляется альфа-версия стандарта. Это происходит так: code owner идет в платформенную команду (Frontend Factory), демонстрирует им свой стандарт и собирает обратную связь. Так у нас появляется новое видение и команда реформаторов, потому что платформенная команда начинает с этим стандартом себя ассоциировать. Также потихоньку начинается пропаганда нового.
Как получается бета-версия? Происходит тоже самое, что на альфа-версии, но с участием лидов бизнес-команд.
И вот наступает магия, когда стандарт демонстрируется всем фронтенд-разработчикам. Почему магия? Во-первых, к этому моменту стандарт уже очень проработанный — в нем разобраны все вопросы на предыдущих этапах. Во-вторых, лидер бизнес-команды уже ассоциирует себя с этим стандартом. Поэтому сопротивление в такой команде очень маленькое. Все дают конструктивный фидбэк и происходит пропаганда нового.

Покажу, что в итоге получается. Этот стандарт — огромная структура папок:
Итак, вы всё внедрили, все согласились с новым стандартом. Но ничего не взлетит, если не создать условия, чтобы претворить его в жизнь. Для этого каждый сотрудник должен потрогать стандарт руками, поэтому у каждого своя задача на рефактор сервиса под стандарты. Новенькие в компании должны сразу изучать этот стандарт, чтобы не появлялось нового legacy. Также у разработчика должны быть возможности исполнять данный стандарт — время и административные полномочия.
Кроме этого, стоит внести в линтеры правила по стандарту, чтобы разработчик в реальном времени видел, когда что-то делает не так. Но и этого недостаточно: одно дело, когда разработчик просто видит, что делает не так, другое — когда он замотивирован делать по-другому. То есть необходим способ отслеживания чистоты.
Далее идут еще три стадии (с 6 по 8). У нас осталось куча legacy, который нужно рефакторить. Нужно построить Roadmap конкретных шагов по миграции на новые стандарты.
Когда мы все отрефакторим, наступит седьмая стадия. На ней все должны понять, что мы реально избавились от legacy. И даже после всех этих шагов не стоит думать, что всё завершилось. Дальше нужно отслеживать соблюдение нового стандарта в течение какого-то времени, пока он не станет частью культуры. Команде должно работаться легче по новым стандартам, а не по старым.
Технический долг
Что быстрее — один подход по 20 приседаний или 20 подходов по одному приседанию? Логически кажется, что один поход. Но давайте добавим условия из реальной жизни:

20 приседаний нельзя сделать за один спринт. А какой продакт-менеджер даст нам делать приседания целых два спринта? А если вы давно не приседали и не можете физически присесть 20 раз подряд? Или у бизнеса очень ограниченное время и лучше сделать хотя бы одно приседание, чем вообще ни одного? Получается, что в жизни 20 подходов по одному приседанию получаются быстрее.
К чему я это? Микрофронты позволяют поставлять тех. долг посервисно. Вы можете прийти в один микросервис, порефакторить, потом в другой, и так постепенно поставлять техдолг. Но действительно ли мы можем сделать только одно приседание?
Разберем пример: у нас есть задача — подтянуть в старый UI kit кнопку из очень свежего UI kit«а:
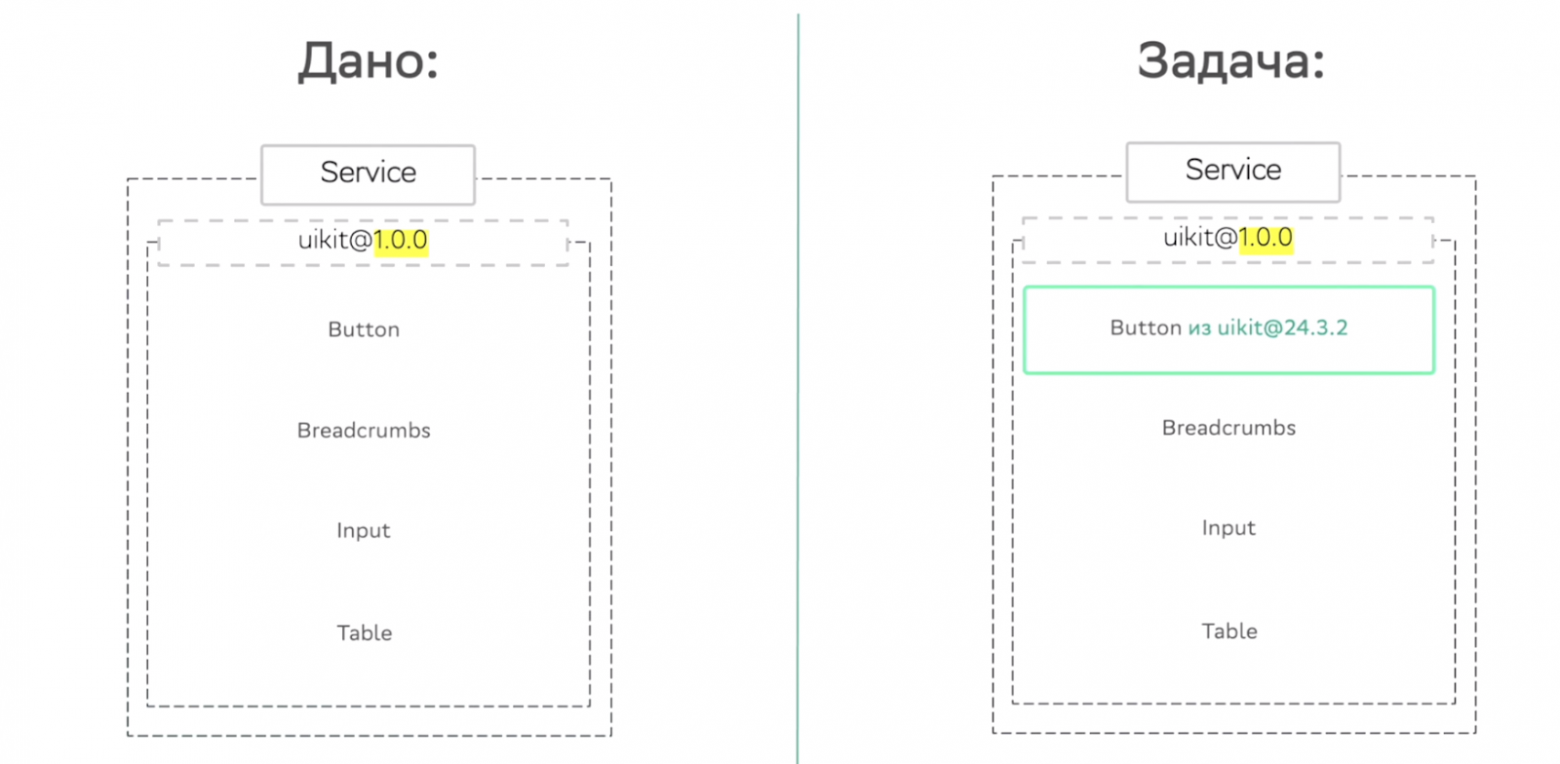
Вместо того, чтобы подтянуть кнопку и выполнить задачу, мы начнем рефакторить все компоненты. А это может занять очень много времени, даже больше спринта. Поэтому UI kit мы тоже распилили на отдельные пакеты — кнопки, поля, таблицы и т. д.
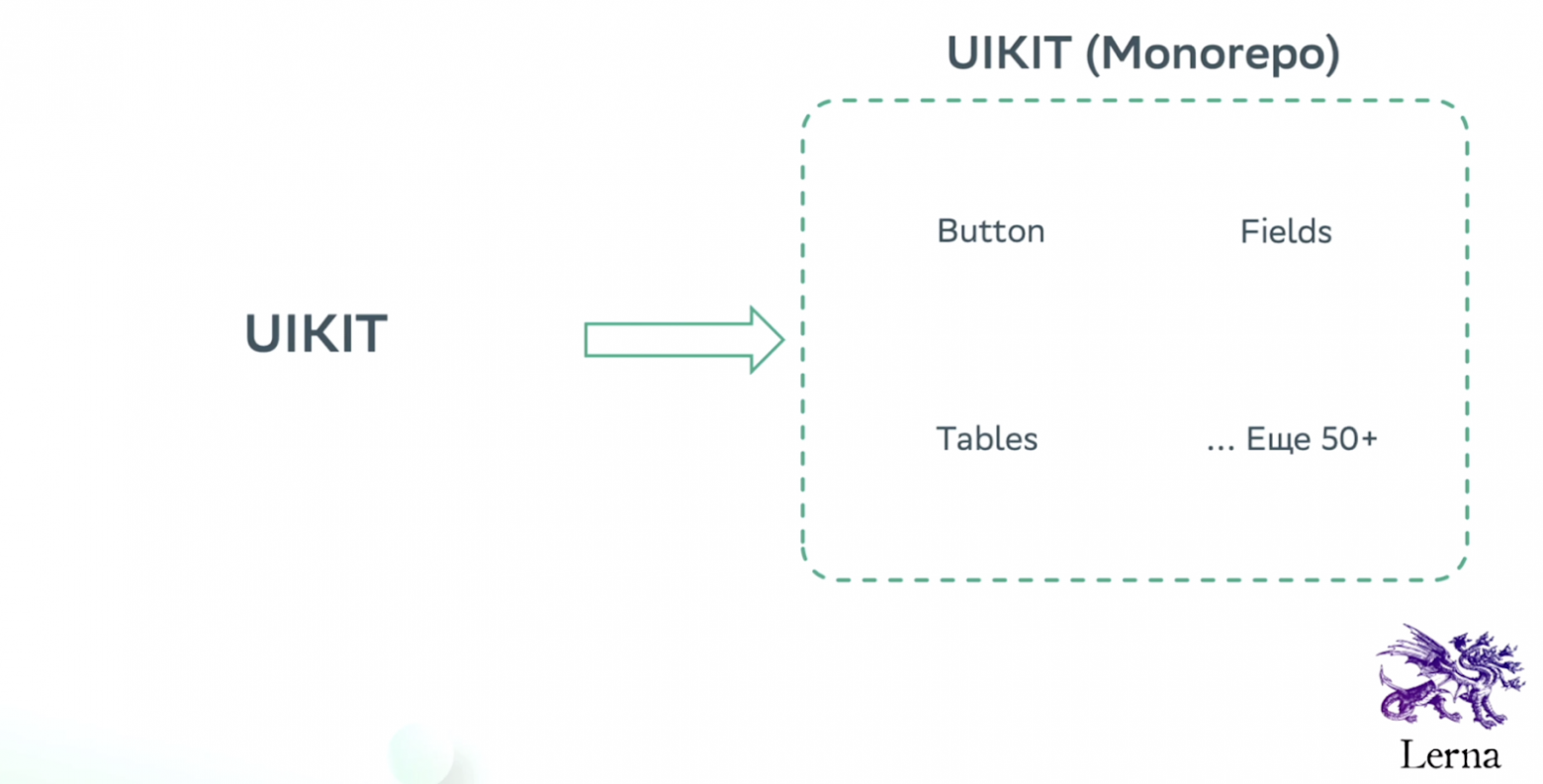
Так мы сможем обновить только кнопку, не трогая всё остальное. Менеджерим мы это с помощью Lerna. Кстати, на эту тему есть хороший доклад с HolyJS — «Вытягиваем монорепку».
Boilerplate
Микросервисы отличаются от монолита тем, что у вас получается очень много Boilerplate, который надо переиспользовать. У нас есть четыре разных микросервиса:

Это четыре разных приложения, каждое со своей кодовой базой. И чтобы не разрабатывать четыре раза одну и ту же кнопку, вам понадобится как минимум UI kit.
Однако UI kit«а недостаточно, потому что у вас еще появляются общие функции, хуки, конфиги. Представьте, если бы у вас были разные линтеры в каждом микросервисе — толку от них было бы ноль. Для всего этого тоже создана библиотека. Мы ее назвали Frontend Tools. Она содержит несколько репозиториев внутри, которые занимаются конфигами и функциями.

Но этого тоже недостаточно. Я надергал из бизнеса четыре сервиса — вот их «хлебные крошки»:

И у них всех есть что-то общее. Это просто пример: есть много такой логики, которая с одной стороны, не подходит в общие библиотеки, с другой стороны — должна переиспользоваться между микросервисами. Поэтому наклевывается еще несколько «монорепок»:

По этому пути можно пойти, но может случиться вот что: все команды начнут разрабатывать в бизнесовых UI kit«ах и Frontend Tools, потому что это проще — не надо думать над универсальной логикой. Вы просто пришли, быстро накодили и потом переиспользуете. Поэтому, если пойти по такому пути, то не будет драйва на улучшение основных библиотек. Из-за этого мы не стали у себя делать Business UI kit, потому что любой компонент можно разделить на логику и view.
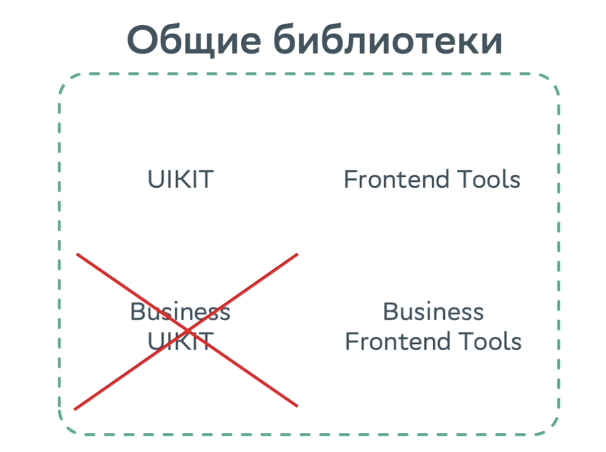
Если вы всё же решите делать Business UI kit, то должна быть команда, которая из него будет выдергивать новые компоненты в основной UI kit.
Следующий «бойлерплейтный» момент — это создание нового сервиса.
В нашем сервисе очень много файликов, и каждый раз держать в голове — очень тяжело. Поэтому мы пошли в сторону GitLab Templates. С их помощью можно вынести всю логику в шаблоны и за 15 секунд создавать новые сервисы, только перенастроив конфиги.

Dependency
Напомню немного вводных: у нас одно приложение, 81 микросервис и больше 2000 зависимостей.

В чем тут проблема? Для нас здесь — 81 микросервис, а для пользователя — одно приложение. То есть ему неважны микросервисы, монолиты и прочее. И если ваши микросервисы будут сильно отличаться друг от друга, у пользователя будет большая когнитивная нагрузка. Одна и та же кнопка не может в трех местах выглядит по-разному.
Поэтому все эти зависимости мы договорились обновлять один раз в спринт. Решение, конечно, не очень приятное
