Микрочипы становятся непредсказуемыми по мере уменьшения техпроцесса
Инженеры Google и Facebook предположили, что постоянное уменьшение размеров техпроцессов в сочетании с возрастающей сложностью архитектурного проектирования приводит к снижению надёжности микросхем.

Микроэлектроника выходит из строя из-за перегрева, интенсивного использования компьютера, перепада напряжения, механического воздействия, неисправности материнской платы и огрех при проектировании и сборке. Тем не менее, частота появления ошибок до этого не вызывала сильного беспокойства по поводу надёжности микросхем у производителей электроники и её пользователей.
В последние годы инженеры фиксируют рост числа неполадок, связанных с работой процессоров. Например, устройства выявляли несуществующие ошибки в крупных хорошо отлаженных приложениях. Дополнительная диагностика приложений не подтверждала наличие ошибок.
Инженеры Google занялись изучением задействованных кодов и операционной телеметрии своих устройств. В результате они обнаружили больше ошибок, чем ожидали. Ошибки носят случайный, спорадический характер и проявляются не на целых микросхемах или семействах компонентов, а на отдельных ядрах спустя много времени после начала эксплуатации процессора. По мнению инженеров, неполадки появляются из-за «неустойчивых ядер», время от времени совершающих ошибки в расчётах. Специалисты утверждают, что выявленные неполадки не связаны с архитектурой микросхем, и их нельзя обнаружить во время производственных испытаний.
В феврале этого года Facebook опубликовала статью, где приводит пример проявляющейся от случая к случаю ошибки. По словам инженеров, подобное искажение в дата-центрах встречается им всё чаще. Такие ошибки трудно обнаружить и исправить.
Инженеры Facebook приводят пример из практики. В крупных инфраструктурах незадействованные в работе файлы сжимаются. Программа распаковывает их, когда поступает запрос на чтение. Перед распаковкой программа проверяет размер файла: он должен быть больше 0. В примере из статьи алгоритм показал нулевое значение для файла ненулевого размера, из-за чего файл не попал в распаковку базы данных. В результате совершившая запрос инфраструктура сообщает о потере данных при распаковке.
В системах большого масштаба обнаружить и воспроизвести подобный сценарий сложно, поэтому инженеры работали с одним устройством. Затем инженеры обнаружили, что ошибка носила единичный характер при многопоточной рабочей нагрузке и постоянный при однопоточной нагрузке для определенного подмножества значений данных на одном конкретном ядре устройства.
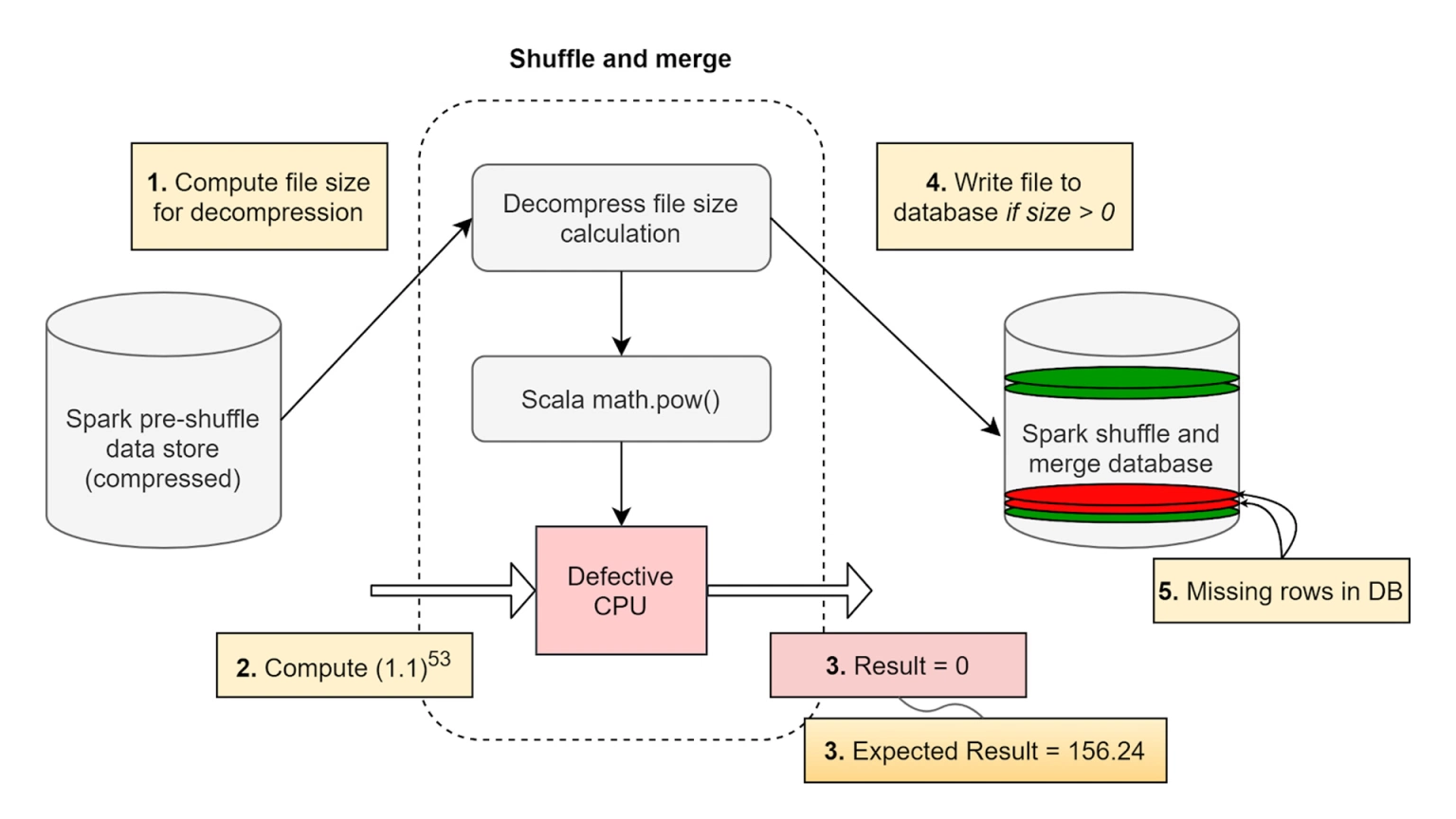
После нескольких повторений на устройстве исследователи поняли, что вычисление Int (1.1^53) в качестве входных данных для функции math.pow в Scala всегда выдаёт результат 0 на ядре 59 процессора. Когда они заменили вычисление на Int (1.1^52), программа выдала ожидаемый результат 142.
Приведённая выше диаграмма показывает поток первопричин. Неправильный результат приводит не только к нулю в качестве результата Инженеры определили, что вычисления влияют на положительные и отрицательные степени для конкретных значений данных.
Примеры ошибок: Int [(1.1)^3] = 0, расчётный = 1; Int [(1.1)^107] = 32809, расчётный = 26854; Int [(1.1)^-3] = 1, расчётный = 0.
В реальном приложении эта ошибка приводит к распаковке файлов с неправильными размерами и некорректной меткой end of file, из-за чего данные терялись или повреждались. По словам инженеров, им трудно определять подобные проблемы по причине прямой зависимости от корректности работы процессора.
Инженеры Google столкнулись со схожими ошибками и назвали её проблемой «неустойчивых ядер». 2 июня они опубликовали статью на эту тему.
Специалисты назвали найденные в ядрах ошибки CEE (ошибка выполнения с искажениями — corrupt execution error). Незаметные CEE затрагивают работу отдельных ядер, а не всего чипа. Они появляются незаметно и постепенно выводят устройство из строя.
Примеры ситуаций, при которых инженеры сталкивались с CEE:
Нарушения семантики блокировки, приводящие к повреждению данных приложений и сбоям.
Повреждение данных, вызванное различными операциями загрузки, хранения, направления и когерентности.
Неправильное вычисление AES: шифрование и дешифрование в одном и том же ядре выполняли функцию идентификации, но дешифрование в другом месте выдавало тарабарщину.
Повреждение, влияющее на сборку мусора в системе хранения и приводящее к потере данных в реальном времени.
Повреждение индекса базы данных, приводящее к тому, что некоторые запросы, не зависящие от того, в каком ядре происходит обработка, повреждены.
Повторяющиеся битовые сдвиги в строках в определенной позиции бита (что вряд-ли появилось в результате ошибок в коде).
Повреждение ядра, приводящее к сбоям в работе процессов и приложений.
В своей работе Google пытается объяснить причины появления этих ошибок. Производители приближаются к пределам масштабирования чипов и усложняют архитектуру устройств. Из-за этого инженерам приходится дорабатывать и усложнять методы диагностики, что всё равно не гарантирует отсутствие случайных ошибок. Размеры кремниевых элементов измеряются в нанометрах. Это сужает поле для ошибок, но повышает риск сбоев при перегреве. Кроме того, наложение слоёв увеличивает сложность структуры и производственные риски. Повышение сложности приводит к специфическому поведению CEE при общей правильной структуре ядра.
Инженеры Google отмечают сниженную эффективность диагностики при работе с крупномасштабными структурами. Они утверждают, что эта проблема со временем будет только усугубляться, и пока нет эффективного метода диагностики случайных ошибок в «неустойчивых ядрах».
Специалисты отмечают, что их работа основана на анализе поведения реальных микросхем, а не исследованиях происходящих в них физических и химических процессов. Они хотят разработать симуляторы процессора и загрузить в них разные виды незаметных CEE. Таким образом инженеры планируют разработать эффективные методы диагностики ошибок и устойчивые к CEE алгоритмы.
На данный момент инженеры планируют работать совместно с разработчиками над повышением надёжности оборудования:
Производство программ для тестирования процессоров и поиск ядер с незначительными производственными дефектами. После передача этих тестовых характеристик конечным пользователям.
Непрерывная проверка, при которой функциональные подразделения всегда проверяют свои собственные результаты.
Консервативное проектирование критически важных функциональных блоков с учётом дополнительной площади и мощности для обеспечения надёжности.
