Мифы о CAP теореме
Введение

Давно хотел написать про мифы о CAP теореме, но как-то все не доходили руки. Однако, почитав очередной опус, схватился за голову и решил разложить все по полочкам, чтобы в мозгах возникла стройная картина.
Событие, когда какая-то статья вызывает бурю эмоций, — крайне редкое. Первый раз такое возникло, когда я прочитал про chained replication. Меня пытались убедить, что это мощный подход и что это лучшее, что могло произойти с консистентной репликацией. Я сейчас не буду приводить доводы, почему это плохо работает, а просто приведу говорящую цитату из статьи Chain Replication metadata management:
Split brain management is a thorny problem. The method presented here is one based on pragmatics. If it doesn«t work, there isn«t a serious worry, because Machi«s first serious use case all require only AP Mode. If we end up falling back to «use Riak Ensemble» or «use ZooKeeper», then perhaps that«s fine enough.
В моем вольном пересказе это означает примерно следующее: «У нас тут есть некий алгоритм. Мы не знаем, будет ли он работать правильно или нет. Да нам это и не важно». Хотя бы честно, сэкономило кучу времени, спасибо авторам.
И тут, значит, попадается на глаза статья: Spanner, TrueTime & The CAP Theorem. Её мы разберем по полочкам ближе к концу, вооружившись понятиями и знаниями. А перед этим разберем самые распространенные мифы, связанные с CAP теоремой.
Миф 1: A означает доступность
A, конечно же, образовалось от слова Availability, что означает доступность. Но какая это доступность? Какого рода?
Доступность в разных контекстах означает разное. И тут надо различать как минимум 2 разных контекста, в которых она употребляется:
- Доступность реального сервиса. Эта доступность выражается в процентах: измеряется общее время простоя в течении года и составляется соотношение, выраженное в процентах, говорящее о вероятности доступности в течении длительного времени.
- Доступность в рамках модели теоремы CAP.
В теореме CAP используется понятие, наиболее близкое по смыслу к термину полная доступность (total availability):
For a distributed system to be continuously available, every request received by a non-failing node in the system must result in a response.
Что означает примерно следующее: «любая неупавшая нода в системе должна ответить на запрос». В этом определении есть несколько моментов, которые я хотел бы подчеркнуть:
- «Неупавшая». Понятно, что упавшая нода никак не может ответить. Однако загвоздка состоит в том, что если все ноды упали, то с точки зрения определения такой сервис является доступным. В принципе, можно исправить определение, дополнив обстоятельством, что клиент должен получить ответ.
- «Должна ответить». Теорема не говорит, когда именно. Её вообще не интересуют временные параметры. Понятно, что нода не может ответить мгновенно. А раз не может, то достаточно, чтобы ответила когда-то.
С точки зрения пользователя, если у нас было 100 нод и 99 упали, а оставшаяся одна продолжает отвечать со скоростью один запрос в час, то такой сервис вряд ли можно назвать доступным (это контекст 1). Однако с точки зрения CAP теоремы тут все нормально и такая система будет являться доступной (контекст 2).
Поэтому A — это не доступность в общепринятом понимании, а так называемая полная доступность, которая пользователю может быть совсем неинтересна.
Миф 2: P означает устойчивость к сетевому разделению
Такое определение можно встретить практически во всех статьях. Чтобы понять, что тут не так, надо взглянуть на проблему под другим углом.
Возьмем любую систему, которая обменивается сообщениями. Рассмотрим то, как сообщения передаются между акторами — объектами системы. Эти сообщения могут либо доходить до другого актора, либо не доходить. И тут надо различать 2 случая:
- В системе невозможна ситуация, когда сообщения теряются.
- В системе возможна ситуация, когда сообщения теряются.
Нетрудно догадаться, что этот список исчерпывающий. В этом месте стоит обратить внимание, что каждый пункт описывает свойства системы. Т.е. мы еще даже не дошли до алгоритма. Это будет иметь далеко идущие последствия.
Если мы рассмотрим первый случай, когда сообщения никогда не теряются, то это означает, что в такой ситуации сетевое разделение (network split) просто невозможно. Действительно, раз каждое сообщение от каждого актора может дойти без потерь, то нет смысла говорить о сетевом разделении. Во втором случае все наоборот: из-за потерь возможна ситуация, когда целый сегмент отделился от другого, т.е. произошла потеря связности между группой акторов. В этом случае говорят, что случилось сетевое разделение.
Надо отметить, что свойство возможности изоляции групп акторов друг от друга есть прямое следствие выполнения пункта 2.
Если мы работаем с реальной сетью, то она, как нетрудно догадаться, подпадает под 2-й пункт. При этом мы еще не начали думать про алгоритм, а у нас уже появилась способность к разделению и потери связности между группами акторов. P — именно про это, что в системе возможно расщепление. И это — не свойство алгоритма, а свойство системы, в которой работает алгоритм.
Почему вообще в случае наличия потерь сообщений важно рассматривать именно сетевое разделение? Потому что остальные проблемы не вызывают столько хлопот и проблем, сколько порождает расщепление системы на независимые части.
В заключении этого мифа приведу цитату из блога Aphyr: Percona XtraDB Cluster:
Partition tolerance doesn«t require every node still be available to handle requests. It just means that partitions may occur. If you deploy on a typical IP network, partitions will occur; partition tolerance in these environments is not optional.
Таким образом, если мы рассматриваем систему, которая работает с реальной ненадежной сетью, то нарушения сетевой связности — это не исключительная ситуация, а то, с чем приходится иметь дело. И буква P в данном контексте всего лишь означает, что в системе возможно нарушение сетевой связности.
Миф 3: систем AC не существует
Из предыдущего мифа может возникнуть ощущение, что систем AC не существует, т.к. не существует надежных сетей, способных передавать данные. На это можно сразу попытаться предложить схему с резервированием компонент. Однако если вероятность потери пакета в линии >0, то как бы мы не добавляли каналов, вероятность не может стать =0 чисто из математических соображений. А раз так, то, согласно описанному выше, может быть сетевое разделение (network split).
Но кто сказал, что CAP описывает исключительно системы, связанные сетью? CAP — это теоретическая модель, которая может применяться к очень широкому классу задач. Например, можно взять многоядерный процессор:
- Каждое ядро — это отдельный актор.
- Акторы (ядра) обмениваются сообщениями (информацией).
Этого достаточно, чтобы говорить об CAP теореме.
Давайте обсудим сначала A. Есть ли доступность ядер? Безусловно, да, в любой момент времени можно обратиться к любому ядру и получить любые данные, которые мы захотим, из памяти.
Что по поводу P? Процессор гарантирует, что данные будут переданы без проблем другому ядру в случае необходимости. Если этого по каким-то причинам не происходит, то такой процессор считается бракованным. Таким образом, буква P отсутствует.
Вопрос с консистентностью также решается следующим образом. В модели памяти определена sequential consistency, что является самым высоким уровнем консистентности в такой системе. При этом внутри процессора как правило реализуют протоколы когерентности кэшей наподобие MESI или MOESI, обеспечивая тем самым заданный уровень консистентности.
Таким образом, современный процессор представляет собой систему AC с гарантированной доставкой сообщений между ядрами.
Миф 4: C означает консистентность
C без сомнения означает консистентность. Однако какую консистентность? Ведь eventual consistency — это тоже консистентность, только крайне слабая. Так что тут имеется в виду? Моделей консистентности много, достаточно взглянуть на диаграмму из статьи Consistency in Non-Transactional Distributed Storage Systems:
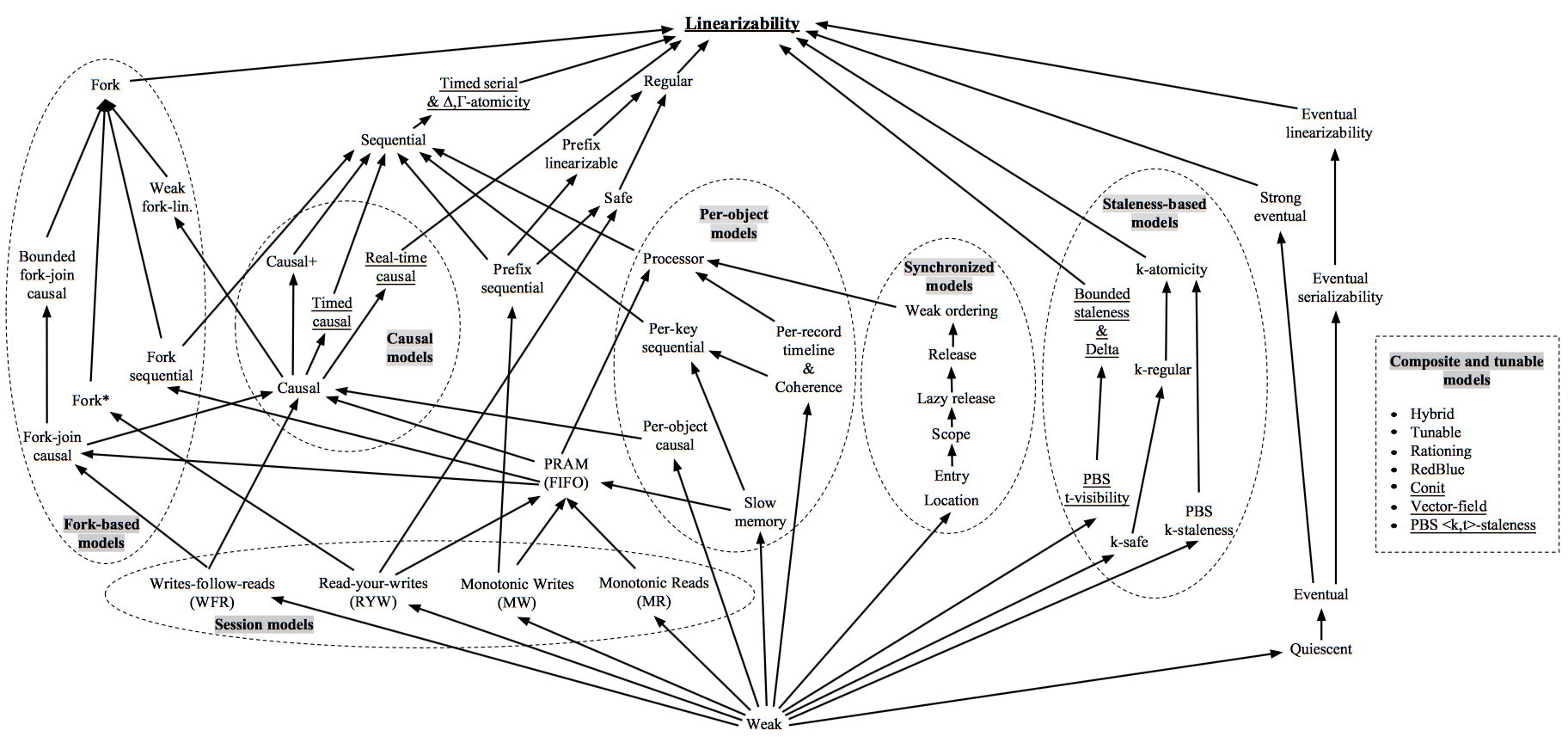
И это только про распределенные нетранзакционные системы! Если добавить в рассмотрение транзакционность, то можно сразу похоронить идею о том, чтобы разобраться в этом, так ни разу и не начав.
В оригинальной статье про CAP теорему речь везде шла про линеаризумость. Суть линеаризуемости, если вкратце, следующая. Если произошло какое-либо действие (не важно, чтение, запись, или смешанное действие или действия), то результат этого действия доступен сразу после того, как мы получили ответ.
Возникает закономерный вопрос:, а что с другими моделями консистентности? Подпадают ли они под CAP теорему?
И тут начинается полная каша в головах. Некоторые думают, что раз модель доказана для линеаризуемости, то и применять ее стоит строго и исключительно для линеаризуемости. Другие думают, что любая более слабая модель консистентности уже не подпадает под эту теорему. Третьи вообще не понимают, в чем суть обсуждения.
Для ответа на этот вопрос рассмотрим замечательную картинку, взятую из статьи Highly Available Transactions:
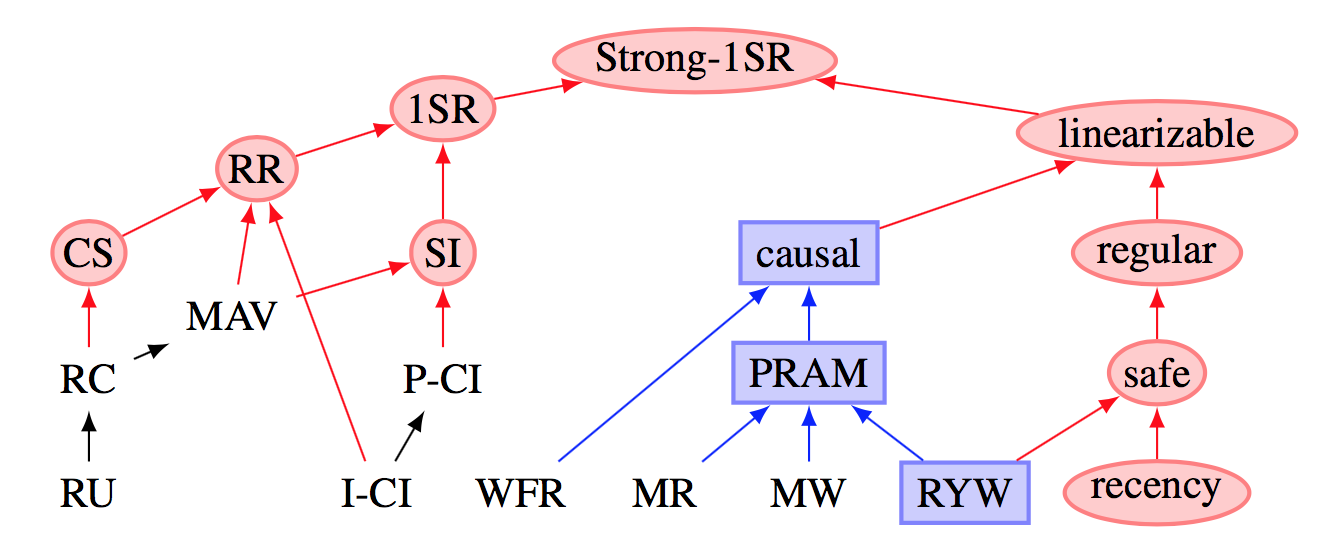
О чем она говорит? Красным помечены так называемые модели недоступности, которые работают в рамках CAP теоремы. Т.е. одновременно с ней нельзя достичь A и P одновременно. Однако присутствуют другие модели, обладающие достаточным уровнем консистентности для ряда задач, которые тем не менее могут одновременно выполняться совместно с AP, получая систему CAP без всяких скидок. Типичный пример: Read Committed (RC) и Monotonic Atomic View (MAV) допускают соблюдение одновременно всех трех букв в CAP, при этом сложно назвать такие модели неконсистентными. Такие модели консистентности, для которых нарушается CAP-теорема, называют высокодоступными (highly available models).
Таким образом, говоря об консистентности, имеется в виду широкая группа моделей консистентности, называемых недоступными моделями (unavailable models).
Миф 5: системы CP не являются высокодоступными
После предыдущего пункта это утверждение кажется вполне логичным, но в корне неправильным. Напомню, что A означает полную доступность, а не доступность в рамках девяток. Возможно ли сделать систему CP высокодоступной?
Тут следует разделять модель и железо, т.е. теорию и реальность.
Давайте рассуждать сначала в рамках модели. Доступность в рамках CAP теоремы означает полную доступность, т.е. любая живая нода должна ответить. Однако зачем вообще нужно такое? Ведь логику клиента мы можем написать совершенно по-другому. Предположим, что у нас есть 3 ноды, расположенных в разных датацентрах. Мы пишем на кворум из 2-х нод, при этом 1 нода может прилечь без потери живучести и консистентности всей системы. А читаем мы всегда из 2-х любых нод. При этом если одна нода прилегла, то другая нода даст правильный ответ. Если придет 2 разных ответа, то мы можем выбираем наиболее свежий. Таким образом, если в этой системе гарантируется, что только одна нода может быть неработоспособна в любой промежуток времени, то система будет с точки зрения клиента полностью 100% доступна как на чтение, так и на запись. Причем консистентно.
В реальности всегда существует ненулевая вероятность того, что приляжет не одна, а 2 или более нод. В этом легко убедиться, т.к. если есть ненулевая вероятность падения одной ноды, значит будет и ненулевая вероятность падения другой ноды или нод. Более того, падение — это не самое плохое, что может случиться. Помимо отказов оборудования, может еще быть потеря связности, т.е. поломка разнообразного сетевого оборудования, включая магистральное оборудование. Я думаю, не стоит напоминать о том, что все это имеет ненулевую вероятность. Все эти вероятности складываются, давая лишь некоторое, иногда очень малое, количество девяток. Понятно, что чем больше резервирование узлов, тем большее количество девяток можно получить. И это я еще не принял в рассмотрение саму программу, которую пишут программисты с ненулевой вероятностью внесения ошибки…
Т.е. в теории мы имеем, что правильно написанный клиент может добиться 100% доступности, а на практике мы всегда имеем меньшее число. Вся наука состоит в том, чтобы добиться как можно большего количества девяток. И в этом аспекте CAP теорема полностью бесполезна. Потому что она вообще про другое.
Поэтому идея, а высокой доступности нисколько не противоречит тому, что это не A, а значит CP может быть высокодоступной.
Миф 6: системы CP обладают низкой производительностью, высокой латентностью и плохо масштабируются
Очевидно, что чем более высокий уровень консистентности, тем менее производительна система. Вопрос возникает в том, насколько будет просадка в производительности и будет ли она являться критичной для наших процессов.
Оказывается, что даже strict consistency или Strong-1SR (самый высокий уровень консистентности) возможно использовать в системах реального времени. У меня есть экспериментальное доказательство этого факта, но тут я приведу ряд некоторых практичных аргументов в пользу него.
Идея заключается в том, чтобы использовать множество независимых отказоустойчивых сущностей. Их можно запускать где угодно, они работают параллельно, а их количество фактически ограничено размером кластера. Поверх этих сущностей создается транзакционный слой, который связывает работу этих сущностей воедино. Именно так работает Spanner и многие другие системы. Таким образом достигается масштабируемость и быстродействие.
Миф 7: системы AP легко использовать за счет того, что они хорошо масштабируются
Системы с AP допускают более простое масштабирование, однако только в теории. В реальности все равно в той или иной степени приходится решать вопросы консистентности. Практика показывает, что написать клиентский код на основе такой системы — задача крайне нетривиальная, а иногда и вообще недостижимая. Причина в том, что если система не предоставляют каких-то базовых гарантий по консистентному хранению данных, то последующая обработка превращается в очень увлекательную шараду: применилась ли операция? увидят ли ее пользователи?, а что они увидят? можно ли получить консистентный срез данных? будут ли видеть разные клиенты одинаковый набор данных? и т.д.
Т.е. не смотря на относительную простоту создания таких систем, сложность её использования возрастает многократно.
Разбор статьи
Ну, а теперь приступим к разбору статьи Spanner, TrueTime & The CAP Theorem. Первое, на что стоит обратить внимание:
The CAP theorem [Bre12] says that you can only have two of the three desirable properties of:
- C: Consistency, which we can think of as serializability for this discussion;
- A: 100% availability, for both reads and updates;
- P: tolerance to network partitions.
Первое, на что стоит обратить внимание — ссылка [Bre12] под названием CAP Twelve Years Later: How the «Rules» Have Changed, датированной маем 2012 года. Почему выбрали ссылку не на оригинальную статью — мне неведомо. Более того, это статья про обсуждение CAP теоремы, а не про вывод самой теоремы.
Про буквы C, A и P мы уже обсуждали, не буду останавливаться. Далее:
Once you believe that partitions are inevitable, any distributed system must be prepared to forfeit either consistency (AP) or availability (CP), which is not a choice anyone wants to make.
Первая часть звучит вполне разумно в рамках наших обсуждений, однако после AP & CP следует странное, т.к. внезапно оказывается, мы не хотим делать такой выбор. Почему мы не хотим делать такой выбор, в статье не написано. Зато потом написаны правильные слова:
The actual theorem is about 100% availability, while the interesting discussion here is about the tradeoffs involved for realistic high availability.
Казалось бы, на этом можно было бы остановиться и сказать, что Spanner — это система CP с доступностью 99.9…%, поставив на этом точку. Но нет, автора дальше несет и он пишет подзаголовок:
Spanner claims to be consistent and available.
Spanner claims to be consistent and highly available, which implies there are no partitions and thus many are skeptical.
Как я показывал выше, так называемая высокодоступность (highly available) вовсе не означает A, и тем более не означает отсутствие P. После этого начинается словесная эквилибристика, т.к. из ошибочного посыла можно вывести множество забавных суждений. Автору очень хочется, чтобы система была и C и A одновременно, ведь P пользователю не нужно от слова совсем. При этом вводится новое понятие: effectively CA. Такое ощущение, что автор заигрался с понятиями и начал выдумывать новые без какого-либо определения, т.к. старые плохо описывали такую замечательную систему.
Читаем далее:
Based on a large number of internal users of Spanner, we know that they assume Spanner is highly available.
Сама по себе фраза замечательна. Оказывается, что если внутренние пользователи скажут: «мы предполагаем, что она высокодоступна», то отсюда сразу что-то следует о самой системе. Ладно бы, если бы пользователи заявляли: «да, она высокодоступна», тут же вообще про то, что они лишь предполагают.
Далее следует феерическое:
If the primary causes of Spanner outages are not partitions, then CA is in some sense more accurate.
Т.е. если у нас происходит сбой, не связанный с нарушением сетевой связности, то тогда такую систему более точно в некотором смысле (!) стоит называть как CA.Т. е. если вероятность других сбоев больше, чем нарушение связности, то P нет. В таком смысле стоит понимать эту фразу?
Далее приводятся маркетинговые измышления, что мы построили сверхнадежную систему, подтверждаемые графиками. Чуть ниже наконец-то приводится определение, раскрывающее значение совокупности слов effectively CA:
… to claim effectively CA a system must be in this state of relative probabilities:
- At a minimum it must have very high availability in practice (so that users can ignore exceptions), and
- as this is about partitions it should also have a low fraction of those outages due to partitions.
Spanner meets both.
Т.е. система должна:
- иметь high availability на практике, причем пользователи могут игнорировать исключения, и
- вероятность сетевого разделения должна быть меньше других проблем.
Сразу возникает вопрос:, а каков уровень high availability достаточен на практике? 5 девяток? 6 девяток? А может все 9? Тут виден некоторый произвол, не позволяющий однозначно судить о принадлежности к этому свойству. Ну и «игнорирование пользователем исключений» довершает всю двусмысленность и неоднозначность этого, страшно сказать, определения.
Как видно, такое определение не подпадает под модель, которая используется непосредственно в CAP теореме. Тут вообще непонятно, к какой модели это относится. Это скорее про экспериментальные наблюдения, а не про теоретическую модель. И связи между экспериментом и теорией в статье не прослеживается.
Не буду долго расписывать другие аспекты статьи. Скажу лишь, что ряд абзацев вполне заслуживает того, чтобы их почитать, например «What happens during a Partition».
Заканчивают авторы следующим великолепным пассажем:
Spanner reasonably claims to be an «effectively CA» system despite operating over a wide area, as it is always consistent and achieves greater than 5 9s availability.
Ну да, если мы определим, что наша система — это X, то наша система будет обладать свойствами X. Здорово, правда? Только никакого отношения такое определение к CAP теореме не имеет. Это надо четко осознавать. Авторам, видимо, ну очень хотелось, чтобы не было P, а были 2 другие буквы, т.к. пользователь именно за них и платит. Почему их не устроило CP с высокой доступностью — мне неведомо.
Even then outages will occur, in which case Spanner chooses consistency over availability.
Что явно противоречит системе CA: в такой системе не делается никакого выбора, т.к. выбираются оба свойства, как мы это видели выше в примере с CA. Наличие такого утверждения говорит как раз о том, что это точно не CA. Не ожидал я увидеть взаимоисключающие параграфы в такой статье.
Миф последний: CAP теорема устарела
Популярность этой темы привело к тому, что многие перестали понимать значения терминов, они стали размываться, выхолащиваясь до совсем уже вульгарного понимания. Спекуляция на терминах, переопределение и непонимание — вот неполный перечень родовых пятен этой многострадальной теоремы.
На волне популярности маятник качнулся в другую сторону, и про эту теорему стали немножко забывать. Стали появляться статьи про то, что, дескать, CAP теорема устарела и просят остановить её использование. Другие пытались покритиковать и внести свою лепту в закапывание и переиначивание смыслов. Даже сам автор теоремы начинает подменять понятия и искажать первоначальный замысел.
Подобные выпады в сторону теоремы снова и снова лишь подчеркивают её актуальность, обнажая новые, доселе неизвестные, грани.
Заключение
В свое время, знакомство с CAP теоремой достаточно хорошо протрезвляло мозги. Ведь теоретическая невозможность создания определенного вида систем давала основания для того, чтобы не заниматься на практике решением неразрешимых задач и концентрироваться на решении задач определенного класса. В контексте распределенных систем имеет смысл говорить лишь о задачах AP или CP.
Подобного рода теоремы не устаревают, как не может устареть классическая механика, несмотря на наличие релятивистских эффектов или квантовой механики. Просто она должна найти свое достойное место, надо о ней помнить и идти дальше. А все дело в том, что эта теорема является лишь частным случаем более общего фундаментального свойства:
The CAP Theorem, in this light, is simply one example of the fundamental fact that you cannot achieve both safety and liveness in an unreliable distributed system.
Т.е. CAP теорема — это просто один из примеров фундаментального факта, что невозможно достичь одновременно безопасности и живучести в ненадежной распределенной системе.
- C: Безопасность
- A: Живучесть
- P: Ненадежная распределенная система
Григорий Демченко, разработчик YT
Литература:
Chain Replication metadata management in Machi, an immutable file store
Spanner, TrueTime & The CAP Theorem
Brewer«s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web
Jepsen: Percona XtraDB Cluster
Consistency in Non-Transactional Distributed Storage Systems
Survey on consistency conditions
Highly Available Transactions: Virtues and Limitations (Extended Version)
Spanner: Google«s Globally-Distributed Database
CAP Twelve Years Later: How the «Rules» Have Changed
Забудьте САР теорему как более не актуальную
Please stop calling databases CP or AP
A Critique of the CAP Theorem
Perspectives on the CAP Theorem
YT: зачем Яндексу своя MapReduce-система и как она устроена
Комментарии (1)
21 февраля 2017 в 10:59
0↑
↓
То есть, по Вашему
C согласованность данных — состояние системы, когда действие внешних и внутренних факторов не приводит к ухудшению её функционирования.
A доступность — способность выполнять свои функции, несмотря на полученные повреждения.
P устойчивость к разделению — свойство выполнять свои функции во времени.
Статья хорошая, теоретический вывод — чушь. Извините.
