Методология как конструктор: инструкция по сборке
Из современного конструктора LEGO можно собрать только одну модель игрушки, например, самолет. Кастомизировать? Можете поменять местами кресла пилотов — вот и вся кастомизация. Лет 30 назад из конструктора можно было собрать примерно все, от самолета до грузовика, при том же количестве деталей как и в современных. Создатели большинства современных методологий в детстве играли в старое Лего. Те, кто сейчас пользуется методологиями — играли уже в современный. Разница в инженерных практиках огромна.

Под катом Филипп Дельгядо (dph) расскажет об инженерном подходе к формированию методологии. Все проекты и команды разные, а лидеры — неповторимы. Подогнать одну методологию под всех не получится — таких просто нет. Придется брать конструктор и строить из него что-то свое, уникальное. В расшифровке одного из лучших докладов TeamLead Conf не будет секретных тайн шаолиньских монахов — только банальности, проверенные опытом. Нас ждет каталог деталей методологии разработки, на что обращать внимание при ее конструировании и внедрении, правила перестраивания методологий. Для всех идей приведены реальные примеры из опыта Филиппа. За свою карьеру он попробовал все — от Visual Basic до хардкорного SQL, разрабатывал крупнейший в России букмекерский движок и Яндекс.Деньги, а сейчас работает над нагруженными проектами на Java. Регулярно делает доклады на разных конференциях, в том числе и на HighLoad++.
Задача
Несколько лет назад я в очередной раз пришел на проект по созданию платежной системы с нуля. На самом старте проекта не было ничего: ни разработчиков, ни процессов, ни постановок. С чего начать работу, если ничего нет? Сразу что-то внедрять — странно и даже глупо. Поэтому первый шаг — понять, что собственно нужно от методики.
Кент Бек в конце своей книги по SCRUM написал:
Все методики основаны на страхе. Вы пытаетесь развить у себя привычки, которые помогут вам не допустить воплощения ваших страхов в реальность.
Поэтому первое, что стоит сделать — выяснить у бизнеса, чего он боится.
Обычно бизнесу страшно за проект целиком: страшно делать слишком долго или не сделать вообще. Технологически ему страшно за надежность и безопасность. В нашем случае эти страхи обоснованы: платежная система — это контрагенты, деньги и серьезные обязательства.
Разные страхи приводят к разным методологиям. Страх переплатить ведет к найму дешевых разработчиков, которых просто менять — это SCRUM. Страх ошибки приводит к ГОСТам или RUP с кучей формализованных документов.
У разработчиков тоже есть свои страхи: написать неподдерживаемое или сделать плохо. К сожалению, методологии под страхи разработчиков почти никто не разрабатывает. Только в XP мельком упоминается, что разработчики боятся делать плохо, давайте попытаемся им помочь выполнить свою работу хорошо.
Кроме страхов, у бизнеса есть и пожелания, под какие цели оптимизировать процессы:
- быстро;
- дешево;
- предсказуемо;
- контролируемо;
- качественно;
- масштабируемо;
- хайпово.
Выберите один любой вариант, и, может быть, возможно, вероятно, когда-нибудь, наверно, если ничего не случится и Марс сойдется с Луной в Козероге, у вас все получится. Большинство пожеланий по оптимизации тоже про страх, только в другой формулировке: дешево — про страх переплатить, контролируемо — про страх сделать не то, предсказуемо — про страх не успеть.
Обычно бизнес хочет все и сразу. Когда собираете требования — придерживайтесь пресуппозиции «пациент всегда врет». Когда бизнес хочет все, он врет. Попытайтесь понять, что бизнес действительно хочет и попытайтесь ему это продать. Это не самый стандартный для тимлида набор умений. Но если вы не умеете выяснять реальные требования бизнеса, то необходимо найти человека, который умеет.
Помимо пожеланий бизнеса, нужно выяснить и существенные ограничения.
- Жесткие сроки. В моем случае не было жесткого дедлайна, например, олимпиады, когда есть только два варианта: либо успеть, либо нет.
- Строгий контракт. Если вы работаете с госкомпанией, то договор — это то, что нельзя нарушать. Все остальное можно делать, как угодно. Это очень сильно влияет на методику.
- Регулярные отгрузки. Нужно постоянно выкатывать новые фичи, это принципиально для бизнеса.
- Сертификация: ЦБ, PCI DSS. Это основное ограничение проекта платежной системы. Самые большие риски и опасения связаны с сертификацией ЦБ, PCI DSS и другими.
Именно существенные ограничения отличают, например, процессы FixPrice от процессов Time&Material.
В нашем проекте платежной системы, как удалось выяснить, страшно делать слишком долго и страшно не сделать, страшно за надежность и за безопасность, но желательно все сделать быстро. При этом на начало работы постановок нет, разработчиков нет, но есть специалисты в предметной области (например, я). Понятны только крупные и достаточно независимые друг от друга блоки: процессинг, клиенты, интеграции, бэкофис и фронтофис.
Разобравшись с целями и ограничениями, можно приступать к построению методики, к пониманию того, а как именно мы будем разрабатывать нужную систему — хотя бы на самой первой стадии.
Строим методику для старта проекта
Но что такое методика? Что вообще мы хотим построить? Ответ на вопросы — прекрасная картинка Алистера Коуберна с кучей пунктов.
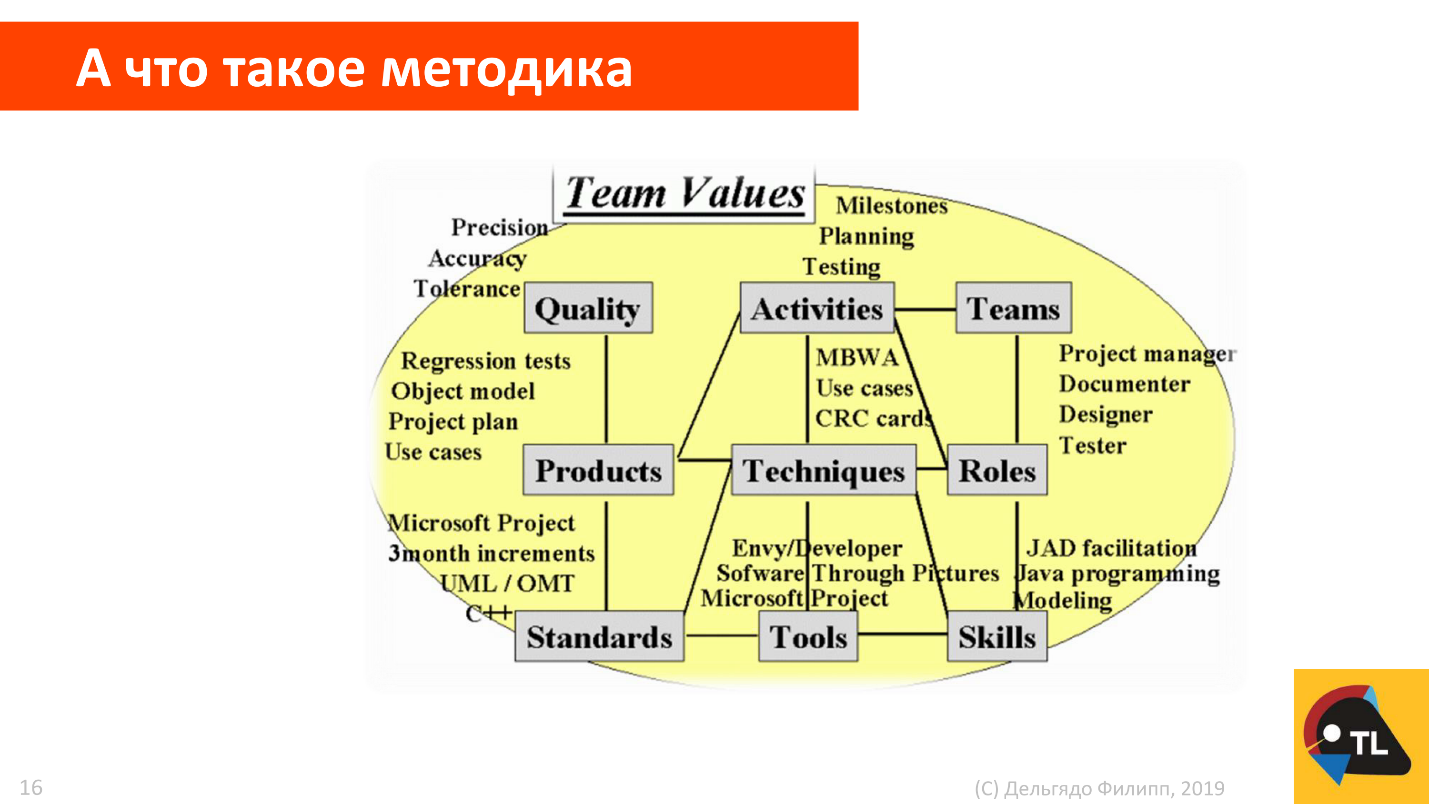
Из этой картинки в первую очередь нам важны три вещи: люди — те, кто делает; процессы — как делают; и артефакты — что должно быть сделано. Людей и процессов у нас пока нет, так что разберемся, какие нам нужны артефакты.
Начинать с артефактов — хороший паттерн при проектировании методики, даже если люди и процессы уже есть. Желательно начинать проектирование артефактов «с конца», с доставленной ценности, с тех артефактов, что будут выкладываться на прод или отправляться клиенту. Почему лучше именно так — отдельный вопрос для отдельной статьи. Если знаете ответ — напишите в комментариях.
Выбираем артефакты
Берем страхи и разбираемся, какие артефакты какие страхи закрывают.
От страха «работать над проектом слишком долго» спасает долгосрочный план и факт по вехам. От страха за надежность — автотесты. Для страха «не сделать» — поднимаем «почти боевой» стенд. На нем будем демонстрировать бизнесу прогресс работы. Так сразу видно, что есть и что работает, а в крайнем случае хоть какой-то результат и выложим.
Формируем процессы
Мы в начале разработки, поэтому нет времени и оснований для создания сложных формализованных процессов. Так что упрощаем все процессы, фокусируемся на облегчении общения.
В результате есть ровно два процесса: разобраться в большой задаче — подумать над решением, и проверить выполненное. Эти процессы длинные, исследовательские и мало связаны друг с другом, что приводит к соответствующим практикам разработки.
Чтобы было быстро — нанимаем крутых сотрудников. Но в платежную систему, которая никому на рынке неизвестна, крутые специалисты не идут. Как-то справится получилось, но решение этого вопроса — это отдельное обсуждение. Кстати, напишите в комментариях, как вы у себя его решили и решили ли вообще?
Отступление: о найме
При найме обычно смотрят на стандартные описания должностей и привычные градации уровней кандидатов, рисуя примерно такую карту ролей в команде:
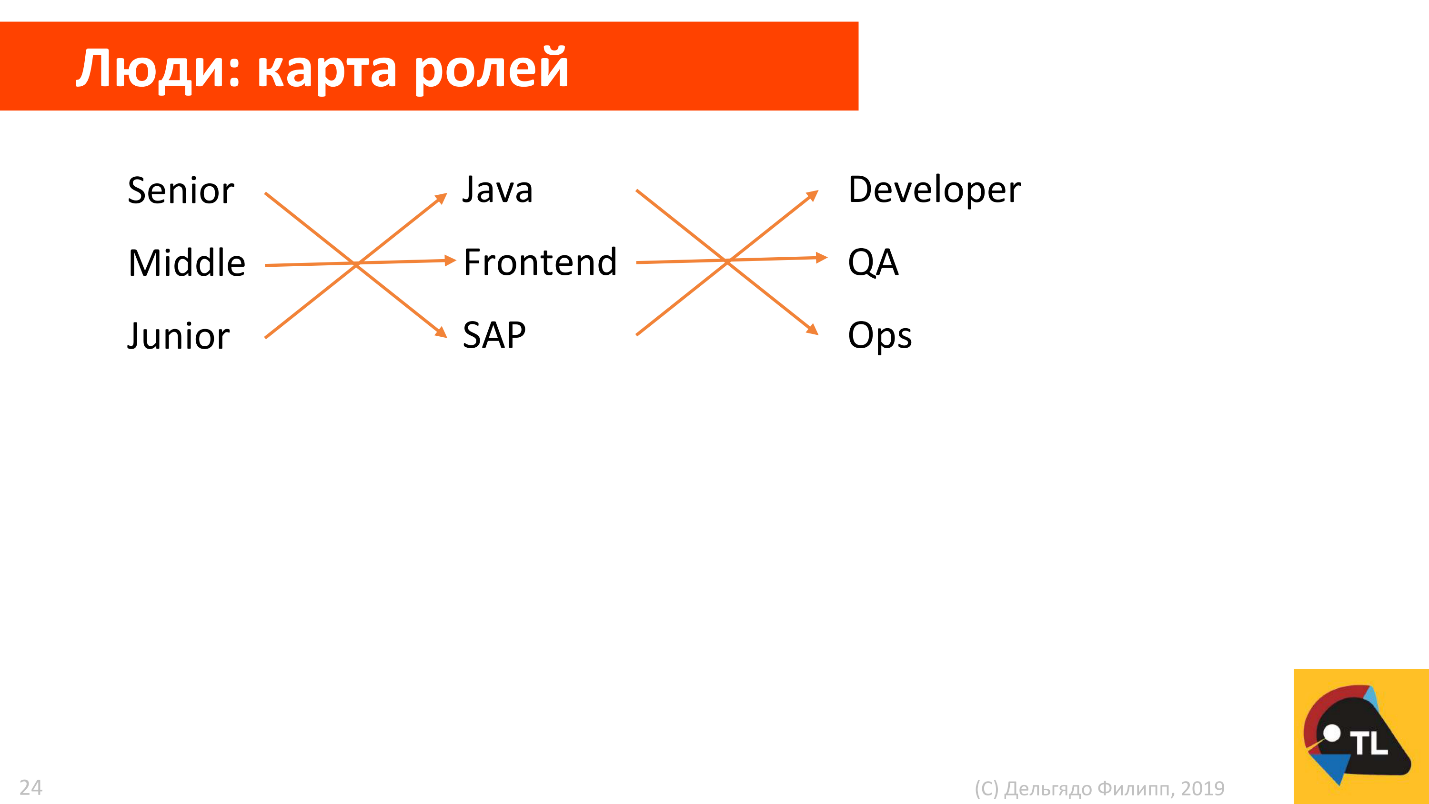
Но стандартные описания не позволяют понять необходимость конкретного человека на проекте. Я обычно стараюсь держать в голове несколько разных карт для разных проектов, выделяя разные важные для проекта роли и компетенции. Например, технологические.
Troubleshooter. Это человек, который может нырнуть в legacy-код с каким-то багом без документации и тестов на 2 дня, и вынырнуть с фразой: «В этой строчке замените + на –, и все заработает».
И оно заработает. Такие люди как четырёхлистный клевер — встречаются редко. К сожалению, рынок не ценит таких людей, сложно объяснить бизнесу, что troubleshooter критически нужен и достоит уважения и большой зарплаты. В результате большая часть из них уходит в тимлиды, и этот ресурс исчерпывается. Остается только пропагандировать полезность таких специалистов, и, возможно, через некоторое время ситуация изменится.
Integrator. Это человек, который умеет из нескольких разных компонент, библиотек, модулей создать что-то цельное. Это уже не программист на XML, а тот, кто понимает внутреннее устройство. Это крайне редкий навык, который обычно очень востребован в реальной разработке.
Guru: Framework, Security, Database, DevOps. Про гуру все понятно — это люди, к которым можно обратиться с вопросами на соответствующие темы.
Помимо этого, бывают еще «нетехнологические» роли, социальная карта ролей. Генератор идей — человек, который может что-то придумать. Критик — кто может конструктивно критиковать. Бывалый — опытный человек, который может сказать: «Мы так пробовали и получилась ерунда». Перфекционист — человек, который хочет, чтобы все стало хорошо. Это важная роль. Если его нет, обычно все быстро приходит в упадок, потому что нет никого, кто вам говорит: «Вы опять нафигачили, все не так — давайте исправим!»
Если какая-то роль в карте ролей для вашего конкретного проекта не заполнена, то выполнять ее придется тимлиду.
Поэтому думайте кого брать, и учитывайте, что для разных ролей и позиций подходят разные собеседования. С бывалым сеньором собеседование пройдет быстро — просто узнайте, что он делал. С джуниором обычно приходится долго беседовать, давать тестовые задания, выяснять, что он вообще может.
Чем выше уровень кандидата, тем короче собеседование.
Какие еще нужны люди?
Экстраверт — тот, кто хочет и может активно общаться вне разработки. Точных постановок у нас нет, поэтому нужно несколько людей, которые могут понять конечных пользователей, в том числе внутренних, например, наших бухгалтеров. Экстраверту не страшно пойти, поговорить, выяснить потребности таких непривычных «непрограммистов» — и таких людей мало.
Критик — мне в первую очередь нужен критик меня. Это человек, который будет критиковать мои решения. Без критики я боюсь, что несу какую-то ерунду. Когда же меня критикуют, мне приходится всерьез задумываться над аргументами, и выясняется, что это и не совсем ерунда.
Специалист по монотонным задачам: отчетам, интеграциям. Я точно знал, что у нас в проекте будет огромное количество отчетов. Полгода писать бухгалтерские отчеты и не сойти с ума — редкий навык. Раскидывать эту функцию по разным людям тоже неудобно, поэтому мне требовался специалист по монотонным задачам.
Пофигист. Это человек, которому все равно какие задачи делать, лишь бы платили. Эта роль крайне важно для проекта, потому что были разные задачи: монотонные, но сложные, безумно интересные или вообще никак не связанные с нашим предыдущим опытом из-за вылезшего внешнего требования.
Вернемся к нашему проекту. Troubleshooter нам не нужен, потому что legacy еще нет. Нужны были Integrator и набор гуру. Security Guru фактически вырастили внутри.
Database Guru удачно нашли на аутсорсе. Идея «брать компетенцию по БД где-то снаружи» мне очень нравится — найти в штат такого человека обычно нереально, если у вас не огромная компания, а для поддержки важной базы данных 24×7 требуется минимум 5 человек. DevOps Guru мы тоже сначала взяли на аутсорс, но не столь удачно, эта роль сложнее выносится на внешних исполнителей.
Социальные роли тоже удалось заполнить (а критиков было даже несколько).
Практики
Итак, мы разорались с необходимыми артефактами, выяснили, какие нужны люди и какие требования к процессам. Что же получилось, как именно мы организуем разработку:
- Планируем крупными мазками. У нас нет постановок, поэтому невозможно планировать точнее. Есть необходимость сделать личный кабинет за три месяца — и все. Планы ведем в Confluence.
- Каждый немножко аналитик. Нет нормальных постановок и компетенцию по предметной области держат люди, которые не умеют писать постановки. Их никто не научил, надо с них эту информацию снимать. Зато у нас есть «экстраверты».
- Трекер не нужен. У нас на проект всего 20 крупных задач — зачем заводить трекер.
- Одна ветка в VCS. На начальном этапе сложная работа с контролем версий не потребуется.
- Процессы приблизительные. Людей еще мало, коммуникаций и проблем нет, да и сам проект зыбкий. Не нужно ничего подробно описывать.
Когда рассказывают про подобные не слишком формализованные методики, то часто говорят просто:»У нас аджайл».
У нас тоже получился классический «У нас аджайл». Но я четко понимал, почему именно такая методика и почему это именно «agile», а не что-то более конкретное и сложное. И меня (и бизнес) эта методика вполне устраивала.
Внимательный читатель заметит, что при проектировании методики мы забыли про два важных страха: страх за безопасность и необходимость сертификации. Попробуем разобраться, а как с ними справиться.
Отступление: Матрица Коуберна
В 1980 году Алистер Коуберн нарисовал матрицу сложности проекта.

По вертикали — критичность проекта. То, что можно потерять в случае существенных ошибок: от потери комфорта пользователем до потери жизни пользователя, например, если мы проектируем софт для атомных станций. По горизонтали — размер команды. Размер влияет на число коммуникаций. Критичность — на подробность этих коммуникаций. Все в сумме влияет на сложность процесса.
Алистер утверждает, что переход в каждый квадрат вправо или вверх сильно усложняет и удорожает разработку. Это логично — больше людей требуют больше расходов на коммуникации. Если нужны более формальные отношения, то опять требуется больше расходов на коммуникацию. Т.е. чем дальше, тем больше ресурсов уходит на непроизводительные задачи и потери.
Кстати, в качестве третьей оси Алистер рисует оптимизацию под разные пожелания бизнеса.
Попробуем разместить на этой матрице нашу платежную систему. Матрица очень удобна как модель для понимания предполагаемой сложности вашего проекта, вашей системы.
У нас платежная система, а значит, в крайнем случае потеряем немного денег пользователей. Это, конечно, неприятно, но не приводит к резкому росту сложности.
Но у нас почти банк, а у банка в некоторых случаях, при нарушении нормативов или требований Центробанка, могут отнять лицензию. Это уже потери очень больших денег, практически закрытие бизнеса, очень грустно.
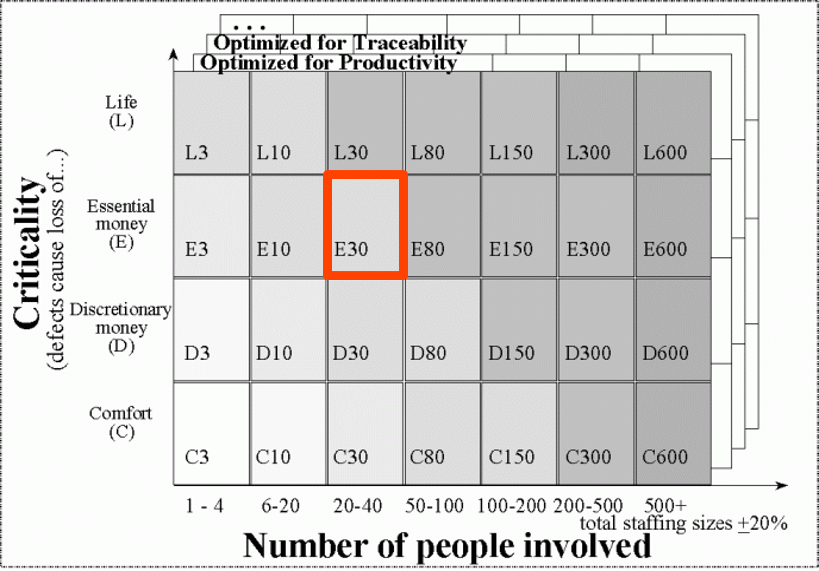
Команда у нас около 20 человек, так что попадаем в квадрат Е30. Это плохо, потому что хорошим примером методики в этом квадрате будет полноценный Rational Unified Process — формальные процессы, много документов, четкие постановки. С этим не справиться силами 20–30 человек. Придется нанимать 50, и сложность будет расти как снежный ком. Подобные системы в таких методологиях обычно писали сотни и больше людей.
Что делать? Беда? Нет, не весь проект одинаково критичен. У нас есть только несколько критичных частей.
- Проверка на отмывание денег — за что Центробанк сильно бьет по голове.
- Работа с банковскими картами — за что мировые платежные системы сильно бьют по голове.
- Хранение персональных данных — за это государство сильно бьет по голове.
Давайте выделим отдельные критичные модули. Пропишем для них специальные практики работы именно с этими частями нашего проекта: полноценный PCI DSS Audit на каждый commit, хорошее документирование, двойной Code Review, специальный процесс выкладки и еще куча всего. Пусть эти части проекта пишут только senior developers.
Но таких частей мало. Поэтому матрица Коуберна для проекта получается такая.
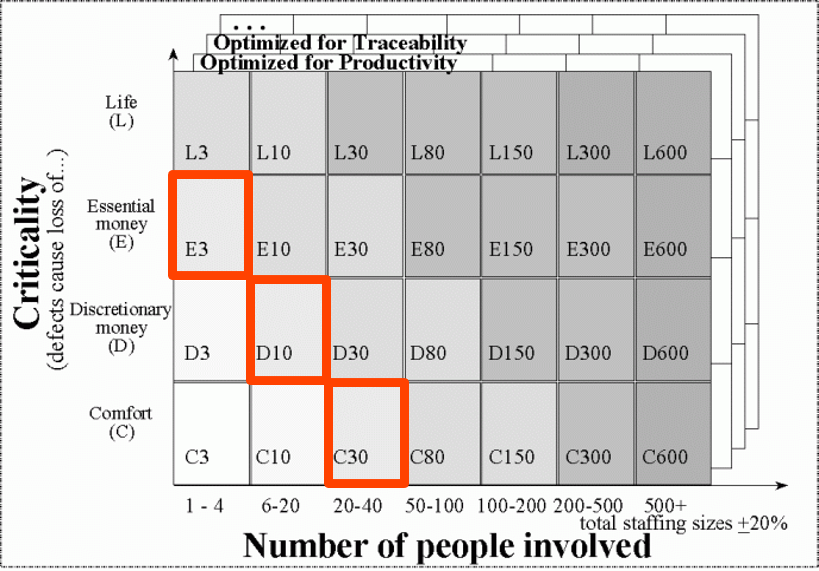
Для разных частей проекта будет разная сложность методики, разный набор практик. Самым сложным и страшным занимается три человека. Платежной логикой — человек 8. Всякими менее важными задачами, которых больше всего, вроде системы помощи или верстки сайта для бэк-офиса, в которых ошибка не принципиальна, занимается больше всего людей. Но там и процессы могут быть самые легкие и неформальные.
В большом сложном проекте могут использоваться разные наборы практик для разных его компонентов.
Это один из больших плюсов микросервисной архитектуры — возможность прописывать такую картину, в которой разные сервисы отвечают не столько разным методикам, сколько разным практикам внутри одной методики. При этом важные вещи остаются общими: планирование, артефакты, общий подход к взаимодействию.
Подытожим
Мы выяснили требования к методике: цели и ограничения. Определили основные элементы: процессы, артефакты и люди. Описали практики: как реализовать процессы, требования к артефактам, какие нужны люди.
Это классическая схема инженерной разработки: у нас есть требования, потом мы уточнили архитектуру, и дальше запрограммировали.
Проектирование методик — это инженерная практика, инженерный процесс, который ничем не отличается от программирования какого-нибудь модуля.
Практики первой стадии проекта
Немножко практик, чтобы отвлечься от теории на реальность.
Право на «Зачем?»
Это моя любимая практика.
Каждый сотрудник имеет право спросить про любую задачу: зачем ее делать, зачем делать именно так и кому она вообще нужна?

Люди бояться спрашивать «зачем» — возможно, потому что в детстве на такие вопросы все равно не отвечали. Если у вас где-то явно записано и много раз повторено «можно и нужно», люди это делают. Как только начинаете спрашивать «зачем» на всех уровнях, включая бизнес, в разы уменьшается объем задач и так же увеличивается мотивация. Люди понимают смысл работы и выполняют ее быстрее и экономнее, срезая углы.
До трех не обобщать
Не создавайте универсальное решение, пока нет трех разных примеров. Если проектируете три разных самолетика, то не можете сразу по одному из них написать корректный класс, который он представляет.

Это решение и для разработки — не стройте универсальную интеграцию с контрагентами, пока нет трех разных интеграций и нет понимания, где они разные. Но и при проектировании методики не рисуйте сразу формальное описание артефакта — схему или шаблон — пока не попробовали три разных подхода и не выяснили, что в них общее. Это простая, но полезная практика, позволяющая не создавать избыточные абстракции на ровном месте.
IDE Driven Development
JetBrains всемогущий дал нам в руки хороший инструмент — давайте его использовать на полную! Реализуйте то, что легко сделать и проверить в IDE.

Не используйте вообще то, что не поддерживается в IDE.
Я уважаю аспектное программирование. Но я не буду использовать его в проекте пока не могу легко проанализировать свой аспектный код, не выходя из IDE и не нажимая больше двух кнопок, потому что это сильно усложняет поддержку. Как только эту возможность добавили в IDE — аспектное программирование пригодно для использования. Чем больше возможностей IDE — тем больше возможностей в вашей работе: быстрее рефакторинг, замена кода, анализ ошибок, управление более сложной логикой. Это позволяет избежать лишнего: тестирования, процессов, коммуникаций и даже документирования.
В нашем проекте мы дописывали много специального странного кода, например, чтобы в IDE можно было для акторной асинхронной модели посмотреть call stack по одной кнопочке. Обычно это сделать невозможно.
Простейшее использование IDE — вместо длинного стандарта оформления кода написать набор настроек и утвердить его как стандарт кодирования.
Пятничный тортик
В новой команде, в которой люди еще не очень знакомы, проводить классические ретроспективы по скрамовским образцам не получается. Люди не понимают зачем это. Человек думает: «Зачем я вообще пришел в эту компанию и что я тут делаю?» Проще в пятницу купить за свои деньги тортик и попить чай, параллельно незаметно выясняя проблемы в проекте. Люди охотнее открываются, когда их кормят чем-то сладеньким вечером и неофициально. Можно пиво, но это уж зависит от компании и команды.

Через 3–4 месяца можно переходить от тортиков к нормальным ретроспективам и рефлексии. Но начинать с практики пятничного тортика удобнее.
Это все практики под конкретные процессы, которые можно использовать. Но это не значит, что их нужно использовать всегда. Вообще, не бывает практик, применимых в любых случаях, всегда нужно сначала думать.
Запуск
По описанной выше методике мы сделали первую версию системы. А дальше предстоит запуск — выход в продакшн, показ проекта инвестору и заказчику, первые реальные пользователи и живые деньги.
В нашем конкретном случае требовалась интеграция с контрагентами и бета-тестирование малым числом внешних, но очень требовательных пользователей. Тут начинается маленький ад.
Много неожиданных требований — наши планы столкнулись с реальностью.
Много срочных требований: «Надо поправить завтра, потому что сегодня наш важный контрагент нашел багу, и если мы не поправим, он обидится».
Частые обновления продукта — каждый день, и чем чаще, тем лучше. Объемы задач вообще непредсказуемы. Но есть технологические паузы — поскольку пользователей нет, мы можем, например, ночью все вырубать начисто.
Предыдущая методика в этих условиях вообще не работает. Понятно, что надо делать что-то новое. Поэтому мы опять пошли к бизнесу выяснять его страхи.
Новые страхи
Как можно было догадаться, теперь страшно бизнесу только за надежность — за то, что у нас все будет падать не вовремя. И доработки нужно делать быстро: быстро править баги, быстро чинить интеграции, быстро находить проблемы
Хорошо, у нас появились новые процессы: срочная выкладка и исправление ошибок. Исходя из этого делаем новую методику. Появляются новые практики.
- Нормальный трекер. У нас бывают баги, и если до этого трекер был не нужен, то теперь необходим.
- Ручное тестирование. Мы не успеваем все покрыть автотестами, и есть вещи, которые сложно покрыть автотестами, например, изменение цвета кнопочки под чей-то корпоративный стиль.
- Командная работа. До этого можно было пилить 3 месяца свою большую мега-фичу, а потом аккуратно смержиться, и все это были отдельные интерфейсы, отдельные сервисы, поэтому проблем не было. Сейчас если упал продакшн, его поднимают все.
- Мотивация. В этот момент люди точно будут перерабатывать, иногда выходить в выходные. Чтобы просить людей разбираться с багами ночью в выходные, их надо как-то мотивировать — хотя бы премией или тройной оплатой переработок.
Мы запустили методику, которую можно назвать однодневный SCRUM, хотя к SCRUM она не имеет никакого отношения. Мы с утра собирались на планирование, распределяли задачи, выполняли, а вечером выкладывали новую версию и проводили ретроспективу.
И так каждый день примерно месяц. За месяц прошло 20 спринтов. К SCRUM Сазерленда этот процесс, конечно, никакого отношения не имеет, хотя чем-то и похож. Но в нашем случае эта методика сработала.
Практики стадии запуска
Нам особенно пригодилось две практики.

Чек-лист — это ритуал, который разгружает мозг и дает возможность в 3 часа ночи сделать выкладку на продакшн и его не уронить.
Чек-лист позволяет не думать.
Мы делали много чек-листов на разные темы: как проверять PCI DSS код, как выложить на продакшн новый сервис (включая сообщения контрагентам и операционному отделу и прочие орг.мелочи, про которые системные администраторы предпочитают ночью забыть), что нужно проверить при потенциальных проблемах с БД или при чем-то непонятном в мониторинге.

Дежурства. Это не формальные дежурства типа «я сижу и жду, когда сервер упадет», а понимание планов людей в команде. Если выясняется, что половина команды в пятницу 1 сентября идет на линейку к своим детям и берет на это время отгул — мы заранее узнаем, кто из команды может при этом все-таки быть рядом с компьютером. Если человека попросить заранее изменить планы, он может их изменить. Если у вас shit happens прямо сейчас, а сотрудник при этом в театре — он будет недоволен, если его оторвут. Если его попросить перенести поход в театр на неделю, он, скорее всего, согласится, особенно если это компенсировать.
Так мы вышли в продакшн, там задержались, устаканились, и пошла третья стадия — нормальное развитие проекта, когда уже все работает, но мы должны активно двигаться вперед.
Развитие проекта
Третья стадия — проект становится продуктом. Остались страхи за надежность и безопасность. Появился страх переплатить. Проект есть и приносит какой-то объем денег, и чем меньше мы на него тратим и больше денег он приносит, тем больше выгода у бизнеса — он не хочет платить лишнее.
Еще новый страх — сделать неподдерживаемое. Теперь команда растет, «старые» люди уже не так важны, нужно как-то повышать bus factor — мы же нормальный бизнес, все должно быть серьезно.
И теперь нужно делать предсказуемо и масштабируемо. Масштабируемо не в смысле увеличения нагрузки, а в смысле увеличения количества разработчиков и команд, потому что бизнес и задачи растут.
Получается куча новых процессов. Краткосрочные планы и регулярные выкладки, потому что нужно предсказуемо. Документация, потому что масштабируемо, чтобы новые люди могли быстрее обучаться и встраиваться. Нормальные постановки, по которым легко пилить не очень дорогим разработчикам, и регулярные показы, потому что страшно сделать лишнее. Style guides и code review нужны не для того, чтобы разработчики не сделали чего-нибудь тотально плохого, а чтобы проще поддерживать код.
Это уже знакомый набор процессов, вы все регулярно используете что-то подобное. Но как выбирать конкретные практики для этих процессов?
Выбор практик
Рассмотрим Planning poker. Это хорошая практика для создания артефакта »краткосрочный план» — давайте ее использовать. Но сначала разберёмся, что нужно, чтобы эта практика работала. Planning poker хорошо работает при условиях отсортированного и качественного бэклога, коротких задач и команды универсалов.
Это нормальные условия для внедрения практики. Бывают и другие условия внедрения практик:
- единый офис;
- product owner под рукой;
- фиксированные планы;
- редкие обновления.
Хорошо, у нас есть нормальный бэклог, короткие задачи, все универсалы —, но зачем тогда отвлекать всю команду на планирование? Можно поручить планирование тимлиду, он раскидает все задачи за 2 часа и сэкономит 10% от общей производительности команды. Зачем нам так много тратить времени?
Попробуем понять, а зачем нам Planning poker на самом деле — раз уж не только для того, чтобы создать краткосрочный план, какие реальные цели практики? На мой взгляд, основная цель — дать разработчикам ощущение ответственности за данные им оценки. Обычно разработчики оценивают сложность любой задачи ниже реальной. Но в случае planning poker они сами закоммитились на эту оценку, им неудобно не соответствовать своим обещаниям, и они начинают работать по ночам.
Вообще есть много разных скрытых целей у популярных практик: удешевление стоимости труда, увеличение нормы эксплуатации, уменьшение зависимости от конкретных людей. Вообще весь Agile — это про увеличение нормы эксплуатации разработчиков, потому он и востребован бизнесом. Бизнесу нравится, что люди работают быстрее и дешевле.
Если бы у программистов был профсоюз, то Agile, SCRUM и XP запретили бы.
Надо понимать, что у практик есть внешняя цель, например, создать краткосрочный план, и внутренняя, например, уменьшить норму эксплуатации. Каждый раз, когда вы слышите про какую-то практику, подумайте — какие у нее внутренние реальные цели? Всегда ли будут эти цели выполняться?
Домашнее задание. Есть прекрасные стандартные практики: корпоративная столовая, парное программирование, проектный учет времени, бесплатный кофе. Найдите их внутренние цели и подумайте, как их еще можно реализовать?
Картина мира
Предположим, у нас в Planning poker есть прекрасный сеньор, который выполняет задач больше всех остальных в команде, но при этом на Planning poker всегда ставит единичку:
— Мне все просто, и вообще я не хочу заниматься этой вашей ерундой, дайте мне программировать!
В этом случае Planning poker работать не будет. Он работает только если каждому разработчику важно мнение команды о нем. Эта практика эффективна только в такой картине мира.
В разных методиках можно найти следы разных картин мира их создателей:
- изменения неожиданы и непредсказуемы;
- дисциплина должна быть;
- люди отвечают за свои слова.
Отслеживайте картины мира в используемых вами практиках.
Есть простой критерий: если вы не можете вычленить картину мира, значит, вы с ней согласны.
Практики развитой системы
Насколько часто у вас в Jira программисты пишут время, которое потратили на задачи «от балды» в конце недели? Насколько часто они регулярно неправильно заполняют какую-нибудь хитрую заявку на что-нибудь? Насколько часто забывают ответить на письма в переписке?

Чтобы за всей этой чепухой следил не тимлид, у которого дорогое время, наймите секретаря проекта. По сути, это junior product manager — человек, который стоит не очень больших денег, но может взять на себя большую часть отслеживания качества бюрократических артефактов, либо вообще их создание.
Иногда бизнес просит отслеживать, когда программисты приходят и уходят — пусть за этим следит секретарь. Так вы сэкономите много денег и усилий разработчиков. Они любят, когда о них заботятся. Если секретарь будет им еще мартини подавать — вообще прекрасно!

Review before code. Регулярно слышу, как человеку дали ответственность за большую фичу, а он сделал не то и надо переделывать. Давайте делать ревью кода до того, как его написали. Прежде, чем писать код, сотрудник в Jira описывает план решения задачи на две строки или два абзаца текста. Ревьюить эти два абзаца просто и быстро, но при этом глобальные ошибки ловятся на раннем этапе, особенно, если у вас есть тимлид или архитектор.
Кроме того, такая практика позволяет тимлиду или архитектору быть в курсе всех изменений в большом проекте. Он читает не кривой код, а два абзаца о том, что вообще происходит в системе, и быстро ловит людей за руку. Это особенно актуально для критически важных частей продукта, например, платежной логики.
Как менять методику и не убить проект
Итак, за 9 месяцев мы поменяли 3 методики: «У нас Agile», однодневный SCRUM и Kanban. Как сделать так, чтобы при этом не терять ресурсы? Как вообще менять методику, и не убить при этом проект в ноль?
Мы умудрились менять методики так, что некоторые разработчики вообще не заметили изменений. Им никто об этом не говорил, они работают, а методика уже другая!
Главное — понять, когда менять.
Если вы понимаете «зачем». Часто методики меняют, потому что пришел новый технический директор, которому хочется все переделать. Это плохой повод. Лучше возьмите старую и переименуйте — все, методика другая, стало лучше. Если не можете ответить на вопрос зачем, лучше не меняйте. Я вообще люблю спрашивать зачем.
Если продумали «как». Если понимаете, как будете приходить из точки А в точку В, то меняйте. Пока не придумали — не надо.
Если
