Метод фрагментарного сжатия видеопотока
Я решил представить на суд уважаемого хабрасообщества свою разработку — метод фрагментарного сжатия видеопотока. Особенностью предлагаемого метода является полное соответствие сжатого видеопотока исходному, то есть метод осуществляет сжатие без потерь.Прежде чем описывать сам метод, необходимо договориться об используемой терминологии. Все используемые термины интуитивно понятны, но тем не менее, стоит определить их строго: Пиксель — минимальная единица изображения. Числовое значение пикселя выражает значение функции яркости изображения в одной точке экрана. Количество бит, отводимое для кодирования яркости, называется глубиной цвета и обозначается в дальнейшем bpp;
Кадр — набор всех пикселей в конкретный момент времени. Кадр представляется как двумерный массив пикселей высотой N1 и шириной N2 пикселей.
Видеопоток (фильм) — последовательность кадров, упорядоченная по времени. Общее число кадров в фильме в дальнейшем обозначается M.
Окно — прямоугольная область пикселей высотой n1 и шириной n2.
Фрагмент — часть кадра, ограниченная окном.
Логическая разность — результат применения операции сложения по модулю 2 (исключающего ИЛИ) к двум цифровым представлениям соответствующих фрагментов в соседних кадрах.
Арифметическая разность — результат арифметического вычитания цифровых представлений соответствующих фрагментов в соседних кадрах.
Элемент — в качестве элемента в зависимости от особенностей задачи выступает либо фрагмент, либо различные виды разностей. Цифровым представлением элемента является битовая строка длиной k. В случае фрагментов или логических разностей k=n1*n2*bpp, а в случае арифметических разностей k=n1*n2*bpp+n1*n2, так как на каждый пиксел окна требуется дополнительный знаковый бит.
Объём фильма (Nф) — общее количество элементов в фильме. Nф=(N1*N2*M)/(n1*n2)
Частота элемента — отношение количества появлений данного элемента в фильме к объёму фильма.
База элементов — набор всех присутствующих в видеопотоке элементов и их частот. Мощность базы элементов обозначается Nб.
Код элемента– двоичный код, позволяющий однозначно идентифицировать элемент в базе.
Основная идея фрагментарного метода сжатия заключается в представлении видеопотока в виде цепочки элементов длиной Nф из базы элементов. Поскольку видеопоток представляет собой набор осмысленных изображений (кадров), достаточно медленно меняющихся во времени, следует ожидать существенной корреляции как между соседними элементами одного кадра, так и между соответствующими элементами на соседних кадрах. Это должно приводить к двум эффектам: Сравнительно небольшой мощности базы (Nб) относительно мощности множества всех возможных значений фрагментов (2kf) даже при достаточно большом объёме фильма;
Значительной неравномерности частот появлений различных элементов из базы элементов в фильме. Это должно позволить применять эффективные энтропийные алгоритмы кодирования-сжатия цепочки элементов в видеопотоке.
Таким образом основная идея метода фрагментарного сжатия состоит в представлении видеопотока в виде хорошо сжимаемой последовательности элементов из некоторой специально составленной базы элементов. Проведённые авторами эксперименты подтверждают эту гипотезу.Концепция метода позволяет осуществлять сжатие видеопотока как без потерь, так и с потерями. В случае сжатия с потерями возможна и предобработка (фильтрация), позволяющая сгладить исходное изображение, и постобработка, заключающаяся в анализе базы элементов и последующем выделении и удалении из видеопотока как случайных помех, так и визуально избыточной информации. Совместное использование пред- и постобработки позволяет формировать новый сжатый видеопоток с нужными свойствами.Метод фрагментарного сжатия можно представить в виде последовательности четырёх шагов: Формирование базы элементов. В случае сжатия с потерями возможна предварительная фильтрация кадров видеопотока;
Анализ полученной базы элементов и её частотных характеристик;
Построение коротких кодов для элементов базы;
Формирование схемы сжатой передачи фильма.
Ниже эти шаги рассмотрены более подробно.Формирование базы элементовПроцесс формирования базы элементов — один из самых ресурсоёмких шагов фрагментарного метода сжатия. Итоговая скорость компрессии во многом зависит от того, насколько эффективно выполняется этот этап.Ввиду крайне высоких требований к скорости, алгоритм формирования базы элементов выполняется в несколько этапов, при этом на каждом шаге используются различные алгоритмы и структуры данных.Формирование базы элементов кадра — первый и самый простой шаг. На этом этапе происходит получение очередного кадра из видеопотока, его предварительная обработка в случае необходимости, и, в зависимости от вида элемента, формируется соответствующий «псевдокадр».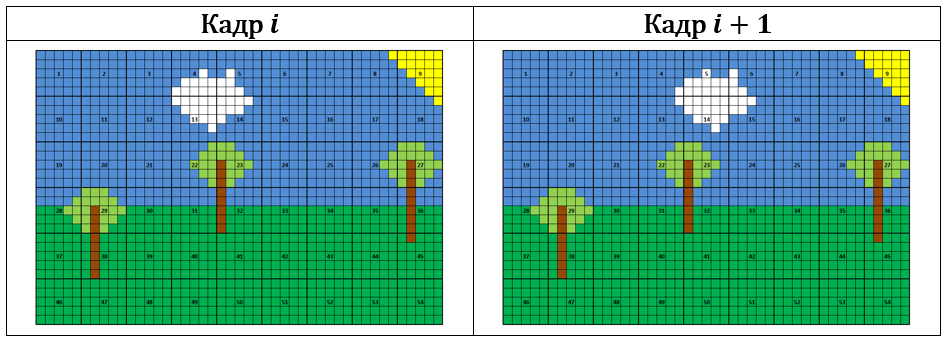 При просмотре псевдокадра» окно сдвигается на n2 пикселов по ширине и на n1 пикселов по высоте. На рисунке приведён пример кадра N1=30 строк на N2=45 столбцов, просмотр выполняется с помощью квадратного окна n1=n2=5. Тонкими линиями на рисунке выделены отдельные пикселы, толстыми линиями показаны границы окна, а цифры внутри окна — порядковый номер при просмотре.Если в качестве элементов выступают логические или арифметические разности, то в результате сканирования получится следующий набор разностей:
При просмотре псевдокадра» окно сдвигается на n2 пикселов по ширине и на n1 пикселов по высоте. На рисунке приведён пример кадра N1=30 строк на N2=45 столбцов, просмотр выполняется с помощью квадратного окна n1=n2=5. Тонкими линиями на рисунке выделены отдельные пикселы, толстыми линиями показаны границы окна, а цифры внутри окна — порядковый номер при просмотре.Если в качестве элементов выступают логические или арифметические разности, то в результате сканирования получится следующий набор разностей: 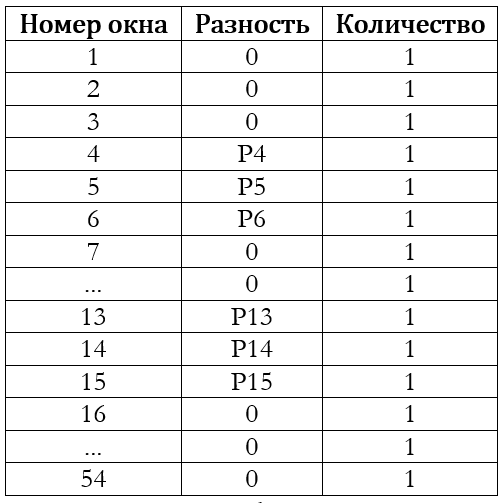 Для большинства реальных видеофильмов выполняется предположение о существенной корреляции между соответствующими элементами на соседних кадрах. Это видно и в таблице: большинство элементов соответствует нулевым разностям. Для экономии памяти полученная база элементов кадра уплотняется. Сначала выполняется сортировка каким-нибудь эффективным алгоритмом, а затем совпадающие элементы объединяются в одну запись. То есть вместо 48 нулевых разностей в уплотнённой базе будет только одна запись.
Для большинства реальных видеофильмов выполняется предположение о существенной корреляции между соответствующими элементами на соседних кадрах. Это видно и в таблице: большинство элементов соответствует нулевым разностям. Для экономии памяти полученная база элементов кадра уплотняется. Сначала выполняется сортировка каким-нибудь эффективным алгоритмом, а затем совпадающие элементы объединяются в одну запись. То есть вместо 48 нулевых разностей в уплотнённой базе будет только одна запись.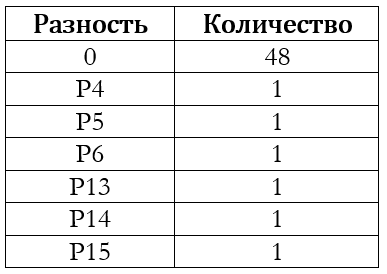 На втором этапе уплотнённые базы элементов кадра записываются в специальный буфер элементов — отдельную область памяти, где множество баз кадров накапливаются, а потом одним большим блоком записываются в глобальное хранилище. Особенностью буфера является то, что к любому его элементу возможен произвольный доступ по индексу, т.е. по сути это просто большой массив элементов, размещённый в ОЗУ: Также стоит отметить, что базы элементов кадра записываются в буфер «как есть» без всякой дополнительной пересортировки. Это приводит к тому, что буфер содержит в себе множество упорядоченных последовательностей элементов, но при этом сам не упорядочен:
На втором этапе уплотнённые базы элементов кадра записываются в специальный буфер элементов — отдельную область памяти, где множество баз кадров накапливаются, а потом одним большим блоком записываются в глобальное хранилище. Особенностью буфера является то, что к любому его элементу возможен произвольный доступ по индексу, т.е. по сути это просто большой массив элементов, размещённый в ОЗУ: Также стоит отметить, что базы элементов кадра записываются в буфер «как есть» без всякой дополнительной пересортировки. Это приводит к тому, что буфер содержит в себе множество упорядоченных последовательностей элементов, но при этом сам не упорядочен:  Когда для записи очередной базы кадра в буфере недостаточно места, вызывается процедура обновления списка реально встретившихся элементов.На третьем этапе накопленные в буфере элементы перемещаются в специальное глобальное хранилище, которое представляет собой односвязный список элементов, упорядоченный по их значениям. Представление глобального хранилища в виде списка не позволяет выполнять произвольный доступ за константное время, но зато позволяет выполнять добавление и удаление элементов за константное время.Перед тем, как добавить элементы из буфера в глобальное хранилище, выполняется уже рассмотренная ранее процедура сортировки и уплотнения буфера. Это позволяет выполнить добавление элементов за линейное относительно размера списка время:
Когда для записи очередной базы кадра в буфере недостаточно места, вызывается процедура обновления списка реально встретившихся элементов.На третьем этапе накопленные в буфере элементы перемещаются в специальное глобальное хранилище, которое представляет собой односвязный список элементов, упорядоченный по их значениям. Представление глобального хранилища в виде списка не позволяет выполнять произвольный доступ за константное время, но зато позволяет выполнять добавление и удаление элементов за константное время.Перед тем, как добавить элементы из буфера в глобальное хранилище, выполняется уже рассмотренная ранее процедура сортировки и уплотнения буфера. Это позволяет выполнить добавление элементов за линейное относительно размера списка время: 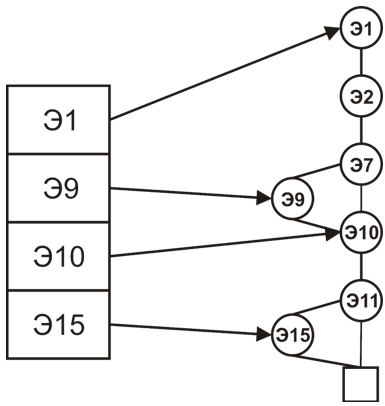 Три рассмотренных этапа оперируют данными, размещёнными в ОЗУ. Заключительный этап предполагает работу с данными, размещёнными на жёстких дисках. В подавляющем большинстве случаев достаточно мощный современный компьютер позволяет полностью собрать базу элементов в ОЗУ, но существуют ситуации, когда размера оперативной памяти недостаточно, чтобы разместить там всю базу (например, если выполняется формирование общей базы для сотен часов съёмки). В этом случае необходимо сохранять полученные базы на диск по мере исчерпания оперативной памяти, а потом выполнить процедуру слияния баз.Таким образом в процессе формирования базы элементов выполняется следующая последовательность шагов:
Три рассмотренных этапа оперируют данными, размещёнными в ОЗУ. Заключительный этап предполагает работу с данными, размещёнными на жёстких дисках. В подавляющем большинстве случаев достаточно мощный современный компьютер позволяет полностью собрать базу элементов в ОЗУ, но существуют ситуации, когда размера оперативной памяти недостаточно, чтобы разместить там всю базу (например, если выполняется формирование общей базы для сотен часов съёмки). В этом случае необходимо сохранять полученные базы на диск по мере исчерпания оперативной памяти, а потом выполнить процедуру слияния баз.Таким образом в процессе формирования базы элементов выполняется следующая последовательность шагов:  Анализ полученной базы элементов и её частотных характеристик
Анализ базы элементов предполагает анализ как индивидуальных значений каждого элемента, так и частотных характеристик базы. Это позволяет, во-первых, выбирать эффективные комбинации методов сжатия (построения коротких кодов и способов их передачи), а, во-вторых, в случае сжатия с потерями, осознанно проводить сокращение базы (фильтрацию).Построение коротких кодов для элементов базы
База элементов включает в себя массив из Nб строк длины k бит и таблицу частот появления этих строк в видеопотоке (фильме). Этой информации достаточно для применения хорошо известных методов энтропийного кодирования (дерево Хаффмана, арифметическое кодирование и т.д.). Перечисленные алгоритмы имеют очень высокие оценки эффективности, но их реальное использование связано с существенными трудностями реализации.Для построения коротких кодов элементов авторы предлагают и используют предложенный ими ранее метод построения префиксных кодов с помощью секущих функций. В этом методе короткие коды элементов базы строятся по содержанию строк самих элементов. Автором было доказано, что средняя длина таких кодов не превышает величины Hб*1,049, где Hб — энтропия базы элементов, вычисляемая по частотам появления элементов в видеопотоке. В численных экспериментах с реальными фильмами Hб никогда не превышала 20, а это значит, что Hб*1,049 б+1, откуда следует, что средняя длина кодов секущих укладывается в те же априорные оценки избыточности, что коды Шеннона-Фано и Хаффмана. При этом кодирование с помощью секущих функций лишено тех недостатков, которые возникают при кодировании и декодировании вышеназванными методами цифровых массивов больших размеров (Nб≈107–109).Формирование схемы сжатой передачи фильма
В сжатом видеопотоке элементы заменяются полученными ранее короткими кодами. При воспроизведении сжатого видеопотока возникает проблема декодирования. Для декодирования необходимо иметь информацию о соответствии коротких кодов и элементов базы. Самым простым способом передачи такой информации является непосредственная передача элемента и его частоты (количества появлений). Такой способ подразумевает передачу самой базы, а также дополнительных 64 бит на каждый элемент. Принимающая сторона после получения данных сама должна построить кодовое дерево по заранее сообщённому алгоритму.Был предложен способ записи и передачи дерева, в листьях которого записана вся база элементов. При этом объём передачи равен объёму базы плюс два дополнительных бита на каждый элемент базы ((k+2)*Nб).Договоримся о порядке обхода дерева: например, будем использовать обход в ширину. Если встречается делящий узел дерева, то передаётся бит 0, если в процессе обхода был обнаружен лист, то передаётся бит 1 и соответствующий элемент базы. В итоге легко показать, что на каждый элемент базы дополнительно передаётся всего 2 лишних бита. На рисунке показано представление двоичного дерева в виде двоичной строки с помощью описанного метода:
Анализ полученной базы элементов и её частотных характеристик
Анализ базы элементов предполагает анализ как индивидуальных значений каждого элемента, так и частотных характеристик базы. Это позволяет, во-первых, выбирать эффективные комбинации методов сжатия (построения коротких кодов и способов их передачи), а, во-вторых, в случае сжатия с потерями, осознанно проводить сокращение базы (фильтрацию).Построение коротких кодов для элементов базы
База элементов включает в себя массив из Nб строк длины k бит и таблицу частот появления этих строк в видеопотоке (фильме). Этой информации достаточно для применения хорошо известных методов энтропийного кодирования (дерево Хаффмана, арифметическое кодирование и т.д.). Перечисленные алгоритмы имеют очень высокие оценки эффективности, но их реальное использование связано с существенными трудностями реализации.Для построения коротких кодов элементов авторы предлагают и используют предложенный ими ранее метод построения префиксных кодов с помощью секущих функций. В этом методе короткие коды элементов базы строятся по содержанию строк самих элементов. Автором было доказано, что средняя длина таких кодов не превышает величины Hб*1,049, где Hб — энтропия базы элементов, вычисляемая по частотам появления элементов в видеопотоке. В численных экспериментах с реальными фильмами Hб никогда не превышала 20, а это значит, что Hб*1,049 б+1, откуда следует, что средняя длина кодов секущих укладывается в те же априорные оценки избыточности, что коды Шеннона-Фано и Хаффмана. При этом кодирование с помощью секущих функций лишено тех недостатков, которые возникают при кодировании и декодировании вышеназванными методами цифровых массивов больших размеров (Nб≈107–109).Формирование схемы сжатой передачи фильма
В сжатом видеопотоке элементы заменяются полученными ранее короткими кодами. При воспроизведении сжатого видеопотока возникает проблема декодирования. Для декодирования необходимо иметь информацию о соответствии коротких кодов и элементов базы. Самым простым способом передачи такой информации является непосредственная передача элемента и его частоты (количества появлений). Такой способ подразумевает передачу самой базы, а также дополнительных 64 бит на каждый элемент. Принимающая сторона после получения данных сама должна построить кодовое дерево по заранее сообщённому алгоритму.Был предложен способ записи и передачи дерева, в листьях которого записана вся база элементов. При этом объём передачи равен объёму базы плюс два дополнительных бита на каждый элемент базы ((k+2)*Nб).Договоримся о порядке обхода дерева: например, будем использовать обход в ширину. Если встречается делящий узел дерева, то передаётся бит 0, если в процессе обхода был обнаружен лист, то передаётся бит 1 и соответствующий элемент базы. В итоге легко показать, что на каждый элемент базы дополнительно передаётся всего 2 лишних бита. На рисунке показано представление двоичного дерева в виде двоичной строки с помощью описанного метода: 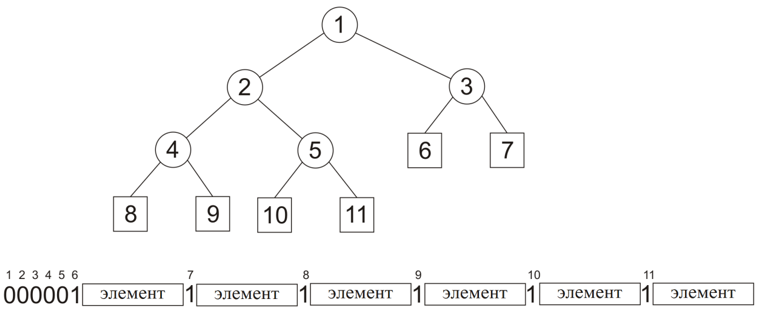 Указанное представление обратимо: для каждой строки, построенной описанным способом, можно построить исходное кодовое дерево. Помимо очевидной экономии памяти описанный способ передачи избавляет от необходимости строить кодовое дерево при декодировании (оно восстанавливается естественным образом). То есть кодовое дерево строится только один раз во время сжатия.Таким образом в работе предлагается схема передачи видеопотока, состоящая из двух частей: кодовое дерево с элементами базы и цепочка сжатых кодов элементов.Примерная структура сжатого видеопотока приведена на рисунке:
Указанное представление обратимо: для каждой строки, построенной описанным способом, можно построить исходное кодовое дерево. Помимо очевидной экономии памяти описанный способ передачи избавляет от необходимости строить кодовое дерево при декодировании (оно восстанавливается естественным образом). То есть кодовое дерево строится только один раз во время сжатия.Таким образом в работе предлагается схема передачи видеопотока, состоящая из двух частей: кодовое дерево с элементами базы и цепочка сжатых кодов элементов.Примерная структура сжатого видеопотока приведена на рисунке:  Степень сжатия, обеспечиваемая алгоритмом фрагментарного сжатия, во многом зависит от свойств и характеристик сформированной базы элементов. Основными характеристиками базы являются размер (количество элементов) и частотные характеристики (в первую очередь энтропия).Для оценки достижимой степени сжатия воспользуемся следующими формулами. Пусть lср — средняя длина кодов элементов базы, тогда объём сжатой передачи равен Vсж=Nб (k+2)+lср*Nф, а объём несжатого фильма при этом равен Vф=Nф*k.Степенью сжатия назовём величину: Rсж=Vсж/Vф. Обратная степени сжатия величина называется коэффициентом сжатия и обозначается Kсж.Основная цель, которой надо стремиться, — максимизация Kсж. В формуле, приведённой выше, N1, N2, M, bpp — характеристики исходного видеопотока, на которые мы влиять не можем. А величины lср, Nбазы зависят от площади и конфигурации окна сканирования (n1, n2). Т.е. единственными вариабельными параметрами в методе фрагментарного сжатия являются геометрические размеры окна.Для любого размера окна существует максимально возможный объём базы, равный 2bpp*n1*n2, и эта величина растёт чрезвычайно быстро. Конечно, в реальных фильмах встречаются далеко не все возможные элементы, но с увеличением размера окна растёт и количество бит, необходимое для представления соответствующего элемента базы. Кроме того, появляется существенное количество (более 70% от общего числа) элементов, которые встречаются в видеопотоке не более одного раза. В конечном итоге все перечисленные эффекты приводят к уменьшению коэффициента сжатия.С другой стороны, слишком маленький размер окна приведёт к росту Nф и ограничению Nб, что в свою очередь приведёт к тому, что элементы будут повторяться более равномерно и «перекос» частот сгладится. Чем равномернее повторяются элементы базе, тем ближе её энтропия к log2Nб. Это в свою очередь тоже приводит к уменьшению коэффициента сжатия.Рассмотрим два крайних случая окно 1×1 и окно N1*N2. И в первом, и во втором случае Kсж≈1. В процессе исследований было установлено, что зависимость Kсж от площади окна сканирования (n1*n2) имеет примерно следующий вид:
Степень сжатия, обеспечиваемая алгоритмом фрагментарного сжатия, во многом зависит от свойств и характеристик сформированной базы элементов. Основными характеристиками базы являются размер (количество элементов) и частотные характеристики (в первую очередь энтропия).Для оценки достижимой степени сжатия воспользуемся следующими формулами. Пусть lср — средняя длина кодов элементов базы, тогда объём сжатой передачи равен Vсж=Nб (k+2)+lср*Nф, а объём несжатого фильма при этом равен Vф=Nф*k.Степенью сжатия назовём величину: Rсж=Vсж/Vф. Обратная степени сжатия величина называется коэффициентом сжатия и обозначается Kсж.Основная цель, которой надо стремиться, — максимизация Kсж. В формуле, приведённой выше, N1, N2, M, bpp — характеристики исходного видеопотока, на которые мы влиять не можем. А величины lср, Nбазы зависят от площади и конфигурации окна сканирования (n1, n2). Т.е. единственными вариабельными параметрами в методе фрагментарного сжатия являются геометрические размеры окна.Для любого размера окна существует максимально возможный объём базы, равный 2bpp*n1*n2, и эта величина растёт чрезвычайно быстро. Конечно, в реальных фильмах встречаются далеко не все возможные элементы, но с увеличением размера окна растёт и количество бит, необходимое для представления соответствующего элемента базы. Кроме того, появляется существенное количество (более 70% от общего числа) элементов, которые встречаются в видеопотоке не более одного раза. В конечном итоге все перечисленные эффекты приводят к уменьшению коэффициента сжатия.С другой стороны, слишком маленький размер окна приведёт к росту Nф и ограничению Nб, что в свою очередь приведёт к тому, что элементы будут повторяться более равномерно и «перекос» частот сгладится. Чем равномернее повторяются элементы базе, тем ближе её энтропия к log2Nб. Это в свою очередь тоже приводит к уменьшению коэффициента сжатия.Рассмотрим два крайних случая окно 1×1 и окно N1*N2. И в первом, и во втором случае Kсж≈1. В процессе исследований было установлено, что зависимость Kсж от площади окна сканирования (n1*n2) имеет примерно следующий вид: 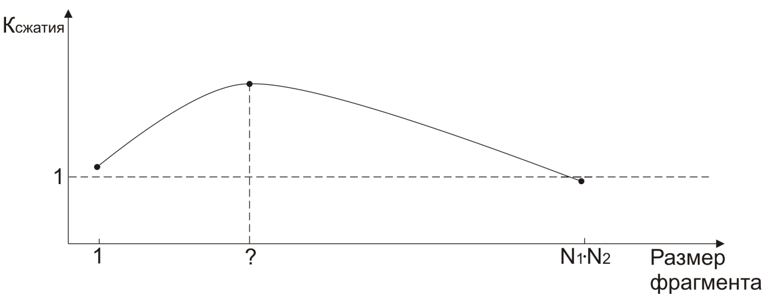 Задача заключается в том, чтобы найти точку, где уровень сжатия максимальный. Т.к. уровень сжатия во многом зависит и от характеристик фильма, понятно, что не существует «идеальной» конфигурации, которая будет давать оптимальное сжатие для всех фильмов. Но эксперименты позволили найти сравнительно небольшую область, где сжатие оптимально.Все анализируемые видеопотоки были разделены на две группы в зависимости от их особенностей: Естественные съёмки. К этой группе относится большинство фильмов, телепередач и любительских съёмок. Для фильмов этой группы характерно плавное изменение кадров с течением времени. При этом изменения достаточно плавные и сконцентрированы в центре кадра. Фон в большинстве случаев однородный, но возможны небольшие колебания яркости.
Для выбора оптимальной конфигурации окна видеопотоки, принадлежащие каждой группе, были сжаты с использованием фрагментарного метода сжатия. В ходе исследований были проанализированы все возможные конфигурации окон площадью от одного до восьми пикселей (в качестве элементов использовались логические разности). В сумме было проанализировано около десяти тысяч часов видео, что составляет около миллиарда кадров. Полученные результаты представлены на графиках.
Задача заключается в том, чтобы найти точку, где уровень сжатия максимальный. Т.к. уровень сжатия во многом зависит и от характеристик фильма, понятно, что не существует «идеальной» конфигурации, которая будет давать оптимальное сжатие для всех фильмов. Но эксперименты позволили найти сравнительно небольшую область, где сжатие оптимально.Все анализируемые видеопотоки были разделены на две группы в зависимости от их особенностей: Естественные съёмки. К этой группе относится большинство фильмов, телепередач и любительских съёмок. Для фильмов этой группы характерно плавное изменение кадров с течением времени. При этом изменения достаточно плавные и сконцентрированы в центре кадра. Фон в большинстве случаев однородный, но возможны небольшие колебания яркости.
Для выбора оптимальной конфигурации окна видеопотоки, принадлежащие каждой группе, были сжаты с использованием фрагментарного метода сжатия. В ходе исследований были проанализированы все возможные конфигурации окон площадью от одного до восьми пикселей (в качестве элементов использовались логические разности). В сумме было проанализировано около десяти тысяч часов видео, что составляет около миллиарда кадров. Полученные результаты представлены на графиках.
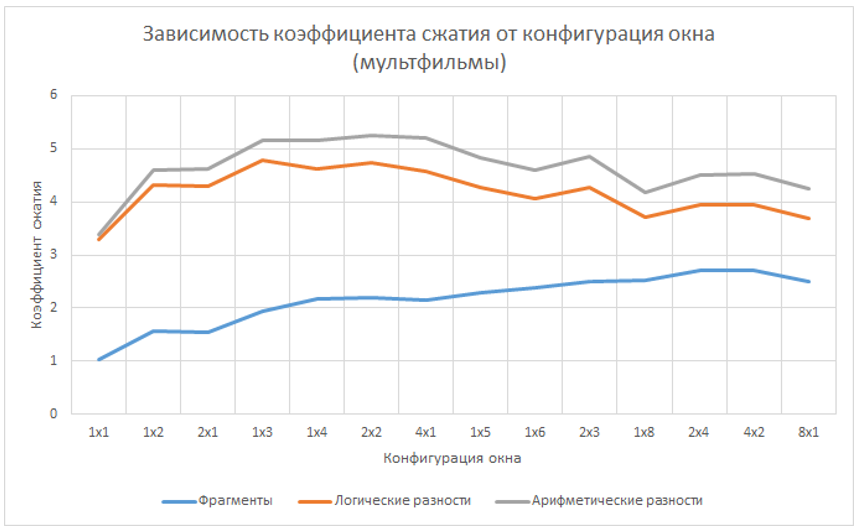 Из представленных данных очевидно, что максимального коэффициента сжатия можно достичь при использовании окон площадью в три, четыре или пять пикселей. Также при практическом использовании метода фрагментарного сжатия видеопотока надо учитывать, что при фиксированной площади окна наибольшая эффективность сжатия наблюдается при использовании прямоугольного окна с соотношением сторон близким 2/1.Кодирование видеопотока в различных цветовых пространствах
Рассмотренные ранее результаты относились к ситуации кодирования видеопотока, содержащего только яркостную компоненту (так называемого монохромного видеопотока). Больший практический интерес представляют методы, позволяющие кодировать цветные видеопотоки.Самым простым способом кодирования цветного видеопотока является независимое кодирование цветовых каналов. Был также рассмотрен способ, при котором базы элементов, собранные для независимых цветовых каналов, объединялись в одну общую базу. Несмотря на то, что доля базы в передаче при этом уменьшалась, рост эффективности сжатия был незначительным. Также было показано, что эффективность метода фрагментарного сжатия в пространстве YIQ существенно выше, чем в пространстве RGB. В первую очередь этот эффект связан с потерями, возникающими при преобразовании цветовых пространств.
Из представленных данных очевидно, что максимального коэффициента сжатия можно достичь при использовании окон площадью в три, четыре или пять пикселей. Также при практическом использовании метода фрагментарного сжатия видеопотока надо учитывать, что при фиксированной площади окна наибольшая эффективность сжатия наблюдается при использовании прямоугольного окна с соотношением сторон близким 2/1.Кодирование видеопотока в различных цветовых пространствах
Рассмотренные ранее результаты относились к ситуации кодирования видеопотока, содержащего только яркостную компоненту (так называемого монохромного видеопотока). Больший практический интерес представляют методы, позволяющие кодировать цветные видеопотоки.Самым простым способом кодирования цветного видеопотока является независимое кодирование цветовых каналов. Был также рассмотрен способ, при котором базы элементов, собранные для независимых цветовых каналов, объединялись в одну общую базу. Несмотря на то, что доля базы в передаче при этом уменьшалась, рост эффективности сжатия был незначительным. Также было показано, что эффективность метода фрагментарного сжатия в пространстве YIQ существенно выше, чем в пространстве RGB. В первую очередь этот эффект связан с потерями, возникающими при преобразовании цветовых пространств.
 Стоит также отметить, что эффективность сжатия в пространстве YIQ может быть существенно повышена за счёт грубого квантования цветоразностных каналов.На сегодняшний день существуют методы, позволяющие сжимать видеопотоки без потерь. Некоторые из них узкоспециализированы и эффективны только на одном типе видеопотоков (например, на записи экрана), другие методы оказываются эффективны на различных видеопотоках. Данный раздел посвящён сравнению эффективности предложенного метода фрагментарного сжатия видеопотока с известными методами.В Graphics & Media Lab Video Group при МГУ им. Ломоносова было выполнено обширное сравнение алгоритмов сжатия видео без потерь по множеству параметров (скорости компрессии, расходу ресурсов, эффективности сжатия и т.д.). Наиболее важной характеристикой является эффективность сжатия. По этому критерию были проанализированы следующие кодеки: Alpary
ArithYuv
AVIzlib
CamStudio GZIP
CorePNG
FastCodec
FFV1
Huffyuv
Lagarith
LOCO
LZO
MSU Lab
PICVideo
Snow
x264
YULS
Сравнение выполнялось на стандартных тестовых последовательностях. Каждая видеопоследовательность была сжата каждым кодеком независимо. Полученные результаты приведены на графике:
Стоит также отметить, что эффективность сжатия в пространстве YIQ может быть существенно повышена за счёт грубого квантования цветоразностных каналов.На сегодняшний день существуют методы, позволяющие сжимать видеопотоки без потерь. Некоторые из них узкоспециализированы и эффективны только на одном типе видеопотоков (например, на записи экрана), другие методы оказываются эффективны на различных видеопотоках. Данный раздел посвящён сравнению эффективности предложенного метода фрагментарного сжатия видеопотока с известными методами.В Graphics & Media Lab Video Group при МГУ им. Ломоносова было выполнено обширное сравнение алгоритмов сжатия видео без потерь по множеству параметров (скорости компрессии, расходу ресурсов, эффективности сжатия и т.д.). Наиболее важной характеристикой является эффективность сжатия. По этому критерию были проанализированы следующие кодеки: Alpary
ArithYuv
AVIzlib
CamStudio GZIP
CorePNG
FastCodec
FFV1
Huffyuv
Lagarith
LOCO
LZO
MSU Lab
PICVideo
Snow
x264
YULS
Сравнение выполнялось на стандартных тестовых последовательностях. Каждая видеопоследовательность была сжата каждым кодеком независимо. Полученные результаты приведены на графике:  Для удобства анализа полученные значения коэффициентов сжатия были усреднены, и полученные средние оценки приведены ниже:
Для удобства анализа полученные значения коэффициентов сжатия были усреднены, и полученные средние оценки приведены ниже: 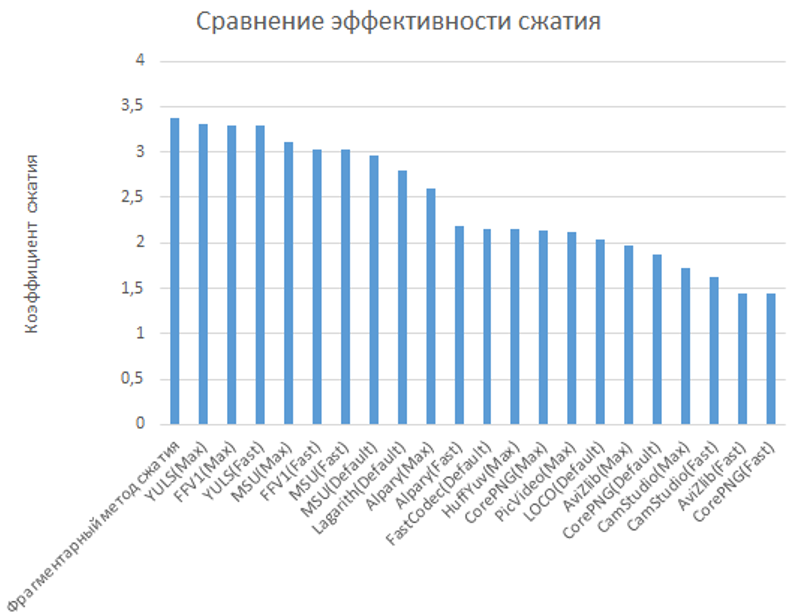 Прямое применение метода фрагментарного сжатия на этих тестовых видеопоследовательностях оказывается малоэффективным. Это объясняется тем, что длительность тестовых видеопотоков очень мала и существенную часть в сжатом методом фрагментарного сжатия фильме составляет база элементов:
Прямое применение метода фрагментарного сжатия на этих тестовых видеопоследовательностях оказывается малоэффективным. Это объясняется тем, что длительность тестовых видеопотоков очень мала и существенную часть в сжатом методом фрагментарного сжатия фильме составляет база элементов:  При достаточной длительности видеопотока (от 5000 кадров) средний коэффициент сжатия метода фрагментарного сжатия составляет 3,38, что превышает коэффициенты сжатия лучших из рассмотренных методов.Если сообществу будет интересно, я расскажу про дерево секущих, которое позволило добиться такого весьма неплохого результата.
При достаточной длительности видеопотока (от 5000 кадров) средний коэффициент сжатия метода фрагментарного сжатия составляет 3,38, что превышает коэффициенты сжатия лучших из рассмотренных методов.Если сообществу будет интересно, я расскажу про дерево секущих, которое позволило добиться такого весьма неплохого результата.
