Механизмы контейнеризации: cgroups

Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре Linux имеется специальный механизм — cgroups (сокращение от control groups, контрольные группы). О нём мы расскажем в сегодняшней статье.
Тема cgroups сегодня особенно актуальна: в ядро версии 4.5, вышедшей в свет в январе текущего года, была официально добавлена новая версия этого механизма — group v2.
В ходе работы над ней cgroups был по сути переписан заново.
Почему потребовались столь радикальные изменения? Чтобы ответить на этот вопрос, рассмотрим в деталях, как была реализована первая версия cgroups.
Cgroups: краткая история
Разработка cgroups была начата в 2006 году сотрудниками Google Полом Менеджем и Рохитом Сетом. Термин «контрольная группа» тогда ещё не использовался, а вместо него употреблялся термин «контейнеры процессов» (process containers). Собственно, сначала они и не ставили перед собой цели создать cgroups в современном понимании. Изначальный замысел был гораздо скромнее: усовершенствовать механизм cpuset, предназначенный для распределения процессорного времени и памяти между задачами. Но со временем всё переросло в более масштабный проект.
В конце 2007 года название process containers было заменено на control groups. Это было сделано, чтобы избежать разночтений в толковании термина «контейнер» (в то время уже активно развивался проект OpenVZ, и слово «контейнер» стало употребляться в новом, современном значении).
В 2008 году механизм cgroups был официально добавлен в ядро Linux (версия 2.6.24). Что нового появилось в этой версии ядра по сравнению с предыдущими?
Ни одного системного вызова, предназначенного специально для работы с cgroups, добавлено не было. В числе главных изменений следует назвать файловую систему cgroups, известную также под названием cgroupfs.
В init/main.c были были добавлены отсылки к функциям для активации cgoups во время загрузки: cgroup_init и cgroup_init_early. Были незначительно изменены функции, используемые для порождения и завершения процесса — fork () и exit ().
В виртуальной файловой системе /proc появились новые директории: /proc/{pid}/сgroup (для каждого процесса) и /proc/cgroups (для системы в целом).
Архитектура
Механизм cgroups состоит из двух составных частей: ядра (cgroup core) и так называемых подсистем. В ядре версии 4.4.0.21 таких подсистем 12:
- blkio — устанавливает лимиты на чтение и запись с блочных устройств;
- cpuacct — генерирует отчёты об использовании ресурсов процессора;
- cpu — обеспечивает доступ процессов в рамках контрольной группы к CPU;
- cpuset — распределяет задачи в рамках контрольной группы между процессорными ядрами;
- devices — разрешает или блокирует доступ к устройствам;
- freezer — приостанавливает и возобновляет выполнение задач в рамках контрольной группы
- hugetlb — активирует поддержку больших страниц памяти для контрольных групп;
- memory — управляет выделением памяти для групп процессов;
- net_cls — помечает сетевые пакеты специальным тэгом, что позволяет идентифицировать пакеты, порождаемые определённой задачей в рамках контрольной группы;
- netprio — используется для динамической установки приоритетов по трафику;
- pids — используется для ограничения количества процессов в рамках контрольной группы.
Вывести список подсистем на консоль можно с помощью команды:
$ ls /sys/fs/cgroup/
blkio cpu,cpuacct freezer net_cls perf_event
cpu cpuset hugetlb net_cls,net_prio pids
cpuacct devices memory net_prio systemd
Каждая подсистема представляет собой директорию с управляющими файлами, в которых прописываются все настройки. В каждой из этих директорий имеются следующие управляющие файлы:
- cgroup.clone_children — позволяет передавать дочерним контрольным группам свойства родительских;
- tasks — содержит список PID всех процессов, включённых в контрольные группы;
cgroup.procs — содержит список TGID групп процессов, включённых в контрольные группы; - cgroup.event_control — позволяет отправлять уведомления в случае изменения статуса контрольной группы;
- release_agent — содержится команда, которая будет выполнена, если включена опция notify_on_release. Может использоваться, например, для автоматического удаления пустых контрольных групп;
- notify_on_release — содержит булеву переменную (0 или 1), включающую (или наоборот отключающую), выполнение команду, указанной в release_agent.
У каждой подсистемы имеются также собственные управляющие файлы. О некоторых из них мы расскажем ниже.
Чтобы создать контрольную группу, достаточно создать вложенную директорию в любой из подсистем. В эту вложенную директорию будут автоматически добавлены управляющие файлы (ниже мы расскажем об этом более подробно). Добавить процессы в группу очень просто: нужно просто записать их PID в управляющий файл tasks.
Совокупность контрольных групп, встроенных в подсистему, называется иерархией.Попробуем разобрать принципы функционирования cgroups на простых практических примерах.
Иерархия cgroups: практическое знакомство
Пример 1: управление процессорными ресурсами
Выполним команду:
$ mkdir /sys/fs/cgroup/cpuset/group0
С помощью этой команды мы создали контрольную группу, в которой содержатся следующие управляющие файлы:
$ ls /sys/fs/cgroup/cpuset/group0
group.clone_children cpuset.memory_pressure
cgroup.procs cpuset.memory_spread_page
cpuset.cpu_exclusive cpuset.memory_spread_slab
cpuset.cpus cpuset.mems
cpuset.effective_cpus cpuset.sched_load_balance
cpuset.effective_mems cpuset.sched_relax_domain_level
cpuset.mem_exclusive notify_on_release
cpuset.mem_hardwall tasks
cpuset.memory_migrate
Пока что в нашей группе никаких процессов нет. Чтобы добавить процесс, нужно записать его PID в файл tasks, например:
$ echo $$ > /sys/fs/cgroup/cpuset/group0/tasks
Cимволами $$ обозначается PID процесса, выполняемого текущей командной оболочкой.
Этот процесс не закреплён ни за одним ядром CPU, что подтверждает следующая команда:
$ cat /proc/$$/status |grep '_allowed'
Cpus_allowed: 2
Cpus_allowed_list: 0-1
Mems_allowed: 00000000,00000001
Mems_allowed_list: 0
Вывод этой команды показывает, что для интересующего нас процесса доступны 2 ядра CPU с номерами 0 и 1.
Попробуем «привязать» этот процесс к ядру с номером 0:
$ echo 0 >/sys/fs/cgroup/cpuset/group0/cpuset.cpus
Проверим, что получилось:
$ cat /proc/$$/status |grep '_allowed'
Cpus_allowed: 1
Cpus_allowed_list: 0
Mems_allowed: 00000000,00000001
Mems_allowed_list: 0
Пример 2: управление памятью
Встроим созданную в предыдущем примере группу ещё в одну подсистему:
$ mkdir /sys/fs/cgroup/memory/group0
Далее выполним:
$ echo $$ > /sys/fs/cgroup/memory/group0/tasks
Попробуем ограничить для контрольной группы group0 потребление памяти. Для этого нам понадобится прописать соответствующий лимит в файле memory.limit_in_bytes:
$ echo 40M > /sys/fs/cgroup/memory/group0/memory.limit_in_bytes
Механизм cgroups предоставляет очень обширные возможности управления памятью. Например, с его помощью мы можем оградить критически важные процессы от попадания под горячую руку OOM-killer«a:
$ echo 1 > /sys/fs/cgroup/memory/group0/memory.oom_control
$ cat /sys/fs/cgroup/memory/group0/memory.oom_control
oom_kill_disable 1
under_oom 0
Если мы поместим в отдельную контрольную группу, например, ssh-демон и отключим для этой группы OOM-killer, то мы можем быть уверены в том, что он не будет «убит» при преувеличении потребления памяти.
Пример 3: управление устройствами
Добавим нашу контрольную группу ещё в одну иерархию:
$ mkdir /sys/fs/cgroup/devices/group0
По умолчанию у группы нет никаких ограничений доступа к устройствам:
$ cat /sys/fs/cgroup/devices/group0/devices.list
a *:* rwm
Попробуем выставить ограничения:
$ echo 'c 1:3 rmw' > /sys/fs/cgroup/devices/group0/devices.deny
Эта команда включит устройство /dev/null в список запрещённых для нашей контрольной группы. Мы записали в управляющий файл строку вида «c 1:3 rmw». Сначала мы указываем тип устройства — в нашем случае это символьное устройство, обозначаемое буквой с (сокращение от character device). Два других типа устройств — это блочные (b) и все возможные устройства (а). Далее следуют мажорный и минорный номера устройства. Узнать номера можно с помощью команды вида:
$ ls -l /dev/null
Вместо /dev/null, естественно, можно указать любой другой путь. Вывод этой команды выглядит так:
crw-rw-rw- 1 root root 1, 3 May 30 10:49 /dev/null
Первая цифра в выводе — это мажорный, а вторая — минорный номер.
Три последние буквы означают права доступа: r — разрешение читать файлы с указанного устройства, w — разрешение записывать на указанное устройство, m — разрешение создавать новые файлы устройств.
Далее выполним:
$ echo $$ > /sys/fs/cgroup/devices/group0/tasks
$ echo "test" > /dev/null
При выполнении последней команды система выдаст сообщение об ошибке:
-bash: /dev/null: Operation not permitted
С устройством /dev/null мы никак взаимодействовать не можем, потому что доступ закрыт.
Восстановим доступ:
$ echo a > /sys/fs/cgroup/devices/group0/devices.allow
В результате выполнения этой команды в файл /sys/fs/cgroup/devices/group0/devices.allow будет добавлена запись a *:* rwm, и все ограничения будут сняты.
Cgroups и контейнеры
Из приведённых примеров понятно, в чём заключается принцип работы cgroups: мы помещаем определённые процессы в группу, которую затем «встраиваем» в подсистемы. Разберём теперь более сложные примеры и рассмотрим, как cgroups используются в современных инструментах контейнеризации на примере LXC.
Установим LXC и создадим контейнер:
$ sudo apt-get install lxc debootstrap bridge-utils
$ sudo lxc-create -n ubuntu -t ubuntu -f /usr/share/doc/lxc/examples/lxc-veth.conf
$ lxc-start -d -n ubuntu
Посмотрим, что изменилось в директории cgroups после создания и запуска контейнера:
$ ls /sys/fs/cgroup/memory
cgroup.clone_children memory.limit_in_bytes memory.swappiness
cgroup.event_control memory.max_usage_in_bytes memory.usage_in_bytes
cgroup.procs memory.move_charge_at_immigrate memory.use_hierarchy
cgroup.sane_behavior memory.numa_stat notify_on_release
lxc memory.oom_control release_agent
memory.failcnt memory.pressure_level tasks
memory.force_empty memory.soft_limit_in_bytes
Как видим, в каждой иерархии появилась директория lxc, которая в свою очередь содержит поддиректорию Ubuntu. Для каждого нового контейнера в директории lxc будет создаваться отдельная поддиректория. PID всех запускаемых в этом контейнере процессов будут записываться в файл /sys/fs/cgroup/cpu/lxc/[имя контейнера]/tasks
Выделять ресурсы для контейнеров можно как с помощью управляющих файлов cgroups, так и с помощью специальных команд lxc, например:
$ lxc-cgroup -n [имя контейнера] memory.limit_in_bytes 400
Аналогичным образом дело обстоит с контейнерами Docker, systemd-nspawn и другими.
Недостатки cgroups
На протяжении почти 10 лет существования механизм cgroups неоднократно подвергался критике. Как отметил автор одной статьи на LWN.net, разработчики ядра cgroups активно не любят. Причины такой нелюбви можно понять даже из приведённых в этой статье примеров, хоть мы и старались подавать их максимально нейтрально, без эмоций: встраивать контрольную группу в каждую подсистему по отдельности очень неудобно. Присмотревшись повнимательней, мы увидим, что такой подход отличается крайней непоследовательностью.
Если мы, например, создаём вложенную контрольную группу, то в некоторых подсистемах настройки родительской группы наследуются, а в некоторых — нет.
В подсистеме cpuset любое изменение в родительской контрольной группе автоматически передаётся вложенным группам, а в других подсистемах такого нет и нужно активировать параметр clone.children.
Об устранении этих и других недостатков cgroups разговоры в сообществе разработчиков ядра шли очень давно: один из первых текстов на эту тему датируется началом 2012 года.
Автор этого текста, инженер Facebook Течжен Хе, прямо указал, что главная проблема cgroups заключается в неправильной организации, при которой подсистемы подключаются к многочисленным иерархиям контрольных групп. Он предложил использовать одну и только одну иерархию, а подсистемы добавлять для каждой группы отдельно. Такой подход повлёк за собой серьёзные изменения вплоть до смены названия: механизм изоляции ресурсов теперь называется cgroup (в единственном числе), а не cgroups.
Разберёмся более подробно в сути реализованных нововведений.
Cgroup v2: что нового
Как уже было отмечено выше, сgroup v2 был включён в ядро Linux начиная с версии ядра 4.5. При этом старая версия поддерживается тоже. Для версии 4.6 уже существует патч, с помощью которого можно отключить поддержку первой версии при загрузке ядра.
На текущий момент в cgroup v2 можно работать только с тремя подсистемами: blkio, memory и PID. Уже появились (пока что в тестовом варианте) патчи, позволяющие управлять ресурсами CPU.
Cgroup v2 монтируется при помощи следующей команды:
$ mount -t cgroup2 none [точка монтирования]
Предположим, мы смонтировали cgroup 2 в директорию /cgroup2. В этой директории будут автоматически созданы следующие управляющие файлы:
- cgroup.controllers — содержит список поддерживаемых подсистем;
- cgroup.procs — по завершении монтирования содержит список всех выполняемых процессов в системе, включая процессы-зомби. Если мы создадим группу, то для неё тоже будет создан такой файл; он будет пустым, пока в группу не добавлены процессы;
- cgroup.subtree_control — содержит список подсистем, активированных для данной контрольной группы; по умолчанию пуст.
Эти же самые файлы создаются в каждой новой контрольной группе. Также в группу добавляется файл cgroup.events, который в корневой директории отсутствует.
Новая группа создаётся так:
$ mkdir /cgroup2/group1
Чтобы добавить для группы подсистему, нужно записать имя этой подсистемы в файл cgroup.subtree_control:
$ echo "+pid" > /cgroup2/group1/cgroup.subtree_control
Для удаления подсистемы используется аналогичная команда, только на место плюса ставится минус:
$ echo "-pid" > /cgroup2/group1/cgroup.subtree_control
Когда для группы активируется подсистема, в ней создаются дополнительные управляющие файлы. Например, после активации подсистемы PID в директории появятся файлы pids.max и pids.current. Первый из этих файлов используется для ограничения числа процессов в группе, а второй — содержит информацию о числе процессов, включённых в группу на текущий момент.
Внутри уже имеющихся групп можно создавать подгруппы:
$ mkdir /cgroup2/group1/subgroup1
$ mkdir /cgroup2/group1/subgroup2
$ echo "+memory" > /cgroup2/group1/cgroup.subtree_control,
Все подгруппы наследуют характеристики родительской группы. В только что приведённом примере подсистема PID будет активирована как для группы group1, так и для обеих вложенных в неё подгрупп; в них также будут добавлены файлы pids.max и pids.current. Сказанное можно проиллюстрировать с помощью схемы:
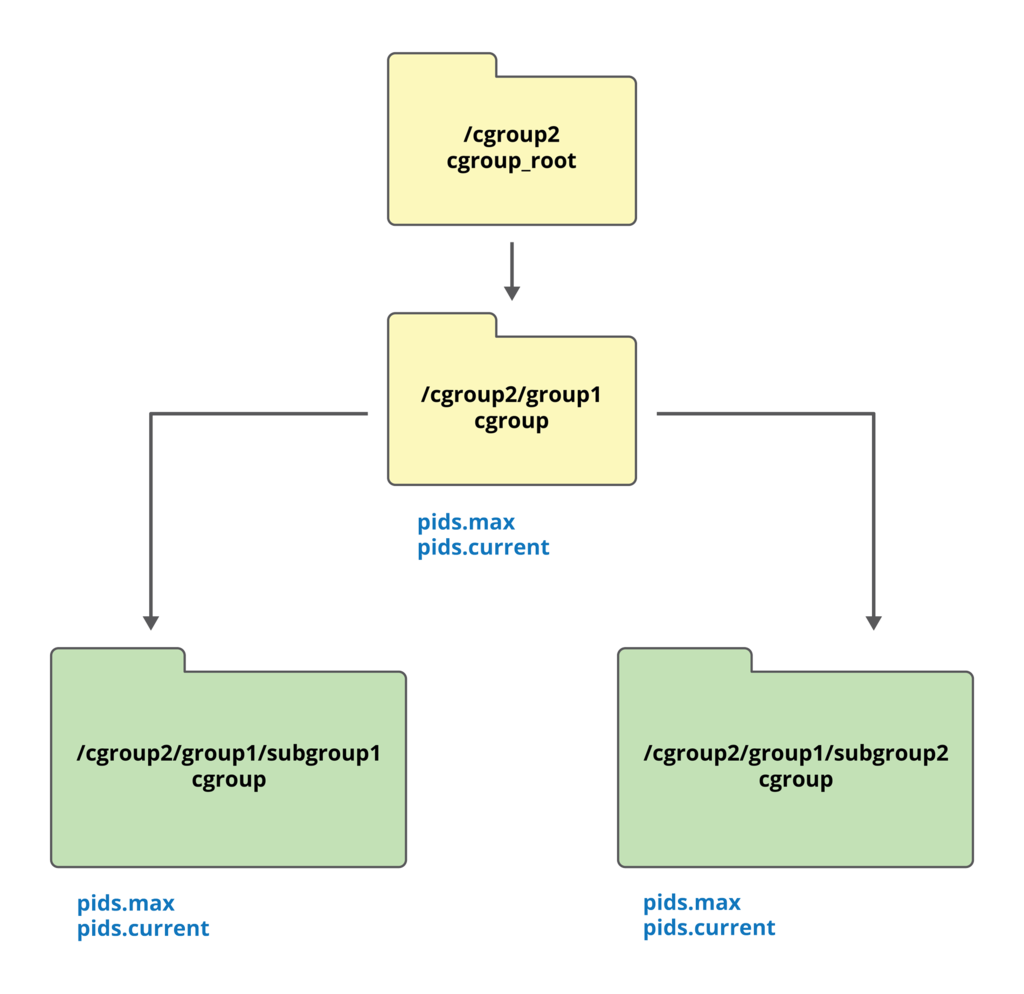
Чтобы избежать недоразумений с вложенными группами (см. выше), в cgroup v2 действует следующее правило: нельзя добавить процесс во вложенную группу, если в ней уже активирована какая-либо подсистема:

В первой версии cgroups процесс мог входить в несколько подгрупп одновременно, если эти подгруппы входили в разные иерархии, встроенные в разные подсистемы. Во второй версии один процесс может принадлежать только к одной подгруппе, что позволяет избежать путаницы.
Заключение
В этой статье мы рассказали, как устроен механизм cgroups и какие изменения были внесены в его новую версию. Если у вас есть вопросы и дополнения — добро пожаловать в комментарии.
Для всех, кто хочет глубже погрузиться в тему, приводим список ссылок на интересные материалы:
Если вы по тем или иным причинам не можете оставлять комментарии здесь, добро пожаловать в наш корпоративный блог.
