Масштабируемая Big Data система в Kubernetes с использованием Spark и Cassandra
В предыдущей статье я рассказал, как организовать систему распределенного машинного обучения на GPU NVidia, используя язык Java с фреймворками Spring, Spark ML, XGBoost, DML в standalone кластере Spark. Особенностью поставленной задачи являлось организация системы под управлением ОС Windows 10 Pro, в Docker-контейнерах. Эксперимент оказался не вполне успешным. В данной статье я покажу, как воспользоваться имеющимися наработками и запустить Spark Jobs в Kubernetes в режимах client и cluster, опишу особенности работы с Cassandra в Spark, покажу пример обучения модели и ее дальнейшего использования. В этот раз буду использовать язык Kotlin. Репозиторий с кодом доступен на GitLab.
Данная статья представляет интерес для тех, кто интересуется системами Big Data и стремится создать систему, позволяющую, в том числе, выполнять задачи распределенного машинного обучения на Spark в Kubernetes, используя GPU NVidia и Cassandra для хранения данных.
Версии библиотек и фреймворков
Первое, что нужно принять во внимание при построении подобной системы — она довольно сложная, с рядом элементов, которые не совместимы друг с другом. Так как используется Rapids, использовать Boot 3 не получится — для него требуется Java 17, и, хоть Spark и поддерживает данную версию, ускоритель GPU-вычислений Rapids на момент написания статьи не поддерживает данную версию в полной мере. Скорее всего, Java 17 будет добавлена в версии, которая также обзаведется поддержкой Spark 3.4.0. По этой причине, последний Spark (на момент написания статьи 3.4.0) брать за основу не стоит. К тому же, DataStax так же не обновила свой cassandra connector, и данная версия не поддерживается.
Версии компонентов, с которыми система заработала:
JDK 8
Spring Boot 2.7.11
Spark 3.3.2
NVidia Rapids 23.04.0
Cassandra 4.1.1
PostgreSQL 15.3–1.pgdg110+1
scala-library 2.12.15
spark-cassandra-connector_2.12 3.3.0
com.fasterxml.jackson.core 2.13.5
На уровне инфраструктуры:
Kubernetes 1.26.3
ContainerD 1.7.0
NVidia GPU Operator 0.13.0
NVidia Driver 530.30.02–1 (ставится с CUDA)
CUDA — желательно не ниже 11.8 в базовом образе NVidia, в последних же драйверах по умолчанию 12+
Ubuntu 22.04.2
Конфигурация стенда:
Узел | CPU | RAM | GPU | Адрес в ЛВС |
master1 | Intel i7–2700k | 16 Gb | NVidia GTX 1650 4 Gb | 192.168.0.150 |
worker1 | AMD 3800x | 32 Gb | NVidia RTX 2600 6 Gb | 192.168.0.125 |
Особенности
Не использовать spring-boot-starter-parent. Он тянет за собой множество библиотек, которые конфликтуют с библиотеками Spark. В том числе, для последующего перехода на Java 17 (выпустят же когда-нибудь разработчики Rapids библиотеку, поддерживающую данную версию) лучше не использовать Tomcat, и использовать Undertow (на момент написания статьи были проблемы с classloader’ами Rapids и Tomcat, а на Undertow успешно запустилось). Но и тут есть особенности: необходимо подключить корректную версию Jackson (указана выше) и ряд библиотек jakarta и javax servlet:
pom.xml
org.glassfish.web
jakarta.servlet.jsp.jstl
3.0.1
jakarta.servlet
jakarta.servlet-api
6.0.0
provided
jakarta.servlet.jsp.jstl
jakarta.servlet.jsp.jstl-api
3.0.0
javax.servlet
javax.servlet-api
4.0.1
provided
ch.qos.logback
logback-classic
1.2.9
Подключить scala-library 2.12.15. Зависимость spark-cassandra-connector_2.12 3.3.0 использует версию 2.12.11, а Spark 3.3.2 — 2.12.15. Если не заменить, будут конфликты SerialVersionUID. Чтобы заменить, в pom.xml просто нужно поставить scala-library перед spark-cassandra-connector.
Могут быть другие нюансы совместимости компонентов, следует быть готовым к отладке. Полностью рабочую конфигурацию можно посмотреть в репозитории.
Подготовка инфраструктуры
В этот раз постараюсь этот вопрос изложить покороче, но на важных моментах остановлюсь подробнее. Подготовка образа executor подробно описана в предыдущей статье, но в этой сам метод сборки будет отличаться. В первую очередь нужно подготовить кластер Kubernetes. Описывать установку не буду, скажу лишь, что взял KubeSpray и раскатал 1.26.3.
Nvidia drivers
Выбрать последнюю Cuda, драйвер поставится автоматом:
install CUDA and NVidia driver
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-ubuntu2204-12-1-local_1
sudo dpkg -i cuda-repo-ubuntu2204-12-1-local_12.1.0-530.30.02-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudaВыполнить шаги установки, перезагрузить машину, проверить:
nvidia-smi
nvidia-smi
Sun Mar 19 20:56:18 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1650 On | 00000000:02:00.0 Off | N/A |
| 0% 47C P2 N/A / 75W| 332MiB / 4096MiB | 2% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1346 G /usr/lib/xorg/Xorg 62MiB |
| 0 N/A N/A 1905 C+G ...libexec/gnome-remote-desktop-daemon 132MiB |
| 0 N/A N/A 2013 G /usr/bin/gnome-shell 131MiB |
+---------------------------------------------------------------------------------------+Донастроить:
nvidia-container-toolkit
sudo -i
apt-get update && apt-get install -y nvidia-container-toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
nvidia-ctk runtime configure --runtime=dockerНе обязательно: запустить для проверки контейнеры со спарк воркерами (можно взять из прошлой статьи).
Containerd
Выполнить:
nano /etc/containerd/config.tomlОтредактировать:
config.toml
version = 2
root = "/var/lib/containerd"
state = "/run/containerd"
oom_score = 0
[grpc]
max_recv_message_size = 16777216
max_send_message_size = 16777216
[debug]
level = "info"
[metrics]
address = ""
grpc_histogram = false
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.k8s.io/pause:3.8"
max_container_log_line_size = -1
enable_unprivileged_ports = false
enable_unprivileged_icmp = false
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
snapshotter = "overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
runtime_engine = ""
runtime_root = ""
base_runtime_spec = "/etc/containerd/cri-base.json"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
systemdCgroup = true
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://registry-1.docker.io"]
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.configs."registry-1.docker.io".auth]
username = "login"
password = "password"
auth = ""
identitytoken = ""Обращаю внимание на последнюю секцию — в ней указывается ваш репозиторий, здесь я привел пример с публичным Docker Hub "registry-1.docker.io".
Перезапустить сервис:
sudo systemctl restart containerdKubernetes
Начиная с версии Spark 3.1.1, поддержка Spark в Kubernetes доведена production-ready. Это означает, что появлилась возможность использовать Kubernetes как менеджер кластера Spark, указывая в качестве мастера Kube API Server:
k8s://https://${KUBE_API_SERVER}:6443или
k8s://https://kubernetes.default.svcТеперь, при запуске Spark Job, в кластере K8S будут запускаться Spark Executors с указанным Docker образом, ресурсами и прочими необходимыми конфигами. Если образ уже находится в локальном репозитории машины, POD поднимается довольно быстро, на моих машинах в течении 5 секунд после старта приложения поднимались 2 экзекуктора, полностью готовых к работе.
В связке со Spring приложением есть возможность создать Spring Bean с JavaSparkContext/SparkSession. Однако, есть другой способ: создавать SparkSession под каждую Spark Job, чтобы высвобождать ресурсы кластера. Это хорошо для редких задач по расписанию / запросу, в том числе запросам с различающимся количеством необходимых ресурсов (количество Spark Executors, CPU, память, видеопамять и т.п.), но имеет накладные расходы на поднятие экзекуторов и время выполнения задач. На моей практике все команды для работы со Spark требовали «прогрева», т.е. каждая первая операция выполнялась дольше, чем все последующие. Стоит иметь это в виду, и, если необходимо постоянно запускать одинаковые задачи по расписанию, имеет смысл зарезервировать ресурсы кластера под спарковые экзекуторы.
Nvidia GPU Operator
Для использования ресурсов GPU внутри кластера Kubernetes необходимо установить Nvidia GPU Operator. Следует выполнить:
Install GPU Operator
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.13.0/nvidia-device-plugin.yml
helm repo add nvidia https://nvidia.github.io/gpu-operator
helm repo update
kubectl create ns gpu-operator
helm install --wait gpu-operator \
-n gpu-operator \
nvidia/gpu-operator \
--set operator.defaultRuntime=containerdПроверить работу можно следующим образом:
kubectl run gpu-test \
--rm -t -i \
--restart=Never \
--image=nvcr.io/nvidia/cuda:10.1-base-ubuntu18.04 nvidia-smiВ случае успеха вернется результат nvidia-smi:
В целях проверки можно запустить deployment с двумя репликами заготовленного образа Spark executor:
executor deployment
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: cuda-example
spec:
replicas: 2
selector:
matchLabels:
app: cuda-example
template:
metadata:
labels:
app: cuda-example
spec:
containers:
- name: cuda-jdk8
image: repo/cuda-jdk8-spark-3.3.2:v2
resources:
limits:
cpu: 2
memory: 4Gi
nvidia.com/gpu: 1
requests:
cpu: "200m"
memory: 0.5Gi
nvidia.com/gpu: 1на каждой машине должно подняться по одному поду, и, если экзекнуться в них, команда nvidia-smi должна вывести результат. Обращаю внимание, что для запуска экзекуторов не нужно поднимать их вручную, K8S Scheduler сделает это сам. Манифест приведен для примера и проверки работоспособности GPU Operator, после проверки его можно удалить.
Образ Spark executor
Следует изменить spark/kubernetes/dockerfiles/Dockerfile:
Dockerfile
ARG java_image_tag=17-jre
FROM ${java_image_tag}
ARG spark_uid=1001
ARG UID_GID=1001
ENV UID=${UID_GID}
ENV GID=${UID_GID}
ENV SPARK_RAPIDS_DIR=/opt/sparkRapidsPlugin
ENV SPARK_RAPIDS_PLUGIN_JAR=${SPARK_RAPIDS_DIR}/rapids-4-spark_2.12-23.04.0.jar
RUN set -ex && \
sed -i 's/http:\/\/deb.\(.*\)/https:\/\/deb.\1/g' /etc/apt/sources.list && \
apt-get update && \
ln -s /lib /lib64 && \
apt install -y bash tini libc6 libpam-modules libnss3 procps nano iputils-ping net-tools iptables sudo \
wget software-properties-common build-essential libnss3-dev zlib1g-dev libgdbm-dev libncurses5-dev \
libssl-dev libffi-dev libreadline-dev libsqlite3-dev libbz2-dev python3 && \
mkdir -p /opt/spark && \
mkdir -p /opt/spark/examples && \
mkdir -p /opt/spark/conf && \
mkdir -p /opt/spark/work-dir && \
mkdir -p /opt/sparkRapidsPlugin && \
touch /opt/spark/RELEASE && \
rm /bin/sh && \
ln -sv /bin/bash /bin/sh && \
echo "auth required pam_wheel.so use_uid" >> /etc/pam.d/su && \
chgrp root /etc/passwd && chmod ug+rw /etc/passwd && \
rm -rf /var/cache/apt/*
RUN apt-get install libnccl2 libnccl-dev -y --allow-change-held-packages && rm -rf /var/cache/apt/*
COPY jars /opt/spark/jars
COPY rapids ${SPARK_RAPIDS_DIR}
COPY extraclasspath /opt/spark/extraclasspath
COPY bin /opt/spark/bin
COPY sbin /opt/spark/sbin
COPY conf /opt/spark/conf
COPY kubernetes/dockerfiles/spark/entrypoint.sh /opt/
COPY kubernetes/dockerfiles/spark/decom.sh /opt/
COPY kubernetes/tests /opt/spark/tests
COPY data /opt/spark/data
COPY datasets /opt/spark/
ENV SPARK_HOME /opt/spark
WORKDIR /opt/spark/work-dir
RUN chmod g+w /opt/spark/work-dir
RUN chmod a+x /opt/decom.sh
RUN chmod a+x /opt/entrypoint.sh
RUN chmod a+x /opt/sparkRapidsPlugin/getGpusResources.sh
RUN ls -lah /opt
RUN groupadd --gid $UID appuser && useradd --uid $UID --gid appuser --shell /bin/bash --create-home appuser
RUN mkdir /var/logs && chown -R appuser:appuser /var/logs
RUN mkdir /opt/spark/logs && chown -R appuser:appuser /opt/spark/
RUN chown -R appuser:appuser /tmp
RUN ls -lah /home/appuser
RUN touch /home/appuser/.bashrc
RUN echo -e '\
export SPARK_HOME=/opt/spark\n\
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin\
' > /home/appuser/.bashrc
RUN chown -R appuser:appuser /home/appuser
EXPOSE 4040
EXPOSE 8081
USER ${spark_uid}
ENTRYPOINT [ "/opt/entrypoint.sh" ]entrypoint.sh из прошлой статьи пригодится, но для локального standalone кластера из одного воркера (подходит для отладки в Windows). spark/kubernetes/dockerfiles/entrypoint.sh следует изменить до стандартного вида:
entryoint.sh
#!/bin/bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# echo commands to the terminal output
set -ex
# Check whether there is a passwd entry for the container UID
myuid=$(id -u)
mygid=$(id -g)
# turn off -e for getent because it will return error code in anonymous uid case
set +e
uidentry=$(getent passwd $myuid)
set -e
# If there is no passwd entry for the container UID, attempt to create one
if [ -z "$uidentry" ] ; then
if [ -w /etc/passwd ] ; then
echo "$myuid:x:$myuid:$mygid:${SPARK_USER_NAME:-anonymous uid}:$SPARK_HOME:/bin/false" >> /etc/passwd
else
echo "Container ENTRYPOINT failed to add passwd entry for anonymous UID"
fi
fi
SPARK_CLASSPATH="$SPARK_CLASSPATH:${SPARK_HOME}/jars/*"
env | grep SPARK_JAVA_OPT_ | sort -t_ -k4 -n | sed 's/[^=]*=\(.*\)/\1/g' > /tmp/java_opts.txt
readarray -t SPARK_EXECUTOR_JAVA_OPTS < /tmp/java_opts.txt
if [ -n "$SPARK_EXTRA_CLASSPATH" ]; then
SPARK_CLASSPATH="$SPARK_CLASSPATH:$SPARK_EXTRA_CLASSPATH"
fi
if ! [ -z ${PYSPARK_PYTHON+x} ]; then
export PYSPARK_PYTHON
fi
if ! [ -z ${PYSPARK_DRIVER_PYTHON+x} ]; then
export PYSPARK_DRIVER_PYTHON
fi
# If HADOOP_HOME is set and SPARK_DIST_CLASSPATH is not set, set it here so Hadoop jars are available to the executor.
# It does not set SPARK_DIST_CLASSPATH if already set, to avoid overriding customizations of this value from elsewhere e.g. Docker/K8s.
if [ -n "${HADOOP_HOME}" ] && [ -z "${SPARK_DIST_CLASSPATH}" ]; then
export SPARK_DIST_CLASSPATH="$($HADOOP_HOME/bin/hadoop classpath)"
fi
if ! [ -z ${HADOOP_CONF_DIR+x} ]; then
SPARK_CLASSPATH="$HADOOP_CONF_DIR:$SPARK_CLASSPATH";
fi
if ! [ -z ${SPARK_CONF_DIR+x} ]; then
SPARK_CLASSPATH="$SPARK_CONF_DIR:$SPARK_CLASSPATH";
elif ! [ -z ${SPARK_HOME+x} ]; then
SPARK_CLASSPATH="$SPARK_HOME/conf:$SPARK_CLASSPATH";
fi
case "$1" in
driver)
shift 1
CMD=(
"$SPARK_HOME/bin/spark-submit"
--conf "spark.driver.bindAddress=$SPARK_DRIVER_BIND_ADDRESS"
--deploy-mode client
"$@"
)
;;
executor)
shift 1
CMD=(
${JAVA_HOME}/bin/java
"${SPARK_EXECUTOR_JAVA_OPTS[@]}"
-Xms$SPARK_EXECUTOR_MEMORY
-Xmx$SPARK_EXECUTOR_MEMORY
-cp "$SPARK_CLASSPATH:$SPARK_DIST_CLASSPATH"
org.apache.spark.executor.CoarseGrainedExecutorBackend
--driver-url $SPARK_DRIVER_URL
--executor-id $SPARK_EXECUTOR_ID
--cores $SPARK_EXECUTOR_CORES
--app-id $SPARK_APPLICATION_ID
--hostname $SPARK_EXECUTOR_POD_IP
--resourceProfileId $SPARK_RESOURCE_PROFILE_ID
)
;;
*)
echo "Non-spark-on-k8s command provided, proceeding in pass-through mode..."
CMD=("$@")
;;
esac
# Execute the container CMD under tini for better hygiene
exec /usr/bin/tini -s -- "${CMD[@]}"
Файл spark/kubernetes/dockerfiles/decom.sh должен выглядеть следующим образом:
decom.sh
#!/usr/bin/env bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
set -ex
echo "Asked to decommission"
# Find the pid to signal
date | tee -a ${LOG}
WORKER_PID=$(ps -o pid -C java | tail -n 1| awk '{ sub(/^[ \t]+/, ""); print }')
echo "Using worker pid $WORKER_PID"
kill -s SIGPWR ${WORKER_PID}
# For now we expect this to timeout, since we don't start exiting the backend.
echo "Waiting for worker pid to exit"
# If the worker does exit stop blocking the cleanup.
timeout 60 tail --pid=${WORKER_PID} -f /dev/null
date
echo "Done"
date
sleep 1
Скрипт сборки образов, который собирает два образа — для чистого JVM и PySpark (на всякий случай):
build-java-8-spark-3.3.2.sh
#!/bin/bash
echo "=========== 1st stage ==========="
echo "Docker repo: $DOCKER_REPO"
echo "### build base cuda11.8 java8 image ###"
docker build -f Dockerfile-cuda-java8 -t localhost:5000/cuda11.8-jdk8:v1 .
echo "=========== 2nd stage ==========="
echo "### build Spark and PySpark images ###"
cd spark-3.3.2
./bin/docker-image-tool.sh -r localhost:5000 \
-t jdk8-3.3.2 -b java_image_tag=localhost:5000/cuda11.8-jdk8:v1 \
-p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile \
-n build
cd ..
docker tag localhost:5000/spark-py:jdk8-3.3.2 $DOCKER_REPO/cuda-jdk8-spark-py-3.3.2:v2
docker tag localhost:5000/spark:jdk8-3.3.2 $DOCKER_REPO/cuda-jdk8-spark-3.3.2:v2
echo "=========== 3rt stage ==========="
echo "### push Spark and PySpark images ###"
docker push $DOCKER_REPO/cuda-jdk8-spark-py-3.3.2:v2
docker push $DOCKER_REPO/cuda-jdk8-spark-3.3.2:v2
, где $DOCKER_REPO — ваш репозиторий Docker.
Для сборки образа executor необходим образ localhost:5000/cuda-jdk8:v1. Его можно собрать со следующим Dockerfile:
Dockerfile localhost:5000/cuda11.8-jdk8: v1
FROM nvcr.io/nvidia/cuda:11.8.0-runtime-ubuntu22.04
ENV LANG='en_US.UTF-8' LANGUAGE='en_US:en' LC_ALL='en_US.UTF-8'
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt install -y bash tini libc6 libpam-modules libnss3 procps nano iputils-ping net-tools
RUN apt-get update && \
apt-get install -y openjdk-8-jdk && \
apt-get install -y ant && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
rm -rf /var/cache/oracle-jdk8-installer;
RUN apt-get update && \
apt-get install -y ca-certificates-java && \
apt-get clean && \
update-ca-certificates -f && \
rm -rf /var/lib/apt/lists/* && \
rm -rf /var/cache/oracle-jdk8-installer;
ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64/
RUN export JAVA_HOME
CMD ["tail", "-f", "/dev/null"]
Команда сборки приведена в скрипте выше:
docker build -f Dockerfile-cuda-java8 -t localhost:5000/cuda-jdk8:v1 .Требования для запуска Spark Driver
Service account
Для драйвера необходим K8S Service Account с полными правами на неймспейс (в данном примере namespace default, но в продуктивном кластере, разумеется, следует выделять отдельный namespace). Следующий манифест создает необходимы SA и CRB:
Service Account и ClusterRoleBinding
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark-driver
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: spark-driver-crb
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: spark-driver
namespace: default
Имя SA указывается в конфиге SparkContext:
.set("spark.kubernetes.authenticate.driver.serviceAccountName", driverSa)В манифесте приложения так же указывается SA:
serviceAccountName: spark-driverВ идеале, для Executor необходим отдельный SA с ограниченными правами (ClusterRole «edit»), но в данном примере он не конфигурировался.
Headless service
Для того, чтобы экзекуторы могли делать запросы к драйверу, необходимо сделать headless service:
kubectl expose pod $SPARK_DRIVER_NAME --port=$SPARK_DRIVER_PORT \
--type=ClusterIP --cluster-ip=NoneМанифест такого сервиса выглядит следующим образом:
headless service
kind: Service
apiVersion: v1
metadata:
labels:
app: ml-app
name: ml-app
spec:
type: ClusterIP
clusterIP: None
clusterIPs:
- None
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: driver-port
port: 33139
targetPort: 33139
protocol: TCP
- name: block-manager-port
port: 45029
targetPort: 45029
protocol: TCP
selector:
app: ml-app
sessionAffinity: NoneЗапуск Spring приложения
На ряду с указанием мастера, необходимо указать параметр
spark.submit.deployModeЗначением cluster или client.
Cluster mode
В режиме работы Cluster приложение (spark driver) существует вне кластера K8S, его под не создается внутри кластера. Хорошо подходит для отладки, либо когда приложение запускается в отдельном кластере/сервере.
Client mode
В режиме работы Client приложение (spark driver) существует в кластере, поднимается как POD. При этом следует указать дополнительные настройки (будет рассмотрено ниже, в разделе с конфигурацией приложения).
Манифест приложения
application.yml
---
apiVersion: v1
kind: Pod
metadata:
labels:
app: ml-app
name: ml-app
spec:
serviceAccountName: spark-driver
containers:
- name: ml-app
image: repo/ml:cuda11.8-jdk8
imagePullPolicy: Always
env:
- name: "SPARK_EXECUTORS"
value: "2"
- name: "SPARK_MODE"
value: "client"
- name: "POSTGRES_HOST"
value: "192.168.0.125"
- name: "CASSANDRA_HOST"
value: "192.168.0.125,192.168.0.150"
# add your own env vars from ConfigMaps/Secrets
resources:
limits:
cpu: "2"
memory: 4Gi
requests:
cpu: "200m"
memory: 0.5Gi
ports:
- containerPort: 4040
- containerPort: 9090
- containerPort: 33139
- containerPort: 45029
---
kind: Service
apiVersion: v1
metadata:
labels:
app: ml-app
name: ml-app
spec:
type: ClusterIP
clusterIP: None
clusterIPs:
- None
internalTrafficPolicy: Cluster
ipFamilies:
- IPv4
ipFamilyPolicy: SingleStack
ports:
- name: driver-port
port: 33139
targetPort: 33139
protocol: TCP
- name: block-manager-port
port: 45029
targetPort: 45029
protocol: TCP
selector:
app: ml-app
sessionAffinity: None
После применения манифеста автоматически поднимаются два Spark Executor в отдельных подах:

Cassandra
Cassandra — великолепный инструмент для хранения больших объемов данных. Это OLTP БД, те. рассчитанная на частые записи. Также особенностью этой БД является то, что модель данных нужно строить исходя из того, как будут запрашиваться данные: при не корректном задании ключей партиционирования и ключей кластеризации таблиц легко прийти к запросам с ALLOW FILTERING или организовать неравномерное заполнение узлов кластера Cassandra.
Для частных запросов на чтение больше подходят аналитические (OLAP) БД. Если посмотреть в сторону wide‑column DB, то аналогом Cassandra может быть Clickhouse. Однако, бывают различные случаи принципиального выбора Cassandra как источника аналитических данных и невозможности использования Clickhouse: недостаток вычислительных ресурсов, компетенций команд разработки и администрирования, и прочие ограничения.
Результатом такого решения может быть сложность выборки необходимых данных, так как, в отличие от реляционных БД, в Cassandra нет механизма отношений и поддержки join‑операций. В таком случае можно использовать Apache Spark, который позволяет выполнять запросы к Cassandra как к реляционной базе данных. Если имеется несколько Cassandra датацентров, один из них можно настроить для аналитических операций, разгрузив при этом датацентр (ы) для транзакций записи.
Связкой Spark‑Cassandra можно реализовать ETL‑процессы, как между таблицами Cassandra, так и в другие БД, например, в тот же Clickhouse, используя различные коннекторы Spark.
Сущности Big Data системы
Случайно или нет, статья публикуется во время сезона Big Data на Habr. Поскольку статья является руководством и ориентирована в том числе для новичков в этой области, кратко рассмотрим некоторые ключевые понятия: что такое ETL, Data Lake, DWH и Data Mart.
Data Lake — это централизованное хранилище данных, которое позволяет хранить данные в исходном формате без предварительной структуризации или преобразования. Data Lake предоставляет возможность хранить большие объемы разнородных данных, включая структурированные, полуструктурированные и неструктурированные данные. Это позволяет проводить различные виды анализа, исследований и обработки данных в будущем, когда появится необходимость.
DWH — это хранилище данных, и это специально организованная структура, предназначенная для хранения и управления данными. DWH интегрирует данные из разных источников, таких как транзакционные базы данных, файлы, веб‑сервисы и другие источники данных. Он предоставляет единое и консолидированное представление данных, которое удобно для анализа и отчетности.
Data Mart (Витрина данных) представляет собой сегментированное подмножество данных из хранилища данных (т. е. является подмножеством DWH), ориентированное на конкретные потребности бизнеса или отделов компании. Data Mart содержит данные, специально организованные и структурированные для поддержки аналитических запросов и принятия решений в конкретной области или функциональном подразделении компании.
ETL (Извлечение, Трансформация и Загрузка) — это процесс, который обеспечивает передачу данных из исходных источников в целевые системы хранения данных. В процессе ETL данные извлекаются из различных источников, затем подвергаются трансформации, включающей очистку, фильтрацию, преобразование и объединение данных, и, наконец, загружаются в целевую систему хранения данных, такую как DWH или Data Mart. Процесс ETL играет важную роль в обеспечении актуальности, целостности и качества данных в аналитической системе.
Пример процесса работы с данными в рассматриваемой системе
Рассмотрим, как можно использовать получившуюся систему на конкретном примере. Предметная область — аналитика цен финансовых инструментов, торгующихся на фондовых рынках. Так система строится на основе вычислений на GPU, попробуем построить модель машинного обучения, которая предсказывает цену курса акций NVidia (тикер NVDA) на несколько периодов вперед. Анализ проводился на данных дневного таймфрейма (1 day) с предсказанием на 2 периода (2 дня) вперед.
Схематично, система выглядит следующим образом:
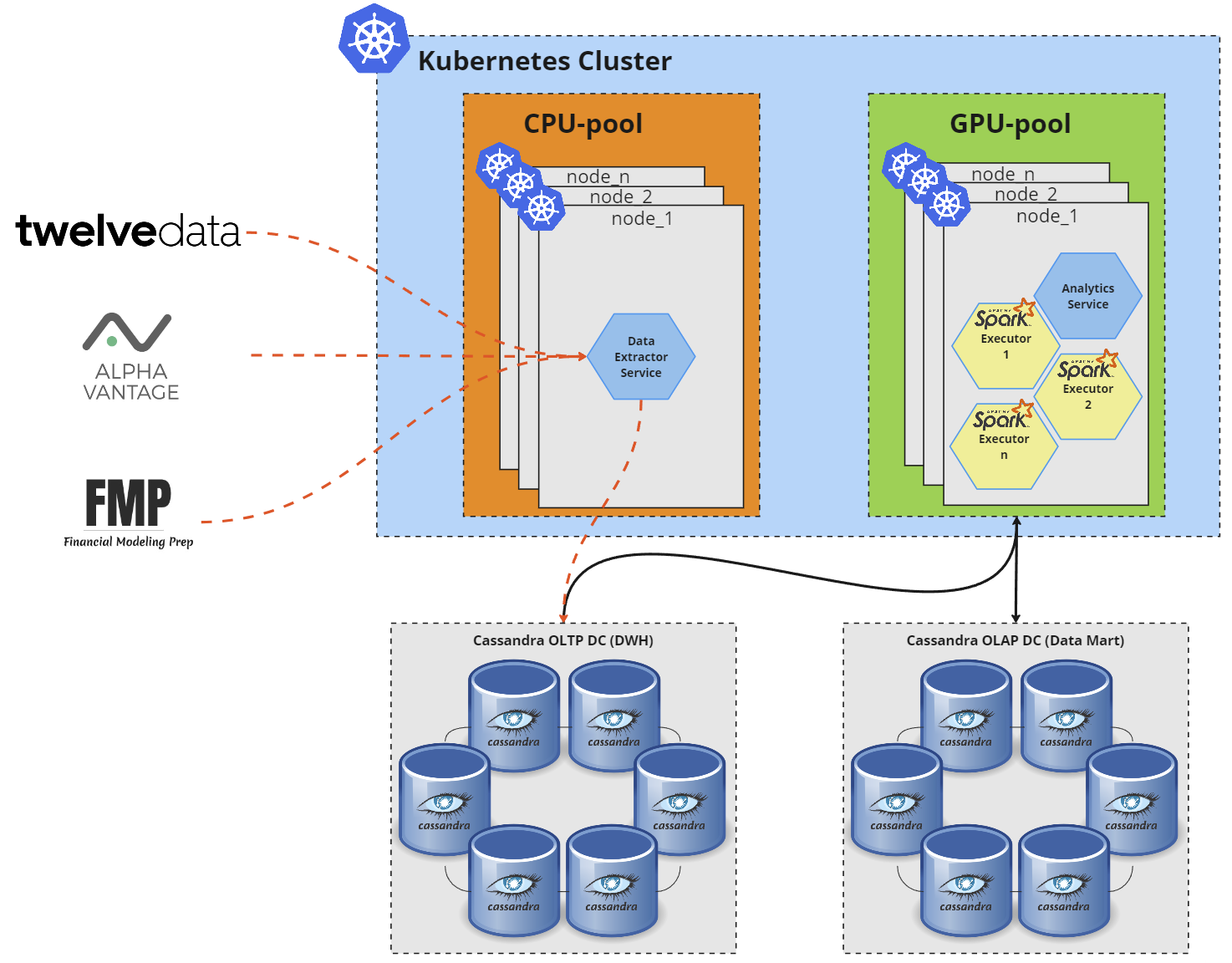
Красной пунктирной линией показаны ETL процессы из источников данных, которые в рассматриваемой системе можно принять за Data Lakes. Данные из них забираются сервисом Data Extractor, который развернут на k8s node pool только с CPU, и записываются в OLTP DWH кластер Cassandra.
По необходимости/расписанию/событию Analytics Service, который развернут на k8s node pool с GPU, забирает данные из нескольких таблиц DWH кластера, трансформирует их в единую структуру и записывает в Data Mart кластер Cassandra, который может быть настроен для OLAP операций. Это тоже ETL процесс, он обозначен черными сплошными линиями, выполняется посредством Spark Executors, которые назначены Analytics Service — в терминологии Spark это driver.
Говоря об инфраструктуре решения, не будет лишним упомянуть еще пару инструментов для работы в с Big Data системой:
Apache Zeppelin — мощный инструмент визуализации и анализа данных. Он предоставляет интерактивную среду для разработки, выполнения и представления результатов вычислений на основе больших объемов данных. С помощью Apache Zeppelin можно создавать и запускать ноутбуки, которые содержат код на различных языках программирования, включая Java, Scala, Kotlin и многие другие. Zeppelin обладает широким набором интегрированных визуализаций и возможностей интерактивного анализа данных, что делает его полезным инструментом для работы с результатами аналитики и машинного обучения. Zeppelin имеет возможность работы с интерпретатором Spark.
Spring Cloud Data Flow (SCDF) — это распределенная система управления потоками данных (Data Flow) в облачной среде. Она предоставляет инфраструктуру и инструменты для развертывания, управления и мониторинга сложных потоков данных между различными источниками и приемниками данных. SCDF позволяет создавать и конфигурировать потоки данных в виде графа, состоящего из различных компонентов обработки, таких как источники, преобразования, фильтры и назначения. С помощью SCDF можно управлять и масштабировать потоки данных в распределенной среде.
Оба эти инструмента, Apache Zeppelin и Spring Cloud Data Flow, могут быть полезными в контексте рассматриваемой системы для аналитики цен финансовых инструментов. Apache Zeppelin предоставит удобную среду для визуализации и анализа данных, а Spring Cloud Data Flow поможет в управлении потоками данных и обработке информации между различными компонентами системы.
Конфигурация приложения
Стоит подробнее рассмотреть конфигурацию приложения для работы со Spark.
public static JavaSparkContext sparkContext(SparkSettings sparkSettings) {
String host = sparkSettings.getHost();
SparkConf sparkConf = new SparkConf(true)
.setAppName(sparkSettings.getAppName())
.setMaster(sparkSettings.getMasterHost())
.setJars(sparkSettings.getJars())
...
.set("spark.driver.resource.gpu.amount", "0") // (1)
...
// Cassandra // (2)
.set("spark.jars.packages", "datastax:spark-cassandra-connector:3.3.0-s_2.12")
.set("spark.sql.extensions", "com.datastax.spark.connector.CassandraSparkExtensions")
.set("spark.cassandra.auth.username", sparkSettings.getCassandraUser())
.set("spark.cassandra.auth.password", sparkSettings.getCassandraPass())
.set("spark.cassandra.connection.host", sparkSettings.getCassandraHosts());
if (sparkSettings.isKubernetesEnabled()) { // (3)
sparkConf.set("spark.kubernetes.container.image", sparkSettings.getExecutorImage());
if (sparkSettings.getDeployMode().equals("client")) {
sparkConf
.set("spark.kubernetes.driver.pod.name", sparkSettings.getHostName())
.set("spark.kubernetes.namespace", sparkSettings.getNamespace())
.set("spark.kubernetes.authenticate.driver.serviceAccountName", sparkSettings.getDriverSa());
}
}
return new JavaSparkContext(sparkConf);
}(1) — если приложение (spark driver) не использует ресурсы GPU напрямую, следует указать в данной настройке »0», чтобы под него не резервировался необходимый Spark Executor’ам ресурс.
(2) — настройки cassandra spark connector. Для подключения экзекуторов к кластеру Cassandra следует указать данные настройки. Коннектор cassandra имеет большое число настроек, все можно найти здесь;
(3) — так как приложение может работать не только в k8s, настройки, которые предназначены только для него, не стоит указывать. Здесь должен быть указан, как минимум, необходимый для работы приложения образ spark executor, имя driver k8s Pod (можно получить с помощью InetAddress.getLocalHost().getHostName();), namespace, в котором будут создаваться executor Pods, и Service Account. Все это было создано ранее.
JavaSparkContext может быть передан в объект SparkSession, который далее будет использоваться для работы с executor’ами.
Работа с Cassandra в Spark
Получение данных
В сервисе будем использовать Dataset как объект с данными. Существуют так же RDD и Dataframe, и, почему в Java/Kotlin стоит использовать Dataset, можно почитать здесь и здесь.
Базовый метод получения данных из кассандра:
AbstractCassandraRepository
abstract class AbstractCassandraRepository constructor(
private val sparkSession: SparkSession
) {
companion object {
internal const val keyspace: String = "instrument_data"
}
fun cassandraDataset(keyspace: String, table: String): Dataset {
val cassandraDataset: Dataset = sparkSession.read()
.format("org.apache.spark.sql.cassandra")
.option("keyspace", keyspace)
.option("table", table)
.load()
cassandraDataset.createOrReplaceTempView(table)
return cassandraDataset
}
}
Здесь мы работаем со спарковой сессией: указываем ей, что Dataset
Естественно, никого не интересует получать все данные и делать full scan таблицы — у каждой есть Partition Key, по которому нужно искать необходимые данные.
Рассмотрим пример получения данных из таблицы instrument_data.time_series_history:
instrument_data.time_series_history
create table instrument_data.time_series_history
(
ticker text,
task_number uuid,
datetime timestamp,
timeframe text,
close decimal,
high decimal,
low decimal,
open decimal,
volume bigint,
primary key (ticker, task_number, datetime, timeframe)
)
with compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'};
create index time_series_history_datetime_index
on instrument_data.time_series_history (datetime);
create index time_series_history_task_number_index
on instrument_data.time_series_history (task_number);
create index time_series_history_timeframe_index
on instrument_data.time_series_history (timeframe);У нее имеется Partition Key ticker и три Clustering Column:
task_number — номер задания на получение и анализ данных в смежной системе;
datetime — дата и время записи;
timeframe — таймфрейм временного ряда (1day в рассматриваемом случае).
Задача — доставать данные по ticker, task_number и datetime between (dateStart, dateEnd) из всех таблиц.
AbstractIndicatorRepository
abstract class AbstractIndicatorRepository constructor(
sparkSession: SparkSession,
private val table : String
) : AbstractCassandraRepository(sparkSession) {
fun getBaseDataSet(
ticker: String,
taskNumber : UUID,
dateStart : LocalDate,
dateEnd : LocalDate
): Dataset {
return cassandraDataset(table)
.filter(
functions.col("ticker").equalTo(ticker)
.and(functions.col("task_number").equalTo(taskNumber.toString()))
.and(functions.col("datetime").between(dateStart, dateEnd)))
}
}
Таким образом, можно обратиться к предыдущему методу и отфильтровать значения. Функционал данного метода будет аналогичен запросу данных из таблицы с указанными полями. При этом Spark не будет доставать весь датасет, затем его фильтровать — в экзекуторы попадут уже отфильтрованные данные.
Данный метод аналогичен запросу:
select *
from instrument_data.time_series_history
where ticker = ?1
AND task_number = ?2
AND datetime > ?3 and datetime < ?4;Если не передавать partition key, увеличение времени запроса можно отследить на DAG запроса в Spark UI. Это лежит на поверхности, можно очень быстро разобраться, на получении каких данных запрос тормозит работу.
Чтобы выполнить select по определенным столбцам, уже следует создать репозиторий для отдельной таблицы и выполнить запрос следующим образом:
TimeSeriesRepository
@Component
class TimeSeriesRepository(
sparkSession: SparkSession
) : AbstractIndicatorRepository(sparkSession, "time_series_history") {
fun getDataset(
ticker: String,
taskNumber : UUID,
dateStart : LocalDate,
dateEnd : LocalDate
) : Dataset {
val dataset = getBaseDataSet(ticker, taskNumber, dateStart, dateEnd)
.selectExpr(
"to_date(datetime) as dateTime",
"CAST(close AS Double) as close"
)
dataset.createOrReplaceTempView("ts")
return dataset
}
}
Тогда конечный датасет вернет таблицу из двух столбцов с датой и временем и ценой закрытия, преобразованной в Double. Double необходим при передаче данных на вычисление в GPU.
Получаем все необходимые данные:
getMainDataset
private fun getMainDataset(
ticker : String,
taskNumber : UUID,
dateStart : LocalDate,
dateEnd : LocalDate,
currentOffset : Int,
batchSize : Int
) : Dataset {
val timeSeries = timeSeriesRepository
.getDataset(ticker, taskNumber, dateStart, dateEnd, currentOffset, batchSize)
.`as`("ts")
val emaDataSet = emaRepository
.getEmaDataSet(ticker, dateStart, dateEnd, currentOffset, batchSize)
.`as`("ema")
val stochasticDataset = stochasticRepository
.getStochasticDataSet(ticker, dateStart, dateEnd, currentOffset, batchSize)
.`as`("stoch")
val bBandsDataset = bBandIndicatorRepository
.getBBandsDataSet(ticker, dateStart, dateEnd, currentOffset, batchSize)
.`as`("bb")
val macdDataset = macdRepository
.getMacdDataSet(ticker, dateStart, dateEnd, currentOffset, batchSize)
.`as`("macd")
val rsiDataset = rsiRepository
.getRsiDataSet(ticker, dateStart, dateEnd, currentOffset, batchSize)
.`as`("rsi")
val smaDataset = smaRepository
.getSmaDataSet(ticker, dateStart, dateEnd, currentOffset, batchSize)
.`as`("sma")
val willrDataset = willrRepository
.getWillrDataSet(ticker, dateStart, dateEnd, currentOffset, batchSize)
.`as`("willr")
return combineDatasets(
timeSeries, emaDataSet, stochasticDataset, bBandsDataset, macdDataset, rsiDataset, smaDataset, willrDataset
)
}
Здесь у Java/Kotlin разработчика может возникнуть желание сделать запрос данных через CompletableFuture и выполнить их все в одном тредпуле. Однако, не стоит этого делать. Спарк сам распараллеливает работу и создает FutureTask’s, программисту не стоит распараллеливать код на разные потоки.
и комбинируем:
combineDatasets
private fun combineDatasets(
timeSeries : Dataset,
emaDataSet : Dataset,
stochasticDataset : Dataset,
bBandsDataset : Dataset,
macdDataset : Dataset,
rsiDataset : Dataset,
smaDataset : Dataset,
willrDataset : Dataset
): Dataset {
val result = timeSeries
.join(emaDataSet, timeSeries.col("datetime")
.equalTo(emaDataSet.col("datetime")), "leftouter")
.join(stochasticDataset, timeSeries.col("datetime")
.equalTo(stochasticDataset.col("datetime")), "leftouter")
.join(bBandsDataset, timeSeries.col("datetime")
.equalTo(bBandsDataset.col("datetime")), "leftouter")
.join(macdDataset, timeSeries.col("datetime")
.equalTo(macdDataset.col("datetime")), "leftouter")
.join(rsiDataset, timeSeries.col("datetime")
.equalTo(rsiDataset.col("datetime")), "leftouter")
.join(smaDataset, timeSeries.col("datetime")
.equalTo(smaDataset.col("datetime")), "leftouter")
.join(willrDataset, timeSeries.col("datetime")
.equalTo(willrDataset.col("datetime")), "leftouter")
.selectExpr(
"ts.dateTime as dateTime",
"ema.emaTimePeriod as emaTimePeriod",
"ema.ema as ema",
"stoch.fastKPeriod as fastKPeriod",
"stoch.slowKPeriod as slowKPeriod",
"stoch.slowDPeriod as slowDPeriod",
"stoch.slowD as slowD",
"stoch.slowK as slowK",
"bb.timePeriod as bbTimePeriod",
"bb.sd as bbSd",
"bb.lowerBand as lowerBand",
"bb.middleBand as middleBand",
"bb.upperBand as upperBand",
"macd.signalPeriod as signalPeriod",
"macd.fastPeriod as fastPeriod",
"macd.slowPeriod as slowPeriod",
"macd.macd as macd",
"macd.macdHist as macdHist",
"macd.macdSignal as macdSignal",
"rsi.timePeriod as rsiTimePeriod",
"rsi.rsi as rsi",
"sma.timePeriod as smaTimePeriod",
"sma.sma as sma",
"willr.timePeriod as willrTimePeriod",
"willr.willr as willr",
"ts.close as close"
)
val windowSpec = Window.orderBy(functions.asc("dateTime"))
return result
.withColumn("id", functions.row_number().over(windowSpec))
.filter(functions.col("dateTime").isNotNull)
}
В методе combineDatasets происходит объединение таблиц, которое Cassandra не поддерживает, а Spark предоставляет такую возможность.
В результирующий датасет добавляется колонка id, которая содержит номер строки. Здесь же предварительно сортируются данные по колонке dateTime и отфильтровываются строки с пустыми ячейками.
Стоит отметить, что есть иной способ работы с Dataset — можно обратиться к объекту sparkSession, вызвать метод sql () и передать в него обычный SQL запрос на объединение данных, и он будет работать.
Если все‑таки предпочтительно использовать SQL запросы, можно это делать, различий в скорости работы в моих без учета предварительных фильтров для датасетов не было замечено. Spark поддерживает все основные функции, с единственной оговоркой — не стоит писать свои собственные функции (UDF) и стараться выполнить запрос, это плохо влияет на производительность. За помощью в этом вопросе следует обратиться к оф. документации. Spark понимает ANSI формат. Если нужно перевести запрос, написанный на другом диалекте, можно воспользоваться инструментом.
В абзаце выше не просто так выделено полужирным с подчеркиванием одно важное условие. Допустим, мы получили датасет timeSeries, и сразу же хотим через sparkSession.sql () нативным запр
