MASK-RCNN для поиска крыш по снимкам с беспилотников

В белом-белом городе на белой-белой улице стояли белые-белые дома… А как быстро вы можете найти все крыши домов на этой фотографии?
Все чаще можно слышать про планы правительства провести полную инвентаризацию объектов недвижимости с целью уточнения кадастровых данных. Для первичного решения этой задачи можно применить простой способ, основанный на расчете площади крыш капитальных строений по аэрофотоснимкам и дальнейшее сопоставление с кадастровыми данными. К сожалению, ручной поиск и расчет занимает много времени, а поскольку новые дома сносятся и строятся непрерывно, то расчет требуется повторять снова и снова. Сразу возникает гипотеза, что этот процесс можно автоматизировать с помощью алгоритмов машинного обучения, в частности, Computer Vision. В этой статье я расскажу о том, как мы в «НОРБИТ» решали эту задачу и с какими сложностями столкнулись.
Спойлер — у нас получилось. В основе разработанного ML сервиса находится модель глубокого машинного обучения, основанная на свёрточных (convolution) нейронных сетях. Сервис принимает на вход снимки с беспилотных летательных аппаратов, на выходе генерирует GeoJSON файл с разметкой найденных объектов капитального строительства с привязкой к географическим координатам.
В результате это выглядит так:

Проблемы
Начнем с технических проблем, с которыми мы столкнулись:
- есть существенное отличие между зимними и летними аэрофотоснимками (модель, обученная только на летних фотографиях совершенно не способна находить крыши зимой);
- для решения задачи определения площади капитального строения очень важно точное определение границ крыш, а не просто их обнаружение и локализация;
- часто возникала ситуация, когда несколько частей одной крыши оказывались на соседних тайлах (квадратных кропах облета), а поскольку процесс инференса (запуск обученной модели для новых изображений) выполняется для каждого тайла в отдельности, то на выходе вместо цельной крыши мы получали несколько ее кусков;
- модель демонстрирует хорошие результаты, начиная с определенного разрешения снимков, когда нейронная сеть может четко выделять контуры объектов (это важно учитывать при планировании аэрофотосъемки). Для инференса космоснимков нужно немного иначе обучать модель;
- некоторые объекты (например, бассейны и грузовики) модель иногда ошибочно считала крышами.
А еще беспилотники иногда приносят вот такие фотографии:

Также хотелось бы отметить и проблемы, которые могли бы быть, но нас не коснулись:
- у нас не было задачи выполнять инференс в ограниченное время (например, непосредственно в момент полета), что сразу решило все возможные проблемы с производительностью;
- на входе для обработки мы сразу получали качественные изображения в высоком разрешении (используются объективы с фокусным расстоянием 21 мм на высоте 250 м, что составляет 5 см/px) от нашего заказчика, компании «Шахты», могли использовать их экспертизу в геопозиционировании объектов на картах, а также имели возможность устанавливать определенный набор требований к будущим полетам беспилотников, что в итоге сильно снизило вероятность появления совсем уж уникальных тайлов, которых не было в обучающей выборке;
Первый вариант решения задачи, обводка с помощью Boundary box
Несколько слов о том, какие инструменты были использованы нами для создания решения.
- Anaconda — удобная система управления пакетами для языков Python и R.
- Tensorflow — открытая программная библиотека для машинного обучения, разработанная компанией Google.
- Keras — надстройка над фреймворками Deeplearning4j, TensorFlow и Theano.
- OpenCV — библиотека алгоритмов компьютерного зрения, обработки изображений и численных алгоритмов общего назначения с открытым кодом.
- Flask — фреймворк для создания веб-приложений на языке программирования Python.
В качестве ОС использовали Ubuntu 18.04. С драйверами на GPU (NVIDIA) в Ubuntu все в порядке, поэтому задача обычно решается одной командой:
> sudo apt install nvidia-cuda-toolkit
Подготовка тайлов
Первой задачей, с которой мы столкнулись, было разбиение изображений облета на тайлы (2048×2048 px). Можно было бы написать свой скрипт, но тогда бы пришлось думать о сохранении географической привязки каждого тайла. Проще было использовать готовое решение, например, GeoServer — это ПО с открытым исходным кодом, позволяющее публиковать на сервере геоданные. Помимо этого GeoServer решил для нас еще одну задачу — удобное отображение результата автоматической разметки на карте. Это можно сделать локально, например, и в qGIS, но для распределенной команды и демонстрации удобнее web-ресурс.
Для выполнения разбиения на тайлы нужно в настройках указать требуемый масштаб и размер.
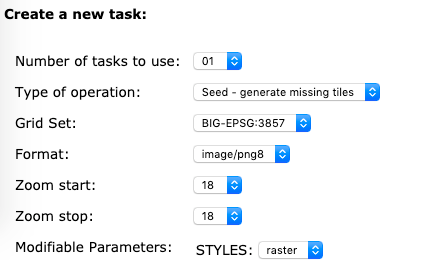
Для переводов между системами координат мы использовали библиотеку pyproj:
from pyproj import Proj, transform
class Converter:
P3857 = Proj(init='epsg:3857')
P4326 = Proj(init='epsg:4326')
...
def from_3857_to_GPS(self, point):
x, y = point
return transform(self.P3857, self.P4326, x, y)
def from_GPS_to_3857(self, point):
x, y = point
return transform(self.P4326, self.P3857, x, y)
...
В результате удалось легко сформировать из всех полигонов один большой слой и наложить его сверху на подложку.

- Установить Java версии 8.
- Скачать GeoServer. Последнюю версию ПО можно скачать на официальном сайте
- Распаковать в выбранную директорию на сервере, например,
/usr/share/geoserver - Добавить в переменную окружения путь к директории
echo «export GEOSERVER_HOME=/usr/share/geoserver» >> ~/.profile - Создать группу пользователей геосервера:
sudo groupadd geoserver - Добавить пользователя, который будет работать с моделью, в группу геосервера:
sudo usermod -a -G geoserver - Установить группу-владельца директории геосервера:
sudo chown -R :geoserver /usr/share/geoserver/ - Добавить права доступа для группы:
sudo chmod -R g+rwx /usr/share/geoserver/ - Запустить GeoServer
cd geoserver/bin && sh startup.sh
GeoServer — не единственное приложение, позволяющее решить нашу задачу. В качестве альтернативы, например, можно рассмотреть ArcGIS for Server, однако этот продукт является проприетарным, потому использовать его мы не стали.
Далее предстояло на каждом тайле находить все видимые крыши. Первым подходом к решению задачи было использование object_detection из набора models/research Tensorflow. Этим способом можно находить и локализовывать прямоугольным выделением (boundary box) классы на изображениях.
Разметка обучающих данных
Очевидно, для обучения модели нужен размеченный датасет. По счастливой случайности, помимо облетов, в наших закромах сохранился датасет на 50 тыс. крыш со старых добрых времен, когда все датасеты для обучения еще повсеместно лежали в открытом доступе.
Точный размер обучающей выборки, требующийся для получения приемлемой точности модели, заранее предсказать довольно сложно. Он может варьироваться в зависимости от качества изображений, степени их непохожести друг на друга и условий, в которых модель будет эксплуатироваться в production. У нас были кейсы, когда хватало 200 шт., а иногда не хватало и 50 тыс. размеченных образцов. В случае дефицита размеченных изображений мы обычно добавляем методы аугментации: повороты, зеркальные отражения, цветокоррекции и др.
Сейчас доступно множество сервисов, позволяющих произвести разметку изображений — как с открытым исходным кодом для установки на свой компьютер/сервер, так и корпоративные решения, включающие работу внешних асессоров, например Яндекс.Толока. В этом проекте мы использовали самый простой VGG Image Annotator. В качестве альтернативы ему можно попробовать coco-annotator или label-studio. Последний мы обычно используем для разметки текста и аудиофайлов.

Для обучения на разметке различных аннотаторов обычно нужно выполнить небольшое перекладывание полей, пример для VGG.
Чтобы правильно вычислить площадь крыши, которая попала в область прямоугольного выделения, необходимо, соблюдения нескольких условий:
- все границы крыш должны быть параллельны/перпендикулярны на каждом тайле границам обводки. В противном случае будет проблема с превышением величины вычисленной площади:

- важно, чтобы крыша была прямоугольная, иначе величина площади также получится завышенной:

Для решения второй проблемы можно попробовать обучить отдельную модель, которая бы определяла правильный угол поворота тайла для разметки, но все получилось немного проще. Люди сами стремятся к уменьшению энтропии, поэтому выравнивают все рукотворные сооружения по отношению друг к другу, особенно при плотной застройке. Если посмотреть сверху, то на локализованном участке заборы, дорожки, посадки, теплицы, беседки будут параллельны или перпендикулярны границам крыш. Остается только найти все четкие линии и вычислить самый часто встречающийся угол наклона к вертикали. Для этого в OpenCV есть замечательный инструмент HoughLinesP.
...
lines = cv2.HoughLinesP(edges, 1, np.pi/180, 50, minLineLength=minLineLength, maxLineGap=5)
if lines is not None:
length = image.shape[0]
angles = []
for x1, y1, x2, y2 in lines[0]:
angle = math.degrees(math.atan2(y2 — y1, x2 - x1))
angles.append(angle)
parts_angles.append(angles)
median_angle = np.median(angles)
...
# разбиение тайла на кропы
for x in range(0, image.shape[0]-1, image.shape[0] // count_crops):
for y in range(0, image.shape[1]-1, image.shape[1] // count_crops):
get_line(image[x:x+image.shape[0]//count_crops, y:y+image.shape[1]//count_crops, :])
...
# вычисление медианы угла на всех кропах
np.median([a if a>0 else 90+a for a in np.array(parts_angles).flatten()])
После нахождения угла изображение поворачиваем с помощью аффинного преобразования:
h, w = image.shape[:2]
image_center = (w/2, h/2)
if size is None:
radians = math.radians(angle)
sin = math.sin(radians)
cos = math.cos(radians)
size = (int((h * abs(sin)) + (w * abs(cos))), int((h * abs(cos)) + (w * abs(sin))))
rotation_matrix = cv2.getRotationMatrix2D(image_center, angle, 1)
rotation_matrix[0, 2] += ((size[0] / 2) — image_center[0])
rotation_matrix[1, 2] += ((size[1] / 2) — image_center[1])
else:
rotation_matrix = cv2.getRotationMatrix2D(image_center, angle, 1)
cv2.warpAffine(image, rotation_matrix, size)
Полный код примера тут. Вот как это выглядит:

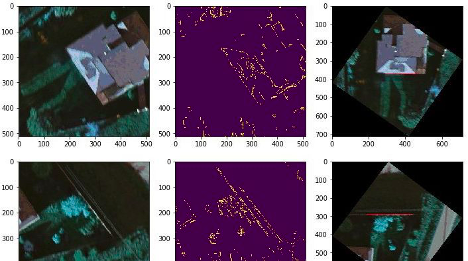
Метод поворота тайлов и разметка прямоугольниками работает быстрее, чем разметка масками, практически все крыши находятся, но в продакшене этот метод используется только как вспомогательный из-за нескольких недостатков:
- есть множество облетов, где встречается большое количество непрямоугольных крыш, из-за этого слишком много ручной работы по уточнению площадей,
- иногда встречаются дома с разной ориентацией на одном тайле,
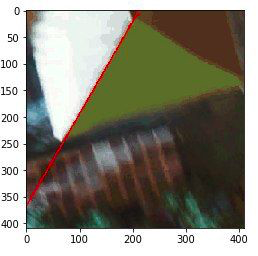
- иногда на тайлах встречается множество ложных линий, что в итоге приводит к неправильному повороту. Выглядит это так:

Итоговое решение на базе Mask-RCNN
Второй попыткой была реализация поиска и выделения крыш масками попиксельно, а затем автоматическая обводка контуров найденных масок и создание векторных полигонов.
Материалов о принципах работы, видах и задачах свёрточных нейронных сетей, в том числе и на русском языке, уже предостаточно, поэтому мы не станем углубляться в них в этой статье. Остановимся только на одной конкретной реализации, Mask-RCNN — архитектуры для локализации и выделения контуров объектов на изображениях. Есть и другие отличные решения со своими достоинствами и недостатками, например, UNet, но лучшего качества удалось добиться именно на Mask-RCNN.
В процессе своего развития она прошла несколько стадий. Первая версия R-CNN была разработана в 2014 году. Принцип ее работы заключается в выделении на изображении небольших областей, для каждой из которых производится оценка вероятности наличия в этой области целевого объекта. R-CNN отлично справлялась с поставленной задачей, однако скорость ее работы оставляла желать лучшего. Закономерным развитием стали сети Fast R-CNN и Faster R-CNN, получившие улучшения в алгоритме обхода изображений, что позволило значительно повысить быстродействие. На выходе в Faster R-CNN появляется разметка прямоугольным выделением, обозначающим границы объекта, что не всегда достаточно для решения задачи.
В Mask R-CNN добавляется еще и попиксельное наложение маски, позволяющее получить точное очертание объекта.
Наглядно boundary box и маски можно увидеть на результате работы модели (включен фильтр по минимальной площади здания):

Условно можно выделить 4 этапа в работе этой сети:
- стандартное для всех сверточных нейронных сетей выделение признаков на изображении, таких как линии, изгибы, контрастные границы и другие;
- Region Proposal Network (RPN) сканирует небольшие фрагменты изображения, именуемые anchors (якоря) и определяет, содержит ли этот якорь признаки, характерные для целевого класса (в нашем случае крыши);
- Region of Interest Classification and Bounding Box. На этом этапе сеть, основываясь на результатах предыдущего этапа пытается выделить на фотографии большие прямоугольные области, предположительно содержащие целевой объект;
- Segmentation Masks. На этом этапе из прямоугольной области, полученной при наложении boundary box, получается маска искомого объекта.
Помимо всего, сеть оказалась очень гибкой в конфигурировании, и нам удалось перестроить ее на обработку изображений с дополнительными информационными слоями.
Использование исключительно только RGB изображений не позволило добиться необходимой точности распознавания (модель пропускала целые здания, была средняя ошибка в 15% в вычислении площади крыш), поэтому мы подавали на вход модели дополнительные полезные данные, например карты высот, полученные методом фотограмметрии.

Метрики, применяемые для оценки качества модели
При определении качества моделей мы чаще всего пользовались метрикой Intersection over Union (IoU)
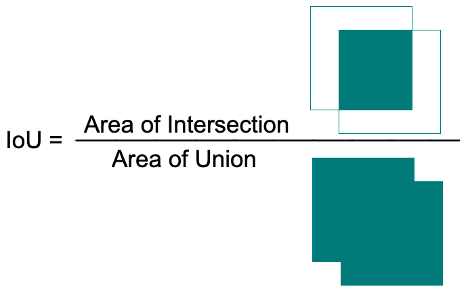
Пример кода для вычисления IoU с использованием библиотеки geometry.shapely:
from shapely.geometry import Polygon
true_polygon = Polygon([(2, 2), (2, 6), (5, 6), (5, 2)])
predicted_polygon = Polygon([(3, 3), (3, 7), (6, 7), (6, 3)])
print(true_polygon.intersection(predicted_polygon).area / true_polygon.union(predicted_polygon).area)
>>> 0.3333333333333333
Отслеживание процесса обучения моделей удобно контролировать с помощью Tensorboard — удобного инструмента для контроля метрик, позволяющего в режиме реального времени получать данные о качестве модели и сопоставлять их с другими моделями.
Tensorboard предоставляет данные по множеству различных метрик. Для нас наиболее интересными являются:
- val_mrcnn_bbox_loss — показывает, насколько хорошо модель локализует объекты (т. е. накладывает boundary box);
- val_mrcnn_mask_loss — показывает, насколько хорошо модель сегментирует объекты (т. е. накладывает маску).
Обучение модели и валидация
При обучении нами применялась стандартная практика случайного разделения датасета на 3 части — обучающей, валидационной и тестовой. В процессе обучения качество модели оценивается на валидационной выборке, а по завершении проходит финальное испытание на тестовых данных, которые были от нее закрыты в процессе обучения.
Наши первые запуски обучения мы делали на небольшом наборе летних снимков и, решив проверить, насколько хороша будет наша модель зимой, ожидаемо получили разочаровывающий результат. Вариант с использованием разных моделей для разных сезонов, безусловно, является отличным выходом из ситуации, однако он повлек бы за собой ряд неудобств, поэтому решили попытаться сделать модель универсальной. Поэкспериментировав с различными конфигурациями слоев, а также закрывая от изменений веса отдельных слоев, мы нашли оптимальную стратегию обучения модели, подавая на вход попеременно летние и зимние снимки.
Создание фонового сервиса для распознавания
Теперь, когда у нас есть функционирующая модель, можно сделать из скрипта распознавания фоновый API сервис, который принимает на вход изображение, а на выходе генерит json с найденными полигонами крыш. Это непосредственно не влияет на решение задачи, но может быть кому-то будет полезно.
Ubuntu использует systemd, и пример будет приведен именно для этой системы. Код самого сервиса можно посмотреть здесь. Пользовательские юниты находятся в директории /etc/systemd/system, там мы и создадим файл нашего сервиса.
cd /etc/systemd/system
sudo touch my_srv.service
Отредактируем файл:
sudo vim my_srv.service
Юнит systemd состоит из трех секций:
- [Unit] — описывает порядок и условие запуска (например, можно указать процессу дожидаться запуска определенной службы и только после этого стартовать самому);
- [Service] — описывает параметры запуска;
- [Install] — описывает поведение сервиса при добавлении его в автозагрузку.
В результате наш файл будет выглядеть таким образом:
[Unit]
Description=my_test_unit
[Service]
WorkingDirectory=/home/user/test_project
User=root
ExecStart=/home/user/test_project/venv/bin/python3 /home/user/test_project/script.py
[Install]
WantedBy=multi-user.target
Теперь перезагрузим конфигурацию systemd и запустим наш сервис:
sudo systemctl daemon-reload
sudo systemctl start my_srv.service
Это простой пример фонового процесса, systemd поддерживает множество различных параметров, позволяющих гибко конфигурировать поведение сервиса, но для нашей задачи ничего более сложного и не требуется.
Выводы
Главным результатом проекта стала возможность автоматически выявлять несоответствия фактической застройки и информации, содержащейся в кадастровых данных.
В результате оценки точности модели на тестовых данных получены следующие значения: количество найденных крыш — 91%, точность обводки крыш полигонами — 94%.
Удалось добиться приемлемого качества работы моделей на летних и зимних облётах, но качество распознавания может снижаться на снимках сразу после снегопада.
Теперь даже Сиднейский оперный театр не ускользнет от глаз нашей модели.

Мы планируем выложить этот сервис с обученной моделью на нашем демостенде. Если интересно попробовать работу сервиса на своих собственных фото, присылайте заявки на ai@norbit.ru.
