Машинное обучение на C#: введение в ML.NET

ML.NET претендует на звание самой мощной библиотеки для машинного обучения на платформе .NET. Так ли это на самом деле? На вопрос отвечает Джефф Просайз.
Джефф Просайз — один из создателей компании Wintellect, коллега по цеху знаменитого Джеффри Рихтера, автор более девяти книг и множества статей по разработке приложений, сейчас работает с Azure и разрабатывает различные AI-решения.
Под катом перевод и видео доклада Джеффа с конференции DotNext 2019 Moscow в оригинале.
Далее — повествование от лица спикера.
Я считаю, что в истории нашей отрасли каждые 10 лет происходит смена парадигмы. В 1980-е годы произошла революция персональных компьютеров, я тогда как раз закончил ВУЗ и начал работать. Эта революция изменила не только нашу отрасль, но и повседневную жизнь людей. В 1990-е годы аналогичный переворот произвел интернет. В 2000-е годы настолько же масштабные изменения были вызваны появлением смартфонов. Сейчас в ресторанах, в метро, на улице люди постоянно смотрят в экраны смартфонов. 20 лет назад было бы трудно представить, к каким переменам приведет появление этой технологии. Я считаю, что сейчас мы на пороге настолько же фундаментальной революции, на этот раз связанной с машинным обучением и искусственным интеллектом.
В Microsoft Research, Google, Facebook и много где ещё работает множество очень одаренных людей, защитивших диссертации в этой области. Они получают очень большие зарплаты и проектируют сложные нейронные сети. До того, как я стал программистом, я был инженером ракетостроения. Инженеры не занимаются высокими материями, для этого существуют физики. Физики формулируют законы и пишут уравнения, инженеры же используют эти законы и уравнения для решения проблем из реальной жизни. Точно такая же роль у программистов в мире машинного обучения и ИИ: они не создают архитектуру новых сетей, им нужно уметь пользоваться уже существующими, знать соответствующие инструменты и технологии. Именно поэтому, с моей точки зрения, так важен ML.NET.
Ещё несколько лет тому назад всем, кто работал в области машинного обучения, приходилось учить Python. Python — один из наиболее популярных языков в области ИИ, и одна из причин этого заключается в том, что люди, разрабатывающие модели ИИ в университетах и крупнейших компаниях, в свое время учились программировать на Python. Кроме того, значительная часть передовых библиотек для ИИ созданы именно для Python. Это Scikit, Keras, PyTorch и другие. Я начал активно заниматься машинным обучением где-то пять лет тому назад, и за всю свою предшествующую жизнь я написал не больше десяти строк кода на Python. Мне пришлось выучить этот язык, но при этом я постоянно испытывал дискомфорт, потому что привык к .NET. До недавнего времени на C# не было альтернатив тем библиотекам, которые есть на Python, а теперь такая альтернатива появилась. Это ML.NET, опенсорсная библиотека от Microsoft для работы с ИИ. Сегодня мы с вами рассмотрим множество примеров кода с этой библиотекой, и я дам ссылку на репозиторий GitHub c этими примерами.
Тот факт, что у нас появилась библиотека для ИИ под C#, важен по многим причинам. Теперь для работы с ИИ не нужно знать Python. На C# сложно работать с моделями, созданными с помощью библиотеки на Python вроде Scikit или Keras. Для этого есть много различных способов, один из самых распространенных — помещение модели на Python в контейнер вместе с веб-сервером Flask. Но такой подход крайне неэффективен. Для разработчиков, пишущих приложения на C#, необходима возможность использовать модели на этом языке, и такую возможность предоставляет ML.NET.
Интересно, что ML.NET не такая уж и новая библиотека. Она вышла в свет совсем недавно, но внутри Microsoft она используется уже около 10 лет. Она возникла не внезапно, а развивалась постепенно в течение многих лет. Значительная часть кода была написана в Microsoft Research. Это был довольно сырой код, и пользоваться им было трудно даже тем, кто работал в Microsoft и имел доступ к этим библиотекам — не было общей архитектуры, приходилось пользоваться различными оболочками и прочим. Три года назад небольшая группа людей из Microsoft решила сделать эту библиотеку готовой к внешнему использованию и опенсорсной. На то, чтобы уговорить менеджмент в Microsoft согласиться на этот проект, ушел почти год. Он вышел под названием ML.NET. В основе ML.NET лежат те же алгоритмы, которые используются во множестве других продуктов Microsoft. Их почистили, сделали для них документацию и создали общий API.
DataView
Перейдем непосредственно к тому, как работает эта библиотека, как она устроена и как её использовать в ваших проектах. Откроем Visual Studio. Нужно будет познакомиться с тем, что такое DataView. Те, кто занимался машинным обучением на Python, наверняка пользовались библиотекой pandas. У неё есть очень полезная структура данных, которая называется DataFrame. Типичная работа приложения выглядит так: мы читаем данные из некоторого источника, загружаем их в DataFrame, совершаем нужные преобразования, а затем используем их для обучения модели. Одна из основных структур в ML.NET называется DataView, это объект, который реализует интерфейс IDataView. Эта структура — аналог DataFrame, но более гибкая и универсальная. Команда ML.NET хотела создать библиотеку, которая, обучала бы модели значительно быстрее, чем обычные библиотеки вроде Scikit, и могла бы масштабировать работу, то есть чтобы при увеличении мощностей (например, на компьютере с несколькими ядрами или на кластере HTC с несколькими многоядерными процессорами) время обучения модели изменялось бы почти линейно.
Разработчики ML.NET хотели предоставить возможность работать с наборами данных такого размера, с которыми Python попросту не может справиться. Для этого и был создан DataView. На первых порах для этих целей использовался интерфейс IEnumerable, но у него довольно быстро обнаружился ряд ограничений. В частности, содержание IEnumerable должно помещаться в памяти, в то время как в data science часто приходится иметь дело с наборами данных, которые слишком велики для памяти. Выяснилось, что система типов .NET не могла позволить выполнять некоторые действия, которые разработчики хотели выполнять внутри этих структур данных.
Предположим, нам необходимо указать не только, что столбец содержит ряд целочисленных значений, но и что диапазон каждого из них ограничен (например, от 0 до 10). Для преодоления этих ограничений, команда ML.NET создала DataView. Идея этой структуры данных была взята у баз данных SQL. У такой DataView в сущности нет ограничения на размер содержащихся в ней данных, поскольку в память загружается ровно столько, сколько необходимо в данный момент. Кроме того, в DataView используется отложенное вычисление (lazy evaluation) — она не выполняет никаких действий до тех пор, пока не начинается обучение модели. Это создает некоторые сложности при отладке.
Предположим, вы загрузили данные в DataView и выполнили некоторые преобразования — если затем выполнить код по шагам в отладчике, из-за отложенного вычисления там не будет данных. Поэтому при работе с DataView один из самых важных методов — это preview. Поскольку он снижает производительность, есть смысл использовать его только при отладке. Если вызов preview с определенным DataView вставить в код, поставить на этот вызов точку останова, то в этой точке при отладке будет загружено содержимое DataView.
Одно из предназначений DataView — загрузка в него данных. При работе с машинным обучением данные очень часто хранятся в файлах с расширением .csv и .tsv.
// Load data from a CSV file that contains a header row
var data = context.Data.LoadFromTextFile<Input>("PATH_TO_DATA_FILE", hasHeader: true,
separatorChar: ',');
// Load data from a TSV file without a header row. Allow quotes and trim whitespace.
var data = context.Data.LoadFromTextFile<Input>("PATH_TO_DATA_FILE", allowQuoting: true,
trimWhitespace: true);
// Load data from multiple CSV files (all files must have the same schema)
var loader = context.Data.CreateTextLoader<Input>(hasHeader: true, separatorChar: ',');
var data = loader.Load("PATH1", "PATH2", "PATH3");
Для загрузки данных из этих файлов разработчики DataView сделали несколько методов, которые вы сейчас видите выше. У этих методов есть параметры, которые позволяют игнорировать кавычки и тому подобное. Загружать данные для DataView можно не только из файлов CSV и TSV. Очень часто для хранения данных используются базы данных, например, Asure SQL или MySQL.
// TODO: Load data into an array or other IEnumerable from an external data source. // The following example simply creates an array in memory.
var input = new[]
{
new Input { Age = 30, YearsExperience = 10, ... },
new Input { Age = 40, YearsExperience = 20, ... },
new Input { Age = 50, YearsExperience = 30, ... }
};
var data = context.Data.LoadFromEnumerable<Input>(input);
Во всех случаях, когда данные загружаются не из файлов CSV или TSV, мы используем метод LoadFromEnumerable, который сейчас показан выше. В этот метод передается объект IEnumerable. Он может быть как совсем простым, созданным в памяти, так и огромным, содержать миллион строк, загруженных запросом к базе данных. В примерах, которые мы будем с вами рассматривать, я чаще всего буду загружать данные из файлов TSV или CSV, но важно понимать, что данные можно загружать откуда угодно.
Помимо методов для загрузки данных в DataView, ML.NET также предоставляет методы, при помощи которых можно подготовить к работе данные, уже загруженные в DataView. Если вы занимались машинным обучением, вы знаете, что данные, взятые из реальных примеров, очень сырые и нуждаются в существенной обработке. Классический пример такой обработки — процесс под названием нормализация. Если используемые при обучении модели данные слишком сильно варьируются, в худшем случае это может привести к тому, что модель не сможет прийти к определенному решению. В лучшем случае обучение модели займет значительно больше времени, чем следует, и точность модели может пострадать. Чтобы этого избежать, данные подвергаются нормализации. Есть различные способы нормализации, один из них — стандартизация. Это значит, что все значения переводятся в диапазон от -1 до 1, из этих значений рассчитывается среднее, и это среднее отнимается от значений. Этот способ очень часто используется в data science. ML.NET предоставляет возможность выполнить это преобразование за одну строку кода.
// Remove rows with missing values in the "Age" and "YearsExperience" columns
var view = context.Data.FilterRowsByMissingValues(data, "Age", "YearsExperience");
// Remove rows where "Age" is less than 20 or greater than 80
var view = context.Data.FilterRowsByColumn(data, "Age", lowerBound: 20, upperBound: 80);
// Remove the "Age" column
var estimator = context.Transforms.DropColumns("Age");
var view = estimator.Fit(data).Transform(data);
// Replace missing values in the "Age" column
var estimator = context.Transforms.ReplaceMissingValues("Age",
replacementMode: MissingValueReplacingEstimator.ReplacementMode.Mean);
var view = estimator.Fit(data).Transform(data);
Выше приведены примеры того, как можно изменять данные в DataView. При загрузке данных очень часто выясняется, что в некоторых строках есть отсутствующие значения, а это отрицательно сказывается на обучении моделей. Есть несколько способов решить эту проблему. Самый простой заключается в том, чтобы попросту удалить строки с отсутствующими значениями, и в DataView есть метод, который это позволяет сделать. Другой способ — заменить отсутствующие значения средним по столбцу. В DataView есть методы для всех этих способов.
Один из наиболее важных методов в ML.NET — TrainTestSplit. Если вы когда-либо пользовались Scikit, то могли заметить, что у многих методов в ML.NET точно такие же имена, как и у аналогичных методов в Scikit. Команда ML.NET во многом следовала примеру Scikit, и они даже создали оболочку на Python для ML.NET, которая позволяет программистам на Python обучать модели ML.NET через API Scikit. Таким образом на Python доступны преимущества ML.NET: масштабируемость, производительность и т. п. Метод TrainTestSplit важен потому, что без проверки модели машинного обучения невозможно сказать, насколько точны её прогнозы. В идеале необходимо два набора исходных данных: один для обучения и другой — для проверки. Изредка нам с самого начала доступно два набора данных. Чаще всего набор данных есть только один. В этом случае мы делим его на обучающий набор данных и проверочный набор данных. Обычно это деление выполняется в пропорции 80/20, но иногда может быть и 50/50. TrainTestSplit выполняет именно это деление набора данных на два. Он используется практически во всех примерах, которые будут далее.
Когда все подготовительные операции выполнены, начинается обучение модели. В ML.NET для этого есть специальные методы.
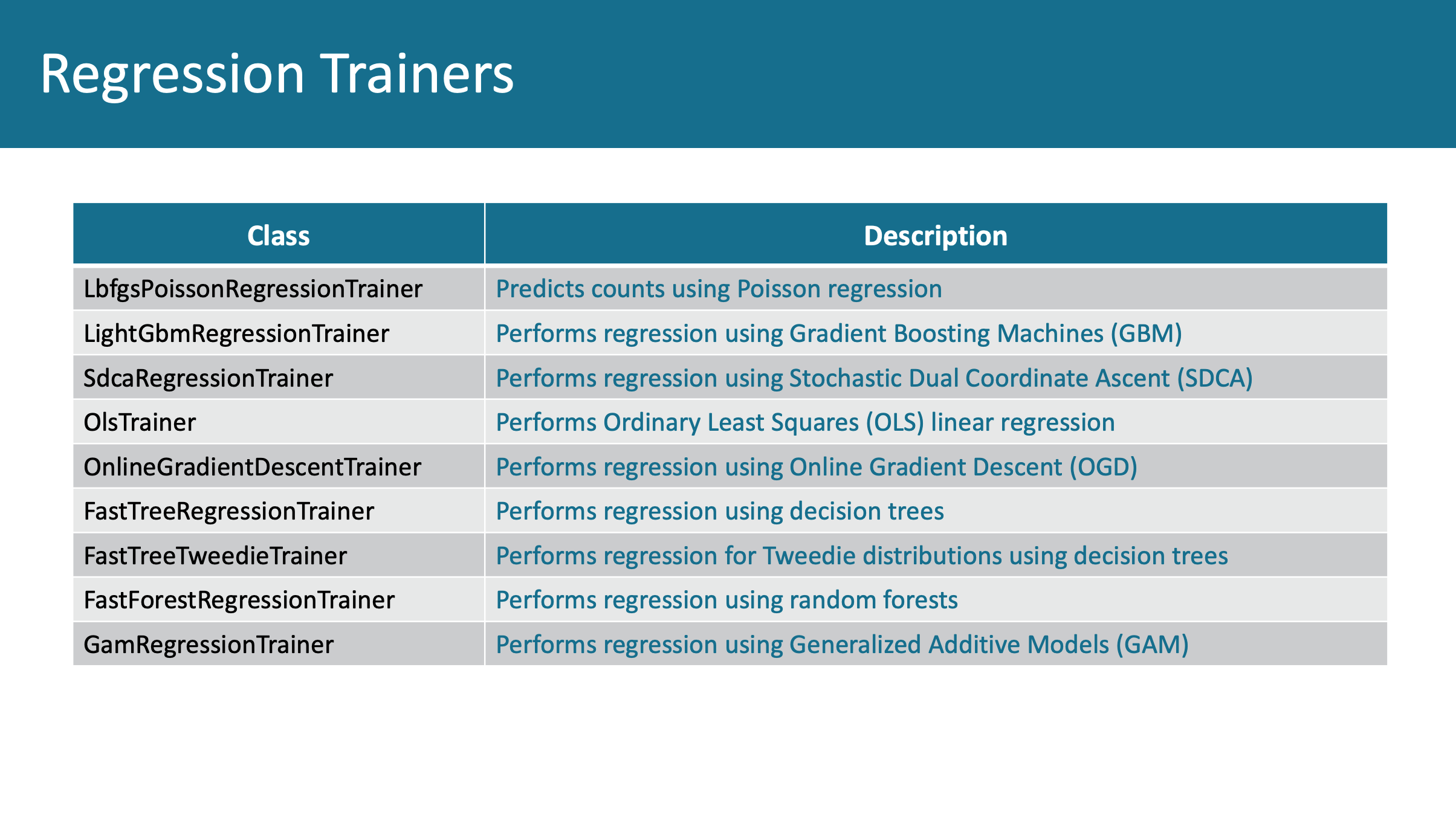
Названия на изображении выше — на самом деле классы, а не методы, просто соответствующие методы создают экземпляр класса. Машинное обучение в основном используется для проблем регрессии и классификации. Эти две проблемы составляют 99.99% того, что называется проблемами контролируемого обучения (supervised learning). Причина популярности Scikit в том, что он представляет используемые в data science алгоритмы (метод опорных векторов, случайный лес, дерево решений, обычная регрессия методом наименьших квадратов) в виде простых вызовов функций. ML.NET добивается того же самого при помощи обучающих классов. В них используется работа, проведенная Microsoft Research на протяжение последних лет.
Создание регрессионной модели
Регрессионная модель — это такая модель, результаты которой можно представить в численном значении. Например, мы используем модель для прогнозирования цены на дом или времени, после которого машина потребует техосмотра. Нам понадобится модель, которая дает результат в виде числа, то есть регрессионная модель. В ML.NET для создания таких моделей есть различные алгоритмы. Возможно многим знаком метод наименьших квадратов. Это наиболее простой вид регрессии, с которого всегда начинаются курсы по машинному обучению. Есть и значительно более сложные алгоритмы. В ML.NET все алгоритмы в этих классах обладают отличной документацией, где можно найти все подробности реализации.

Выше пример регрессионной модели. Здесь выполняется разделение данных в DataView в пропорции 80/20, то есть 80% данных будет использоваться для обучения, а 20% — для проверки. Следующий шаг — создание пайплайна. Здесь выполняется вызов context.Transforms.Concatenate. Первая строка кода в любом приложении ML.NET создает объект класса MLContext. Этот объект позволяет обратиться к свойствам, через которые предоставляется доступ к различным API ML.NET. В примере выше переменная context на первой строке является экземпляром класса MLContext. Через свойство Data этой переменной мы вызываем метод TrainTestSplit, который делит данные на два набора. Затем через свойство Transforms делается вызов метода Concatenate. Эта константа не существует в Scikit и других библиотеках машинного обучения. При обучении модели машинного обучения мы начинаем с таблицы со столбцами и строками. В одном из этих столбцов содержатся значения зависимой переменной (label column), а в остальных — значения независимых переменных (feature columns).
При обучении модель пытается построить зависимость между зависимой и независимыми переменными. Для создания такую структуру в ML.NET, необходимо вызвать метод Concatenate и создать столбец Features в своем DataView. В этом же вызове можно указать столбцы DataView, в которых будут содержаться значения независимых переменных. Можно не указывать ничего, и тогда в эту категорию будут включены все столбцы DataView. В случае примера выше мы указываем столбцы Col1, Col2 и Col3. После этого необходимо выполнить алгоритм обучения. Снова обращаемся к нашему объекту context, к свойству Regression.Trainers, и вызываем метод FastForest(), который создает экземпляр класса FastForestRegressionTrainer. Регрессия быстрый лес (Fast Forest )— это более сложный вариант регрессии случайный лес (Random Forest) и дерева решений.
Преимуществом этих алгоритмов является отсутствие потребности в нормализации данных, поэтому в нашем примере никакой нормализации не выполняется. Следующий шаг — обучение модели. Это происходит при вызове метода pipeline.Fit(), в который в качестве аргумента передаются данные для обучения. Весь предшествующий код выполняется очень быстро, этот же метод может потребовать продолжительного времени. Если набор данных небольшой, в районе тысячи значений, то выполнение займет несколько секунд, если же это таблица с 500 миллионами строк, то необходимо будет значительно больше времени. Работа с такими массивами данных обычно выполняется не на ноутбуках, а в кластерах HPC в Azure или AWS с GPU.
var options = new FastForestRegressionTrainer.Options
{
// Only use 80% of features to reduce over-fitting
FeatureFraction = 0.8,
// Simplify the model by penalizing usage of new features
FeatureFirstUsePenalty = 0.1,
// Limit the number of trees to 50
NumberOfTrees = 50
};
var pipeline = context.Transforms.Concatenate("Features", "Col1", "Col2", "Col3")
.Append(context.Regression.Trainers.FastForest(options));При вызове метода, определяющего алгоритм обучения (алгоритм быстрый лес из предыдущего примера), можно пользоваться настройками по умолчанию, но есть возможность указать свои настройки через переменную options. У функции Scikit, реализующие алгоритмы обучения, могут принимать 5, 10 или даже 20 параметров. То же самое мы видим и здесь. У всех методов, создающих классы для обучения, есть значения по умолчанию, обеспечивающие вполне удовлетворительную работу. Если правильно подобрать параметры, то точность модели можно существенно улучшить. Этот процесс подбора параметров называется hyperparameter tuning. В ML.NET постоянно используется паттерн, который вы видите выше: создание объекта options и наполнение его необходимыми параметрами. В Scikit вместо этого используются необязательные параметры функций.
Единственный способ узнать, выполняет ли модель свою задачу, это проверка. Во многих библиотеках проверка требует значительного количества кода. В ML.NET, напротив, этот процесс сделан максимально простым. Если мы создали регрессионную модель, дающую результат в виде числа, мы получаем доступ к объекту, в свойствах которого содержатся все метрики, которые используются в data science для оценки регрессионных моделей. Очень часто используется коэффициент детерминации, R2. Он изменяется в диапазоне от 0 до 1, при этом 0 означает низкую точность модели, а 1 — высокую. Следует стремиться, чтобы показатель R2 превышал 0.8 или 0.9. Есть и другие показатели, при помощи которых оценивают регрессионные модели, например, среднеквадратическая ошибка и средняя абсолютная ошибка.

Все эти показатели доступны в ML.NET, а чтобы их увидеть, необходимо сделать вызов метода context.Regression.Evaluate.
В data science очень важна перекрестная проверка (cross-validation). Когда мы случайным образом отбираем строки из набора данных для проверки модели, результаты проверки могут оказаться разными в зависимости от того, какие строки были отобраны. Поэтому принято выполнять перекрестную проверку: деление исходного набора данных на два в пропорции 80/20 выполняется пять раз, и для каждой пары выполняется обучение и проверка. Это увеличивает время выполнения алгоритма в пять раз. Теперь для оценки модели используется среднее от среднеквадратических ошибок и R2 всех пяти результатов, и такая оценка является более достоверной. В ML.NET вся эта процедура максимально упрощена. Это демонстрируется в примере:

Вместо метода Evaluate мы вызываем context.Regression.CrossValidate и указываем количество раз, которое следует выполнить перекрестную проверку. Среднее показателей R2 автоматически не рассчитывается, но отдельные показатели для каждой проверки вычисляются. Чтобы рассчитать среднее самостоятельно, достаточно одной строки кода.
Знакомы ли вы с термином унитарная кодировка (one-hot encoding)? Чаще всего модели машинного обучения умеют работать только с цифрами. При этом есть много задач, где входные значения строковые. Это так называемые категорийные значения (categorical values). В нашем наборе данных может быть столбец, обозначающий марку машины: BMW, Audi, или что-либо подобное. Текст понятен нам, людям, но не модели. Чтобы сделать эти значения понятными для модели, используется процесс, который называется унитарная кодировка. К DataView добавляются дополнительные столбцы, по одной для каждого уникального значения в столбце качественных значений. В этих столбцах указываются значения 0 или 1 в зависимости от того, существует ли соответствующее значение в исходном наборе данных. В такой форме модель машинного обучения может прочитать эти данные. В Scikit и в ML.NET это действие выполняется одной строкой кода.
Модель регрессии в ML.NET
Ссылка на видео с демонстрацией
Ссылка на репозиторий
Набор данных, с которым эта модель работает, позаимствован у Zillow, компании, занимающейся недвижимостью. Они публикуют свои данные, и их очень удобно использовать для обучения моделей машинного обучения. Наш набор данных содержится в файле CSV, в нем 440 строк. Точную модель на таком маленьком наборе не построить, но зато обучение идет быстро даже на двухядерном ноутбуке. В каждой строке содержатся данные о сделке на недвижимость в районе Сан-Франциско в США, размер жилья в квадратных футах, количество спальных комнат, ванных комнат, а также цена последней купли/продажи. Задача модели — сделать прогноз цены недвижимости на основе предоставленных параметров.
Перейдем к приложению program.cs. Это приложение .NET Core.
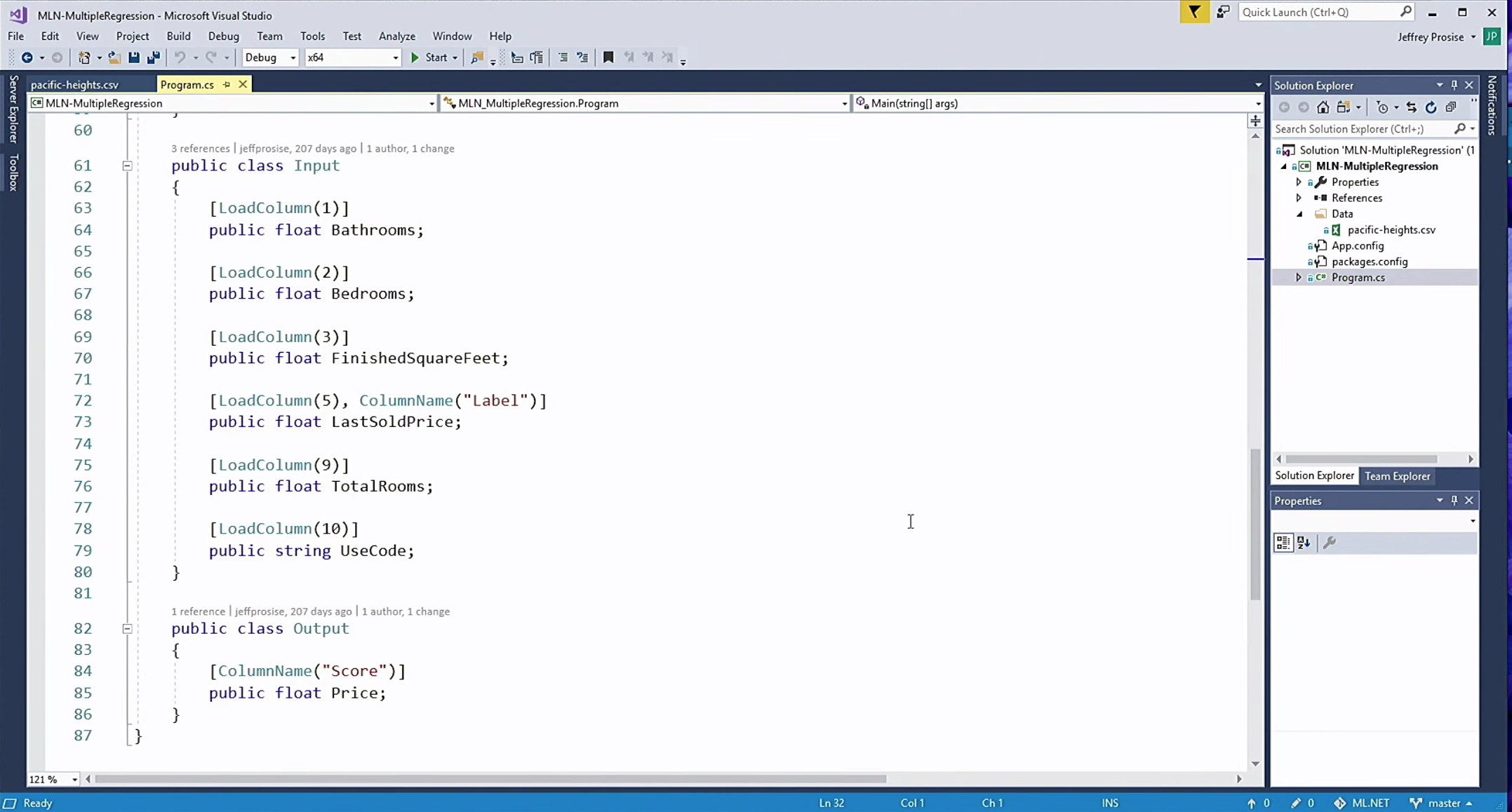
Начнем изучать код с конца. Одно из важных преимуществ ML.NET и C# в целом — сильная типизация. В Python об ошибке типизации узнаешь только при запуске кода, и трудно понять, где именно эта ошибка произошла. В ML.NET мы определяем, как должны выглядеть как входные, так и выходные данные модели машинного обучения. В примере выше я определил класс Input. Имя может быть любым. У этого класса определено несколько свойств, имена которых совпадают с именами столбцов набора данных. Атрибут LoadColumn указывает, из какого столбца файла CSV следует загружать эти данные. Обратите внимание, что одному из столбцов присвоен атрибут Label. Так называется столбец со значениями, которые необходимо прогнозировать, в данном случае это столбец с ценой последней купли/продажи. Выходными данными модели является прогноз цены недвижимости. Для выходных данных мы определяем отдельный класс с именем Output, и создаем в нем переменную Price. Имя переменной может быть любое, важен её атрибут: ColumnName. Мне не нравятся библиотеки, в которых выполняются различные трюки при чтении строковых значений, но здесь допущено такое поведение. В данном случае ColumnName может быть только Score, при любых других значениях возникает исключение. Этот атрибут указывает, что столбец Score итогового DataView должен быть связан с соответствующей переменной в классе Output.
Ccылка на видео с демонстрацией
Ссылка на репозиторий
Рассмотрим код, который создает модель, обучает и затем выполняет её. Мы создаем новый объект MLContext, который, как мы помним, предоставляет доступ ко всем необходимым API. При создании этого объекта можно указать начальное значение для генератора случайных чисел. Во многих популярных библиотеках на Python одну и ту же модель можно обучать по многу раз с одним и тем же набором данных, и каждый раз результат будет новым, поскольку эти библиотеки генерируют случайные числа для своей работы. В Keras не сразу понятно, как изменить такое поведение модели. Для этого нужно выйти на Stack Overflow, где предлагается решение проблемы в виде 10 строк кода, и скопировать этот код к себе. ML.NET значительно упрощает эту процедуру и легко позволяет получать одинаковые результаты при одинаковых входных данных.
Я создаю DataView при помощи метода LoadFromTextFile, которому передается файл PacificHeights.csv. В этом файле нет отдельных наборов данных для обучения и проверки, поэтому их необходимо создать. Это делается при помощи метода TrainTestSplit, и теперь мы используем 80% данных для обучения, а 20% — для проверки. В исходном наборе данных есть столбец под названием UseCode, в котором указывается тип жилища (кондоминиум, отдельный дом, квартира). Эти значения являются категорийными, так что нам необходимо выполнить унитарную кодировку. Для этого мы вызываем метод OneHotEncoding и указываем ему соответствующий столбец качественных значений (UseCode). Затем мы выполняем вызов Concatenate и указываем, в каких столбцах содержатся значения независимых переменных. Последний вызов в этой строке выбирает алгоритм Fast Forest для обучения модели. Вызов метода pipeline.fit() запускает обучение модели. В наборе данных, который мы используем, всего 400 с лишним строк — обучение пройдёт очень быстро.
Ссылка на видео с демонстрацией
В результате показатель R2 равен 0.74, что не так уж и плохо. При этом показатель R2 по результатам перекрестной проверки ниже, то есть без перекрестной проверки этот показатель оказывается завышен. Цена, которую спрогнозировала модель, оказалась довольно близка к фактической цене.
Оценка и прогноз
Для оценки используется метод context.Regression.Evaluate объекта класса MLContext. В качестве ключевого показателя я выбрал R2. Он изменяется в диапазоне от 0 до 1, где 1 соответствует максимальной точности. При помощи метода context.Regression.CrossValidate мы получаем более реалистичное представление о точности модели.
Ссылка на видео с демонстрацией
Ссылка на репозиторий. Строка 48
Перейдем к прогнозу. Чтобы сделать прогноз при помощи созданной (в идеале, проверенной) модели, необходимо вызвать метод CreatePredictionEngine. В качестве параметров этого метода вводятся объекты Input и Output, определяющие свойства входных и выходных данных модели соответственно. Мы создаем этот объект Input, присваиваем необходимые значения его свойствам, и, наконец, вызываем метод .Predict у объекта, возвращенного методом CreatePredictionEngine. Такой паттерн широко используется в ML.NET.
Обобщим
Мы познакомились с основами использования ML.NET. В ML.NET используется сильная типизация, которая позволяет указать как формат данных, используемых для обучения модели, так и формат выходных данных модели. В случае рассмотренного примера результатом работы модели является значение float Price, которое прогнозируется на основе столбца LastSoldPrice исходного набора данных. Этот столбец был обозначен как Lable. Мы создали объект класса MLContext, затем создали DataView на основе файла CSV с исходными данными. Затем мы разделили этот набор данных в пропорции 80/20 для обучения и проверки модели. Поскольку данные содержали столбец с категорийными значениями, указывающий тип жилища, мы выполнили унитарную кодировку. При помощи метода Concatenate мы указали столбцы, на основе которых должно выполняться обучение модели. После этого мы указали, что модели следует использовать алгоритм Fast Forest. Непосредственно обучение было вызвано методом .Fit().
Модели классификации
В машинном обучении есть ещё один вид моделей — модели классификации. Такие модели используются для того, чтобы определить, является ли сообщение электронной почты спамом. Такая модель, где классификация идет лишь по двум возможным классам, называется моделью бинарной классификации. Другой пример — оптическое распознавание символов, было одним из наиболее ранних применений машинного обучения около 20 лет тому назад. Это уже многоклассовая классификация, поскольку возможное число классов равно числу символов, которые необходимо распознать. Для таких моделей применяется немного другой алгоритм обучения. В ML.NET есть несколько различных широко используемых алгоритмов бинарной классификации.
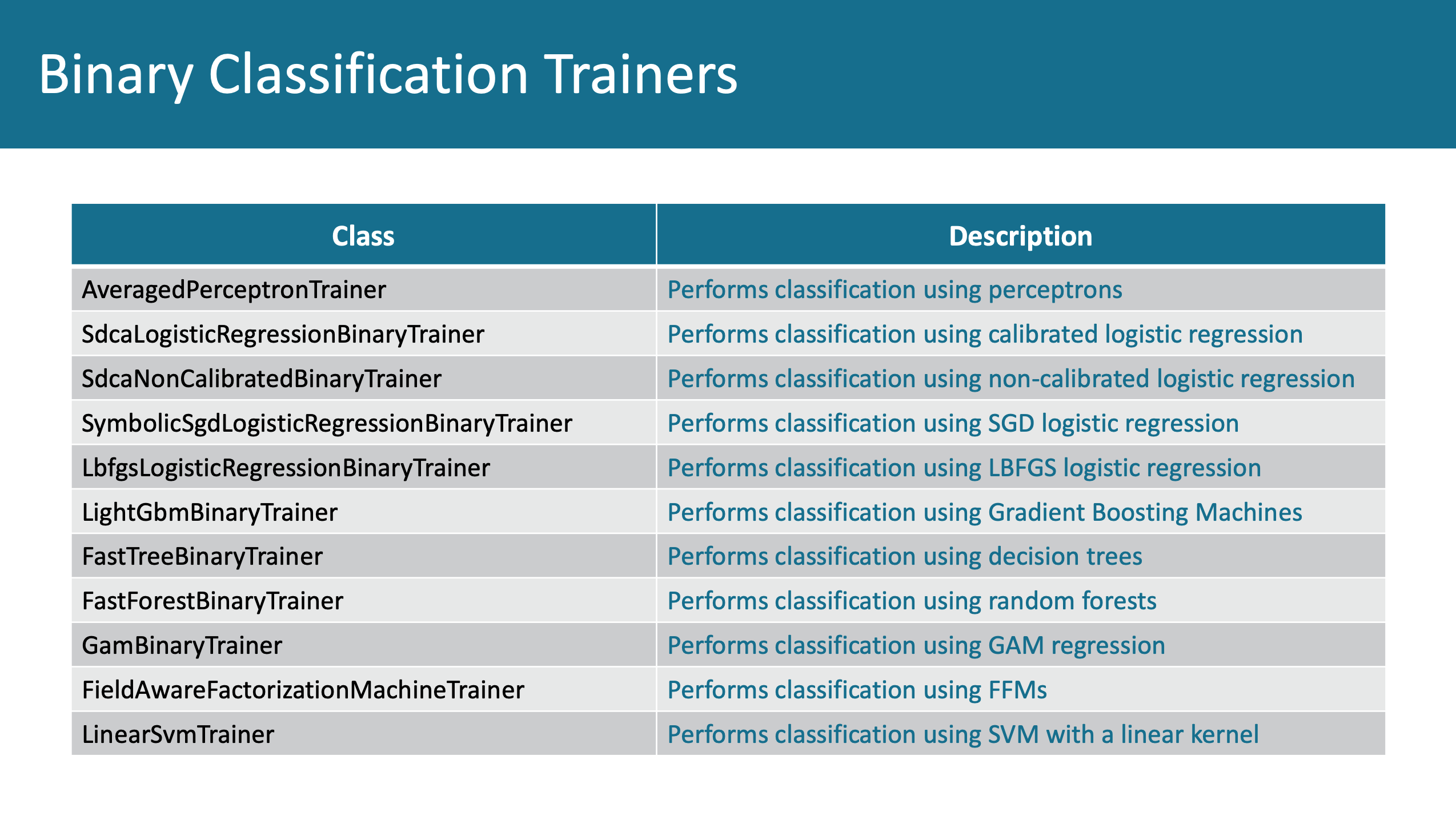
Выше перечислены классы этих алгоритмов. Также, как и в случае с регрессионными моделями, модели классификации необходимо проверять после того, как завершено их обучение. Показатели оценки точности модели здесь используются другие. Тут нет R2 или среднеквадратической ошибки. Вместо этого применяются: показатель F1, показатель площади под кривой scores, матрица несоответствия (confusion matrix) и другие. Все они доступны в ML.NET, для их вычисления необходима всего одна строка кода. Вызов метода Evaluate возвращает объект, в свойствах которого хранятся все необходимые показатели. Так же, как и с регрессионными моделями, с моделями классификации можно выполнять перекрестную проверку. После нее мы, опять-таки, получаем объект, свойства которого содержат показатели, описывающие нашу модель.
Векторизация текста
Модели машинного обучения могут работать лишь с числами. Текст в наборах данных может быть в форме категорийных значений, например, порода собаки или марка автомобиля. Зачастую данные могут содержать целые предложения и абзацы. В случае задачи классификации сообщений электронной почты текст сообщений необходимо превратить в векторы, то есть в наборы нулей и единиц. Здесь нас не выручит унитарная кодировка. Чаще всего в этом случае применяется векторизация. При этом текст проходит несколько преобразований. Он целиком переводится в нижний регистр, из него удаляются слова с небольшой смысловой нагрузкой (в английском языке это напр. «the» или «that»). На основе очищенного текста создается таблица нулей и единиц, в которой для каждого уникального слова или сочетания слов есть отдельный столбец. Такая таблица может достигать колоссальных размеров — если в тексте используется 50 тысяч различных слов, то в таблице будет 50 тысяч столбцов. Если же таких текстов (например, сообщений) миллион, то в ней также будет 1 миллион строк. Для компьютера это не такие уж и большие числа. В ML.NET есть метод FeaturizeText, который автоматически выполняет все эти действия. При его выполнении текст проходит 9 различных преобразований, которые в большинстве других библиотек необходимо делать вручную.
Работа с методом FeaturizeText
Если вы интересуетесь машинным обучением, вы слышали об анализе тональности текста. Модель может проанализировать рецензию на фильм или отзыв на товар и оценить этот текст в диапазоне от 0 до 1, где 1 — позитивная оценка, а 0 — негативная. Мой сын занимается data science, он закончил ВУЗ полтора года тому назад, а за полгода до выпуска он работал в компании, которая продает товары для домашних животных по всему миру. Одной из первых задач для него было создать модель анализа тональности текста, которая могла бы предупреждать отдел маркетинга в случае, если в твиттере появлялись негативные оценки компании или её продуктов. Анализ тональности текста выполнить довольно просто.
Ссылка на видео с демонстрацией
Ccылка на репозиторий. Строка 21
Рассмотрим пример такого анализа. У нас есть набор из 1000 высказываний с Yelp. Это довольно маленький набор данных. Каждому из высказываний уже присвоена оценка 0 или 1 в зависимости от того, положительный это комментарий или отрицательный. На основе этого мы создаем модель бинарной классификации, которая сможет присвоить любой строке текста оценку от 0 до 1. Мы создаем объект класса MLContext, загружаем DataView из файла TSV, делим набор данных на две части, одна из которых используется для обучения, другая — для проверки. После этого мы вызываем метод .FeaturizeText, который создает огромный набор данных с отдельным столбцом для каждого уникального слова в анализируемых текстах. В качестве алгоритма мы используем быстрое дерево (эта версия алгоритма выполняет классификацию, а не регрессию). Я опробовал несколько алгоритмов для решения этой задачи, и этот дал сравнительно неплохие результаты. Метод .Fit() выполняет обучение модели. После этого мы делаем оценку и перекрестную оценку модели.
Ссылка на видео с демонстрацией
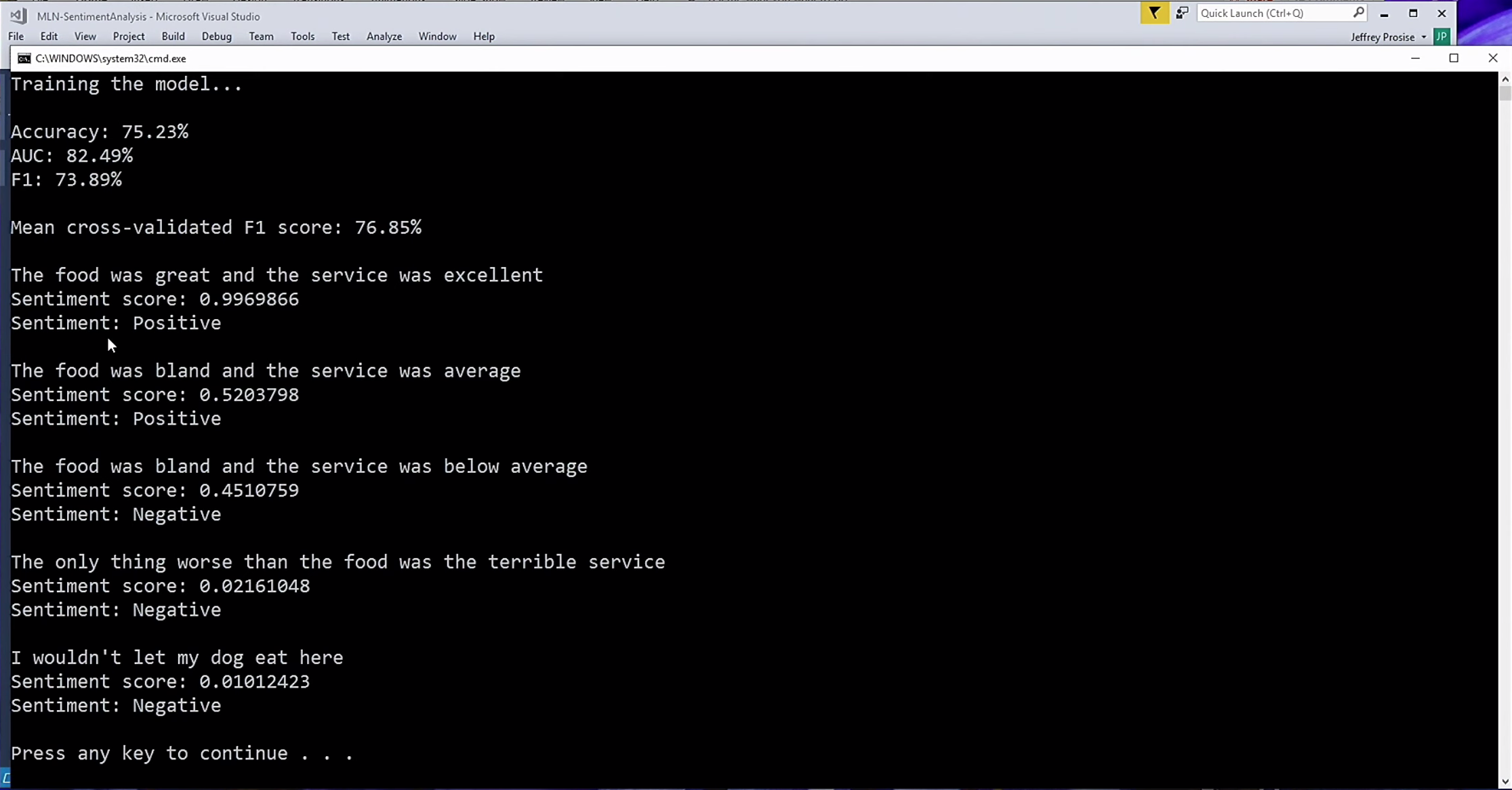
Фраза «Еда отличная, и прекрасное обслуживание» получила оценку 0.996, то есть очень высокую. Фраза «Я бы свою собаку сюда есть не привел» оценена баллом 0.01, то есть очень низким. Результат довольно точный. Ни одна библиотека не создает настолько точные модели анализа тональности настолько быстро, как ML.NET. Это всё можно делать в C#.
Обнаружение спама
Несколько слов об используемом наборе данных. Причина, по которой машинное обучение так сильно набрало обороты в последнее время, заключается в том, что сейчас нам доступно больше данных, чем ещё 5 или 10 лет назад. В прошлом произошел скандал вокруг фирмы Enron, в результате которого несколько её руководителей оказались в тюрьме. Миллионы сообщений электронной почты этой компании стали собственностью государства США и были опубликованы. Исследователи перебрали всю эту гору сообщений, и присвоили каждому оценку 1 или 0, то есть спам или не спам. Благодаря этой работе сейчас мы можем обучать очень точные модели определения спама. Это не единственный набор данных для обнаружения спама, находящийся в открытом доступе.
Для нашей модели мы используем иной алгоритм, чем в предыдущем примере. Я опробовал несколько различных алгоритмов, и этот дал наилучшие результаты. Уже обученной модели я передал несколько пробных сообщений, одно из которых было очевидным спамом. Последнее получило оценку около 0.1. То есть алгоритм дает очень точные результаты. 20 лет назад именно эта задача стала одним из первых применений машинного обучения. До этого для обнаружения спама использовались системы, работавшие на основе правил, и их было довольно легко обойти.
Область применения машинного обучения и ИИ существенно выросла благодаря последним достижениям в компьютерном зрении. Предположим, вы работаете в компании, которая производит детали машин. Нам необходимо написать программу, которая сможет определить по фото, является ли сошедшая с конвейера часть бракованной или нет. 20 лет тому назад эта задача была почти нерешаемой, 10 лет назад она была бы крайне проблематичной, на сегодняшний день она решена благодаря достижениям в области классификации изображений. Классификация изображений — это процесс узнавания программой объектов на изображении. Большинство моделей, выполняющих классификацию изображений, являются конволюционными нейронными сетями. Подробнее о главной трудности при классификации изображений.
В нашем примере с обнаружением брака в деталях создать программу вполне реально, но чтобы обучить её, понадобится очень крупный и дорогой кластер HPC с GPU. Причина, по которой исследователи из Microsoft Research или Facebook могут создавать крайне сложные модели распознавания изображений заключается в том, что у них есть доступ к кластерам с тысячами узлов с GPU от NVIDIA. Без доступа к таким мощностям обучить сеть обычным способом распознавать бракованную деталь невозможно. Мы можем обойти эту трудность при помощи переноса обучения. Microsoft, Google и Facebook уже создали крайне сложные конволюционные нейронные сети при помощи TensorFlow и опубликовали их на GitHub. Эти сети довольно большие, до 100 мегабайт.
Перенос обучения позволяет убрать уровни классификации у такой сети и приспособить её для наших нужд. Переучив такую сеть на 50-100 изображениях, можно получить точность выше 90%. В Scikit этого сделать нельзя. Keras такую возможность предоставляет, но там это выглядит жутко. В ML.NET пока нельзя создавать нейронные сети с нуля. Но зато можно переучивать готовые нейронные сети, созданные Microsoft, Google или кем-либо ещё.
В США есть довольно популярный сериал Silicon Valley. В этом сериале был эпизод, где фигурировало приложение Not a Hot Dog. Оно могло определить, является ли еда на изображении хот-догом. Задача здесь на самом деле очень сложная, и ещё 10 лет тому назад она была бы нерешаемой. В моём примере я использовал созданную Google конволюционную нейронную сеть.
При помощи малоизвестного класса ML.NET TensorFlowModel я переобучил эту модель на 20 изображениях, и теперь она может определить, присутствует ли на изображении хот-дог. После этого я вызвал метод, который сохранил новую версию модели на жёсткий диск в виде файла ZIP. Затем я написал небольшое приложение WPF, которое использует эту модель. Благодаря тому, что она сохранена на жесткий диск, можно не тратить каждый раз время на её обучение, и сразу же загружать её в программу из файла. В приложении можно загрузить изображение, и при помощи модели оно определяет, присутствует ли на изображении хот-дог. Без переноса обучения для обычного программиста было бы невозможно создать нейронную сеть, которая могла бы решить такую задачу. С ML.NET использовать чужие нейронные сети проще, чем с любой другой библиотекой для машинного обучения.
На GitHub есть репозиторий, где можно найти все примеры, которые Джефф Просайз демонстрировал в докладе, а также некоторые другие. Периодически в этих примерах код обновляется. Адрес репозитория: github.com/jeffprosise/ML.NET.
DotNext 2020 Piter пройдет в новом онлайн-формате с 15 по 18 июня. Джефф Просайз представ
