Николай Рыжиков предложил свою версию ответа на вопрос, почему же так сложно разрабатывать пользовательский интерфейс. На примере своего проекта он покажет, что применение на фронтенде некоторых идей из бэкенда сказывается как на сокращении сложности разработки, так и на тестируемости фронтенда.
Материал подготовлен на основе доклада Николая Рыжикова на весенней конференции HolyJS 2018 Piter.
В данный момент Николай Рыжиков работает в Health-IT секторе над созданием медицинских информационных систем. Член питерского сообщества функциональных программистов FPROG. Активный участник Online Clojure community, member стандарта по обмену медицинской информацией HL7 FHIR. Занимается программированием 15 лет.
— Меня всегда мучил вопрос: почему графический UI всегда было сложно делать? Почему это всегда вызывало много вопросов?
Сегодня я попробую порассуждать о том, можно ли эффективно разрабатывать пользовательский интерфейс. Можем ли мы уменьшить сложность его разработки.
Что такое эффективность?
Давайте определим, что такое эффективность. С точки зрения разработки пользовательского интерфейса под эффективностью подразумевают:
скорость разработки,
количество багов,
количество затраченных денег…
Есть очень хорошее определение:
Эффективность — это делать больше, затрачивая меньше
После этого определения можно поставить все, что угодно — затрачивая меньше времени, меньше усилий. Например, «если вы пишите меньше кода, допускаете меньше багов» и достигаете той же самой цели. В целом мы тратим очень много сил напрасно. И эффективность — это достаточно высокая цель — избавиться от этих потерь и делать только то, что нужно.
Что такое сложность?
На мой взгляд, сложность — основная проблема в разработке.
Фред Брукс (Fred Brooks) в далеком 1986 году написал статью, которая называется «No silver bullet». В ней он размышляет о софте. В железе прогресс идет семимильными шагами, а с софтом все гораздо хуже. Основной вопрос Фреда Брукса — может ли появиться такая технология, которая ускорит нас сразу на порядок? И сам дает пессимистичный ответ, констатируя, что в software не получается этого добиться, объясняя свою позицию. Я настоятельно рекомендую почитать эту статью.
Один мой друг сказал, что программирование UI — это такая «грязная проблема». Ты не можешь сесть один раз и придумать правильный вариант, чтобы проблема решилась навсегда. Кроме того, за последние 10 лет сложность разработки только возросла.
12 лет назад…
Мы начали разрабатывать медицинскую информационную систему 12 лет назад. Сначала с flash. Потом посмотрели на то, что начал делать Gmail. Нам понравилось, и мы захотели перейти на JavaScript с HTML.
На самом деле, тогда мы сильно опередили время. Мы взяли dojo, и фактически у нас было все то же самое, что есть сейчас. Были компоненты, достаточно хорошо вылизанные в dojo виджеты, была модульная система сборки и require, которые собирал и минифицировал Google Clojure Compiler (RequireJS и CommonJS тогда даже не пахло).
Все получалось. Мы смотрели на Gmail, вдохновлялись, думали, что все хорошо. Вначале мы писали только ридер карточки пациента. Потом постепенно перешли к автоматизации других workflow в больнице. И все стало сложно. В команде вроде профессионалы —, но каждая фича начала скрипеть. Это ощущение появилось 12 лет назад — и не покидает меня до сих пор.
Rails way + JQuery
Мы делали сертификацию системы, и нужно было написать портал пациента. Это такая система, куда пациент может зайти и посмотреть свои медицинские данные.
Бэкенд у нас тогда был написан на Ruby on Rails. Несмотря на то, что сообщество Ruby on Rails — не очень большое, оно оказало огромное влияние на индустрию. Из маленького пассионарного сообщества пришли все ваши пакетные менеджеры, GitHub, Git, автоматические мейки и т.д.
Суть вызова, с которым мы столкнулись, заключалась в том, что реализовать портал пациента надо было за две недели. И мы решили попробовать Rails way — делать все на сервере. Такой классический web 2.0. И сделали — действительно уложились в две недели.
Мы оказались впереди всей планеты: делали SPA, у нас был REST API, но это почему-то было неэффективно. Некоторые фичи уже могли сделать единицы, потому что только они были способны вместить в себя всю эту сложность компонентов, взаимосвязей бэкенда с фронтендом. А когда мы взяли Rails way — немного устаревший по нашим меркам, фичи вдруг начали клепаться. Средний разработчик начал выкатывать фичу за несколько дней. И мы даже стали писать несложные тесты.
На этой почве у меня на самом деле до сих пор травма: остались вопросы. Когда мы на бэкенде перешли с Java на Rails, эффективность разработки выросла приблизительно в 10 раз. Но когда мы забили на SPA, эффективность разработки тоже выросла в разы. Как так?
Почему Web 2.0 был эффективен?
Начнем с другого вопроса: почему мы делаем single page application, почему верим в него?
Просто нам говорят: нужно делать так — и мы делаем. И очень редко подвергаем это сомнению. Правильная ли архитектура REST API и SPA? Действительно ли она подходит для того случая, где мы ее используем? Мы не задумываемся.
С другой стороны, есть выдающиеся обратные примеры. Все пользуются GitHub. А вы знаете, что GitHub — это не single page приложение? GitHub — это обычное «рельсовое» приложение, которое рендерится на сервере, и где есть немного виджетов. Кто-нибудь испытывал муку от этого? Я думаю, человека три. Остальные даже не заметили. На пользователе это никак не отразилось, но при этом мы почему-то должны платить за разработку других приложений в 10 раз больше (и сил, и сложности, и т.д.). Еще пример — Basecamp. Twitter когда-то был просто Rails-приложением.
На самом деле, есть очень много Rails-приложений. Частично это определил гений DHH (David Heinemeier Hansson, создатель Ruby on Rails). Он смог создать инструмент, сфокусированный на бизнесе, который позволял сразу делать то, что нужно, не отвлекаясь на технические проблемы.
Когда мы использовали Rails way, там, конечно, было очень много черной магии. Постепенно развиваясь, мы переключились с Ruby на Clojure, практически сохранив ту же эффективность, но сделав все на порядок проще. И это было прекрасно.
Прошло 12 лет
Со временем во фронтенде стали появляться новые веяния.
Backbone мы полностью проигнорировали, потому что dojo приложение, которое мы писали до этого, было даже более навороченным, чем то, что предлагала Backbone.
Потом появился Angular. Это был достаточно интересный «лучик света» — с точки зрения эффективности Angular очень хорош. Вы берете среднего разработчика, и он клепает фичу. Но с точки зрения простоты Angular приносит кучу проблем — он непрозрачный, сложный, там watch, оптимизации и т.д.
Появился React, который принес немного простоты (как минимум, прямолинейность рендера, который за счет Virtual DOM позволяет нам каждый раз как будто бы просто перерисовывать, просто понимать и просто писать). Но с точки зрения эффективности, если честно, React ощутимо откинул нас назад.
Самое страшное, что за 12 лет ничего не изменилось. Мы сейчас до сих пор делаем то же, что и тогда. Пора задуматься — что-то здесь не так.
Фред Брукс говорит о том, что в разработке софта есть две проблемы. Конечно, основную проблему он видит в сложности, но разделяет ее на две группы:
существенная сложность, которая приходит из самой задачи. Ее просто не выкинуть, потому что это часть задачи.
случайная сложность — это та, которую мы приносим, пытаясь решить эту задачу.
Встает вопрос, каков баланс между ними. Как раз об этом мы сейчас и порассуждаем.
Почему так больно делать User Interface?
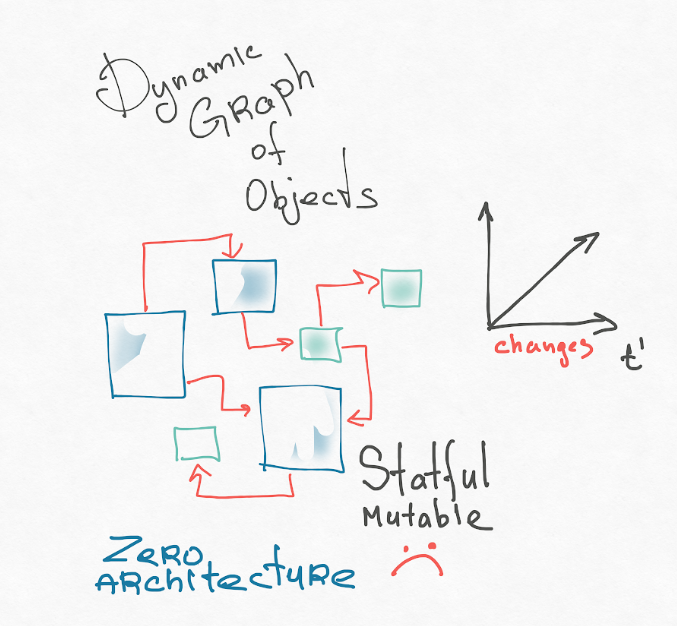
Как мне кажется, первая причина — это наша ментальная модель приложения. React, компоненты — это чисто ООП-шный подход. Наша система — это динамический граф связанных между собой мутабельных объектов. Тьюринг-полные типы порождают постоянно ноды этого графа, какие-то ноды исчезают. Вы когда-нибудь пытались представить свое приложение в голове? Это страшно! Я обычно представляю ООП-шное приложение так:
Рекомендую почитать тезисы Роя Филдинга (автора REST-архитектуры). Его диссертация называется «Architectural Styles and the Design of Network-based Software». В самом начале там идет очень хорошее введение, где он рассказывает, как вообще подобраться к архитектуре, и вводит понятия: разбивает систему на компоненты и связи между этими компонентами. У него есть «нулевая» архитектура, где все компоненты потенциально могут быть связаны со всеми. Это архитектурный хаос. Это и есть наше объектное представление user interface.
Рой Филдинг рекомендует поискать и наложить набор ограничений, потому что именно набором ограничений и определяется ваша архитектура.
Наверное, самая важная вещь заключается в том, что ограничения — это друзья архитектора. Ищите эти настоящие ограничения и дизайните систему от них. Потому что свобода — это зло. Свобода значит, что у вас миллион опций, из которых вы можете выбрать, и ни одного критерия, с помощью которого вы можете определить, правильным ли был выбор. Ищите ограничения и отталкивайтесь от них.
Есть отличная статья, которая называется OUT OF THE TAR PIT («Проще смоляной ямы»), в которой ребята вслед за Бруксом решили проанализировать, что именно вносит вклад в сложность приложения. Они пришли к неутешительному выводу, что мутабельный, размазанный по системе state — это основной источник сложности. Объяснить тут можно чисто комбинаторно — если у вас есть две ячейки, и в каждой из них может лежать (или не лежать) шарик, сколько возможно состояний? — Четыре.
Если три ячейки — 23, если 100 ячеек — 2100. Если вы представите свое приложение и поймете, насколько размазан state, вы осознаете, что возможных состояний вашей системы бесконечное количество. Если при этом вы ничем не будете ограничены, это слишком сложно. А человеческий мозг слаб, это уже доказано различными исследованиями. Мы способны держать в голове до трех элементов одновременно. Некоторые говорят — семь, но даже для этого мозг использует хак. Поэтому сложность для нас — действительно проблема.
Рекомендую прочитать эту статью, где ребята приходят к выводу, что с этим мутабельным state-ом надо что-то делать. Например, существуют реляционные базы данных, туда можно убрать весь мутабельный state. А остальную часть — сделать в чисто функциональном стиле. И они как раз выступают с идеей такого функционально-реляционного программирования.
Таким образом, проблема идет от того, что:
во-первых, у нас нет хорошей зафиксированной модели user interface. Компонентные подходы приводят нас к существующему аду. Мы не накладываем никаких ограничений, размазываем мутабельный state, в результате сложность системы нас в какой-то момент просто давит;
во-вторых, если мы пишем классическое backend — frontend приложение, это уже распределенная система. А первое правило распределенных систем — не создавайте распределенные системы (First Law of Distributed Object Design: Don’t distribute your objects — by Martin Fowler), поскольку вы сразу увеличиваете сложность на порядок. Кто писал любую интеграцию, понимает, что, как только вы входите в межсистемное взаимодействие, все оценки проекта можно умножать на 10. Но мы просто забываем про это и переходим к распределенным системам. Наверное, это было основным соображением, когда мы перешли на Rails, вернув весь контроль на сервер.
Все это слишком жестко для бедного человеческого мозга. Давайте подумаем, что же мы можем сделать с этими двумя проблемами — отсутствием ограничений в архитектуре (графом мутабельных объектов) и переходом к распределенным системам, которые сложны настолько, что академики до сих пор ломают голову, как их правильно делать (в то же время мы обрекаем себя на эти муки в простейших бизнес-приложениях)?
Как эволюционировал бэкенд?
Если мы напишем бэкенд в том же стиле, в каком сейчас создаем UI, будет такое же «кровавое месиво». Мы будем тратить на него столько же времени. Так действительно когда-то пытались делать. Потом постепенно стали накладывать ограничения.
Первое великое изобретение бэкенда — база данных.
Поначалу в программе весь state висел непонятно где, и управляться с ним было сложно. Со временем разработчики придумали базу данных и убрали весь state туда.
Первое интересное отличие базы в том, что данные там — это не какие-то объекты со своим поведением, это чистая информация. Там лежат таблицы или какие-то иные структуры данных (например, JSON). У них нет поведения, и это тоже очень важно. Потому что поведение — это интерпретация информации, и интерпретаций может быть много. А базовые факты — они так и остаются базовыми.
Другой важный момент заключается в том, что над этой базой данных у нас есть язык запросов, например SQL. С точки зрения ограничений в большинстве случаев SQL — это не тьюринг-полный язык, он более простой. С другой стороны, он декларативный — более выразительный, потому что на SQL вы говорите «что», а не «как». Например, когда вы в SQL объединяете две таблички, SQL сам решает, как эффективно выполнить эту операцию. Когда вы что-то ищете, он сам подбирает вам индекс. Вы это никогда явно не указываете. Если вы попробуете объединить что-то в JavaScript, вам придется для этого написать кучу кода.
Тут, опять таки, важно, что мы наложили ограничения и теперь в эту базу мы ходим через более простой и выразительный язык. Перераспределили сложность.
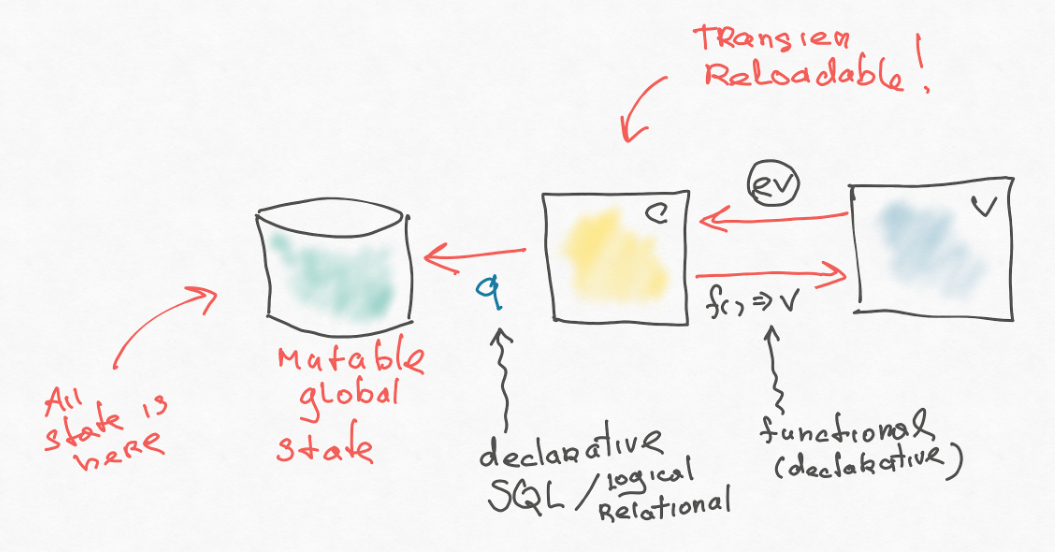
После того, как бэкенд ввел базу, приложение стало stateless. Это приводит к интересным эффектам — теперь мы, например, можем не бояться обновлять приложение (в памяти в application-слое у нас не висит state, который исчезнет, если приложение перезапустится). Для application-слоя stateless — это хорошая характеристика и отличное ограничение. Накладывайте его, если можете. Более того, на старую базу можно натянуть новое приложение, потому что факты и их интерпретация — это не связанные вещи.
С этой точки зрения объекты и классы — ужасны, потому что склеивают поведение и информацию. Информация богаче, она живет дольше. Базы и факты переживают код, написанный на Delphi, Perl или JavaScript.
Когда бэкенд пришел к такой архитектуре, все стало гораздо проще. Наступила «золотая» эпоха Web 2.0. Можно было достать что-то из базы, подвергнуть данные темплейтингу (чистая функция) и вернуть HTML-ку, которая отправляется в браузер.
На бэкенде научились писать достаточно сложные приложения. И большинство приложений написано в таком стиле. Но как только бэкенд делает шаг в сторону — в неопределенность — опять начинаются проблемы.
Люди стали задумываться над этим и пришли к идее выкидывать ООП и ритуалы.
Что на самом деле делают наши системы? Они берут информацию откуда-то — от пользователя, из другой системы и тому подобное — складывают ее в базу, трансформируют, как-то проверяют. Из базы они вынимают ее хитрыми запросами (аналитическими или синтетическими) и возвращают. Это все. И это важно понимать. С этой точки зрения симуляции — очень неправильная и плохая концепция.
Мне кажется, вообще весь ООП на самом деле родился из UI. Люди пытались моделировать и симулировать user interface. Они видели некий графический объект на мониторе и думали: хорошо было бы его просимулировать в нашем рантайме, вместе с его свойствами и т.д. Вся эта история очень тесно переплетена с ООП. Но симуляция — это самый прямолинейный и наивный способ решить поставленную задачу. Интересные вещи делаются, когда шагаешь в сторону. С этой точки зрения важнее все-таки отделить информацию от поведения, избавиться от этих странных объектов, и все станет гораздо проще: ваш веб-сервер получает строку HTTP, возвращает строку ответа HTTP. Если вы добавите в уравнение базу, то получится вообще чистая функция: сервер принимает базу и запрос, возвращает новую базу и ответ (данные вошли — данные вышли).
По пути этого упрощения функциональщики выкинули еще ⅔ багажа, который накопился на бэкенде. Он оказался не нужен, это был просто ритуал. Мы все-таки не game dev — нам не нужно, чтобы пациент и врач как-то жили в рантайме, двигались и отслеживали свои координаты. Наша информационная модель — это нечто иное. Мы не симулируем медицину, продажи или еще что-то. Мы создаем нечто новое на стыке. Например, Uber не симулирует поведение операторов и машин — он привносит новую информационную модель. В своей области мы тоже создаем нечто новое, поэтому можно почувствовать свободу.
Не обязательно пытаться симулировать полностью — создавайте.
Clojure = JS--
Пришло время рассказать, как именно можно все выкинуть. И здесь я хочу упомянуть Clojure Script. На самом деле, если вы знаете JavaScript, вы знаете и Clojure. В Clojure мы не добавляем фичи к JavaScript, а убираем их.
Мы выкидываем синтаксис — в Clojure (в Lisp-ах) нет синтаксиса. В обычном языке мы пишем некий код, который потом разбирается и получается AST, которое компилируется и выполняется. В Lisp-ах мы сразу пишем AST, который можно исполнять — интерпретировать или компилировать.
Мы выкидываем мутабельность. В Clojure нет мутабельных объектов или массивов. Каждая операция порождает как будто бы новую копию. При этом эта копия очень дешевая. Вот так хитро сделано, чтобы она была дешевой. И это позволяет нам работать, как в математике, со значениями. Мы ничего не меняем — мы порождаем что-то новое. Безопасно, легко.
Мы выкидываем классы, игрища с прототипами и т.д. Этого просто нет.
В итоге у нас остаются функции и структуры данных, над которыми мы оперируем, а также примитивы. Вот весь Clojure. И на нем можно делать все то же самое, что вы делаете на других языках, где есть много лишних инструментов, которыми никто не знает, как пользоваться.
Примеры
Как мы приходим к Lisp через AST? Вот классическое выражение:
(1 + 2) - 3
Если мы попробуем записать его AST, например, в виде массива, где голова — это тип ноды, а то, что дальше, — это параметр, у нас получится что-то подобное (мы в Java Script пытаемся это записать):
[‘minus’,
[‘plus’,
1,
2],
3]
Теперь выкинем лишние кавычки, минус можем заменить на -, а плюс на +. Выкинем запятые, которые в Lisp-ах являются пробельным символом. Мы получим то же самое AST:
(- (+ 1 2) 3)
И в Lisp-е мы все записываем так. Мы можем проверить — это чистая математическая функция (мой emacs подключен к браузеру; я кидаю туда скрипт, он там eval-ит команду и присылает мне обратно в emacs — вы видите значение после символа =>):
(- (+ 1 2) 3) => 0
Мы также можем объявить функцию:
(defn xplus [a b]
(+ a b))
((fn [x y] (* x y)) 1 2) => 2
Или анонимную функцию. Возможно, это выглядит немного страшновато:
(type xplus)
Тип у нее — JavaScript-овая функция:
(type xplus) => #object[Function]
Мы можем ее вызвать, передав ей параметр:
(xplus 1 2)
То есть все, что мы делаем, — пишем AST, которое потом либо компилируется в JS или байт-код, либо интерпретируется.
(defn mymin [a b]
(if (a > b) b a))
Clojure — это hosted language. Поэтому он берет примитивы из родительского рантайма, то есть в случае Clojure Script у нас будут JavaScript-овые типы:
Это можно читать так, как будто вы бы создавали объект в JavaScript:
(def user {name: "niquola"
…
В Clojure это называется hashmap. Это некий контейнер, в котором лежат значения. Если используются квадратные скобки — то это называется вектором — это ваш array:
Любую информацию мы записываем хэшмапами и векторами.
Странные имена с двоеточием (:name) — это так называемые символы: константные строки, которые созданы для того, чтобы использовать их в качестве ключиков в хэшмапах. В разных языках они называются по-разному — символами, еще чем-то. Но это можно воспринимать просто как константную строку. Они достаточно эффективны — вы можете писать длинные названия и не тратить на это много ресурсов, потому что они интернятся (т.е. они не повторяются).
Clojure дает сотни функций, позволяющих оперировать этими generic-структурами данных и примитивов. Мы можем складывать, добавлять новые ключики. При этом у нас везде семантика копирования, то есть каждый раз мы получаем новую копию. К этому сначала нужно привыкнуть, поскольку уже не удастся как раньше, где-нибудь в переменной, сохранить что-то, а потом поменять это значение. Ваше вычисление всегда должно быть прямолинейным — все аргументы должны передаваться в функцию явно.
Это приводит к важной вещи. В функциональных языках функция — идеальный компонент, потому что она на вход все получает явно. Никаких скрытых связей, расходящихся по системе. Вы можете взять функцию из одного места, перенести в другое и использовать там.
В Clojure у нас отличные операции equality по значению даже для сложных составных типов:
(= {:a 1} {:a 1}) => true
И эта операция дешевая из-за того, что хитрые иммутабельные структуры можно сравнивать просто по референсу. Поэтому даже hashmap с миллионами ключей мы можем сравнить за одну операцию.
Кстати, ребята из React-а просто скопипастили реализацию Clojure и сделали immutable JS.
Еще в Clojure есть куча операций, например, получить что-то по вложенному пути в hashmap:
Есть сотни операций из базовой библиотеки, которые позволяют оперировать над этими структурами данных. Есть interop с host-ом. К нему нужно немного привыкнуть:
(js/alert "Hello!") => nil
По команде выше у меня в браузер бросилось "Привет".
Я могу получить location от window:
(.-location js/window)
Рич Хикки (Rich Hickey) — создатель Clojure — жестко ограничил нас. У нас действительно больше ничего нет, поэтому мы все делаем через дженерик-структуры данных. Например, когда пишем SQL, мы обычно записываем его структурой данных. Если вы посмотрите внимательно, то увидите, что это просто hashmap, в которой что-то вложено. Потом есть какая-то функция, которая транслирует все это в SQL-строку:
Итак, мы обсудили Clojure. Но ранее я упомянул, что большим достижением в бэкенде была база данных. Если посмотреть на то, что сейчас происходит во фронтенде, мы увидим, что ребята применяют тот же паттерн — вводят базу данных в User Interface (в single page-приложения).
Базы вводятся в elm-архитектуре, в Clojure-скриптовом re-frame и даже в каком-то ограниченном виде во flux и redux (здесь нужно ставить дополнительные плагины, чтобы бросать запросы). Elm-архитектура, re-frame и flux запускались примерно в одно время и заимствовали друг у друга. Мы пишем на re-frame. Далее я немного расскажу, как он работает.
Из view-хи у нас вылетает event (это немного похоже на redux), который ловится неким контроллером. Контроллер мы называем event-handler. Event-handler испускает effect, который тоже является кем-то интерпретируемой data-структуркой.
Один из видов эффекта — это обновить базу данных. То есть он принимает текущее значение базы данных и возвращает новое. Еще у нас есть такая вещь, как subscription — аналог запросов на бэкенде. То есть это некие реактивные запросы, которые мы можем кинуть к этой базе данных. Эти реактивные запросы мы впоследствии бандим на view-шку. В случае react мы как-будто полностью перерисовываем, и если результат этого запроса изменился — это удобно. React присутствует у нас только где-то в самом конце, а в целом архитектура никак не связана с ним. Это выглядит как-то так:
Здесь добавляется то, чего не хватает, например, в redux-ах.
Первое — мы отделяем эффекты. Приложение на фронтенде — не самостоятельное. У него есть некий бэкенд — своего рода, «source of true». Приложение должно постоянно туда что-то писать и что-то оттуда читать. Еще хуже, если у него несколько бэкендов, на которые оно должно ходить. В простейшей реализации можно было бы это сделать прямо в action creater-е — в вашем контроллере, но это плохо. Поэтому ребята из re-frame вводят дополнительный уровень косвенности: из контроллера вылетает некая структура данных, которая говорит, что нужно делать. И у этого сообщения есть свой handler, который делает грязную работу. Это очень важное введение, которое мы еще обсудим чуть позже.
Также важно (про это иногда забывают) — в базе должны лежать некие ground-факты. Все остальное можно вывести из базы — и это обычно делают запросы, они трансформируют данные — не добавляют новую информацию, а правильным образом структурируют существующую. Нам нужен этот query. В redux это по-моему сейчас обеспечивает reselect, а у нас в re-frame это есть из коробки (встроенное).
Посмотрите на схему нашей архитектуры. Мы воспроизвели маленький бэкенд (в стиле Web 2.0) c базой, контроллером, view. Единственное, что добавлено, — реактивщина. Это очень похоже на MVC, за исключением того, что все лежит в одном месте. Когда-то ранние MVC под каждый виджет создавали свою модельку, а здесь все сложено в одну базу. В принципе синхронизироваться с бэкендом можно из контроллера через эффект, можно придумать более дженерико-подобный вид, чтобы база работала, как прокси к бэкенду. Есть даже какой-то дженерик-алгоритм: вы пишите в свою локальную базу, а она синхронизируется с основной. Сейчас в большинстве случаев база — это просто некий объект, в который мы что-то пишем в redux. Но в принципе можно себе представить, что дальше она разовьется в полноценную базу с богатым языком запросов. Возможно, с каким-то дженерик-sync-ом. К примеру, существует datomic — логическая база данных triple-store, которая гонится прямо в браузере. Вы ее поднимаете и складываете туда весь свой state. У datomic достаточно богатый язык запросов, сравнимый по мощности с SQL, а где-то даже выигрывающий. Еще пример — Google написал lovefield. Все будет двигаться куда-то туда.
Далее я объясню, зачем нам нужны реактивные subscription.
Сейчас мы получаем первое наивное восприятие — мы получили юзера с бэкенда, положили в базу и дальше нужно его отрисовать. В момент отрисовки происходит много определенной логики, но мы это смешиваем с рендерингом, с представлением. Если мы сразу возьмемся отрисовывать этого пользователя, у нас получится большой хитрый кусок, который что-то делает с Virtual DOM и еще с чем-то. И он смешан с логической моделью нашей вьюхи.
Очень важный концепт, который нужно понимать: из-за сложности UI его тоже нужно моделировать. Нужно отделить то, как он рисуется (как он представляется), от его логической модели. Тогда логическая модель будет более стабильной. Ее можно не обременять зависимостью от конкретного фреймворка — Angular, React или VueJS. Модель — это обычный first class citizen в вашем рантайме. Идеально, если это просто какие-то данные и набор функций над ними.
То есть из бэкендной модели (предметной) мы можем получить view model, в которой, не используя еще никакого рендеринга, мы можем воссоздать логическую модель. Если там есть какая-то менюшка или что-то подобное — это все можно сделать во view model.
Зачем?
Зачем мы все это делаем?
Хорошие тесты на UI я встречал только там, где есть штат в 10 тестировщиков. Обычно тестирование UI отсутствует. Поэтому мы и пытаемся вытолкнуть эту логику из компонентов во view model. Отсутствие тестов — очень плохой знак, свидетельствующий о том, что там что-то не так, как-то плохо все структурировано.
Почему UI сложно тестировать? Почему ребята на бэкенде научились тестировать свой код, обеспечили огромный coverage и это действительно очень помогает жить с бэкенд-кодом? Почему на UI не так? Скорее всего, мы что-то делаем не так. И все, что я описал выше, на самом деле двигало нас в направлении testability.
Как мы делаем тесты?
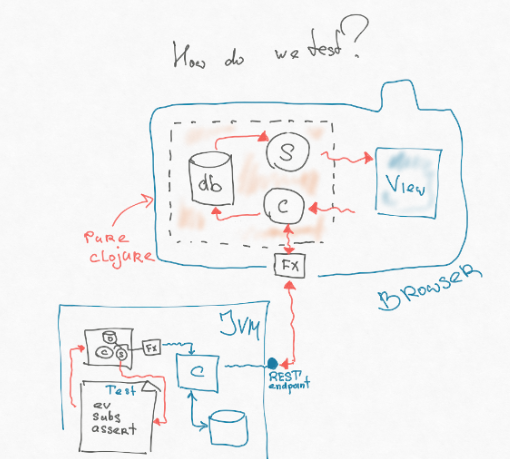
Если присмотреться, часть нашей архитектуры, содержащая controller, subscription и базу данных, никак не связана даже с JS. То есть это какая-то модель, которая оперирует просто структурами данных: мы их куда-то складываем, как-то трансформируем, вынимаем query. Через эффекты у нас оторвано взаимодействие с внешним миром. И этот кусок полностью переносим. Его можно писать на так называемом cljc — это общий subset между Clojure Script и Clojure, который ведет себя одинаково и там, и там. Мы можем просто вырезать этот кусок с фронтенда и поместить в JVM — туда, где живет бэкенд. Потом мы можем написать другой эффект в JVM, который напрямую бьет в end-point — дергает роутер без всяких преобразований http-шной строки, разбора и т.д.
В итоге мы можем написать очень простой тест — такой же функциональный интегральный тест, который ребята пишут на бэкенде. Мы кидаем некий эвент, он кидает эффект, который напрямую бьет в endpoint на бэкенде. Тот нам что-то возвращает, кладет в базу, вычисляется subscription, а в subscription лежит логическое view (мы по-максимуму положили туда логику user interface). Мы этот view ассертим.
Таким образом мы можем протестировать на бэкенде 80% кода, при этом нам доступны все инструменты бэкенд-разработки. Мы можем воссоздать при помощи фикстур или каких-нибудь фабрик определенную ситуацию в базе данных.
Например, у нас пришел новый пациент или что-то не оплачено и т.д. Мы можем перебрать кучу возможных комбинаций.
Таким образом мы можем побороться со второй проблемой — с distributed-системой. Потому что контракт между системами как раз и является основным больным местом, ведь это два разных рантайма, две разные системы: бэкенд что-то поменял, и у нас на фронтенде что-то сломалось (нельзя быть уверенным, что такого не произойдет).
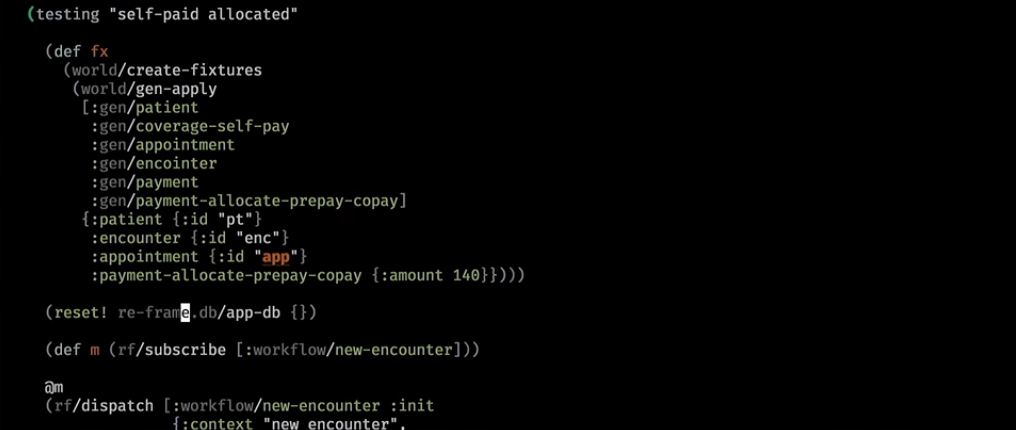
Демонстрация
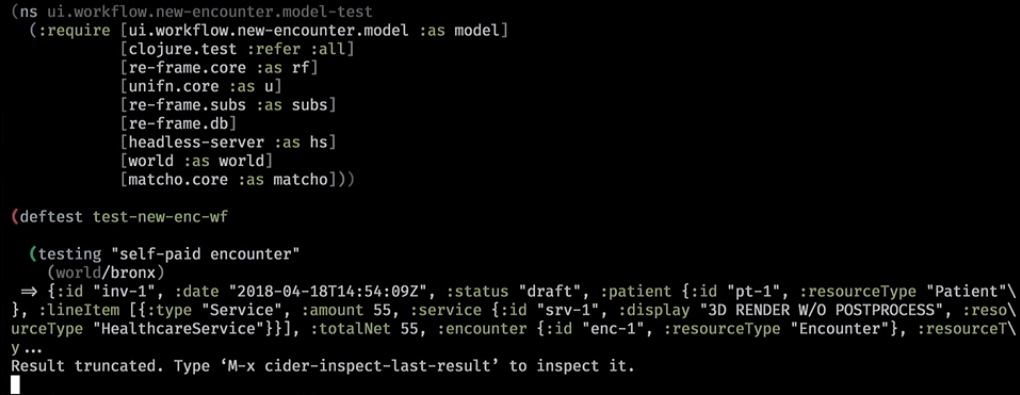
Вот как это выглядит на практике. Это бэкендовский хэлпер, который очистил базу и записал в нее некий мирок:
Дальше мы кидаем subscription:
Обычно URL полностью определяет страницу и кидается некий event — ты сейчас на такой-то странице с набором параметров. Здесь мы зашли в новый workflow и наш subscription вернулся:
За сценой он сходил в базу, что-то достал, положил в нашу UI-базу. Subscription на ней отработал и вывел из нее логическую View model.
Мы ее инициализировали. И вот наша логическая модель:
Даже не глядя на User interface, мы можем догадаться, что будет нарисовано по этой модели: придут какие-то warning-и, будет лежать какая-то информация о пациенте, encounter-ы и набор ссылочек (это workflow-виджет, который ведет фронтдеск по определенным шагам, когда приходит пациент).
Здесь мы придумали более сложный мир. Сделали какие-то оплаты и тоже протестировали после инициализации:
Если он уже оплатил визит, у него это будет видно в user interface:
Прогоняем тесты, выставляем на CI. Sync между бэкендом и фронтендом будет уже гарантирован тестами, а не честным словом.
Снова в бэкенд?
Мы ввели тесты полгода назад, и нам очень понравилось. Остается проблема размазанной логики. Чем умнее ведет себя бизнес-приложение, тем больше ему нужно информации для каких-то шагов. Если попытаться запустить туда какие-то workflow из реального мира, появятся зависимости от всего: на каждый чих user interface нужно что-то достать из разных уголков базы на бэкенде. Если мы пишем учетные системы, этого не избежать. В итоге, как я говорил, вся логика размазана.
При помощи таких тестов мы можем создать иллюзию по крайней мере в dev-time — в момент разработки — что мы, как в старые времена web 2.0, сидим на сервере в одном рантайме и все комфортно.
Возникла другая сумасшедшая идея (она еще не реализована). Почему бы вообще не опустить эту часть на бэкенд? Почему бы сейчас не уй