Magic Tester. Как неподготовленный человек замечает ошибки, и как научить тому же робота
Привет! Меня зовут Илья Кацев, и я представляю небольшое исследовательское подразделение в отделе тестирования в Яндексе. Вы уже могли читать о нашем экспериментальном проекте Роботестер — роботе, который умеет проделывать за тестировщика заметную часть рутинной работы.Наша основная цель — изобрести принципиально новые подходы для нахождения ошибок в Яндексе. Я очень люблю порассуждать на тему того, какая часть работы в будущем ляжет на плечи роботов. Они уже отлично пишут спортивные репортажи и переносят грузы для солдат. И вообще мне кажется, что человеческий прогресс непосредственно зависит от того объема работы, который мы сможем передать роботам — у людей в этом случае появляется свободное время и они придумывают новые крутые штуки.
Есть такой тезис, сторонником которого я лично являюсь, — любую ошибку, которую может заметить неподготовленный пользователь, может обнаружить и робот. Именно это мы и попытались проверить. Но тут возникает вопрос: что именно человек считает ошибкой?
Искусственный интеллект пока никто не изобрёл (хотя Хокинг, например, считает, что это к лучшему), но кое-каких успехов нам удалось добиться. В этом посте я расскажу о том, как мы формулировали опыт, которым обладают тестировщики-люди и постарались научить ему наших роботов, и что из этого вышло.
Роботестер. Первый подход Когда мы создавали Роботестера, перед нами стояла задача автоматизировать рутинную работу, на которую уходит время тестировщика. Мы научили алгоритм открывать веб-страницу, понимать, какие действия можно произвести с элементами, заполнять текстовые поля, нажимать кнопки и пытаться угадать, когда же произошла ошибка. Но у нас возникла проблема — оказалось, что с высокой достоверностью робот может обнаружить только самые тривиальные ошибки.Дело в том, что принцип работы робота — проверять как можно больше страниц — приводил к большому числу тестов, а это означало, что точность определения ошибки становилась ключевым фактором. Мы подсчитали, что для проверки Яндекс.Маркета наш робот делал 800 000 различных проверок в сутки. Соответственно, если false positive rate проверок в среднем равен 0.001 (что кажется небольшим числом), то каждый день будет приходить отчет о якобы найденных 800 ошибках, которых на самом деле нет. Естественно, это никого не устраивает.
Следует отметить, что «фальшивые» сообщения об ошибках всегда случаются. Особенно, когда речь идет о веб-тестах, так как для них используется вспомогательные инструменты — могут быть проблемы с браузером, который использует робот, проблемы с интернетом, и так далее.
Есть весьма «чистые» проверки. Например, код ответа ссылки 404 с огромной вероятностью свидетельствует о том, что проблема есть. Пример проверки с низкой точностью — наличие в тексте буквосочетания » ,» (пробел и запятая). Действительно, когда между пробелом и запятой не подгрузились какие-то данные, такое буквосочетание свидетельствует об ошибках. Но иногда речь идет просто об опечатках. Особенно когда в область проверки попадает текст пользовательских комментариев или контенет из внешних источников. Поэтому для нахождения этих ошибок приходится проводить работу вручную, отделяя «настоящие» проблемы от «фальшивых».
В итоге, робот действительно полностью брал на себя часть работы тестировщиков (например, находил все битые ссылки), но совсем не всю. И мы задумались о том, как «добавить роботу интеллекта».
Как робот догадается об ошибке? Традиционно в тестировании запускают тестируемую программу с какими-то заданными входными данными и сравнивают результаты с каким-то также наперед заданным «правильным» результатом. Он может быть задан вручную, или, скажем, сохраняться при запуске предыдущей версии программы (тогда мы сможем найти все различия между данной версией и предыдущей), но общий принцип все равно остается таким. По сути подход в целом здесь не меняется десятки лет, меняются только инструменты для реализации этих тестов.Однако оказывается, что возможны принципиально иные подходы для определения того, что является ошибкой.Мы изначально говорили о том, что робот должен научиться определять ошибки, которые может любой человек, необязательно профессиональный тестировщик данного сервиса.
Итак, где ошибка на этой странице?

Конечно, правильный ответ — среди пяти предложений снизу есть повторяющиеся. Чтобы понять, что это ошибка, не надо быть экспертом в Маркете — надо просто обладать минимальным здравым смыслом.
Другой пример.
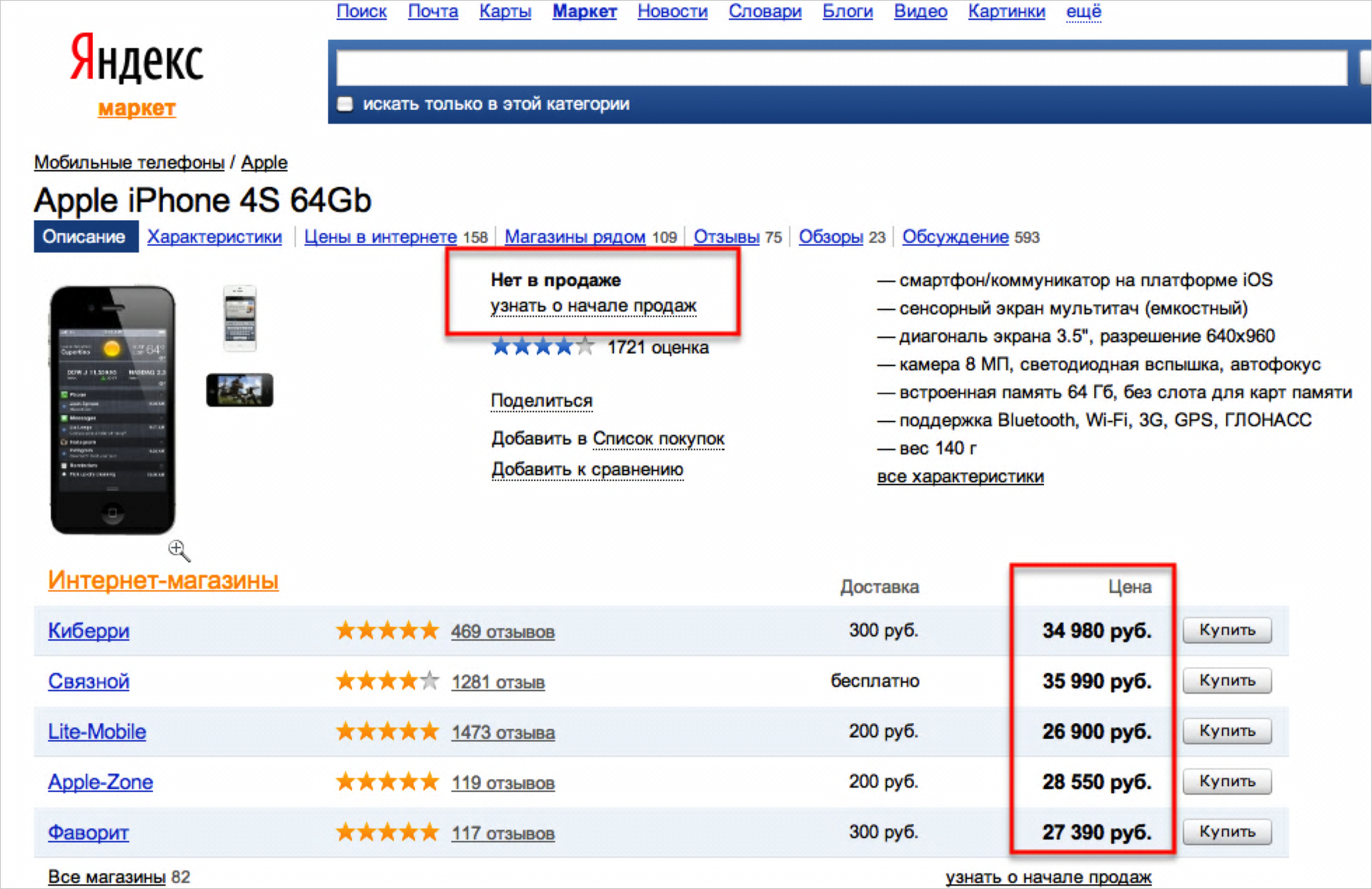
Здесь в одном месте написано «нет в продаже», а в другом — указаны цены. Опять же абсолютно любой человек понимает, что это некорректная ситуация.
Еще один пример.

Это просто чистая страница. То есть у нее есть стандартные «шапка» и «футер», но нет никакого контента в середине.
Здесь и возникает ключевой вопрос — как человек понимает, что это ошибка? На каком механизме это основано?
Мы долго думали, и кажется, что ключевое слово здесь — опыт. То есть человек уже видел в своей жизни много веб-страниц, причем некоторые были ровно такого же типа. И именно из них у него сформировался некоторый шаблон. Этот шаблон может быть как очень общим («страница не должна быть пустой», «все результаты поиска должны быть различны»), или, наоборот, привязанным к данным страницам («два выделенных блока содержат или не содержат цифры одновременно»). То есть у него в голове уже сформировались эти правила и, как мы видим по данным примерам, они выглядят совсем несложными.
Таким образом, дальнейшая задача тут стала ясна — надо научиться автоматически извлекать эти правила, анализируя множество схожих или не очень схожих веб-страниц.
Видно, что сформулированные правила довольно просты, и, если бы мы научились их автоматически извлекать, то можно было бы формировать автотесты без участия человека. Например, роботу дается для анализа много страниц сервисов Яндекса, и он понимает, что на них на всех снизу есть ссылка «О компании». Соответственно этот факт формулируется как правило, и робот будет проверять его выполнение для новой версии сервиса или даже для другого сервиса.
Самое просто применение этой идеи такое: анализируем все страницы сервиса в продакшн, вычленяем такие «правила», а затем проверяем, выполняются ли они для новой версии того же сервиса.
Этот подход давным-давно всем известен. Он называется back-to-back тестирование и есть те, кто его использует. Однако такой метод хорошо применим лишь тогда, когда работа сервиса не должна заметно меняться от версии.
Давайте рассмотрим поисковую выдачу вчера и сегодня — результаты поиска и реклама рядом меняются. Онии зависят от региона пользователя, его предпочтений, времени суток, наконец. Соответственно, при непосредственном сравнении будет слишком много «мусора» (отметим, что в некоторых ситуациях и такой непосредственный метод допустим).
Здесь же мы развиваем нашу идею и осуществляем сравнение, «очищенное» от мусора, — мы сравниваем не сами страницы, а некоторые «модели» страниц.
Блоки Сформулировав общую идею, перейдем к тому, как же ее реализовывать. Наша задача — автоматически извлекать правила. Для понимания человеком они очень простые. Мы их формулируем на языке «блоков» — мы говорим о том, содержит определенная часть страницы какой-то элемент или нет, присутствует ли на странице определенный блок, и так далее. Для человека страница делится на них естественным образом — вот форма авторизации, вот поисковая форма (и в ней подблоки — строка поиска, кнопка «найти»). Однако робот «видит» перед собой html-код, и ему совершенно непонятно, какая часть этого кода образует блок.Мы решили четко сформулировать понятие блока. То есть сначала мы решили понять для себя, что же мы, люди, называем блоком. Давайте посмотрим, какие бывают блоки.
1. Постоянные. Весь блок целиком присутствует на каждой странице).
2. Меняющиеся. Какой-то тэг присутствует на каждой странице, но внутри него каждый раз все меняется.
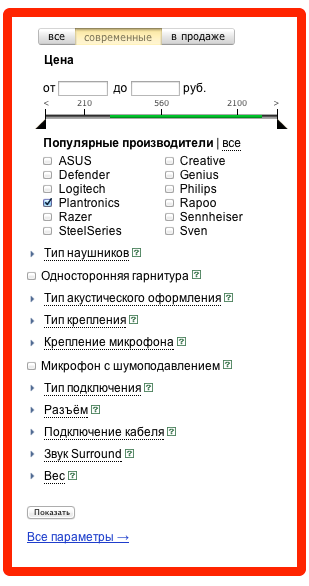
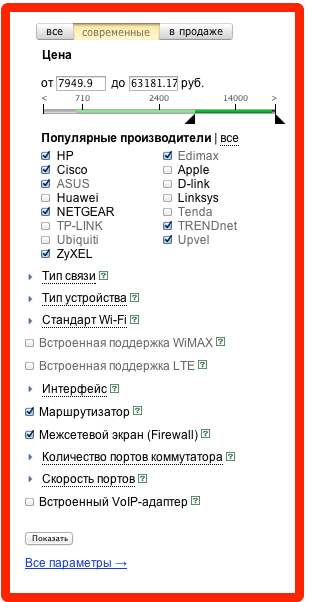
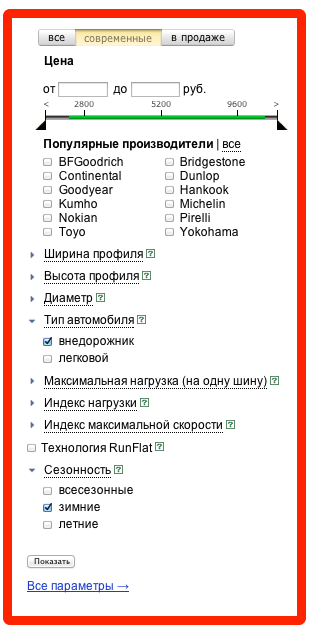
3. Однотипные блоки на одной странице.
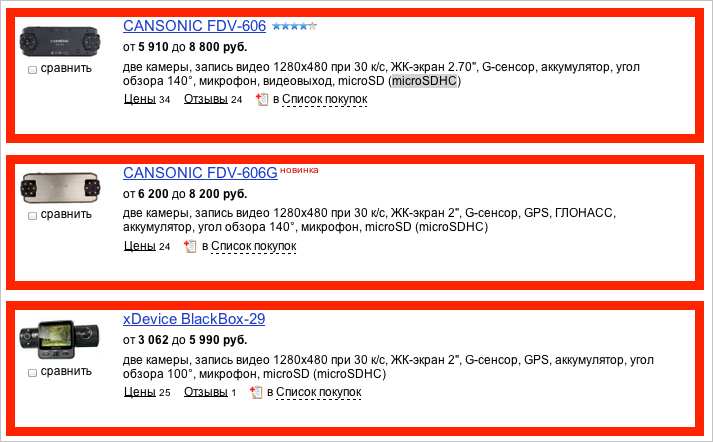
4. Однотипные, но разные по сути блоки на одной странице.

При этом на разных страницах один и тот же блок может стоять на разных местах.



То есть для нас «блок» — это некая часть страницы, которая при её изменении остается более-менее постоянной. Например, человек легко понимает, что формы из пункта 2 (см. выше) — это частные случаи «одной и той же оранжевой формы», но при этом содержание формы меняется.
Отдельную проблему представляют собой несколько схожих блоков, идущих подряд. Иногда это именно «несколько однотипных блоков», а иногда — набор объектов разных типов, и тогда хочется понять, какого типа объекты вообще там встречаются.
В первую очередь нам нужен какой-то способ помечать уже выделенный блок на каждой странице. Традиционный xpath (например, /html/body/div[1]/table[2]/tbody/tr/td[2]/div[2]/ul/li[3]/span/a) плохо подходит потому, что числа в нем могут меняться — один и тот же блок может быть третьим или пятым по счету. В зависимости от того, какие еще блоки есть (см. последние два примера).
Поэтому мы сначала убираем числа из xpath’а (получая /html/body/div/table/tbody/tr/td/div/ul/li/span/a вместо /html/body/div[1]/table[2]/tbody/tr/td[2]/div[2]/ul/li[3]/span/a) и получаем намного более стабильный вариант соответствия (то есть данный блок будет подпадать под xpath на любой странице), однако менее точный — то есть одному и тому же xpath’у теперь, конечно, может соответствовать несколько элементов. Для уменьшения этой неточности мы в описание каждого tag’а добавляем значения некоторых его атрибутов. Атрибуты мы просто руками разделили на более и менее стабильные. Например, атрибут id часто генерится заново при загрузке страницы, то есть он для нас совершенно неинформативен. Например, для блока, рассмотренного сверху, получилось такое описание: другой ipath
|
|