Лучшие DevOps практики для разработчиков. Антон Бойко (2017г.)

В докладе будет рассказано о некоторых DevOps практиках, но с точки зрения разработчика. Обычно все инженеры, которые приходят в DevOps, уже имеют за плечами несколько лет опыта администрирования. Но это не означает что разработчику тут нет места. Чаще всего разработчики заняты тем, что исправляют «очередной срочно-критичный баг дня», и у них нет времени даже одним глазком взглянуть на DevOps сферу. В понимании автора DevOps — это, во-первых, здравый смысл. Во-вторых — это возможность быть более эффективным. Если вы разработчик, обладаете здравым смыслом и хотите быть более эффективным как командный игрок — доклад для вас.
Представлюсь, я вполне допускаю, что в зале есть люди, которые меня не знают. Зовут меня Антон Бойко, я являюсь Microsoft Azure MVP. Что такое MVP? Это Model-View-Presenter. Model-View-Presenter — это именно я.
Кроме того, я сейчас занимаю должность solution architect в компании Ciklum. И буквально недавно купил себе вот такой красивый домен, и у меня обновился мой email, который я обычно показываю на презентациях. Можете писать мне на: me [собака] byokoant.pro. Мне на почту можно писать вопросы. Я обычно на них отвечаю. Единственное, я не хотел бы получать вопросы на почту, которые относятся к двум темам: это политика и религия. Обо всем остальном можете писать мне на почту. Пройдет какое-то время, я отвечу.

Пару слов о себе:
- Уже 10 лет я в этой сфере.
- Я работал в Microsoft.
- Я отец-основатель украинского Azure-сообщества, которое мы основали где-то в 2014-ом году. И до сих пор оно у нас есть и развивается.
- Я также отец основатель Azure-конференции, которая у нас проходит в Украине.
- Также я помогаю организовать Global Azure Bootcamp в Киеве.
- Как я уже сказал, я — Microsoft Azure MVP.
- Я довольно часто выступаю на конференциях. Я очень люблю выступать на конференциях. За прошлый год у меня получилось выступить около 40 раз. Если будете пробегать мимо Украины, Белоруссии, Польши, Болгарии, Швеции, Дании, Нидерландов, Испании или плюс-минус другой страны в Европе, то вполне возможно, что, заходя на конференцию, которая имеет тему облаков у себя в потоке, вы можете увидеть меня в списке докладчиков.
- А еще я фанат Star Trek.

Давайте немножко поговорим про Agenda. Agenda у нас очень простая:
- Мы поговорим, что такое DevOps. Поговорим, почему это важно. Раньше DevOps — это было ключевое слово, которое вы писали в резюме и получали сразу +500 долларов к зарплате. Сейчас нужно писать, например, blockchain в резюме, чтобы получить +500 долларов к зарплате.
- А потом, когда мы немножко разберемся, что из себя это представляет, мы поговорим о том, какие есть DevOps-практики. Но не столько в контексте DevOps в целом, а о тех DevOps-практиках, которые могли бы быть интересны разработчикам. Я расскажу, почему они могли бы быть вам интересны. Расскажу, зачем вообще это делать и как это может вам помочь испытывать меньше боли.

Традиционная картинка, которые показывают многие. Это то, что происходит во многих проектах. Это когда у нас есть отделы разработки и operations, которые поддерживают наш софт. И эти отделы между собой не общаются.
Возможно, если вы не настолько ярко смогли прочувствовать именно на отделах DevOps и operations, вы можете провести аналогию с отделами Dev и QA. Есть люди, которые разрабатывают софт и есть QA, которые плохие с точки зрения разработчиков. Например, я коммичу в репозиторий свой прекрасный код, а там сидит какой-то негодяй, который мне этот код возвращает и говорит, что ваш код плохой.
Это все происходит по той причине, что люди между собой не общаются. И они через какую-то стену недопонимания перекидывают друг другу какие-то пакеты, какое-то приложение и пытаются что-то с ними с делать.
Как раз разрушить эту стену и призвана DevOps-культура, т.е. заставить людей между собой общаться и хотя бы понимать, чем вообще занимаются разные люди в проекте и почему их работа важна.

И когда мы говорим про DevOps, то кто-то вам скажет, что DevOps — это когда в проекте есть continuous integration; кто-то скажет, что DevOps — это если в проекте реализована практика «инфраструктура как код»; кто-то скажет, что первый шаг к DevOps — это feature branching, feature flags.
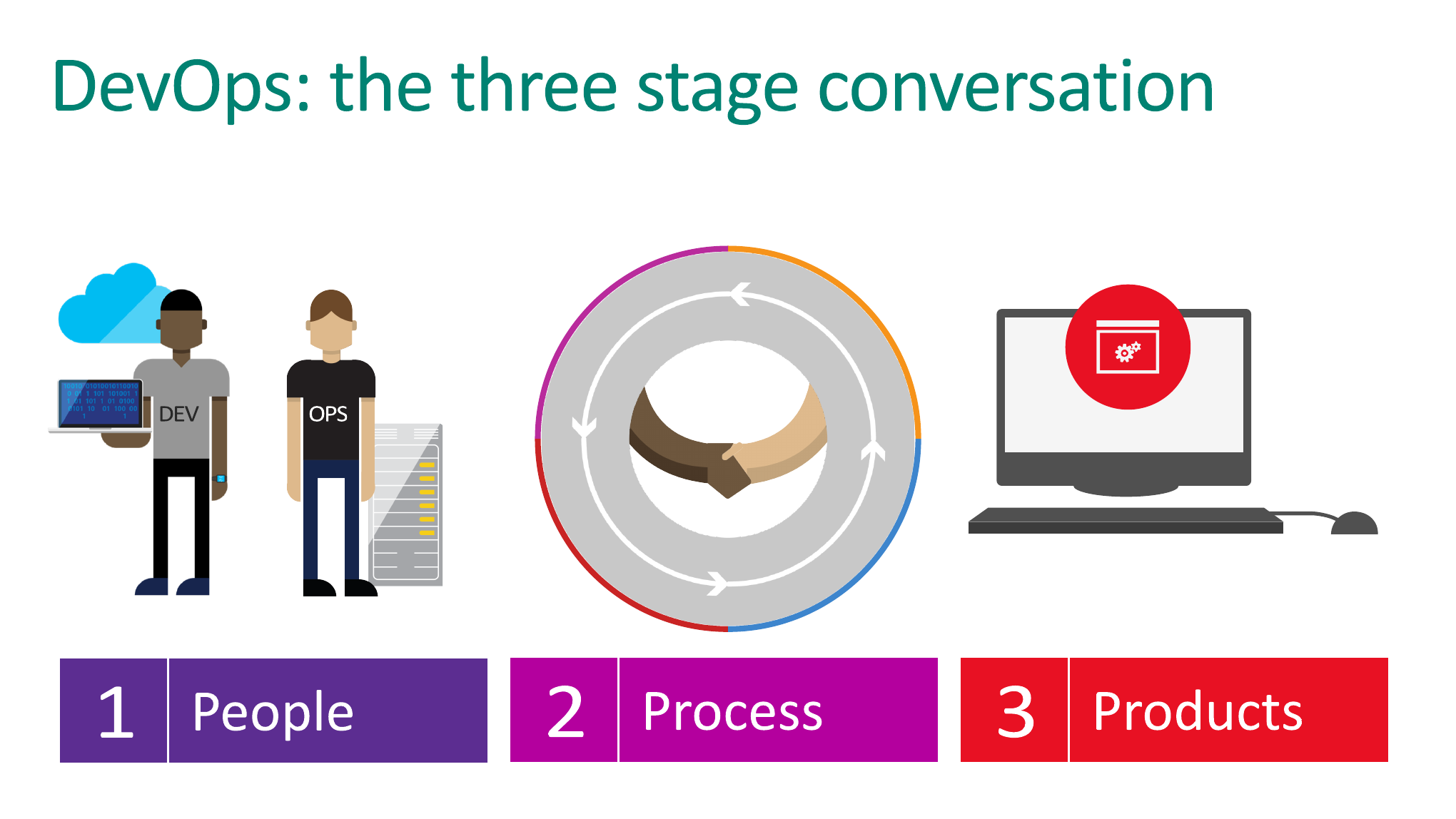
По сути, это все по-своему правда. Но это всего лишь конечные практики, которые у нас есть. Перед тем, как переходить к этим практикам, я предлагаю посмотреть на этот слайд, который показывает 3 этапа внедрения Dev-Ops методологии в вашем проекте, в вашей компании.
Этот слайд носит еще второе неофициальное название. Вы можете поискать в интернете, что такое 3 мушкетера DevOps. Вполне возможно, вы найдете эту статью. Почему 3 мушкетера? Внизу написано: люди, процессы и продукты, т.е. PPP — Портос, Портос и Портос. Вот вам 3 мушкетера DevOps. В этой статье описывается более развернуто, почему это важно и что это под собой несет.
Когда вы начинаете внедрять DevOps-культуру, очень важно, чтобы она внедрялась в следующем порядке.
Первоначально вам нужно говорить с людьми. И вам нужно объяснить людям, что это такое и как они смогут получить от этого какие-то преимущества.
Конференция у нас называется DotNet Fest. И как мне сказали организаторы, что сюда у нас в основном была приглашена аудитория разработчиков, поэтому я надаюсь, что большинство людей в зале занимаются разработкой.
Мы поговорим про людей, поговорим о том, что разработчики хотят делать каждый день. Чего они хотят больше всего? Они хотят писать какой-то новый код, использовать новомодные фреймворки, пилить новые фичи. Чего разработчики хотят меньше всего? Фиксить старые баги. Я надеюсь, вы со мной согласитесь. Это то, что хотят разработчики. Они хотят писать новые фичи, они не хотят фиксить баги.
Количество багов, которые производит тот или иной разработчик, зависит от того, насколько у него прямые руки и насколько они растут из плеч, а не из карманов на попе. Но тем не менее, когда проект у нас большой, иногда бывает так, что за всем уследить невозможно, поэтому нам было бы неплохо использовать какие-то подходы, которые помогут писать более стабильный и более качественный код.
Что больше всего хочется QA? Не знаю, есть ли они в зале. Мне тяжело говорить, что хочется QA, потому что я никогда им не был. И не в обиду ребятам будет сказано, что никогда, надеюсь, не буду. Но не по той причине, что считаю их работу бессмысленной и бесполезной, а потому что я не считаю себя человеком, который смог бы эту работу выполнять качественно, поэтому я даже не буду пытаться это делать. Но из того, что я понимаю, QA больше всего не нравится выходить утром на работу, гонять постоянно какие-то regression tests, наступать на те же самые баги, которые они зарепортили разработчикам 3 спринта назад и говорить: «Когда же вы, месье Д«Артаньян, пофиксите этот баг». А месье Д«Артаньян ему отвечает: «Да-да-да, я уже его пофиксил». И как это бывает, что один баг пофиксил, 5 по дороге сделал.
Люди, которые занимаются поддержкой этого решения на production, хотят, чтобы это решение работало без багов, чтобы им не приходилось переподнимать сервер каждую пятницу, когда все нормальные люди идут в бар. Разработчики в пятницу задеплоились, админы сидят до субботы, пытаясь этот деплой поднять, починить.
И когда вы объясните людям, что они нацелены на решение одних и тех же задач, вы можете переходить к формализации процессов. Это очень важно. Почему? Потому что, когда мы говорим «формализация», то вам важно описать, как ваши процессы происходят хотя бы где-то на салфетке. Вам нужно понять, что если вы, например, делаете деплой на QA-окружение или на production-окружение, то это всегда происходит вот в таком порядке, вот на таких этапах мы запускаем, допустим, автоматические unit-тесты, UI-тесты. После деплоя проверяем, насколько деплой прошел хорошо или плохо. Но у вас уже есть четкий список действий, которые должны повторяться раз за разом, когда вы делаете деплой на production.
И только когда у вас процессы формализованы, вы приступаете к выбору продуктов, которые помогут вам вот эти процессы автоматизировать.
К сожалению, я очень часто вижу, что это происходит в обратном порядке. Как только кто-то слышит слово «DevOps», сразу предлагает поставить Jenkins, потому что считает, что как только они поставят Jenkins, у них будет DevOps. Они поставили Jenkins, почитали статьи «How to» на сайте Jenkins, попытались процессы запихнуть в эти How to статьи, а потом пришли к людям и нагнули людей, сказав, что книжка говорит, что нужно делать вот так, поэтому делаем вот так.
Не то, что бы Jenkins плохой инструмент. Я ни в коем случае не хочу это сказать. Но это всего лишь один из продуктов. И то, какой продукт вы будете использовать, должно быть ваше последнее решение, а ни в коем случае не первое. У вас продукт не должен драйвить внедрение именно культуры и подходов. Это очень важно понять, именно поэтому я так долго кручусь на этом слайде и так долго все это объясняю.

Давайте поговорим про DevOps-практики в целом. Какие они есть? Чем они отличаются? Как их померить? Почему они важны?
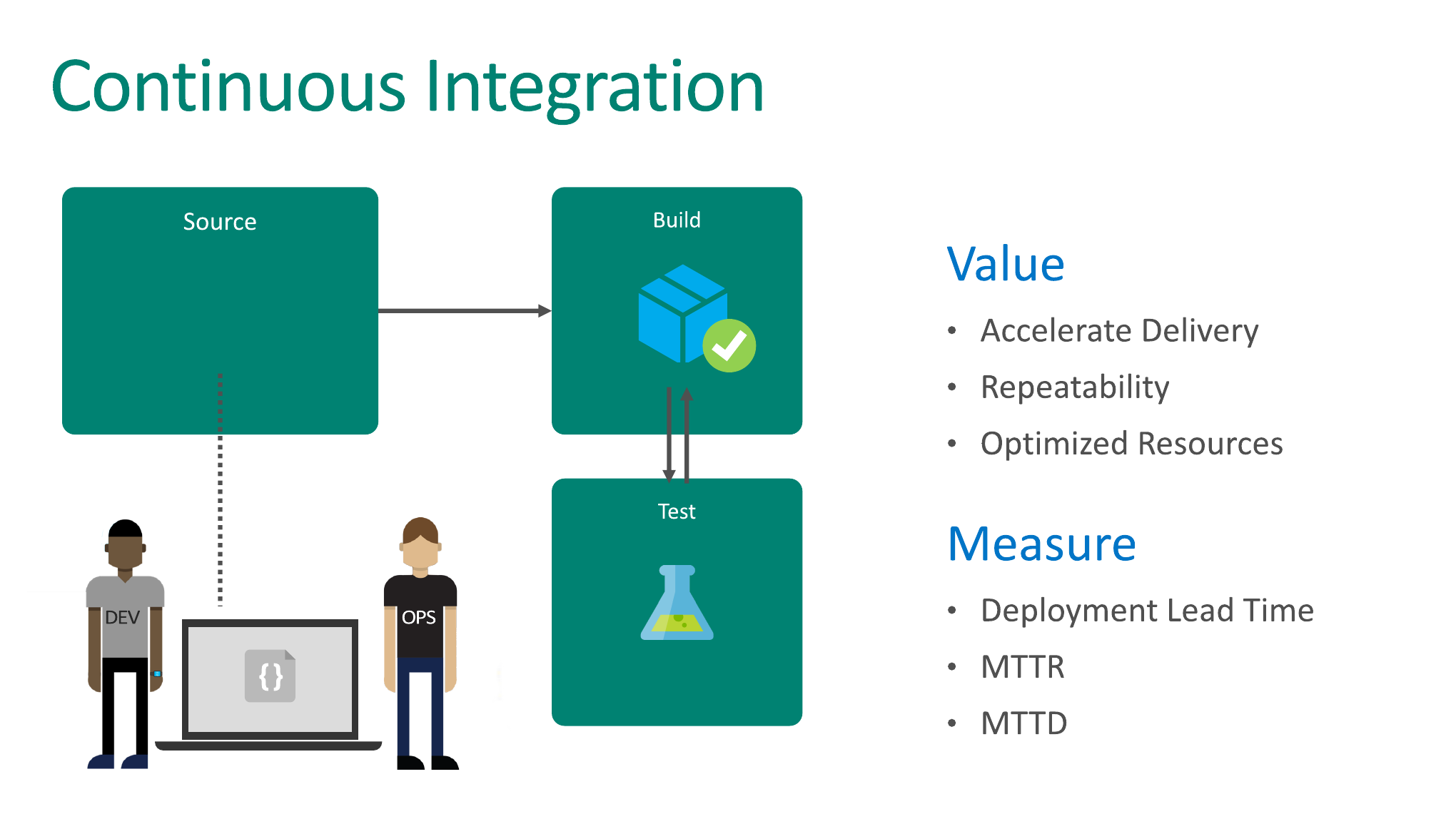
Первая практика, о которой вы могли слышать, называется Continuous Integration. Возможно, у кого-то на проекте есть Continuous Integration (CI).
Самая большая проблема в том, что чаще всего, когда я спрашиваю у человека: «Есть ли у вас CI на проекте?» и он говорит: «Да», то, когда я спрашиваю, что он делает, он мне описывает абсолютно весь процесс автоматизации. Это не совсем так.
На самом деле практика CI всего лишь направлена на то, что код, который пишут разные люди, интегрируется в какую-то единую базу кода. Вот и все.
Вместе с CI по дороге идут обычно еще разные практики — такие, как Continuous Deployment, Release Management, но об этом мы поговорим потом.
Сам CI нам говорит, что разные люди пишут код и этот код должен интегрироваться непрерывно в единую базу кода.
Что это нам дает и почему это важно? Если у нас DotNet, то это хорошо, это компилируемый язык, мы можем скомпилировать наше приложение. Если оно компилируется, то это уже хороший знак. Это еще ничего не означает, но это уже первый хороший знак, что мы хотя бы можем скомпилироваться.
Потом мы можем запустить какие-то тесты, что тоже является отдельной практикой. Тесты все зеленые — это уже второй хороший знак. Но опять же это еще ничего не означает.
Но, зачем вам это делать? Все практики, о которых я буду рассказывать сегодня, под собой несут примерно одинаковый value, т. е. примерно одинаковые преимущества и меряются тоже примерно одинаково.
Первое — это позволяет вам ускорить доставку. За счет чего это позволяет вам ускорить доставку? Когда у нас заходят какие-то новые изменения в нашу кодовую базу, мы можем сразу же попытаться с этим кодом что-то сделать. Мы не ждем пока у нас придет четверг, потому что в четверг мы релизим это на QA Environment, мы делаем это прямо тут и прямо здесь.
Я расскажу вам одну печальную историю из моей жизни. Это было давным-давно, когда я еще был молодым и красивым. Сейчас я уже молодой, красивый и умный, и скромный. Какое-то время назад я был в одном проекте. У нас была большая команда из порядка 30 разработчиков. И у нас был большой-большой Энтерпрайз-проект, который развивался порядка 10 лет. И у нас были разные ветки. В репозитории у нас была ветка, в которой гуляли разработчики. И была ветка, которая отображала версию кода, который есть на production.
Ветка production от ветки, которая была доступна для разработчиков, отставала на 3 месяца. Что это означает? Это означает, что как только у меня где-то какой-то баг ушел на production по вине разработчиков, потому что они его допустили, и по вине QA, потому что они его просмотрели, то это означает, что если мне прилетает задача на hotfix для production’а, то я должен откатить свои кодовые изменения на 3 месяца назад. Я должен вспомнить, что у меня было 3 месяца назад и попытаться это там пофиксить.
Если у вас не было еще такого опыта, то можете попробовать это сделать на вашем домашнем проекте. Главное, не пробуйте на коммерческом. Напишите пару строчек кода, забудьте о них на полгода, а потом вернитесь и попытайтесь быстро объяснить, о чем эти строчки кода и как можно их исправить или оптимизировать. Это очень-очень увлекательный опыт.
Если у нас есть практика Непрерывной интеграции, то это позволяет нам прямо здесь и прямо сейчас, как только я написал свой код, проверить его рядом автоматических инструментов. Пусть это не даст мне полную картину, но тем не менее, это уберет хотя бы часть рисков. И если там будет какая-то потенциальная бага, я об этом узнаю прямо сейчас, т. е. буквально через пару минут. Мне не нужно будет откатываться на 3 месяца назад. Мне нужно будет откатиться всего на 2 минуты назад. За 2 минуты хорошая кофемашина даже кофе не успеет сварить, поэтому это довольно классно.
Это несет в себе ценность, что это можно повторять из раза в раз на каждом проекте, т.е. не только на одном, на котором вы это настроили. Можно повторять как саму практику, так и сам CI будет повторяться на каждое новое изменение, которое вы вносите в проект. Это позволяет вам оптимизировать ресурсы, потому что ваша команда работает более эффективно. У вас уже не будет ситуации, когда к вам прилетает баг из кода, с которым вы работали 3 месяца назад. У вас уже не будет переключения контекста, когда вы сидите и первые два часа пытаетесь понять, что же было тогда и въехать в суть контекста перед тем, как начнете что-то исправлять.
Как можно померить успех или неуспех этой практики? Если отраппортовать большому боссу, что мы внедрили на проекте CI, то он слышит бла-бла-бла. Внедрили, Ок, а зачем, что это нам принесло, как мы это померим, насколько мы правильно или неправильно внедряем?
Первое, это то, что за счет CI мы можем делать деплой чаще и чаще, и чаще именно по той причине, что у нас потенциально это более стабильный код. Точно так же у нас уменьшается время на поиск ошибки и уменьшается время на исправление этой ошибки именно по той причине, что мы получаем ответ от системы прямо здесь и прямо сейчас, что с нашим кодом не так.

Другая практика, которая у нас есть, это практика Автоматического тестирования, которая чаще всего идет с практикой CI. Они идут рука об руку.
Что здесь важно понимать? Важно понимать, что тесты у нас бывают разные. И каждые автоматические тесты нацелены на решение своих задач. У нас есть, допустим, unit-тесты, которые позволяют нам протестировать отдельно какой-то модуль, т.е. как он работает в вакууме. Это хорошо.
Также у нас есть интеграционные тесты, которые позволяют нам понять, как разные модули интегрируются между собой. Это тоже хорошо.
У нас могут быть UI automation тесты, которые позволяют нам проверить, насколько работа с UI соответствует тем или иным требованиям, которые выставил заказчик и т.д.
Оттого, какие именно тесты вы запускаете, это может влиять на периодичность их запуска. Unit-тесты обычно у нас пишутся короткими, небольшими. И их можно запускать регулярно.
Если мы говорим про UI automation тесты, то хорошо, если у вас проект маленький. У вас UI automation тесты могут проходить за какое-то адекватное время. Но обычно UI automation тест — это вещь, которая идет на большом проекте несколько часов. И это хорошо, если несколько часов. Единственное, на каждый build запускать их смысла нет. Есть смысл их запускать ночью. И когда утром все пришли на работу: и тестировщики, и разработчики, то они получили какой-то отчет, что мы ночью погоняли автотестом UI и вот такие результаты получили. И здесь час работы сервера, который будет проверять на то, что ваш продукт соответствует каким-то требованиям, будет намного дешевле, чем час работы того же QA-инженера, даже если это Junior QA-инженер, который работает за еду и за спасибо. Все равно час работы машины будет дешевле. Именно поэтому имеет смысл в это инвестировать.
У меня есть еще один проект, на котором я работал. У нас были двухнедельные спринты на этом проекте. Проект был большой, важный для финансового сектора и ошибку допустить было нельзя. И по двухнедельному спринту, по циклу разработке дальше шел процесс тестирования, который занимал еще 4 недели. Попытайтесь представить себе масштаб трагедии. Две недели мы пишем код, потом мы делаем аля CodeFreeze, пакуем это в новую версию приложения, выкатываем тестировщикам. Тестировщики еще 4 недели его тестируют, т.е. пока они его тестируют, мы успеваем еще две версии им подготовить. Это реально печальный случай.
И мы им сказали, что если вы хотите работать более продуктивнее, вам имеет смысл внедрять практику Автоматического тестирования, потому что это то, что у вас болит прямо здесь и прямо сейчас.
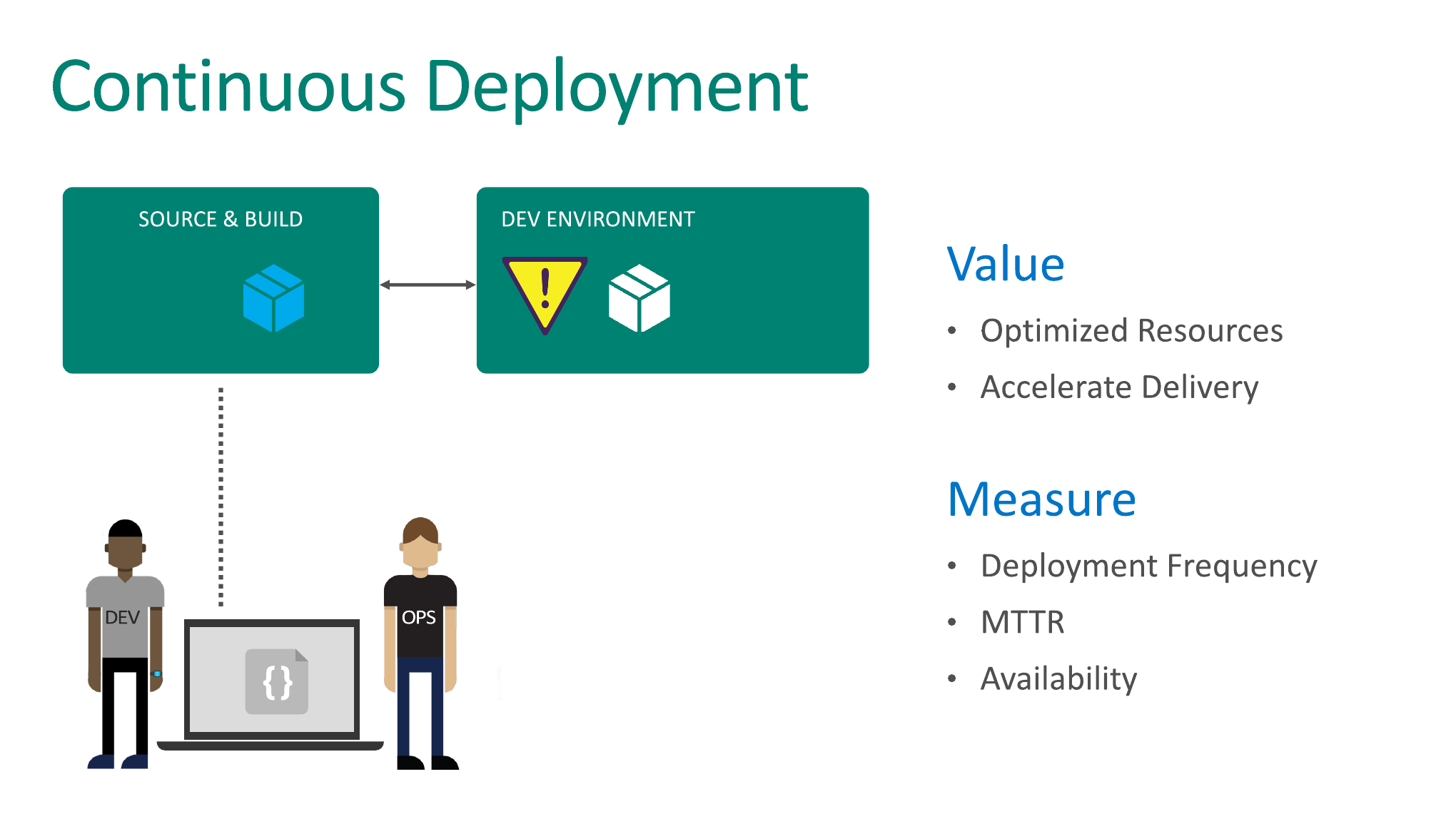
Практика Непрерывного развертывания. Отлично, вы сделали build. Это уже хорошо. У вас код скомпилировался. Теперь было бы неплохо этот build развернуть на каком-то окружении. Допустим, на окружении для разработчиков.
Почему это важно? Во-первых, вы можете посмотреть, насколько успешно у вас происходит сам процесс развертывания. Я встречал такие проекты, когда я спрашиваю: «Как вы разворачиваете новую версию приложения?», мне ребята говорят: «Мы его собираем и пакуем в zip-архив. Отправляем админу по почте. Админ этот архив качает, разворачивает. И вся контора начинает молиться, чтобы сервер подхватит новую версию».
Начнем с чего-то простого. Например, в архив забыли положить CSS или забыли поменять хештег в имени java-script файла. И когда мы делаем запрос к серверу, то браузер думает, что это java-script файл у него уже есть и решает его не перекачивать. А там была старая версия, чего-то стало не хватать. В общем, проблем может быть много. Поэтому практика Непрерывного развертывания позволяет вам, как минимум, проверить, что будет, если вы возьмете чистый эталонный образ и зальете его на полностью чистое новое окружение. Вы можете посмотреть, к чему это приведет.
Кроме того, когда вы интегрируете код между собой, т.е. между командой, это позволяет вам также посмотреть, как это выглядит на UI.
Одна из проблем, которая встречается, где используется много ванильного java-script, это то, что два разработчика взяли и сгоряча в объекте window объявили переменную с одним именем. И потом, как повезет. Чей java-script файл вытянется вторым, тот и перетрет изменения другого. Это тоже очень увлекательно. Ты заходишь: у одного человека одно работает, у другого — другое не работает. И «прекрасно», когда это все вылезает на production.

Следующая практика, которая у нас есть, это практика Автоматического восстановления, а именно отката на предыдущую версию приложения.
Почему это важно для разработчиков? Есть еще те, кто помнят далекие-далекие 90-ые, когда компьютеры были большие, а программы маленькие. И путь в веб-разработку лежал только через php. Не то что бы php — это плохой язык, хоть это и так.
Но проблема была в другом. Когда мы деплоили новую версию нашего php-сайта, мы, как его деплоили? Чаще всего мы открывали Far Manager или что-то еще. И заливали эти файлы на FTP. И мы вдруг поняли, что у нас какая-то маленькая-маленькая бага, например, мы забыли точку с запятой поставить или забыли поменять пароль от базы, и там стоит пароль от базы, которая на local хосте. И решаем быстренько подключиться на FTP и отредактируем файлы прямо там. Вот это просто огонь! Это то, что было популярно в 90-ых.
Но, если вы не заглядывали в календарь, 90-ые были почти 30 лет назад. Сейчас уже все происходит немножко по-другому. И попытайтесь представить масштаб трагедии, когда вам говорят: «Мы задеплоили на production, но там что-то пошло не так. Вот тебе логин и пароль от FTP, подключайся на production и быстренько там поправь». Если вы Чак Норрис, то это сработает. Если нет, то вы рискуете, что вы поправите одну багу, сделаете еще 10. Вот именно поэтому эта практика отката на прошлую версию, позволяет вам добиться многого.
Даже в случае, если что-то где-то как-то плохое пролезло на prod, то это плохо, но не смертельно. Вы можете откатиться на предыдущую версию, которая у вас есть. Назовите это бэкапом, если проще в такой терминологии воспринимать. Вы можете откатиться на эту предыдущую версию, и пользователи все равно смогут работать с вашим продуктом, а у вас появится адекватный запас по времени. Вы сможете спокойно, без спешки, все это взять и локально протестировать, пофиксить, а потом уже залить новую версию. Это реально имеет смысл делать.
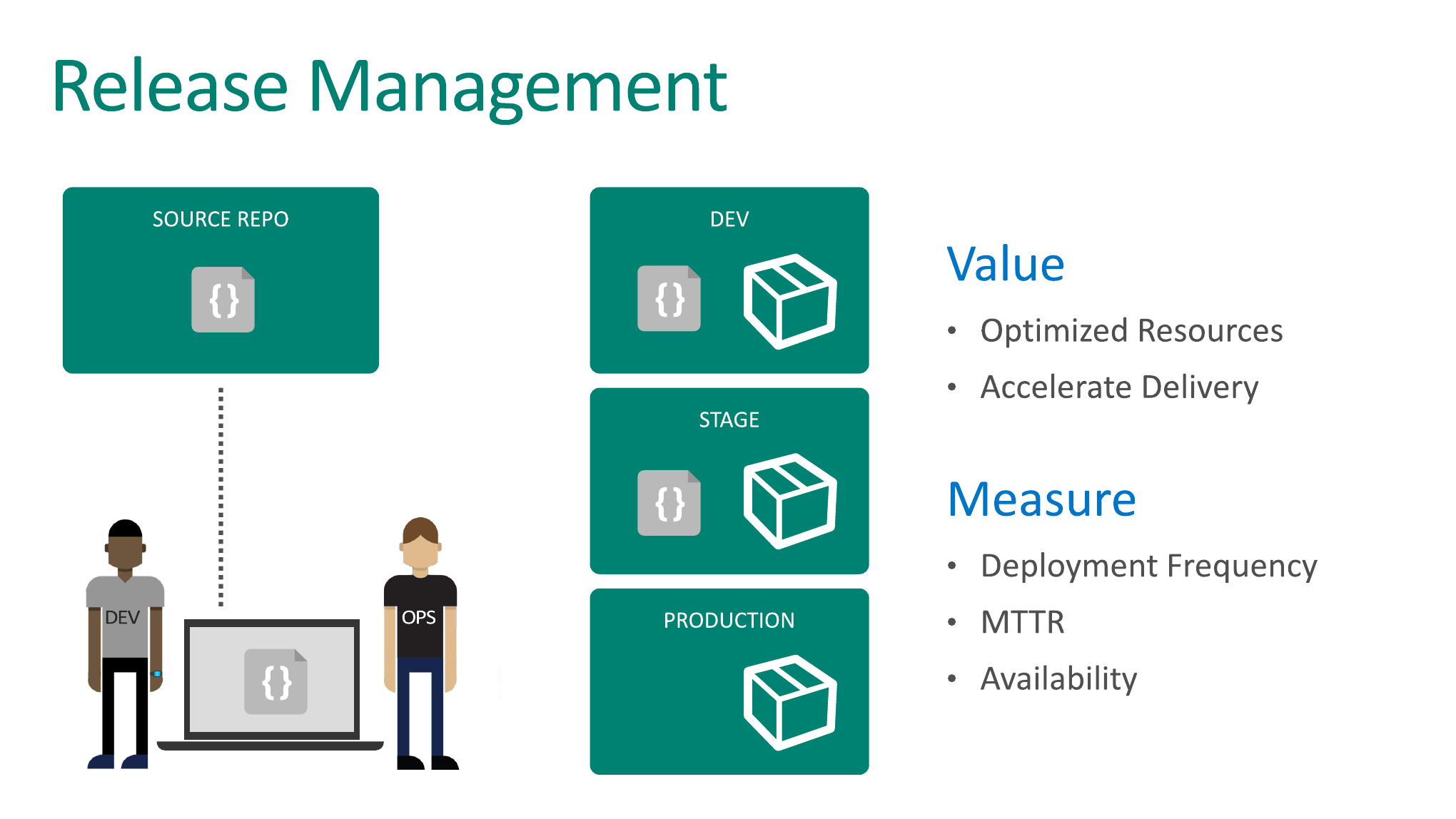
Теперь давайте попытаемся совместить где-то как-то две предыдущие практики вместе. Мы получим третью, которая называется Release Management.
Когда мы говорим про Continuous Deployment в классическом его представлении, то мы говорим, что мы должны вытянуть из репозитория код из какой-то ветки, скомпилировать и задеплоить. Это хорошо, если у нас одно окружение. Если у нас окружений несколько, то это означает, что мы должны каждый раз вытягивать код пускай даже из того же коммита. Мы каждый раз будем его вытягивать, каждый раз будем его билдить и будем деплоить на новое окружение. Во-первых, это время, потому что на build проекта, если он у вас большой и пришел из 90-ых, то это может занять несколько часов.
Кроме того, есть другая печаль. Когда вы будете билдить пускай даже на той же самой машине, вы будете билдить те же самые исходники, у вас все равно нет гарантии, что эта машина находится в том же состоянии, в котором она была во время прошлого билда.
Допустим, кто-то зашел и обновил вам DotNet или, наоборот, кто-то решил что-то удалить. И потом у вас когнитивный диссонанс, что из этого коммита две недели назад мы билдили билд и все было хорошо, а сейчас вроде как та же самая машина, тот же самый коммит, тот же самый код, который мы пытаемся билдить, но не получается. Вы долго с этим будете разбираться и не факт, что разберетесь. По крайней мере, нервов попортите себе очень много.
Поэтому практика Release Management предлагает внедрить дополнительную абстракцию, которая называется хранилище артефактов или галерея, или библиотека. Можно назвать как угодно.
Основная идея в том, что, как только у нас появляется там какой-то коммит, допустим, в ветке, которую мы уже готовы деплоить на наши разные окружения, мы собираем приложения из этого коммита и все, что нам надо для этого приложения, мы пакуем в zip-архив и сохраняем в каком-то надежном хранилище. И из этого хранилища мы этот zip-архив можем в любой момент достать.
Потом мы берем и автоматически разворачиваем его на dev-окружении. Там гоняем, и если все хорошо, то разворачиваем на stage. Если все хорошо, то разворачиваем на production один и тот же архив, одни и те же бинарники, скомпилированные ровно один раз.
Кроме того, когда у нас есть вот такая галерея, это также помогает нам адресовать риски, которые мы адресовали на прошлом слайде, когда мы говорили про rollback до предыдущей версии. Если вы случайно задеплоили что-то не то, вы всегда можете из вот этой галереи взять любую другую предыдущую версию и точно так же раздеплоить на эти окружения. Это позволяет вам в случае какого-то шухера легко откатиться на предыдущую версию.
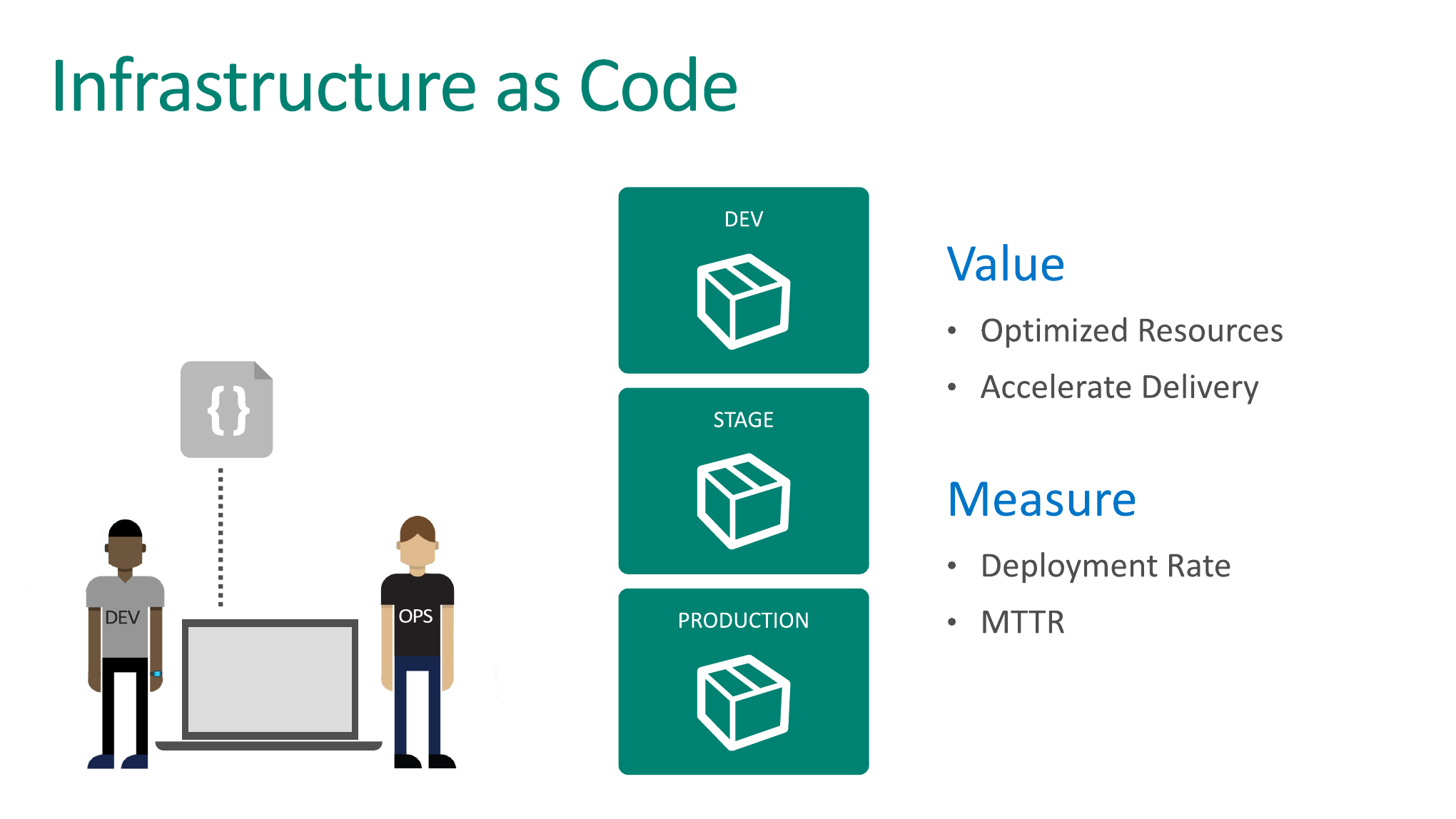
Есть еще одна великолепная практика. Все мы с вами понимаем, что, когда мы откатываем наши приложения на предыдущую версию, это может означать, что инфраструктура нам нужна тоже предыдущей версии.
Когда мы говорим про виртуальную инфраструктуру, многие думают, что это нечто такое, что настраивают админы. И если вам нужно, допустим, получить новый сервер, на котором вы хотите потестировать новую версию вашего приложения, то вы должны писать тикет админам или девопсам. Девопсы будут брать на это 3 недели. И через 3 недели скажут, что мы тебе установили виртуалку, где одно ядро, два гигабайта оперативной памяти и Windows-сервер без DotNet. Вы говорите: «А я хотел DotNet». Они: «Ok, приходи через 3 недели».
Идея в том, что, используя практику «Инфраструктура как код», вы можете относиться к вашей виртуальной инфраструктуре всего лишь как к еще одному очередному ресурсу.
Возможно, если кто-то из вас разрабатывает приложения на DotNet, вы могли слышать о такой библиотеке, как Entity Framework. И, возможно, вы даже слышали, что Entity Framework — это один из подходов, который Microsoft активно пушит. Для работы с базой данных это подход, который называется Code First. Это когда вы в коде описываете, как вы хотите, чтобы выглядела ваша база данных. И потом вы разворачиваете приложение. Оно подключается к базе, оно само определяет, какие таблицы есть, каких таблиц нет, и все, что вам необходимо, создает.
Точно так же вы можете делать с вашей инфраструктурой. Нет никакой разницы между тем нужна ли вам для проекта база данных или нужен для проекта Windows-сервер. Это всего лишь ресурс. И вы можете автоматизировать создание этого ресурса, вы можете автоматизировать настройку этого ресурса. Соответственно, каждый раз, когда вы захотите протестировать какую-то новую концепцию, какой-то новый подход, вам не надо будет писать тикет девопсам, вы сможете взять и просто развернуть сами себе из уже готовых шаблонов, из готовых скриптов изолированную инфраструктуру и провести там все ваши эксперименты. Можете удалить это, получить какие-то результаты и отраппортовать об этом дальше.

Следующая практика, которая тоже есть и тоже важна, но которой мало кто пользуется, это Application Performance Monitoring.
Про Application Performance Monitoring хотел сказать только одну вещь. Что больше всего важно в этой практике? Это то, что Application Performance Monitoring — это примерно так же, как и ремонт в квартире. Это не финальное состояние, это процесс. Вам нужно его проводить регулярно.
По-хорошему было бы хорошо Application Performance Monitoring проводить чуть ли не на каждый build, хотя, как вы понимаете, далеко не всегда это возможно. Но, как минимум, на каждый релиз его нужно проводить.
Почему это важно? Потому что если у вас вдруг пошла просадка по производительности, то вам нужно четко понимать из-за чего. Если у вас в команде, допустим, двухнедельные спринты, то вы хотя бы раз в две недели должны разворачивать ваше приложение на какой-то отдельно стоящий сервер, где у вас четко фиксированный процессор, оперативная память, диски и т. д. И прогоняете те же самые тесты производительности. Получаете результат. Смотрите, как оно поменялось от предыдущего спринта.
И если вы узнаете о том, что просадка пошла резко куда-то вниз, то это будет означать, что это было всего лишь из-за изменений, которые были на протяжении последних двух недель. Это позволит вам намного быстрее определить и исправить эту проблему. И опять это те же примерно метрики, по которым можно померить, насколько успешно это у вас получилось.
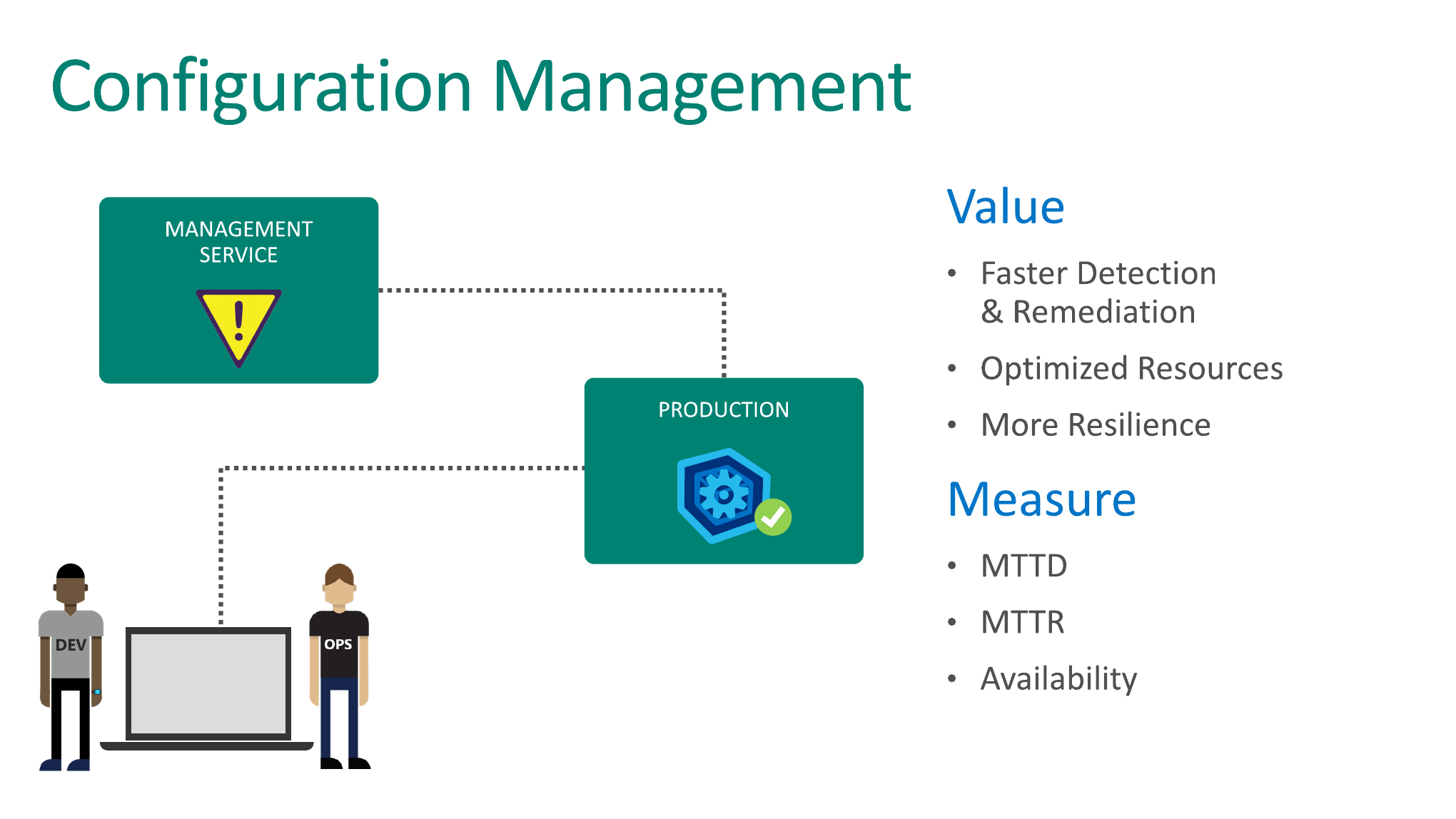
Следующая практика, которая у нас есть, это практика Configuration Management. Очень мало, кто относится к этому серьезно. Но, поверьте мне, это на самом деле очень серьезная штука.
Недавно была смешная история. Пришли ко мне ребята и говорят: «Помоги провести нам security audit нашего приложения». Мы долго смотрели вместе в код, они мне рассказывали о приложении, рисовали схемы. И плюс-минус все было логично, понятно, безопасно, но было одно НО! У них в source control лежали конфигурационные файлы в том числе от production с IP базы данных, с логинами и паролями для подключения к этим базам данных и т. д.
И я говорю: «Ребята, ладно вы firewall-ом закрыли свое production-окружение, но то, что у вас есть логин и пароль от production-базы прямо в source control и любой разработчик имеет возможность это прочитать, это уже огромный риск безопасности. И каким бы суперзащищенным ваше приложение не было с точки зрения кода, если у вас это останется лежать в source control, то никогда нигде никакой аудит вы не пройдете». Вот о чем я и говорю.
Управление конфигурацией. На разном окружении у нас может быть разная конфигурация. Например, у нас могут быть разные логины и пароли для баз данных для QA, demo, production-окружения и т. д.
Настройку этой конфигурации тоже можно автоматизировать. Она должна всегда быть отдельной от непосредственно приложения. Почему? Потому что приложение вы сбилдили один раз, и потом приложению все равно — подключаетесь к SQL-серверу по такому-то IP или по такому-то IP, оно должно работать одинаково. Поэтому если вдруг кто-то из вас до сих пор хардкодит connection string в коде, то запомните, что я вас найду и накажу, если вы окажетесь со мной на одном проекте. Это всегда выносится в отдельную конфигурацию, например, в web.config.
И эта конфигурация уже управляется отдельно, т. е. это как раз тот момент, когда может прийти разработчик и админ, сесть в одной комнате. И разработчик может сказать: «Смотри, вот бинарники моего приложения. Они работают. Приложению для работы нужна база данных. Вот рядом с бинарниками лежит файл. В этом файле это поле отвечает за логин, это за пароль, это за IP. Деплой его куда угодно». И админу это просто и понятно. Он может это деплоить и вправду куда угодно, управляя этой конфигурацией.

И последняя практика, о которой хотел бы сказать, это практика, которая очень-очень сильно относится к облакам. И максимальный эффект она приносит, если вы работаете в облаке. Это Автоматическое удаление вашего окружения.
Я знаю, что на этой конференции присутствуют несколько людей из тех команд, с которыми я работаю. И со всеми командами, с которыми я работаю, мы используем вот эту практику.
Почему? Конечно, было бы классно, если на каждого разработчика была бы виртуальная машина, которая бы работала 24/7. Но, возможно, для вас это новость, возможно, вы не обращали внимание, но сам по себе разработчик не работает 24/7. Разработчик работает обычно 8 часов в день. Пускай он приходит на работу рано, у него большой обед, в течение которого он ходит в спортзал. Пускай это 12 часов в день, когда разработчик реально пользуется этими ресурсами. По нашему законодательству у нас в неделе есть 5 из 7 дней, которые считаются рабочими.
Соответственно, в рабочие дни эта машина должна работать не 24 часа, а только 12, а на выходные дни эта машина работать вообще не должна. Казалось бы, все очень просто, но что здесь важно сказать? Внедряя вот эту простую практику по такому базовому расписанию, это позволяет вам уменьшить стоимость содержания этих окружений на 70%, т. е. вы цену на ваши dev, QA, demo, environment вы взяли и поделили на 3.
Вопрос, что делать с остальными деньгами? Например, купить разработчикам ReSharper, если еще не купили. Или устроить коктейльную вечеринку. Если у вас раньше было одно окружение, на котором паслись и dev, и QA, и все, то теперь вы можете сделать 3 разных, которые будут изолированы, и люди не будет мешать друг другу.

Что касается слайда с постоянным замером производительности, как можно сравнить производительность, если у нас в проекте было 1 000 записей в базе данных, через два месяца их миллион? Как понять, почему и какой смысл в замере производительности?
Это хороший вопрос, потому что вы производительность должны замерять всегда на одних и тех же ресурсах. Т. е. вы выкатываете новый код, вы замеряете производительность на новом коде. Например, вам необходимо проверить разные сценарии производительности, допустим, вы хотите проверить, как приложение работает на легкой нагрузке, где 1 000 пользователей и размер базы данных 5 гигабайтов. Вы замерили, получили цифры. Дальше берем другой сценарий. Например, 5 000 пользователей, размер базы 1 терабайт. Получили результаты, запомнили.
Что здесь важно? Здесь важно то, что в зависимости от сценария, от объема данных, от количества одновременных пользователей и т. д., вы можете упереться в те или иные лимиты. Например, в лимит сетевой карты или в лимит жесткого диска, или в лимит возможностей процессора. Вот, что вам важно понять. На разных сценариях вы упираетесь в те или иные лимиты. И нужно понимать цифры, когда вы в них упретесь.
Тут речь идет о замере производительности на специальном тестовом окружении? Т. е. это не production?
Да, это не production, это тестовое окружение, которое всегда одинаковое, чтобы вы могли сравнить его с предыдущими замерами.
Понял, спасибо!
Если вопросов нет, я думаю, можем закончить. Спасибо!
