Любопытные и неочевидные особенности при работе со Snowflake

Без долгих вступлений, сразу к делу.
Знаете ли вы, что в Snowflake можно создавать объекты с пустыми именами? Например:
CREATE DATABASE "";
CREATE SCHEMA ""."";
CREATE TABLE ""."".""("" NUMBER);Это работает на момент публикации и потенциально создаёт массу проблем для внешних систем, которые не ожидают такого поворота. Также это обычно приводит в восторг админов DWH.
Более интересные и практичные советы под катом.
Бесплатный automatic clustering
Многие знают о возможности указать ключи для автоматической кластеризации данных в таблице:
CREATE TABLE ... CLUSTER BY ( [ , ... ] ); Это позволяет Snowflake более эффективно хранить данные в микро-партициях и заметно ускорить чтение, если в запросе присутствует соответствующий фильтр.
Но немногие знают о том, что почти аналогичного результата можно добиться «бесплатно», если загружать и удалять данные в таблице исключительно небольшими блоками, которые организованы в строгом соответствии с желаемым ключом.
Например, вместо загрузки всей таблицы целиком в одной большой транзакции:
COPY INTO my_events FROM 's3://my_events/*/*.csv'Лучше разделить входящие данные на партиции и выполнить несколько маленьких транзакций, по одной на каждую дату:
COPY INTO my_events FROM 's3://my_events/2022-01-01/*.csv'
COPY INTO my_events FROM 's3://my_events/2022-01-02/*.csv'
COPY INTO my_events FROM 's3://my_events/2022-01-03/*.csv'В этом случае вы получите таблицу, которая кластеризована естественным образом, не потратив ни копейки на повторную перезапись микро-партиций. В зависимости от объема данных на аккаунте, эта простая техника поможет сэкономить сотни, тысячи, десятки тысяч долларов.
Проверить результат можно при помощи функции SYSTEM$CLUSTERING_INFORMATION, а также в профиле выполнения запроса через сравнение «Partitions scanned» и «Partitions total». Чем меньше партиций читает запрос, тем лучше.
Invalid views
В некоторых случаях объекты VIEW могут сломаться и перестать работать, даже если их SQL TEXT абсолютно корректен. К сожалению, при изменениях в объектах TABLE Snowflake не обновляет VIEW, которые от них зависят.
На практике это приводит к тому, что пользователи получают ошибки, которые можно исправить только ручным пересозданием VIEW. Например:
CREATE TABLE my_table(id NUMBER);
CREATE OR REPLACE VIEW my_view AS SELECT * FROM my_table;
SELECT * FROM my_view;
-- it worksПока всё замечательно. Теперь добавим ещё одну колонку в таблицу и сломаем VIEW:
ALTER TABLE my_table ADD name VARCHAR;
SELECT * FROM my_view;
-- it fails: view declared 1 column(s), but view query produces 2 column(s)Пересоздание VIEW исправляет ситуацию:
CREATE OR REPLACE VIEW my_view AS SELECT * FROM my_table;
SELECT * FROM my_view;
-- it works againЗакономерно встает вопрос, как же находить такие VIEW и автоматизировать их пересоздание с минимальными затратами?
Методом проб и ошибок, удалось найти способ, который не требует использования INFORMATION_SCHEMA, активного WAREHOUSE и хитрых процедур. Этот способ заключается в том, чтобы проверять все VIEW через команду .describe () в Snowflake Python Connector.
Она позволяет спланировать запрос, но не выполнять его. Если объект VIEW сломан, то команда вернёт исключение, на которое можно отреагировать пересозданием VIEW. Все эти операции «бесплатны».
Иерархия ролей
Документация Snowflake упоминает о пользе создания грамотной иерархии ролей для управления доступами, но она не приводит конкретных примеров. Из-за этого многие начинающие администраторы не уделяют этому должного внимания на старте, совершают много ошибок и быстро запутываются по мере роста сложности.
Далее я кратко опишу конкретный пример трехступенчатой иерархии ролей, которая показала отличные результаты на практике.
Tier 1: роли, которые дают привилегии на конкретные объекты через GRANTS и FUTURE GRANTS.
Например: «роль позволяет читать все таблицы в схеме XXX», «роль позволяет использовать warehouse YYY», «роль даёт доступ на запись в таблицы ZZ1 и ZZ2».
Tier 2: роли, которые объединяют одну или несколько T1 ролей в бизнес-функцию.
Например: «роль финансовый аналитик», «роль разработчик BI», «роль внешний аудитор».
Tier 3: роли, которые объединяют одну или несколько T2 ролей и назначают их конкретному пользователю.
Например: «Алиса — бизнес аналитик», «Боб — внешний аудитор», «Виктор — бизнес аналитик в проекте ААА, но также администратор в проекте BBB».

Создание большинства типов ролей в этой системе удобно автоматизировать.
Например, можно создавать отдельные T1 роли для каждой схемы с FUTURE GRANTS на:
владение всеми объектами в схеме (
OWNERSHIP);чтение всех объектов в схеме (
READ);запись во все объекты в схеме (
WRITE);
Дополнительно можно создавать T1 роли для каждого WAREHOUSE с правами на USAGE и OPERATE.
Наконец, T3 роли могут создаваться и назначаться для каждого пользователя автоматически. Вручную остаётся настроить только T2 бизнес роли и назначить их конкретным пользователям.
Временные затраты на управление такой системой приближаются к нулю. Также ей очень рады аудиторы и безопасники, которым не нужно распутывать сложный клубок из костылей и подпорок.
Управление пакетами для Java & Python UDF
В настоящий момент Snowflake активно развивает концепцию UDF функций, которые позволяют выполнять почти произвольный код, написанный на Java или Python, прямо внутри WAREHOUSE, не вынимая данные наружу.
Потенциально это крайне мощный инструмент, но его использование поднимает ряд практических вопросов, один из которых — как управлять пакетами (.JAR, .WHL)?
Одно из простых и удачных решений — относиться к пакетам как к еще одному типу объектов внутри Snowflake, которые зависят от STAGE и обновляются вместе с FUNCTION в рамках одного и того же CI/CD процесса.
Например, если вы храните описания объектов в Git, то последовательность их применения будет следующая:
Создать
DATABASE.Создать
SCHEMA.Создать
STAGE(internal) для пакетов.Загрузить .JAR / .WHL файлы в
STAGE.Создать
FUNCTION, который зависит от загруженных файлов.
Другими словами, управление пакетами должно происходить не «до», не «после», не «вручную сбоку», а строго между созданием STAGE и созданием FUNCTION. В этом случае все будет работать без ошибок.
У этого процесса есть одна техническая особенность — как понять, что уже существующие файлы в STAGE нуждаются в обновлении? У Snowflake есть стандартная команда LIST, которая позволяет получить список файлов в STAGE, а также их MD5 суммы.
Но проблема в том, что эти MD5 суммы считаются не от оригинального файла, а от зашифрованного файла, что не подходит для сравнения. Чтобы сохранить оригинальный MD5, можно дополнительно загружать в STAGE пустые файлы, которые содержат хеш в своём имени.
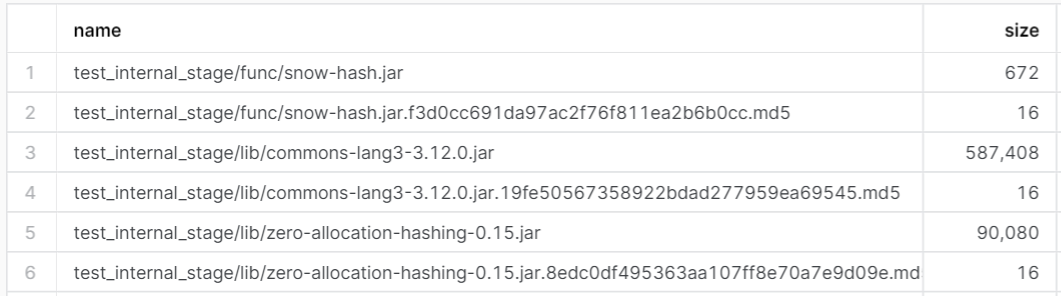
Или, если пакетов пока немного, то их можно целиком перезаписывать при каждом вызове CI/CD.
SnowDDL: open source инструмент для управлений схемой объектов
Когда я только начинал работать со Snowflake, то был удивлен отсутствием полноценных декларативных инструментов для работы со схемой объектов. У самых популярных вариантов (schemachange и Terraform) есть существенные пробелы, и даже сам вендор рекомендует использовать их совместно, что довольно неудобно.
Чтобы немного исправить эту ситуацию, мной был создан и выложен в открытый доступ новый нативный инструмент — SnowDDL (docs). Его основные особенности:
Отсутствие «состояния».
Возможность откатывать изменения.
Поддержка
ALTER COLUMNв тех случаях, когда это возможно.Встроенная иерархия ролей, которая описана выше в этой статье.
Невалидные
VIEWобновляются автоматически.Упрощение Code Review за счет разделения операций на условно «опасные» и условно «безопасные».
Возможность создания несколько изолированных «окружений» для каждого разработчика в рамках одного Snowflake аккаунта.
Простое и явное управление зависимостями между объектами.
Управление пакетами для UDF функций, которое описано выше в этой статье.
Чтобы не делать эту статью слишком длинной, пока на этом остановлюсь.
Если у читателей возникнет достаточный интерес, то в последующих выпусках я с удовольствием расскажу о деталях реализации SnowDDL, а также о других неочевидных особенностях при работе со Snowflake.
Enjoy!
