Логика у HR проста — обучать ИИ на «прижившихся»
На секунду у меня в голове возникла картина: сыщик дает собаке понюхать предмет, принадлежащий разыскиваемому лицу, и та мгновенно берет след. Аналогия не точна, но и не противоречива. А речь идет о сервисе GoRecruit, который с помощью методов машинного обучения выбирает из сотен кандидатов тех, кто с большей вероятностью приживется на должности, и формирует своеобразный рейтинг, который уже изучают кадровики.
Для поиска айтишников такая схема пока не особо применима, поскольку эта область специфическая, и тут рекрутеры используют другие инструменты. А в остальном — вполне актуальная вещь, особенно когда откликнувшихся на вакансию больше сотни.
О том, как работает сервис и какова тут логика кадровиков, нам рассказал Александр Барабаш. Формально он директор GoRecruit, но при этом имеет прямое отношение к разработке.
REM Это продолжение серии бесед с разработчиками и идейными вдохновителями всевозможных AI-систем. Ранее я и мои коллеги общались с создателями генератора изобретений Awtor (https://habr.com/ru/company/leader-id/blog/521378/), разговорного ИИ iPavlov (https://habr.com/ru/company/leader-id/blog/522624/) и организатором конференции OpenTalks.AI (https://habr.com/ru/company/leader-id/blog/523448/).— Что собой представляет GoRecruit, как она работает?
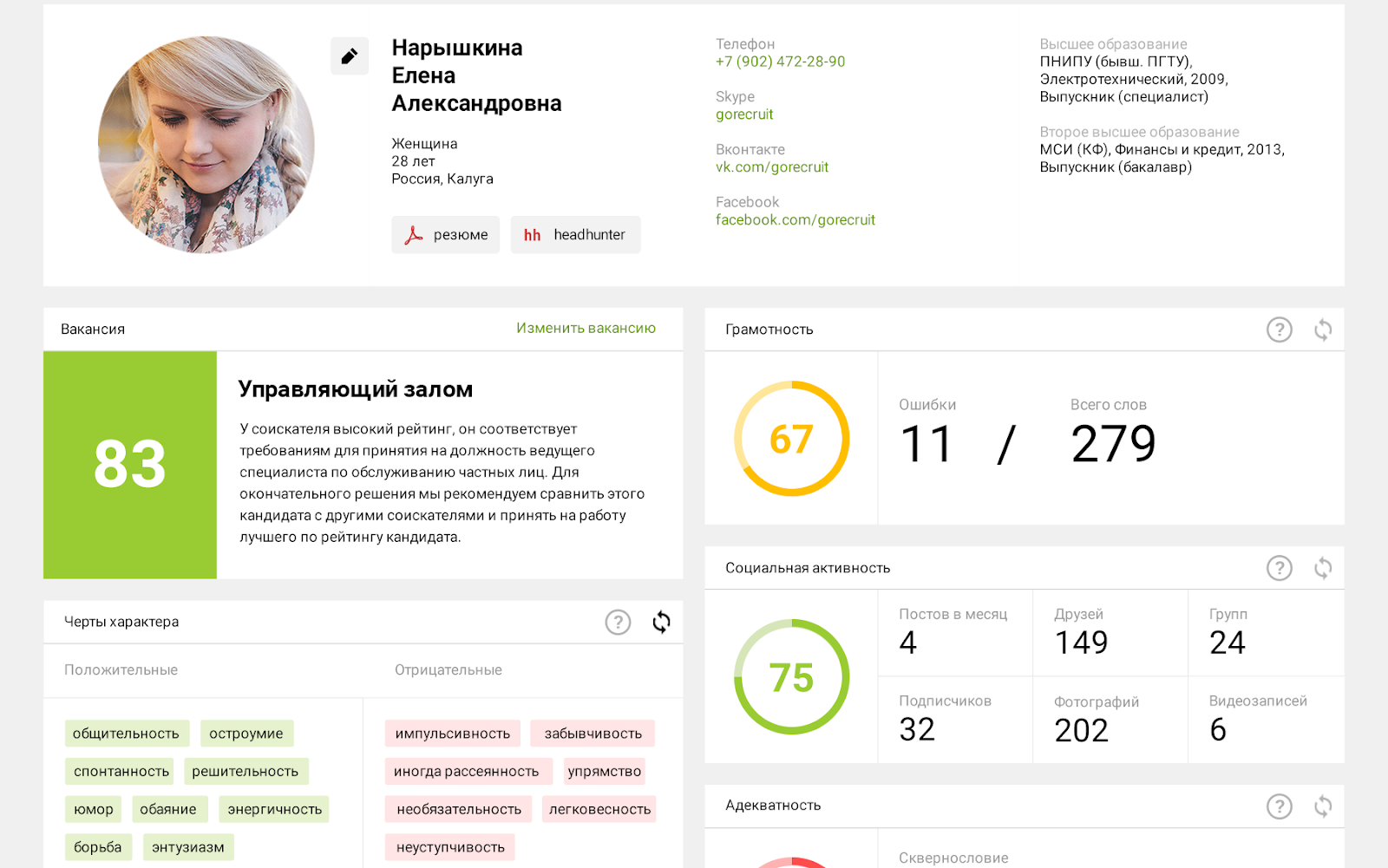
— Это система поддержки принятия кадровых решений на основе анализа данных из резюме и открытых источников, в том числе социальных сетей. Она рассчитывает рейтинг соискателя, претендующего на определенную профессию, сокращая трудозатраты рекрутера.
Принципиальное отличие от аналогов в том, что для участия в оценке соискатель должен откликнуться на вакансию и самостоятельно загрузить в нее свое резюме или авторизоваться через профиль в социальных сетях. На мой взгляд, это очень важная логика. Некоторые сервисы предлагают инструменты «холодного» поиска соискателей: они берут открытые данные из профилей ни о чем не подозревающих людей, что иногда противоречит политике социальных сетей. Это неправильно. Мы же берем данные только после авторизации (т.е. согласия пользователя), дополняя их данными из резюме и открытых источников вроде Федеральной службы судебных приставов, баз МВД и Налоговой. Конечная задача системы — обогатить данные о соискателе, сформировав развернутый отчет для кадровой службы и безопасников.
Среди прочей информации этот отчет содержит рейтинг, который характеризует ожидаемую успешность данного кандидата на выбранной вакансии. Что дальше делать с этим рейтингом, решает рекрутер.
— А каким образом вы описываете вакансию для сравнения? И причем тут искусственный интеллект?
— По сути, искусственный интеллект, о котором так часто сейчас говорят, — это методы экстраполяции статистических данных. Но чтобы что-то экстраполировать, нужно иметь достаточный объем начальной информации. Для крупного бизнеса, где есть статистические данные о движении кадрового состава, мы строим модель вакансии на основе этих данных с помощью нейросетей.
Фактически мы анализируем информацию о тех сотрудниках компании, которые успешны на заданной позиции.
В результате рейтинг кандидата в отчете будет рассчитываться на базе этого опыта компании (на базе сравнения с другими людьми, работавшими на аналогичных должностях в этой компании).
Для малого и среднего бизнеса, где статистических данных недостаточно для построения модели, мы используем экспертную систему. В основе математической модели этой системы лежит экспертное мнение специалистов, заменяющее ход человеческой мысли в принятии решения. Такой подход оправдан, когда у бизнеса не хватает собственных статистических данных. Со временем мы развиваем эти модели — вносим коррективы по необходимости.
— Если говорить о нейросетевой модели, как тут оценивается «успешность» человека на той или иной позиции?
— А это одна из тонкостей нашей работы. В разных компаниях эти критерии отличаются. Самый простой вариант — это статус трудоустройства через определенный период времени. Допустим, если человек через год после трудоустройства все еще работает на этой должности, он может считаться успешным, ведь конечная цель — найти непроблемного человека, который бы долго проработал в компании.
В более продвинутых компаниях есть внутренние кадровые KPI. Мы берем их за основу — считаем успешными людей с показателем, например, выше 70%. Выбираем соответствующим образом данные о движении кадрового состава и обучаем математическую модель на каждую профессию в отдельности.
— Какие есть ограничения применимости у этого подхода?
— Жестких ограничений нет. Но это статистический метод. Понятно, что чем больше данных (богаче выборка), тем точнее прогноз, т.е. мы точнее скажем, насколько успешен будет кандидат. Поэтому решение лучше всего работает на каких-то массовых профессиях. Давать рекомендации на высокие или уникальные позиции мы пока не готовы.
— Какое место занимает система в процедуре поиска людей?
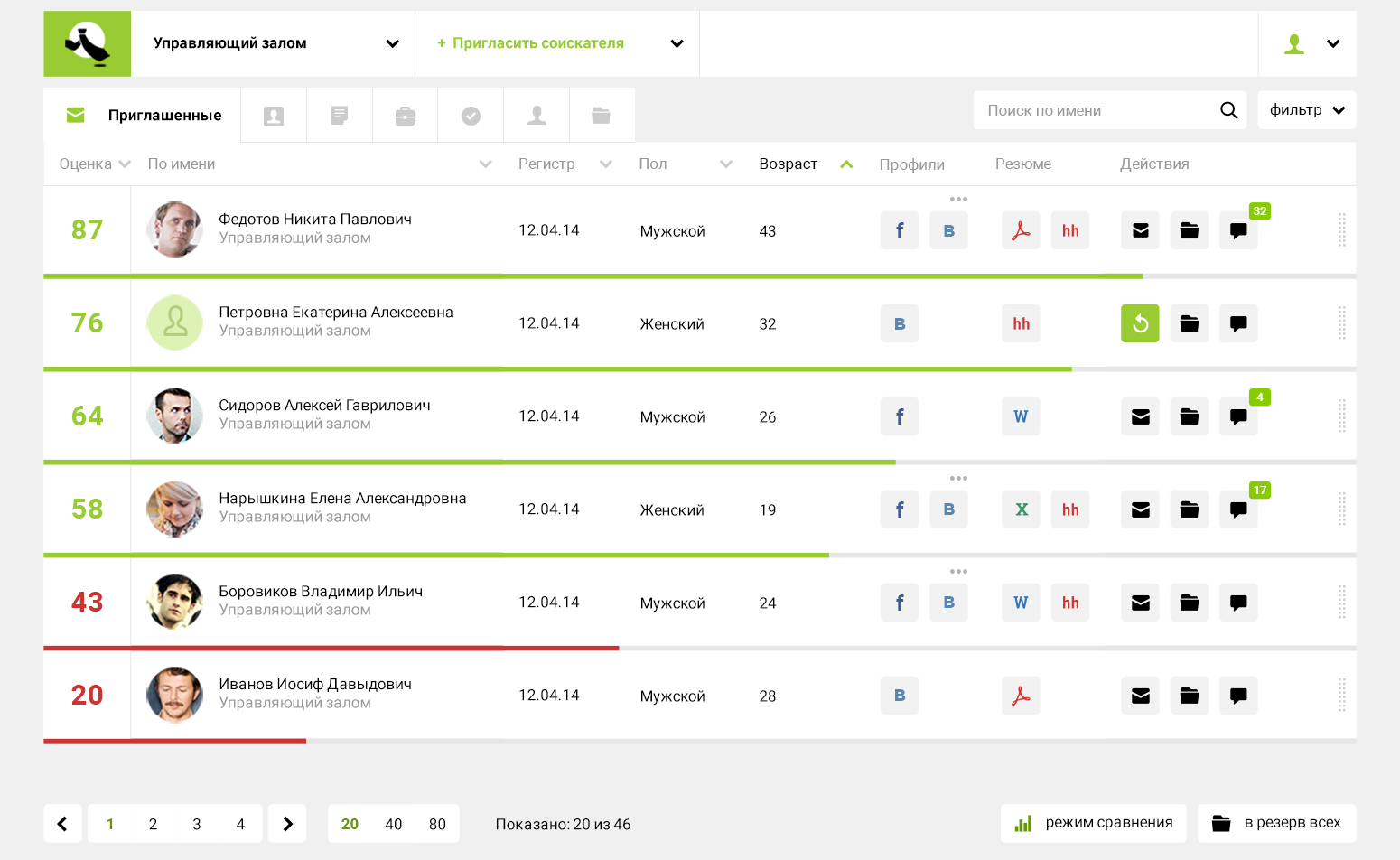
— Мы не занимаемся поиском. Мы занимаем другую нишу — обеспечиваем оценку, когда получили много откликов на вакансию и надо принять решение, кого позвать на собеседование.
У нас был очень показательный кейс: компания среднего размера искала замдиректора. На эту вакансию откликнулось 600 человек. Если бы рекрутер тратил только по 5 минут на каждого кандидата, ему потребовалось бы 50 часов, больше недели чистого рабочего времени, только для того, чтобы прочитать и вникнуть, что же прислали претенденты.
А наша система дает ответ за 5 секунд: рассчитывает рейтинг и ранжирует по нему 600 резюме. Можно сразу переходить к следующему этапу — приглашать на собеседование или отправлять тестовое задание, в зависимости от того, как внутри компании принимают кадровые решения.
Фактически это начальный фильтр в цепочке действий, связанных с принятием кадровых решений, самый трудоемкий. Одно дело — сравнить трех человек. Но невозможно запомнить и сравнить условные 600 резюме — это выше физических возможностей человека. Прочитав даже десяток, вы уже забудете, что было вначале. Наши психологи любят повторять, что человеческий мозг запоминает и может оперативно хранить в голове порядка 7–10 параметров. Поэтому большой вопрос, насколько качественно рекрутер вручную будет изучать 600 резюме в течение недели.
— Как именно строится этот рейтинг? Какие данные вы берете из резюме?
— Мы используем комбинированный подход — методы онтологического инжиниринга сочетаем с нейросетями. Система выделяет из текста резюме смысловые значения, которые нам необходимы для последующего расчета рейтинга. Где человек работал до этого, на какой должности, какие позиции занимал, были ли у него перерывы в работе, каких успехов он достиг и какие функции выполнял, какое получил образование, соответствует ли его профессия профилю образования и т.п.
Также, если это имеет значение, выделяем возраст, пол и прочую дополнительную информацию — все, на что посмотрит обычный сотрудник кадровой службы при прочтении резюме. Каждый из этих пунктов — это параметр. Обычно рекрутер их и сравнивает, мы же просто алгоритмизировали это сравнение.
— Какие дополнительные источники информации вы используете?
— Кроме упомянутых баз МВД, ФССП и т.п, мы сейчас используем социальную сеть ВКонтакте. Также у нас есть разработки для Facebook и Twitter, но ВКонтакте — основной источник. Когда мы делали модель принятия кадровых решений на должность оператора ПК для многофункциональных центров, мы выявили, что порядка 97% кандидатов имеют профиль в этой социальной сети. Кстати, клиент в тот момент сомневался, получится ли данными из ВКонтакте обогатить профили, но показатель в 97% его успокоил.
— А что именно интересует вашу систему в профиле социальной сети?
— В первую очередь мы берем тексты, которые человек публикует у себя на странице, чтобы определить его психологический портрет.

Примеры ключевых слов для оценки психотипа из совместного исследования Университета Пенсильвании и Кембриджа
Это своего рода предобработка данных. Мы оцениваем личностные качества по используемым в постах словам и оборотам (подробнее о похожей методике, использовавшейся для анализа постов в Facebook, можно почитать тут (pdf) и тут).
Используя типологию Майерс — Бриггс, мы относим человека к одному из 16 психотипов.
Эта информация тоже влияет на итоговый рейтинг: для разных профессий подходят люди совершенно разных психотипов.
Кроме того, нас, конечно же, интересует информация из профиля. ВКонтакте выдает около 70 параметров — то, что человек написал о себе на странице: возраст, пол, образование, предпочтения, дети и т.п.
— По скольким постам система может дать оценку человеку? А если в соцсетях размещаются только фотографии котиков?
— Система не предлагает чудес — она ведет себя как обычный рекрутер.
Предположим, кандидат откликнулся на вакансию, но ничего не написал в резюме. Мы (как и рекрутер) смотрим в открытые данные — допустим, там тоже ничего нет. Либо нет самого профиля в социальной сети, либо он пустой.
В этом случае рекрутер и безопасник будут расценивать этого кандидата как источник больших рисков на будущее. Как правило, таких людей не берут, потому что потом они могут создать компании дополнительные проблемы.
Такова распространенная логика принятия кадрового решения. Если вы не видите информации о кандидате и не можете проверить его по открытым источникам, вы переходите к следующему резюме.
Сравнивая двух людей — с богатым подтвержденным опытом, хорошим образованием и знаниями или эдакого инкогнито, вы скорее всего выберете того, о котором известно больше.
Наша система интерпретирует здесь человеческую логику. Отсутствие данных — это тоже информация, определенным образом характеризующая личность, но, как правило, она используется с низким рейтингом.
— В итоге с точки зрения системы идеальный кандидат — тот, кто открыто «выкладывает жизнь» в соцсети?
— Нет. Социальные сети — это всего лишь дополнение, а основные данные получаем из резюме.
— Анализируете ли вы тексты статей на Хабре или код на GitHub, чтобы еще больше обогатить профиль?
— Нет. Это в основном ресурсы для айтишников, а у нас нет такой фокусировки. В этом сегменте есть другие инструменты, которые заточены под поиск и оценку именно ИТ-специалистов.
— Есть какие-то факторы, которые с точки зрения системы однозначно засчитываются кандидату в плюс или в минус?
— В этом как раз уникальная особенность GoRecruit: таких факторов нет. Все собранные данные влияют на итоговое решение. Но под каждую профессию, в каждой компании степень влияния каждого из факторов будет отличаться.
Смысл математической модели и заключается в том, что эти параметры изменяются в зависимости от того, как происходит обучение — какие для этого используются данные.
— В ходе работы над моделями перед вашими глазами, наверное, прошли сотни резюме. Можете ли вы выделить какие-то типичные черты поколений?
— Скорее нет, за исключением одного. Чем человек старше, тем у него богаче бэкграунд. Как правило, с возрастом у него начинает прослеживаться карьерный путь и в целом о нем есть больше информации.
Но я могу отметить другую особенность: резюме как формат гораздо разнообразнее, чем кажется на первый взгляд. Несмотря на наличие шаблонов вроде HeadHunter, люди пишут в резюме очень разные вещи и в очень разных формулировках. И здесь мы сталкиваемся с проблемами при выявлении смысловых значений, поскольку все алгоритмы отчасти упираются в структуру резюме. Это сложная и интересная задача.
— Вы подали заявку на акселератор Архипелаг 20.35. Что вы хотите получить от него?
— Мне кажется, это интересная возможность для общего развития нашего продукта во всех направлениях. Судя по тому, что я читал об Архипелаге, он предлагает разнонаправленные возможности, так что мы не воспринимаем мероприятие как что-то одностороннее — поиск инвестора или что-то еще. Здесь мы ждем решения наших вопросов развития, новых контактов, продвижения продукта и даже будем искать клиентов. Все вместе.
— Кто в вашей команде? Рекрутеры, разработчики, математики?
— У нас команда математиков, программистов и психологов — люди на стыке технических и гуманитарных наук (психологии и математики), специалисты в области Big data, искусственного интеллекта (машинного обучения).
