Девять советов по повышению производительности Kubernetes

Всем привет! Меня зовут Олег Сидоренков, я работаю в компании ДомКлик руководителем команды инфраструктуры. Мы эксплуатируем «Кубик» в проде уже больше трёх лет, и за это время пережили с ним много разных интересных моментов. Сегодня я поведаю вам, как при правильном подходе можно выжать из «ванильного» Kubernetes ещё больше производительности для вашего кластера. Ready steady go!
Все вы прекрасно знаете, что Kubernetes — это масштабируемая система с открытым кодом для оркестрации контейнерами; ну, или 5 бинарей, которые творят магию, управляя жизненным циклом ваших микросервисов в серверной среде. Кроме того, это довольно гибкий инструмент, который можно собирать, как конструктор Lego, для максимальной кастомизации под разные задачи.
И вроде бы всё хорошо: закидывай серваки в кластер, как дровишки в топку, и горя не знай. Но если ты за экологию, то задумаешься: «Как я могу поддерживать огонь в печке и лес пожалеть?». Другими словами, как найти способы улучшения инфраструктуры и снижения затрат.
1. Следите за ресурсами команд и приложений

Один из самых банальных, но действенных методов — введение requests/limits. Разделяйте приложения по неймспейсам, а неймспейсы по командам разработки. Задавайте приложению перед деплоем значения по потреблению процессорного времени, памяти, эфемерного хранилища.
resources:
requests:
memory: 2Gi
cpu: 250m
limits:
memory: 4Gi
cpu: 500mОпытным путём мы пришли к выводу: не стоит раздувать реквесты от лимитов более, чем в два раза. Объём кластера рассчитывается исходя из реквестов, и если вы будете задавать приложениям разницу в ресурсах, например, в 5–10 раз, то представьте, что станет с вашей нодой, когда она заполнится подами и резко получит нагрузку. Ничего хорошего. Как минимум, троттлинг, а как максимум, попрощаетесь с воркером и получите цикличную нагрузку на остальные ноды после того, как поды начнут переезжать.
Кроме того, с помощью limitranges вы можете на старте задать для контейнера значения по ресурсам — минимальные, максимальные и по умолчанию:
➜ ~ kubectl describe limitranges --namespace ops
Name: limit-range
Namespace: ops
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 10 100m 100m 2
Container ephemeral-storage 12Mi 8Gi 128Mi 4Gi -
Container memory 64Mi 40Gi 128Mi 128Mi 2Не забудьте ограничить ресурсы неймспейса, чтобы одна команда не смогла забрать все ресурсы кластера:
➜ ~ kubectl describe resourcequotas --namespace ops
Name: resource-quota
Namespace: ops
Resource Used Hard
-------- ---- ----
limits.cpu 77250m 80
limits.memory 124814367488 150Gi
pods 31 45
requests.cpu 53850m 80
requests.memory 75613234944 150Gi
services 26 50
services.loadbalancers 0 0
services.nodeports 0 0Как видно из описания resourcequotas, если команда ops захочет развернуть поды, которые будут потреблять еще 10 cpu, то планировщик не даст это сделать и выдаст ошибку:
Error creating: pods "nginx-proxy-9967d8d78-nh4fs" is forbidden: exceeded quota: resource-quota, requested: limits.cpu=5,requests.cpu=5, used: limits.cpu=77250m,requests.cpu=53850m, limited: limits.cpu=10,requests.cpu=10Для решения подобной задачи можно написать инструмент, например, как этот, умеющий хранить и коммитить состояние ресурсов команд.
2. Подбирайте оптимальное файловое хранилище

Здесь я хотел бы коснуться темы персистентных томов и дисковой подсистемы worker-нод Kubernetes. Я надеюсь, что никто не использует «Куб» на HDD в проде, но порой и обычного SSD уже становится мало. Мы сталкивались с такой проблемой, что логи убивали диск по операциям ввода-вывода, и тут вариантов решения не очень много:
Использовать высокопроизводительные SSD или переходить на NVMe (если вы сами распоряжаетесь своим железом).
Уменьшать уровень журналирования.
Делать «умную» балансировку подов, которые насилуют диск (
podAntiAffinity).
Скрин выше показывает, что происходит под nginx-ingress-controller с диском, когда включено журналирование access_logs (~12 тыс. журналов/сек.). Такое состояние, конечно же, может приводить к деградации всех приложений на этой ноде.
Что касается PV, увы, я не испробовал все виды Persistent Volumes. Используйте лучший вариант, который подходит именно вам. У нас исторически так сложилось, что небольшая часть сервисов нуждается в RWX-томах, и давным-давно под эту задачу стали использовать NFS-хранилку. Дёшево и… хватает. Конечно, мы с ним наелись говна — будь здоров, но научились его тюнить, и голова больше не болит. А если возможно, переходите на объектное хранилище S3.
3. Собирайте оптимизированные образы

Лучше всего использовать оптимизированные под контейнеры образы, чтобы Kubernetes мог быстрее доставать их и эффективнее исполнять.
Оптимизированность означает, что образы:
содержат только одно приложение или выполняют только одну функцию;
небольшого размера, потому что большие образы хуже передаются по сети;
имеют конечные точки для проверки работоспособности и готовности, с помощью которых Kubernetes может предпринимать какие-то действия в случае простоев;
используют дружелюбные к контейнерам операционные системы (вроде Alpine или CoreOS), которые более устойчивы к ошибкам конфигурирования;
используют многоэтапные сборки, чтобы вы могли развёртывать только скомпилированные приложения, а не сопутствующие исходники.
Есть много инструментов и сервисов, позволяющих проверить и оптимизировать образы на лету. Важно всегда поддерживать их в актуальном состоянии и проверенными на безопасность. В итоге вы получаете:
Снижение сетевой нагрузки на весь кластер.
Уменьшение времени запуска контейнера.
Меньший объём всего вашего Docker registry.
4. Используйте кэш ДНС

Если говорить о высоких нагрузках, то без тюнинга DNS-системы кластера жить довольно паршиво. Когда-то давно разработчики Kubernetes поддерживали своё решение kube-dns. Оно было внедрено и у нас, но эта софтина особо не тюнилась и не выдавала требуемую производительность, хотя, вроде бы, задача простая. Затем появился coredns, на который мы перешли и горя не знали, впоследствии он же стал DNS-сервисом по умолчанию в K8s. В какой-то момент мы доросли до 40 тыс. rps к DNS-системе, и этого решения тоже стало не хватать. Но, по счастливой случайности, вышел Nodelocaldns, он же node local cache, он же NodeLocal DNSCache.
Почему мы это используем? В ядре Linux есть баг, который при множественном обращении через conntrack NAT по UDP приводит к состоянию гонки за запись в conntrack-таблицы, и часть трафика через NAT теряется (каждый поход через Service — это NAT). Nodelocaldns решает эту проблему путем избавления от NAT и апгрейда подключения до TCP к апстримовым DNS, а также локальным кэшированием DNS-запросов к апстримам (включая короткий 5-секундный негативный кэш).
5. Масштабируйте поды горизонтально и вертикально автоматически

Можете ли вы с уверенностью сказать, что все ваши микросервисы готовы к двух-трёкратному росту нагрузки? Как правильно выделять ресурсы своим приложениям? Держать запущенными пару подов сверх рабочей нагрузки может оказаться избыточным, а держать впритык — рискуете получить простой от внезапного роста трафика на сервис. Золотой середины помогают достичь заклятие умножения такие сервисы, как Horizontal Pod Autoscaler и Vertical Pod Autoscaler.
VPA позволяет автоматически поднимать requests/limits ваших контейнеров в поде в зависимости от фактического использования. Чем он может быть полезен? Если у вас есть поды, которые нельзя по какой-то причине горизонтально отмасштабировать (что не совсем надёжно), то можете попробовать доверить изменение его ресурсов VPA. Его фишка заключается в системе рекомендаций на основе исторических и текущих данных из metric-server, поэтому, если вы не хотите автоматически менять requests/limits, то можете просто отслеживать рекомендуемые ресурсы для ваших контейнеров и оптимизировать настройки для экономии процессора и памяти в кластере.
 Изображение взято с https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Изображение взято с https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Планировщик в Kubernetes всегда основывается на requests. Какое бы значение вы туда не поставили, планировщик будет искать подходящую ноду, исходя из него. Значения limits нужны кублету для того, чтобы понимать, когда троттлить или убивать под. И поскольку единственный важный параметр — значение requests, VPA будет работать с ним. Всякий раз, когда вы задаёте вертикальное масштабирование приложения, вы определяете, какими должны быть requests. А что тогда будет с limits? Этот параметр будет также пропорционально отмасштабирован.
К примеру, вот обычные настройки пода:
resources:
requests:
memory: 250Mi
cpu: 200m
limits:
memory: 500Mi
cpu: 350mМеханизм рекомендаций определяет, что вашему приложению для нормальной работы требуется 300m CPU и 500Mi. Вы получите такие настройки:
resources:
requests:
memory: 500Mi
cpu: 300m
limits:
memory: 1000Mi
cpu: 525mКак упоминалось выше, это пропорциональное масштабирование исходя из соотношения requests/limits в манифесте:
Что касается HPA, то тут механизм работы прозрачней. Выставляются пороговые значения метрик, например, процессора и памяти, и если среднее значение всех реплик превышает пороговое, то приложение масштабируется на +1 под до тех пор, пока значение не упадет ниже порога, либо пока не будет достигнуто максимальное количество реплик.
 Изображение взято с https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Изображение взято с https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Помимо обычных метрик, вроде процессора и памяти, вы можете настроить пороги на своих кастомных метриках из Prometheus и работать с ними, если считаете это наиболее точным определением, когда следует масштабировать ваше приложение. После того, как приложение стабилизируется ниже заданной границы метрики, HPA начнет масштабировать поды вниз до минимального количества реплик или до состояния, когда нагрузка будет удовлетворять заданному порогу.
6. Не забывайте про Node Affinity и Pod Affinity

Не все узлы работают на одинаковом оборудовании, не всем подам нужно исполнять приложения, требующие интенсивных вычислений. Kubernetes позволяет задавать специализацию нод и подов с помощью Node Affinity и Pod Affinity.
Если у вас есть ноды, подходящие для операций с интенсивными вычислениями, то для максимальной эффективности лучше привязать приложения к соответствующим нодам. Для этого используйте nodeSelector с меткой узла.
Допустим, у вас две ноды: одна с CPUType=HIGHFREQ и большим количеством быстрых ядер, другая с MemoryType=HIGHMEMORY большим количеством памяти и более высоким быстродействием. Проще всего назначить развёртывание пода ноде HIGHFREQ, добавив в раздел spec такой селектор:
…
nodeSelector:
CPUType: HIGHFREQБолее затратный и специфичный способ сделать это — использовать nodeAffinity в поле affinity раздела spec. Есть два варианта:
requiredDuringSchedulingIgnoredDuringExecution: жёсткая настройка (планировщик будет развёртывать поды только на конкретных нодах (и нигде больше));preferredDuringSchedulingIgnoredDuringExecution: мягкая настройка (планировщик попытается развернуть на конкретных нодах, а если не получится, то попытается развернуть на следующей доступной ноде).
Вы можете задать определённый синтаксис управления метками узлов, например, In, NotIn, Exists, DoesNotExist, Gt или Lt. Однако помните, что сложные методы в длинных списках меток замедлят принятие решений в критических ситуациях. Иными словами, не усложняйте.
Как упоминалось выше, Kubernetes позволяет задать привязку текущих подов. То есть вы можете сделать так, чтобы определённые поды работали вместе с другими подами в той же зоне доступности (актуально для облаков) или нодах.
В podAffinity поля affinity раздела spec доступны те же поля, что и в случае с nodeAffinity: requiredDuringSchedulingIgnoredDuringExecutionи preferredDuringSchedulingIgnoredDuringExecution. Единственное отличие в том, что matchExpressions привяжет поды к ноде, на которой уже исполняется под с такой меткой.
Ещё Kubernetes предлагает поле podAntiAffinity, которое, напротив, не привязывает под к ноде с определёнными подами.
Насчёт выражений nodeAffinity можно дать тот же совет: старайтесь сохранять простоту и логичность правил, не надо пытаться перегрузить спецификацию подов сложным набором правил. Очень легко создать правило, которые не будет соответствовать условиям кластера, создав лишнюю нагрузку на планировщик и снизив общую производительность.
7. Taints & Tolerations
Есть ещё один способ управления планировщиком. Если у вас большой кластер с сотнями нод и тысячами микросервисов, то очень сложно не позволять определённым подам размещаться на определённых нодах.
В этом помогает механизм taints — запрещающих правил. Например, можно в определённых сценариях запретить определенным нодам запускать у себя поды. Для применения taint к конкретному узлу нужно использовать опцию taint в kubectl. Укажите ключ и значение, а затем taint вроде NoSchedule или NoExecute:
$ kubectl taint nodes node10 node-role.kubernetes.io/ingress=true:NoScheduleТакже стоит отметить, что механизм taint поддерживает три основных эффекта: NoSchedule, NoExecute и PreferNoSchedule.
NoScheduleозначает, что пока в спецификации пода не будет соответствующей записиtolerations, он не сможет быть развернут на ноде (в данном примереnode10).PreferNoSchedule— упрощённая версияNoSchedule. В этом случае планировщик попытается не распределять поды, у которых нет соответствующей записиtolerationsна ноду, но это не жёсткое ограничение. Если в кластере не окажется ресурсов, то поды начнут разворачиваться на этой ноде.NoExecute— этот эффект запускает немедленную эвакуацию подов, у которых нет соответствующей записиtolerations.
Любопытно, что такое поведение можно отменить с помощью механизма tolerations. Это удобно, когда есть «запрещенная» нода и вам понадобилось разместить на ней только инфраструктурные сервисы. Как это сделать? Разрешить только те поды, для которых есть подходящий toleration.
Вот как будет выглядеть спецификация пода:
spec:
tolerations:
- key: "node-role.kubernetes.io/ingress"
operator: "Equal"
value: "true"
effect: "NoSchedule"Это не значит, что при следующем редеплое под попадет именно на эту ноду, это не механизм Node Affinity и nodeSelector. Но комбинируя несколько фич, вы можете добиться очень гибкой настройки планировщика.
8. Настройте приоритет развертывания подов
То, что вы настроили привязку подов к нодам, не означает, что все поды должны обрабатываться с одинаковым приоритетом. Например, вы можете захотеть развёртывать какие-то поды раньше остальных.
Kubernetes предлагает разные способы настройки приоритетности подов (Pod Priority and Preemption). Настройка состоит из нескольких частей: объекта PriorityClassи описания поля priorityClassNameв спецификации пода. Рассмотрим пример:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 99999
globalDefault: false
description: "This priority class should be used for very important pods only"Мы создаем PriorityClass, задаем ему имя, описание и значение.Чем выше value, тем выше приоритет. Значение может быть любым 32-битным целым числом, меньше или равным 1 000 000 000. Более высокие значения зарезервированы для критически важных системных подов, которые, как правило, не могут быть вытеснены.Вытеснение будет происходить только если высокоприоритетному поду негде будет развернуться, тогда часть подов с определенной ноды будут эвакуированы. Если для вас этот механизм слишком жёсткий, то можно добавить опцию preemptionPolicy: Never, и тогда вытеснения не будет, под будет стоять первым в очереди и ждать, когда планировщик найдёт для него свободные ресурсы.
Далее мы создаем под, в котором указываем имя priorityClassName:
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
priorityClassName: high-priority
Можно создавать сколько угодно классов приоритетности, хотя рекомендуется не увлекаться этим (скажем, ограничиться низким, средним и высоким приоритетом).
Таким образом, в случае необходимости вы сможете повысить эффективность развёртывания критичных сервисов, таких как nginx-ingress-controller, coredns и т.п.
9. Оптимизируйте ETCD-кластер

ETCD можно назвать мозгом всего кластера. Очень важно поддерживать работу этой БД на высоком уровне, так как именно от нее зависит скорость операций в «Кубе». Достаточно стандартным, и в то же время неплохим решением будет держать кластер ETCD на мастер-нодах, чтобы иметь минимальную задержку до kube-apiserver. Если не получается так сделать, то располагайте ETCD как можно ближе, имея хорошую пропускную способность между участниками. Также обращайте внимание на то, сколько нод из ETCD может выпасть без вреда для кластера
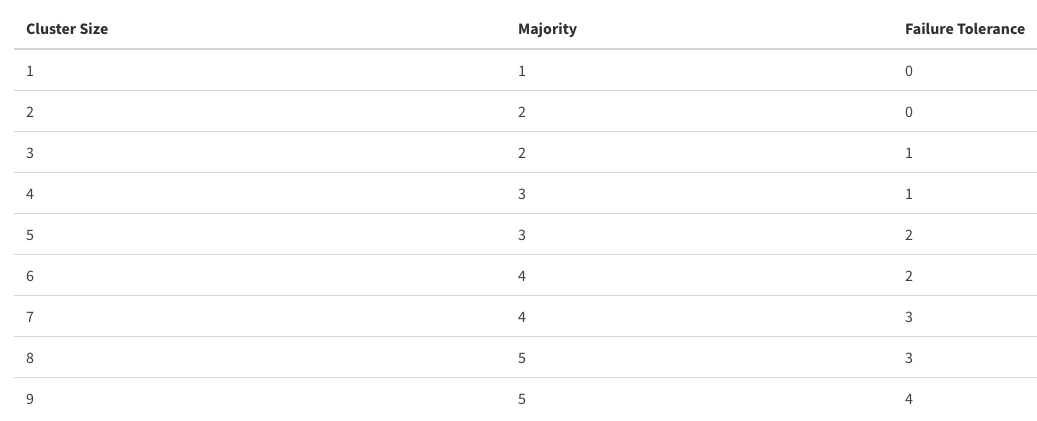
Имейте в виду, что чрезмерное увеличение количества участников в кластере может повысить отказоустойчивость в ущерб производительности, всё должно быть в меру.
Если говорить о настройке сервиса, то рекомендаций немного:
Иметь хорошее железо, исходя из размеров кластера (можно почитать тут).
Подкрутить несколько параметров, если вы размазали кластер между парой ДЦ или ваша сеть и диски оставляют желать лучшего (можно почитать тут).
Заключение
В этой статье описаны пункты, которые наша команда старается соблюдать. Это не пошаговое описание действий, а варианты, которые могут пригодиться для оптимизации накладных расходов на кластер. Понятно, что каждый кластер по-своему уникален, и решения по настройке могут сильно разниться, поэтому было бы интересно получить от вас обратную связь: как вы следите за своим кластером Kubernetes, с помощью чего вы улучшаете его работу. Делитесь своим опытом в комментариях, будет интересно его узнать.
