LLVM: компилятор своими руками. Введение
Представим себе, что в один прекрасный день вам пришла в голову идея процессора собственной, ни на что не похожей архитектуры, и вам очень захотелось эту идею реализовать «в железе». К счастью, в этом нет ничего невозможного. Немного верилога, и вот ваша идея реализована. Вам уже снятся прекрасные сны про то, как Intel разорилась, Microsoft спешно переписывает Windows под вашу архитектуру, а Linux-сообщество уже написало под ваш микропроцессор свежую версию системы с весьма нескучными обоями.
Однако, для всего этого не хватает одной мелочи: компилятора!
Да, я знаю, что многие не считают наличие компилятора чем-то важным, считая, что все должны программировать строго на ассемблере. Если вы тоже так считаете, я не буду с вами спорить, просто не читайте дальше.
Если вы хотите, чтобы для вашей оригинальной архитектуры был доступен хотя бы язык С, прошу под кат.
В статье будет рассматриваться применение инфраструктуры компиляторов LLVM для построения собственных решений на её основе.
Область применения LLVM не ограничивается разработкой компиляторов для новых процессоров, инфраструктура компиляторов LLVM также может применяться для разработки компиляторов новых языков программирования, новых алгоритмов оптимизации и специфических инструментов статического анализа программного кода (поиск ошибок, сбор статистики и т.п.).
Например, вы можете использовать какой-то стандартный процессор (например, ARM) в сочетании с специализированным сопроцессором (например, матричный FPU), в этом случае вам может понадобиться модифицировать существующий компилятор для ARM так, чтобы он мог генерировать код для вашего FPU.
Также интересным применением LLVM может быть генерация исходных текстов на языке высокого уровня («перевод» с одного языка на другой). Например, можно написать генератор кода на Verilog по исходному коду на С.

КДПВ
Почему LLVM?
На сегодняшний день существует только два реалистичных пути разработки компилятора для собственной архитектуры: использование GCC либо использование LLVM. Другие проекты компиляторов с открытым исходным кодом либо не достигли той степени развития, как GCC и LLVM, либо устарели и перестали развиваться, они не обладают развитыми алгоритмами оптимизации, и могут не обеспечивать полной совместимости даже со стандартом языка С, не говоря уже о поддержке других языков программирования. Разработка собственного компилятора «с нуля», это весьма нерациональный путь, т.к. существующие опенсорсные решения уже реализуют фронтенд компилятора с множеством весьма нетривиальных алгоритмов оптимизации, которые, к тому же, хорошо протестированы и используются уже длительное время.
Какой из этих двух open-source проектов выбрать в качестве основы для своего компилятора? GCC (GNU Compiler Collection) является более старым проектом, первый релиз которого состоялся в 1987 году, его автором является Ричард Столлман, известный деятель open-source движения [4]. Он поддерживает множество языков программирования: C, C++, Objective C, Fortran, Java, Ada, Go. Также существуют фронтенды для многих других языков программирования, не включенных в основную сборку. Компилятор GCC поддерживает большое количество процессорных архитектур и операционных систем, и является в настоящее время наиболее распространённым компилятором. Сам GCC написан на языке С.
LLVM гораздо «моложе», его первый релиз состоялся в 2003 году, он (а точнее, его фронтенд Clang) поддерживает языки программирования C, C++, Objective-C and Objective-C++, и также имеет фронтенды для языков Common Lisp, ActionScript, Ada, D, Fortran, OpenGL Shading Language, Go, Haskell, Java bytecode, Julia, Swift, Python, Ruby, Rust, Scala, C# и Lua. Он разработан в университете Иллинойса, в США, и является основным компилятором для разработки под операционную систему OS X. LLVM написан на языке С++ (С++11 для последних релизов) [5].
Относительная «молодость» LLVM не является недостатком, он достаточно зрелый, чтобы в нём не было критических багов, и при этом он не несёт в себе огромного груза устаревших архитектурных решений, как GCC. Модульная структура компилятора позволяет использовать фронтенд LLVM-GCC, который обеспечивает полную поддержку стандартов GCC, при этом генерация кода целевой платформы будет осуществляться LLC (бэкенд LLVM). Также можно использовать Clang — оригинальный фронтенд LLVM.
LLVM хорошо документирован, и для него большое количество примеров кода.
Модульная архитектура компилятора
Инфраструктура компиляторов LLVM состоит из различных инструментов, рассматривать их все в рамках данной статьи не имеет смысла. Ограничимся основными инструментами, которые образуют как таковой компилятор.
Компилятор LLVM, как и некоторые другие компиляторы, состоит из фронтенда, оптимизатора (миддленда), и бэкенда. Такая структура позволяет разделить разработку компилятора нового языка программирования, разработку методов оптимизации и разработку кодогенератора для конкретного процессора (такие компиляторы называют «перенацеливаемыми», retargetable).
Связующим звеном между ними является промежуточный язык LLVM, ассемблер «виртуальной машины». Фронтенд (например, Clang) преобразует текст программы на языке высокого уровня в текст на промежуточном языке, оптимизатор (opt) производит над ним различные оптимизации, а бэкенд (llc) генерирует код целевого процессора (на ассемблере или непосредственно в виде бинарного файла). Помимо этого, LLVM может работать в режиме JIT (just-in-time) компиляции, когда компиляция происходит непосредственно во время исполнения программы.
Промежуточное представление программы может быть как в виде текстового файла на языке ассемблера LLVM, так и в виде двоичного формата, «биткода». По умолчанию clang генерирует именно биткод (файл .bc), но для отладки и изучения LLVM нам нужно будет генерировать текстовое промежуточное представление на ассемблере LLVM (он также называется IR-кодом, от слов Intermediate Representation, промежуточное представление).
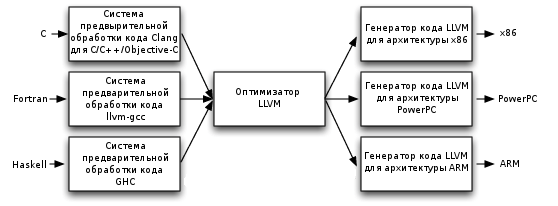
Рис. 1. Модульная архитектура компилятора
Кроме вышеперечисленных программ, LLVM включает в себя и другие утилиты [6].
Итак, напишем простейшую программу на C.
int foo(int x, int y) {
return x + y;
}
И скомпилируем её: clang-3.5 -c add.c -O0 --target=xcore -emit-llvm -S -o add_o0.ll
Некоторые пояснения:
-c add.c — входной файл;
-O0 — уровень оптимизации 0, оптимизация отсутствует;
--target=xcore — ядро процессора xcore не имеет каких-либо сложных особенностей при компиляции в IR-код, поэтому является идеальным объектом для исследований. Это ядро имеет разрядность 32, и clang выравнивает все переменные по границам 32-битных слов;
-emit-llvm -S — указание clang-у сгенерировать файл llvm в текстовом виде (на ассемблере LLVM);
-o add_o0.ll — выходной файл
Посмотрим на результат: ; ModuleID = 'add.c'
target datalayout = "e-m:e-p:32:32-i1:8:32-i8:8:32-i16:16:32-i64:32-f64:32-a:0:32-n32"
target triple = "xcore"
; Function Attrs: nounwind
define i32 @foo(i32 %x, i32 %y) #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 %x, i32* %1, align 4
store i32 %y, i32* %2, align 4
%3 = load i32* %1, align 4
%4 = load i32* %2, align 4
%5 = add nsw i32 %3, %4
ret i32 %5
}
attributes #0 = { nounwind "less-precise-fpmad"="false" "no-frame-pointer-elim"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "stack-protector-buffer-size"="8" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.ident = !{!0}
!xcore.typestrings = !{!1}
!0 = metadata !{metadata !"Ubuntu clang version 3.5.0-4ubuntu2~trusty2 (tags/RELEASE_350/final) (based on LLVM 3.5.0)"}
!1 = metadata !{i32 (i32, i32)* @foo, metadata !"f{si}(si,si)"}
Выглядит довольно сложно, не так ли? Однако давайте разберёмся, что тут написано. Итак:
target datalayout = «e-m: e-p:32:32-i1:8:32-i8:8:32-i16:16:32-i64:32-f64:32-a:0:32-n32»
описание разрядности переменных и самых основных особенностей архитектуры. e- little-endian архитектура. Для big-endian здесь была бы буква E. m: e — mangling, соглашение о преобразовании имён. Нам пока это не понадобится. p:32:32 — указатели имеют 32 бита и выровнены по границам 32-битных слов. i1:8:32 — булевые переменные (i1) выражаются 8-ибитными значениями и выровнены по границам 32-битных слов. Далее аналогично для целочисленных переменных i8 — i64 (от 8 до 64 бит соответственно), и f64 — для вещественных переменных двойной точности. a:0:32 — агрегатные переменные (т.е. массивы и структуры) имеют выравнивание 32 бита, n32 — разрядность чисел, обрабатываемых АЛУ процессора (native integer width).
Далее следует название таргета (т.е. целевого процессора): target triple = «xcore». Хотя код IR часто называют «машинно-независимым», на самом деле мы видим, это не так. Он отражает некоторые особенности целевой архитектуры. Это является одной из причин, по которой мы должны указывать целевую архитектуру не только для бэкенда, но и для фронтенда.
Далее следует код функции foo: define i32 @foo(i32 %x, i32 %y) #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
store i32 %x, i32* %1, align 4
store i32 %y, i32* %2, align 4
%3 = load i32* %1, align 4
%4 = load i32* %2, align 4
%5 = add nsw i32 %3, %4
ret i32 %5
}
Код довольно громоздкий, хотя исходная функция очень проста. Вот что он делает.
Сразу отметим, что все имена переменных в LLVM имеют префикс либо % (для локальных переменных), либо @ — для глобальных. В данном примере все переменные локальные.
%1 = alloca i32, align 4 — выделяет на стеке 4 байта для переменной, указателем на эту область является указатель %1.
store i32%x, i32* %1, align 4 — копирует в выделенную область один из аргументов функции (%x).
%3 = load i32* %1, align 4 — извлекает значение в переменную %3. Теперь в %3 хранится локальная копия %x.
Делает то же самое для аргумента %y
%5 = add nsw i32%3, %4 — складывает локальные копии %x и %y, помещает результат в %5. Есть ещё атрибут nsw, но он пока для нас не важен.
Возвращает значение %5.
Из приведённого примера видно, что при нулевом уровне оптимизации clang генерирует код, буквально следуя исходному коду, создаёт локальные копии всех аргументов и не делает каких-либо попыток удалить избыточные команды. Это может показаться плохим свойством компилятора, но на самом деле это очень полезная особенность при отладке программ и при отладке кода самого компилятора.
Посмотрим, что произойдёт, если поменять уровень оптимизации на O1: define i32 @foo(i32 %x, i32 %y) #0 {
%1 = add nsw i32 %y, %x
ret i32 %1
}
Мы видим, что ни одной лишней команды не осталось. Теперь программа складывает непосредственно аргументы функции и возвращает результат.
Есть и более высокие уровни оптимизации, но в этом конкретном случае они не дадут лучшего результата, т.к. максимальный уровень оптимизации уже достигнут.
Остальная часть LLVM-кода (атрибуты, метаданные), несёт в себе служебную информацию, которая пока нам неинтересна.
Структура кода LLVM
Структура кода LLVM очень проста. Код программы состоит из модулей, компилятор обрабатывает по одному модулю за раз. В модуле есть глобальные объявления (переменные, константы и объявления заголовков функций, находящихся в других модулях) и функции. Функции имеют аргументы и возвращаемые типы. Функции состоят из базовых блоков. Базовый блок — это последовательность команд ассемблера LLVM, имеющая одну точку входа и одну точку выхода. Базовый блок не содержит внутри себя никаких ветвлений и циклов, он выполняется строго последовательно от начала до конца и должен заканчиваться терминирующей командой (возвратом из функции или переходом на другой блок).
И, наконец, базовый блок состоит из команд ассемблера. Список команд приведён в документации на LLVM [7].
Итак, ещё раз: базовый блок имеет одну точку входа, помеченную меткой, и обязательно должен заканчиваться командой безусловного перехода br или командой возврата ret. Перед ними может быть команда условного перехода, в этом случае она должна быть непосредственно перед терминирующей командой. Базовый блок имеет список predecessors — базовых блоков, из которых управление может приходить на него, и successors — базовых блоков, которым он может передавать управление. На основе этой информации строится CFG — Control Flow Graph, граф потока управления, важнейшая структура, представляющая программу в компиляторе.
Рассмотрим тестовый пример на языке С:
Пусть исходный код на языке С имеет цикл:
//функция вычисляет сумму 10 элементов массива
int for_loop(int x[]) {
int sum = 0;
for(int i = 0; i < 10; ++i) {
sum += x[i];
}
return sum;
}
Его CFG имеет вид: 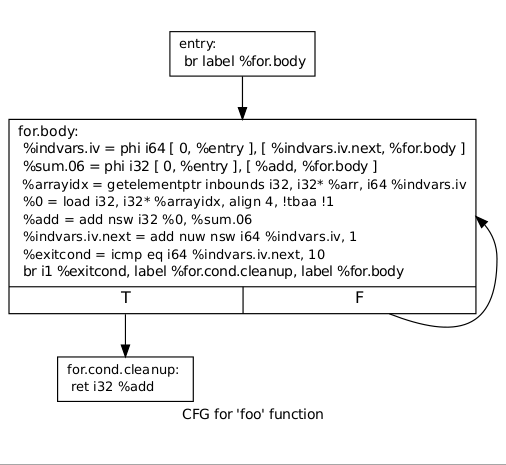
Ещё одним видом графов в LLVM является DAG — directed acyclic graph, направленный ациклический граф, представляющий собой базовый блок.
Он представляет команды ассемблера и зависимости между ними. На рисунке ниже приведён DAG базового блока, представляющий тело цикла в примере выше, при уровне оптимизации -O1: 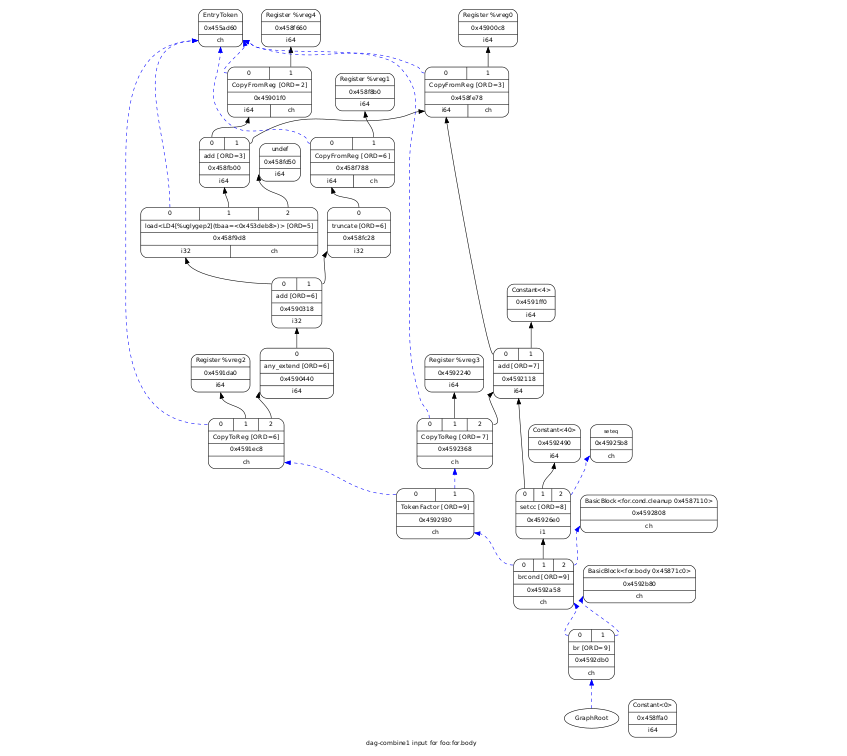
SSA-форма
Ключевой особенностью IR-кода, отличающей его от языков высокого уровня является то, что он представлен в так называемой SSA-форме (Static Single Assignment form). Эта особенность очень важна для понимания при разработке компилятора на платформе LLVM, поэтому уделим ей некоторое внимание. Если формулировать кратко, то в SSA-форме каждой переменной значение присваивается ровно один раз и только в одной точке программы. Все алгоритмы оптимизации и преобразования IR-кода работают только с такой формой.
Однако, как преобразовать обычную программу на языке высокого уровня в такую форму? Ведь в обычных языках программирования значение переменной может присваиваться несколько раз в разных местах программы, или, например, в цикле.
Для реализации такого поведения программы используется один из двух приемов. Первый прием заключается в использовании пар команд load/store, как в вышеприведённом коде. Ограничение единственного присваивания распространяется только на именованные переменные LLVM, и не распространяется на ячейки памяти, на которые ссылаются указатели. То есть, можно неограниченное количество раз производить запись в ячейку памяти командой store, и формальное правило SSA будет соблюдено, так как указатель на эту ячейку не меняется. Этот способ используется обычно при уровне оптимизации -O0, и мы не будем на нём подробно останавливаться. Второй прием использует φ-функции, ещё одну интересную концепцию IR-кода.
Код в SSA-форме: load/store
Воспользуемся тестовым примером из предыдущего раздела.
Скомпилируем с уровнем оптимизации -O0: define i32 @for_loop(i32* %x) #0 {
%1 = alloca i32*, align 4
%sum = alloca i32, align 4
%i = alloca i32, align 4
store i32* %x, i32** %1, align 4
store i32 0, i32* %sum, align 4
store i32 0, i32* %i, align 4
br label %2
; :2 ; preds = %12, %0
%3 = load i32* %i, align 4
%4 = icmp slt i32 %3, 10
br i1 %4, label %5, label %15
; :5 ; preds = %2
%6 = load i32* %i, align 4
%7 = load i32** %1, align 4
%8 = getelementptr inbounds i32* %7, i32 %6
%9 = load i32* %8, align 4
%10 = load i32* %sum, align 4
%11 = add nsw i32 %10, %9
store i32 %11, i32* %sum, align 4
br label %12
; :12 ; preds = %5
%13 = load i32* %i, align 4
%14 = add nsw i32 %13, 1
store i32 %14, i32* %i, align 4
br label %2
; :15 ; preds = %2
%16 = load i32* %sum, align 4
ret i32 %16
}
Здесь мы видим то, о чем было написано выше: переменная цикла, это просто ячейка памяти, на которую ссылается указатель %i.
Код в SSA-форме: φ-функции
Теперь попробуем уровень оптимизации O1: define i32 @for_loop(i32* nocapture readonly %x) #0 {
br label %1
; :1 ; preds = %1, %0
%i.02 = phi i32 [ 0, %0 ], [ %5, %1 ]
%sum.01 = phi i32 [ 0, %0 ], [ %4, %1 ]
%2 = getelementptr inbounds i32* %x, i32 %i.02
%3 = load i32* %2, align 4, !tbaa !2
%4 = add nsw i32 %3, %sum.01
%5 = add nsw i32 %i.02, 1
%exitcond = icmp eq i32 %5, 10
br i1 %exitcond, label %6, label %1
; :6 ; preds = %1
ret i32 %4
}
Здесь мы видим, что переменной цикла является %i.02 (имена переменных в LLVM могут содержать точки), и это не указатель, а обычная 32-битная переменная, а присваивание значения происходит с помощью функции phi i32 [ 0, %0 ], [ %5, %1 ]. Это означает, что функция примет значение 0, если переход произошёл с базового блока %0 (первый базовый блок в функции), и значение переменной %5, если переход произошёл с базового блока %1 (т.е. с выходной точки этого же базового блока). Таким образом, генератор IR-кода избавился от двух присваиваний переменной, строго следуя формальным правилам SSA. Далее видно, что сходным образом происходит присваивание переменной %sum.01.
Итак, смысл φ-функции состоит в том, что её значение зависит от того, из какого базового блока был произведён переход на неё. φ-функции могут находиться только в начале базового блока. Если их несколько, они должны следовать непрерывно, начиная с первой инструкции базового блока.
Moar optimization!
Что будет при уровне оптимизации -O2? define i32 @for_loop(i32* nocapture readonly %x) #0 {
%1 = load i32* %x, align 4, !tbaa !2
%2 = getelementptr inbounds i32* %x, i32 1
%3 = load i32* %2, align 4, !tbaa !2
%4 = add nsw i32 %3, %1
%5 = getelementptr inbounds i32* %x, i32 2
%6 = load i32* %5, align 4, !tbaa !2
%7 = add nsw i32 %6, %4
%8 = getelementptr inbounds i32* %x, i32 3
%9 = load i32* %8, align 4, !tbaa !2
%10 = add nsw i32 %9, %7
%11 = getelementptr inbounds i32* %x, i32 4
%12 = load i32* %11, align 4, !tbaa !2
%13 = add nsw i32 %12, %10
%14 = getelementptr inbounds i32* %x, i32 5
%15 = load i32* %14, align 4, !tbaa !2
%16 = add nsw i32 %15, %13
%17 = getelementptr inbounds i32* %x, i32 6
%18 = load i32* %17, align 4, !tbaa !2
%19 = add nsw i32 %18, %16
%20 = getelementptr inbounds i32* %x, i32 7
%21 = load i32* %20, align 4, !tbaa !2
%22 = add nsw i32 %21, %19
%23 = getelementptr inbounds i32* %x, i32 8
%24 = load i32* %23, align 4, !tbaa !2
%25 = add nsw i32 %24, %22
%26 = getelementptr inbounds i32* %x, i32 9
%27 = load i32* %26, align 4, !tbaa !2
%28 = add nsw i32 %27, %25
ret i32 %28
}
Оптимизатор развернул цикл. Вообще, оптимизатор IR-кода в LLVM очень интеллектуален, он умеет не только разворачивать циклы, но и упрощать нетривиальные конструкции, вычислять константные значения, даже если они не присутствуют в коде в явном виде, и делать другие сложные преобразования кода.
Компоновка IR-кода
Реальные программы состоят не из одного модуля. Традиционный компилятор компилирует модули по отдельности, превращая их в объектные файлы, а затем передаёт их компоновщику (линкеру), который объединяет их в один исполняемый файл. LLVM тоже позволяет так делать.
Но LLVM имеет также возможность компоновки IR-кода. Проще всего рассмотреть это на примере. Пусть есть два исходных модуля: foo.c и bar.c:
//bar.h
#ifndef BAR_H
#define BAR_H
int bar(int x, int k);
#endif
//bar.c
int bar(int x, int k) {
return x * x * k;
}
//foo.c
#include "bar.h"
int foo(int x, int y) {
return bar(x, 2) + bar(y, 3);
}
Если программа будет скомпилирована «традиционным» образом, то оптимизатор не сможет сделать с ней практически ничего: при компиляции foo.c компилятор не знает, что находится внутри функции bar, и может поступить единственным очевидным способом, вставить вызовы bar ().
Но если мы скомпонуем IR-код, то мы получим один модуль, который после оптимизации с уровнем -O2 будет выглядеть так (для ясности заголовок модуля и метаданные опущены): define i32 @foo(i32 %x, i32 %y) #0 {
%1 = shl i32 %x, 1
%2 = mul i32 %1, %x
%3 = mul i32 %y, 3
%4 = mul i32 %3, %y
%5 = add nsw i32 %4, %2
ret i32 %5
}
; Function Attrs: nounwind readnone
define i32 @bar(i32 %x, i32 %k) #0 {
%1 = mul nsw i32 %x, %x
%2 = mul nsw i32 %1, %k
ret i32 %2
}
Здесь видно, что в функции foo не происходит никаких вызовов, компилятор перенёс в неё содержимое bar () полностью, попутно подставив константные значения k. Хотя функция bar () осталась в модуле, она будет исключена при компиляции исполняемого файла, при условии, что она не вызывается нигде больше в программе.
Нужно отметить, что в GCC также есть возможность компоновки и оптимизации промежуточного кода (LTO, link-time optimization) [6].
Разумеется, оптимизация в LLVM не исчерпывается оптимизацией IR-кода. Внутри бэкенда также происходят различные оптимизации на разных стадиях преобразования IR-кода в машинное представление. Часть таких оптимизаций LLVM производит самостоятельно, но разработчик бэкенда может (и должен) разработать собственные алгоритмы оптимизации, которые позволят в полной мере использовать особенности архитектуры процессора.
Генерация кода целевой платформы
Разработка компилятора для оригинальной архитектуры процессора, это, в основном, разработка бэкенда. Вмешательство в алгоритмы фронтенда, как правило, не является необходимым, или, во всяком случае, требует весьма веских оснований. Если проанализировать исходный код Clang, можно увидеть, что большая часть «особенных» алгоритмов приходится на процессоры x86 и PowerPC с их нестандартными форматами вещественных чисел. Для большинства других процессоров нужно указать только размеры базовых типов и endianness (big-endian или little-endian). Чаще всего можно просто найти аналогичный (в плане разрядности) процессор среди множества поддерживаемых.
Генерация кода для целевой платформы происходит в бэкенде LLVM, LLC. LLC поддерживает множество различных процессоров, и вы можете на его основе сделать генератор кода для вашего собственного оригинального процессора. Эта задача упрощается ещё и благодаря тому, что весь исходный код, включая модули для каждой поддерживаемой архитектуры, полностью открыт и доступен для изучения.
Именно генератор кода для целевой платформы (таргета) является наиболее трудоёмкой задачей при разработке компилятора на основе инфрастуктуры LLVM. Я решил не останавливаться подробно здесь на особенностях реализации бэкенда, так как они существенным образом зависят от архитектуры целевого процессора. Впрочем, если у уважаемой аудитории хабра возникнет интерес к данной теме, я готов описать ключевые моменты разработки бэкенда в следующей статье.
Заключение
В рамках небольшой статьи нельзя рассмотреть подробно ни архитектуру LLVM, ни синтаксис языка LLVM IR, ни процесс разработки бэкенда. Однако эти вопросы подробно освещаются в документации. Автор скорее старался дать общее представление об инфраструктуре компиляторов LLVM, сделав упор на то, что эта платформа является современной, мощной, универсальной, и независимой ни от входного языка, ни от целевой архитектуры процессора, позволяя реализовать и то, и другое по желанию разработчика.
Помимо рассмотренных, LLVM содержит и другие утилиты, однако их рассмотрение выходит за рамки статьи.
LLVM позволяет реализовать бэкенд для любой архитектуры (см. примечание), включая архитектуры с конвейеризацией, с внеочередным выполнением команд, с различными вариантами параллелизации, VLIW, для классических и стековых архитектур, в общем, для любых вариантов.
Вне зависимости от того, насколько нестандартные решения лежат в основе процессорной архитектуры, это всего лишь вопрос написания большего или меньшего объёма кода.
для любой, в пределах разумного. Вряд ли возможно реализовать компилятор языка С для 4-хбитной архитектуры, т.к. стандарт языка явно требует, чтобы разрядность была не меньше 8.
Литература

Компиляторы
[1] Книга дракона
[2] Вирт Н. Построение компиляторов
GCC
[3] gcc.gnu.org — сайт проекта GCC
[4] Richard M. Stallman and the GCC Developer Community. GNU Compiler Collection Internals
LLVM
[5] http://llvm.org/ — сайт проекта LLVM
[6] http://llvm.org/docs/GettingStarted.html Getting Started with the LLVM System
[7] http://llvm.org/docs/LangRef.html LLVM Language Reference Manual
[8] http://llvm.org/docs/WritingAnLLVMBackend.html Writing An LLVM Backend
[9] http://llvm.org/docs/WritingAnLLVMPass.html Writing An LLVM Pass
[10] Chen Chung-Shu. Creating an LLVM Backend for the Cpu0 Architecture
[11] Mayur Pandey, Suyog Sarda. LLVM Cookbook
[12] Bruno Cardoso Lopes. Getting Started with LLVM Core Libraries
[13] Suyog Sarda, Mayur Pandey. LLVM Essentials
Автор будет рад ответить на ваши вопросы в комментариях и в личке.
Просьба обо всех замеченных опечатках сообщать в личку. Заранее спасибо.
