Linux на esp32s3
Вопрос о том, можно ли загрузить линукс на микроконтроллерах Espressif я впервые услышал в 2015, в период бума esp8266. Тогда мой ответ на него был: «нет, не это ядро и не на этом железе». Но прошло 8 лет и ответ изменился на «да, и у меня есть рабочий пример». Дальше рассказ о том, как это произошло.
esp8266
Однозначный ответ «нет, невозможно» на вопрос о запуске linux на esp8266 в 2015 был продиктован тем, что версия ядра 4.0 бывшая тогда в разработке, как и все версии до неё, ожидала процессор xtensa с поддержкой регистровых окон, в то время как у процессорного ядра esp8266 нет этой опции и всего 16 регистров общего назначения. Это, однако, была сугубо программная проблема, решение для которой очевидно: просмотреть и исправить все ассемблерные исходники относящиеся к архитектуре xtensa в ядре, добавив поддержку ещё одного ABI, перекомпилировать код на C с другими опциями компилятора и добавить логику в те места, которые готовят структуры в памяти, зависящие от ABI. Первоначально это казалось большим и сложным делом, но в итоге уложилось в десяток патчей, около 800 изменённых строк, вошедших в релиз ядра v5.18.
Однако, считая проблему регистровых окон разрешимой, мы сталкиваемся со следующей проблемой: в esp8266 совсем мало оперативной памяти: 32КБ программной памяти и 80КБ памяти данных (да, у реализации xtensa гарвардская архитектура и доступ к программной памяти и памяти данных устроен существенно по-разному). Что можно сделать с этим? Собрать ядро в минимальной конфигурации и посмотреть, сколько ему требуется памяти. У меня не получилось уложиться меньше чем в 800КБ кода и 300КБ статических данных, что далеко выходит за пределы имеющейся памяти, даже если научиться запускать код прямо из FLASH. И неисследованное направление: возможно к esp8266 можно подключить внешнюю RAM, я, однако, не слышал об успешных попытках это сделать.
esp32, часть 1: XIP-ядро
В следующий раз вопрос из топика настиг меня в 2018, уже касательно esp32 со внешней памятью. Оказалось, что даже имея 8МБ PSRAM на борту, esp32 может одновременно отображать в адресное пространство процессора максимум 4МБ. С этим уже можно было работать: экспериментальным путём удалось выяснить, что xtensa linux вполне стартует в QEMU с 3МБ RAM. Задачей было научиться запускать код ядра напрямую из FLASH, чтобы максимизировать доступную память для динамического распределения, т.е. реализовать технологию известную как XIP (eXecute In Place). Это оказалось не так уж сложно, основное изменение состоит в том, что статические данные ядра выделяются в отдельный сегмент, который при старте копируется из FLASH в RAM, после чего эта область RAM помечается как зарезервированная. Полноценный XIP подразумевает также возможность для ядра записывать данные обратно во FLASH с которого оно запущено, для чего часть кода ядра управляющая записью и обрабатывающая прерывания в это время должна выполняться из оперативной памяти. Я сделал несколько шагов в этом направлении (1, 2, ещё несколько пока не в мейнлайне), но пока поддержка этой возможности не готова.
Главным результатом было то, что имея XIP-ядро можно было посмотреть на то, как поведёт себя юзерспейс. Но единственным поддерживаемым на тот момент форматом исполняемых файлов для xtensa linux без MMU был статический bFLT с релокациями в сегменте кода, а это значит, что исполняемые файлы должны полностью загружаться в RAM, выполняться оттуда и содержать в себе все нужные им библиотечные функции. Мне удалось загрузить XIP-ядро и запустить в нём один экземпляр оболочки hush реализованной busybox в QEMU с 4МБ памяти, но попытка запустить любую другую программу из этой оболочки уже вызывала OOM-киллер. Я из этого сделал вывод, что без поддержки FDPIC ELF продолжать заниматься этим бесполезно, а реализация этой поддержки в тулчейне в тот момент казалась мне слишком сложным делом.
esp32, часть 2: risc-v линукс в эмуляторе
Очередная волна интереса к топику дошла до меня в 2021 со следующим кликбейтным заголовком: «Linux 5.0 shown to boot on ESP32 processor». Это был risc-v linux в эмуляторе и его загрузка длилась несколько часов, на этом фоне меня удивило количество внимания которое этому событию было посвящено. Тем не менее, это подтолкнуло меня к тому чтобы озаботиться загрузкой ядра xtensa linux на реальном esp32 чтобы посмотреть на его скорость. На тот момент для этого не хватало начального загрузчика (т.е. прошивки для esp32 которая могла бы подготовить железо для запуска ядра и запустить его) и ядерного драйвера для UART.
esp32, часть 3: начальный загрузчик и ядро на реальном железе
Для первого начального загрузчика я взял за основу пример hello_world из Espressif IDF, настроил использование PSRAM, отобразил (или, по крайней мере, попытался отобразить) блоки FLASH и PSRAM по фиксированным адресам вызовами функции cache_flash_mmu_set и добавил переход по адресу по которому во FLASH записано ядро.
Для драйвера UART я взял общую структуру из драйвера Freescale LINFlexD, выкинул весь код и реализовал минимальные функции вывода, в том числе такие, которые можно было бы вызывать на самых ранних стадиях загрузки ядра. Понатыкав отладочной печати в процесс инициализации я довольно быстро выяснил то, что теоретически и так давно знал — что из программной памяти нельзя загружать байты и двухбайтные слова, а можно обращаться только к выровненным 32-битным словам (привет ещё раз, гарвардская архитектура). В результате пришлось сдуть пыль со своего древнего патча -mforce-l32 для gcc и пересобрать тулчейн с ним, а также опять прошерстить ассемблерные исходники и поправить все явные загрузки 8- и 16-битных значений. После этого я увидел следующую прекрасную картину:
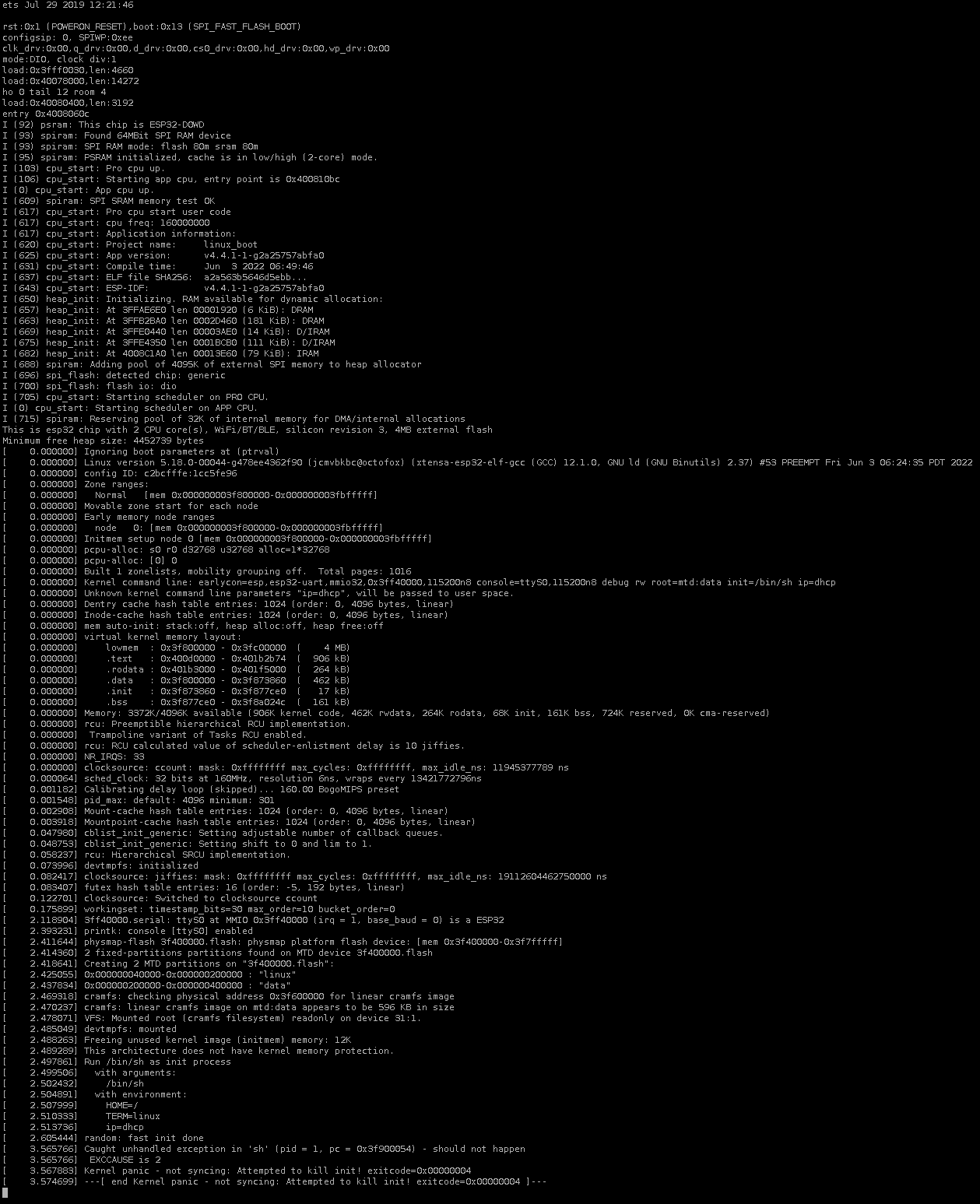
Лог загрузки ядра xtensa linux-5.18 на esp32
Да, временная метка 3.5 секунды в конце лога — это реальное время загрузки. И, да, это был тупик, дальше можно было продвинуться только добавив поддержку FDPIC ELF в тулчейн.
Форматы исполняемых файлов
Для понимания проблемы с юзерспейсом, её предлагаемого решения и связанных с этим сложностей мы немного погрузимся в технические детали форматов исполняемых файлов linux.
PDE ELF
Как устроен обычный для linux с MMU исполняемый ELF-файл (так называемый PDE, position-dependent executable) с точки зрения загрузки для выполнения? Это группа сегментов кода и данных, которые должны попасть в адресное пространство процесса по фиксированным адресам записанным в ELF program header. Почему это работает в linux с MMU? Потому что у каждого процесса своё адресное пространство, изначально (в момент вызова exec) свободное. Какой бы адрес ни был выбран для исполняемого файла при его линковке, этот адрес будет свободен при загрузке в процесс нового исполняемого образа. Почему это не работает в linux без MMU? Потому что ядро и все запущенные процессы разделяют одно общее адресное пространство. Нельзя ожидать, что фиксированный адрес выбранный во время линковки будет доступен процессу. Нельзя даже ожидать, что там будет память, поскольку в отсутствие виртуальной адресации мы вынуждены работать с физической памятью напрямую, а она может быть подключена весьма причудливым образом. Какие существуют выходы из этой ситуации?
bFLT
Существует формат bFLT (binary flat). Для него нет исчерпывающего описания как для ELF, но в сети можно найти довольно полезные документы, например вот или вот. Как устроен исполняемый файл bFLT с точки зрения загрузки для выполнения? Это группа сегментов кода и данных плюс таблица записей о релокациях. Сегменты могут быть загружены по произвольным (выровненным) адресам, после чего указатели расположенные по смещениям записанным в таблице релокаций нужно подправить, добавив к ним базовые адреса по которым были загружены сегменты на которые они ссылаются. Что хорошего в этом решении? Оно простое. Существует инструмент elf2flt, который встраивается в процесс линковки elf-тулчейна и генерирует исполняемые файлы bFLT в довесок к обычным ELF. Поддержка bFLT интегрирована в buildroot, что позволяет с минимальными усилиями сгенерировать образ rootfs. К сожалению у этого решения есть несколько существенных недостатков. Два главных недостатка bFLT, на мой взгляд — принципиальная невозможность использовать его с NPTL (native posix thread library), поскольку формат не поддерживает TLS (thread local storage) и отсутствие вменяемых механизмов динамической линковки, что делает статические бинарники единственной доступной опцией. Кроме того, хотя bFLT и поддерживает загрузку сегментов кода и данных по независимым адресам, из-за особенностей тулчейна xtensa сегмент кода требует релокаций, а это значит что одна копия кода не может разделяться разными процессами и код не может выполняться напрямую из FLASH.
static PIE ELF
Вариация static PIE (position-independent executable) формата ELF это довольно молодое изобретение, существенно моложе bFLT, а его поддержка в ядре linux без MMU появилась совсем недавно — в релизе v4.10 в 2015. Как устроен static PIE ELF с точки зрения загрузки для выполнения? Это группа сегментов кода и данных, плюс таблица записей о релокациях. Сегменты могут быть загружены по произвольным (выровненным) адресам, но должны сохранять неизменное положение друг относительно друга, иными словами, вся группа может перемещаться в адресном пространстве как единое целое. После загрузки указатели расположенные по смещениям записанным в таблице релокаций нужно подправить, добавив к ним смещение адреса загрузки по отношению к адресу линковки. Плюсы этого решения по сравнению с bFLT очевидны: никаких дополнительных инструментов в процессе сборки, результат — это стандартный ELF-файл с полной поддержкой всех фич ELF, включая TLS и отладку. Минус статической линковки никуда не девается, и добавляется минус связанный с тем, что сегмент кода принципиально не может использоваться одновременно разными процессами, даже когда он не требует релокаций. В целом static PIE ELF выглядит как хорошая замена для bFLT при наличии большого объёма RAM, но недостаточно хорошая для нашего случая.
FDPIC ELF
Вариация FDPIC (function descriptor position-independent code) формата ELF это довольно старое изобретение. Оно не получило широкой известности за пределами архитектур без MMU, но внутри noMMU комьюнити это несомненный фаворит и с течением времени всё больше архитектур реализуют поддержку этого формата (из недавних это, например, sh и arm). Как устроен FDPIC ELF с точки зрения загрузки для выполнения? Это группа сегментов кода и данных, плюс как минимум одна таблица записей о релокациях. Сегменты могут быть загружены по произвольным (выровненным) независимым друг от друга адресам, ядро при запуске нового исполняемого образа передаёт ему карту загрузки сегментов в память, после чего пользовательский код должен пройтись по таблице релокаций и подправить указатели расположенные по указанным смещениям в соответствии с картой загрузки. Разные процессы могут совместно использовать одну общую копию сегмента кода, код ссылается на статические данные принадлежащие конкретному процессу используя указатель, называемый FDPIC pointer, идентифицирующий этот сегмент данных в этом процессе. Часть «Function Descriptor» из названия формата вступает в игру при использовании динамической линковки. Когда код из одного ELF-файла вызывает код из другого ELF-файла, он должен загрузить правильный FDPIC pointer, чтобы вызываемый код мог найти свой сегмент данных в текущем процессе. Это реализуется на логическом уровне расширением указателей на функции, так, чтобы они включали в себя как указатель на код, так и FDPIC pointer, а физически это реализуется введением структур Function Descriptor содержащих упомянутые указатели и заменой прямых указателей на функции указателями на эти дескрипторы. Код загружающий указатели из дескриптора при вызове функции генерируется компилятором, а сами дескрипторы генерируются совместными усилиями пары ассемблер/линковщик.
Сложности конкретно архитектуры xtensa
Одним из спорных решений при первоначальной разработке ELF-тулчейна xtensa был отказ от классической структуры ELF-файлов с отдельной секцией .got (global offset table) в пользу литералов объединяемых с секцией .text. Что это значит? Рассмотрим position-independent код который хочет загрузить значение динамически связанной переменной из сегмента данных другого ELF-файла. Стандартный подход с секцией .got реализует это действие следующим образом: в смещение относительно начала .got адреса переменной (это константа) прибавляется к адресу начала .got (совпадающий с FDPIC pointer), и из памяти по полученному адресу загружается значение указателя (помещённое туда динамическим линковщиком в процессе связывания и разрешения имён). В коде это действие может быть представлено цепочкой длиной от одной (загрузка в регистр с помощью косвенной адресации где базовый адрес — регистр FDPIC pointer, а константное смещение закодировано в команде) до трёх (отдельно загрузка константы в регистр, сложение двух регистров, загрузка значения из памяти по адресу в регистре) инструкций, в зависимости от развитости системы команд целевого процессора и опций компилятора. Дальше из памяти по полученному адресу загружается значение переменной. Тулчейн xtensa срезает в этом процессе один угол, всегда загружая адрес переменной в регистр инструкцией загрузки литерала (l32r). В результате адрес переменной оказывается привязан к сегменту кода (потому что l32r загружает константу из памяти по смещению относительно текущего адреса программы), а после линковки он неизменно оказывается внутри сегмента кода, поскольку диапазон смещений инструкции l32r ограничен 256КБ. Схожим образом выполнена реализация обращений к TLS-переменным и реализация фичи longcalls, позволяющая вызывать далеко расположенные функции. Эту логику пришлось полностью переделать для варианта FDPIC, реализовать использование секции .got компилятором и ассемблером и генерацию этой секции линковщиком. Реализация пока не полная, TLS и longcalls ждут своей очереди.
FDPIC ELF тулчейн для юзерспейса
История с добавлением поддержки FDPIC в тулчейн xtensa оказалась довольно длинной и растянулась на несколько месяцев с перерывами. Для начала надо было определиться со спецификацией, т.е. понять, как в деталях это всё должно работать. Я начал с документов FDPIC ABI для frv, sh и arm и какое-то время примерял, как применить это к xtensa. В итоге я решил начать с простейшей возможной реализации, использовать базовый ABI call0, таскать FDPIC pointer в регистре a11, не использовать ленивое связывание и PLT (procedure linkage table), а вставлять межмодульные вызовы прямо по месту. Я добавил поддержку FDPIC ELF в xtensa linux, а для упрощения тестирования — добавил поддержку FDPIC в linux-user QEMU для xtensa. Первым изменение в тулчейне нужно было добавить определение новых типов записей о релокациях в BFD, научиться генерировать их в ассемблере и научиться генерировать соответствующие структуры в линковщике, а тестировать это написав на ассемблере hello world с использованием фич FDPIC (т.е. вызовы функций через дескриптор и обращение к статическим данным через указатель в .got) и линкуя его без каких либо внешних связей. Это был итеративный процесс: правишь ассемблер и/или линковщик, собираешь binutils, собираешь тест, запускаешь в QEMU со сбором логов, смотришь, что пошло не так и в каком месте, разбираешься почему, правишь, начинаешь следующую итерацию. Когда элементарный тестовый пример заработал, стало понятно, что можно браться за компилятор. Начало оказалось довольно простым: нужно было поправить код генерирующий вызовы функций, добавив загрузку указателей из дескриптора и генерацию кода загрузки констант ссылающихся на символы. Это, конечно, не исчерпывающий список правок, к компилятору приходилось возвращаться много раз с более поздних этапов, например когда компилятор выдавал ICE (internal compiler error) на какой-нибудь невинно выглядящий исходный код. Но как только компилятор со сделанными правками удалось собрать можно было двигаться дальше — к стандартной библиотеке C. uClibc-ng стала очевидным выбором, поскольку это библиотека по умолчанию для xtensa linux и в ней есть поддержка FDPIC для других архитектур, а это значит, что есть куда подглядывать. Логика на этой стадии была такой: продвигаясь по этапам инициализации динамического линковщика, а потом самой библиотеки добавлять код нужный для поддержки FDPIC до тех пор, пока не удастся выполнить её сборку. Как только библиотека собралась, можно было двигаться дальше. Я накидал скрипты строящие тулчейн и libc и теперь мой цикл разработки вращался вокруг hello world написанного на C, проходя через все компоненты тулчейна. Я провёл неделю или две в этом цикле, после чего увидел наконец-то долгожданное «Hello world» в консоли. Можно было делать последний шаг: конфигурировать buildroot полученным тулчейном и строить корневую файловую систему.
esp32, часть 4: почти запуск юзерспейса
Этот последний шаг не принёс существенных неожиданностей, buildroot построил образ корневой файловой системы, осталось записать его в выделенный раздел FLASH и загрузиться. Однако, нет, в процессе загрузки на esp32 драйвер cramfs выводит сообщения об ошибках в файловой системе и невозможности отобразить в память динамические библиотеки, хотя в softmmu QEMU всё уже работает. Я переделал загрузчик, перебазировавшись на IDF-5.0.1 и заменив прямую манипуляцию кешем более стандартной функцией esp_partition_mmap в надежде, что это пофиксит ошибку, но она никуда не делась. Добавив подсчёт контрольных сумм FLASH я обнаружил, что ошибка появляется при переходе через адрес 0x40400000. Поиск по issues в проекте IDF принёс одну похожую проблему, куда я и зарапортовал свои наблюдения. Потыкавшись немного в низкоуровневые функции и спецификацию MPU/MMU в esp32 TRM и побродив по дизассемблеру ROM esp32 я пришёл к выводу, что это слишком похоже на аппаратную проблему, которй мне не хотелось бы заниматься сейчас самому. Поэтому я отложил esp32 и взялся за esp32s3.
esp32s3
Поверхностный просмотр TRM esp32s3 показал, что аппаратные отличия от esp32 незначительны и, возможно, даже не потребуют модификации исходников за пределами базовых адресов в DTS. Это оказалось не совсем так, в структуре регистров UART между esp32 и esp32s3 есть небольшие отличия, тем не менее не позволившие получить вывод в консоль при первом запуске ядра, однако приведя макросы определяющие регистры UART в соответствие с TRM удалось оживить консоль и залогиниться в интерактивную оболочку:
Что дальше
Дальше открыты несколько направлений которыми можно заниматься параллельно:
допиливать тулчейн: разделаться со всеми оставленными в процессе разработки
TODOиabort(), добавить поддержку TLS и longcalls, добавить недостающее для включения поддержки C++, запустить набор тестов gcc (и ужаснуться), реализовать PLT и ленивое связывание, …, закоммитить результаты в binutils и gcc и заслать патчи в uClibc-ng.допиливать базовые функции ядра: обеспечить возможность записи во FLASH, задействовать второе процессорное ядро и запустить SMP, исследовать возможность прозрачной загрузки данных в обработчике исключений вызываемых чтением 8- и 16-битных значений из FLASH и сравнить производительность с производительностью кода сгенерированного с опцией
-mforce-l32, …писать или портировать драйвера на документированную периферию: clocks, GPIO, RTC, I2C, SPI, SDIO, I2S, ADC/DAC, …
учиться взаимодействовать с недокументированной периферией: WiFi, BT, возможно используя двоичные библиотеки из IDF, возможно обратной разработкой.
Два слова об авторе
Я связан с технологией xtensa с 2011 года, когда в попытке оптимизации одного процесса на своей тогдашней работе я добавил базовую поддержку target-xtensa в QEMU. В 2012 я стал со-мейнтейнером архитектурного порта xtensa в ядре linux, в 2014 на волне растущего интереса к esp8266 «на коленке» добавил поддержку call0 ABI в порт xtensa для gcc, а в 2020 стал со-мейнтейнером портов xtensa в проектах binutils и gcc.
Постепенно дополняемая wiki-страница по теме со ссылками на репозитории и скриптами: http://wiki.osll.ru/doku.php/etc: users: jcmvbkbc: linux-xtensa: esp32s3
