Lingua Franca — Машинный перевод с учётом именованных сущностей для вопросно-ответных систем
TLDR
Машинный перевод может улучшить существующие вопросно‑ответные системы (англ. Question Answering — QA), которые имеют ограниченную поддержку нескольких языков. Однако у машинного перевода есть один основной недостаток: часто такие системы не справляются с переводом именованных сущностей, которые нельзя перевести дословно. Например, немецкое название фильма «The Pope Must Die» переводится как «Ein Papst zum Küssen», что дословно означает «Папа для поцелуев». На Русском языке название фильма звучит так: «Папа должен похудеть». Поскольку правильность именованных сущностей критична для вопросно‑ответных систем, необходимо как можно лучше обеспечить правильность их перевода. В данной статье я представляю наш метод машинного перевода, учитывающий знания об именованных сущностях, под названием «Lingua Franca». Он использует графы знаний для использования хранящейся там символьной информации с целью обеспечения правильности перевода именованных сущностей. И да, это работает!
В чём челлендж?
Достижение высококачественных переводов в значительной степени зависит от точного перевода именованных сущностей в предложениях. Различные методы были предложены для улучшения перевода сущностей, включая подходы, интегрирующие графы знаний (англ. knowledge graphs). Важно отметить, что качество перевода таких сущностей не является самоцелью. Такие подходы находят своё применение в системах, участвующих в задачах, таких как поиск информации (IR) или вопросно‑ответного поиска на основе графов знаний (англ. Knowledge Graph Question Answering — KGQA). В данной статье мы подробно рассмотрим именно взаимодействие машинного перевода и KGQA.
Значимость систем вопросно‑ответного поиска на основе графов знаний заключается в их способности предоставлять пользователям ответы в виде фактов на основе структурированных данных (см. рисунок ниже).
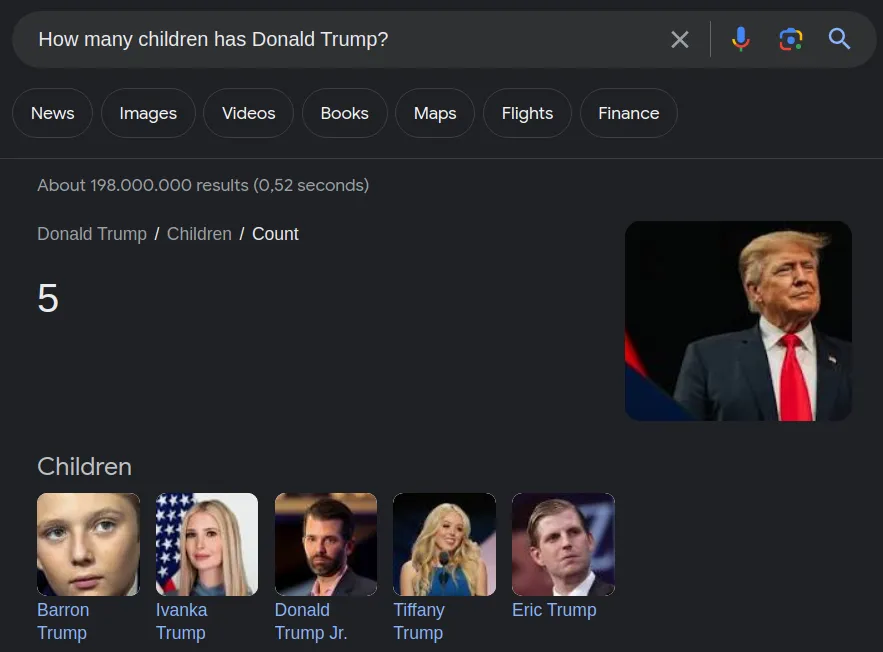
Сколько детей у Дональда Трампа? Отвечает Гугл
Такие KGQA системы являются ключевыми компонентами современных поисковых систем, что позволяет им предоставлять прямые ответы пользователям (например, как скриншоте выше). Кроме того, многоязычные системы KGQA играют решающую роль в преодолении «цифрового языкового барьера» (англ. digital language divide) в сети. Например, статьи в Википедии, связанные с Россией, особенно те, которые посвящены городам или людям нашей страны, содержат больше информации на Русском языке, чем на других языках. Этот дисбаланс информации может быть урегулирован многоязычными системами вопросно‑ответного поиска на основе графов знаний.
Одним из вариантов того, как заставить систему KGQA отвечать на вопросы на разных языках является использование машинного перевода. Однако модели машинного перевода «из коробки» сталкивается с значительными трудностями при переводе именованных сущностей, поскольку многие из них не могут быть дословно переведены и требуют интеграции дополнительных знаний (англ. background knowledge) для точной работы. Рассмотрим немецкое название фильма «The Pope Must Die», которое звучит как «Ein Papst zum Küssen». Дословный перевод «Папа для поцелуев» подчеркивает необходимость контекстного понимания за пределами прямого перевода слово в слово. На Русском языке название фильма звучит так: «Папа должен похудеть».
Учитывая ограничения традиционных методов машинного перевода в переводе именованных сущностей, комбинирование систем KGQA с таким переводом часто приводит к искажению сущностей, существенно уменьшая вероятность точного ответа на вопрос системой KGQA. Поэтому мы видим необходимость в усовершенствованном подходе, который базируется на интеграции дополнительных знаний о именованных сущностях в машинный перевод.
Наш подход Lingua Franca
Наша статья реализует новый подход к машинному переводу, ориентированный на именованные сущности (англ. Named entity‑aware machine translation — NEAMT), с целью улучшения многоязычных возможностей систем KGQA. Основная идея NEAMT заключается в повышении качества машинного перевода путем включения информации об именованных сущностях из графа знаний (например, Wikidata и DBpedia). Это достигается с использованием техники подмены сущности в исходном тексте (англ. entity‑replacement).
В качестве данных для оценки мы используем такие датасеты, как QALD-9-plus и QALD-10. Затем мы используем пайплайн из нескольких компонентов для извлечения и связывания именованных сущностей и, впоследствии, их машинного перевода. Компоненты и соответствующий фреймворк доступен в нашем репозитории. Наконец, подход оценивается на двух системах: QAnswer и Qanary. Подробное описание подхода доступно на рисунке ниже.

Обзор подхода Lingua Franca в процессе вопросно-ответных систем KGQA
По сути, наш подход в процессе перевода сохраняет распознанные именованные сущности, используя технику подмены сущности. Затем эти сущности заменяются соответствующими представлениями из графа знаний на целевом языке перевода. Этот процесс обеспечивает точный перевод вопросов и именованных сущностей перед их использованием системой KGQA.
Следуя урокам из нашей предыдущей статьи, мы будем использовать английский язык как целевой язык перевода, что приводит к названию нашего подхода «Lingua Franca» (вдохновленного значением «язык‑мост» или «язык‑связь»). Важно отметить, что наш подход универсален и легко адаптируется к любому другому языку в качестве целевого. И, что не менее важно, Lingua Franca выходит за рамки KGQA и находит применение в других различных системах информационного поиска, ориентированных на именованные сущности.
Lingua Franca включает в себя три основных этапа: (1) распознавание именованных сущностей (NER) и связывание именованных сущностей (NEL), (2) применение техники подмены сущности на основе информации из предыдущего этапа, и (3) использование инструмента машинного перевода для генерации текста на целевом языке с учетом информации с предыдущих этапов. Здесь английский язык, как упоминалось ранее, последовательно используется в качестве целевого языка. Однако подход не ограничивается только английским языком, при необходимости могут быть использованы и другие языки в качестве целевых.
Open‑source реализация нашего подхода позволяет пользователям создавать свои собственные пайплайны машинного перевода, учитывающие именованные сущности путем интеграции пользовательских компонентов NER, NEL и MT (см. наш GitHub). Подробности подхода Lingua Franca для всех настроек проиллюстрированы в предоставленном примере, как показано на рисунке ниже.
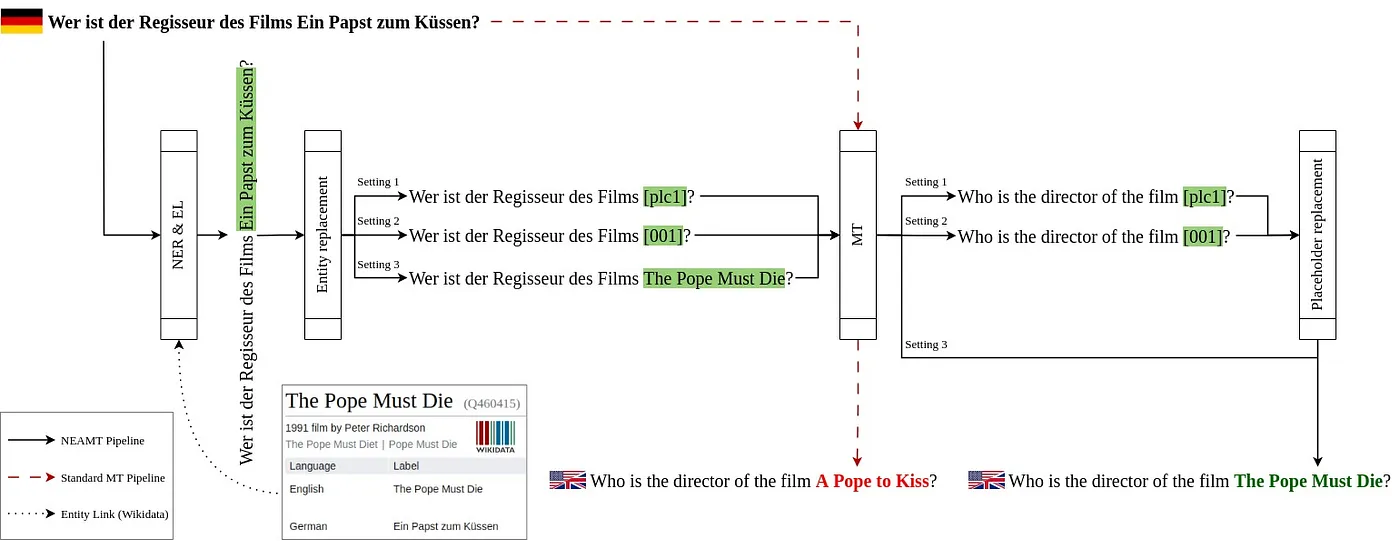
Подробное представление подхода Lingua Franca с различными стратегиями подмены сущности
Результаты экспериментов нашего исследования свидетельствуют о значительном улучшении качества вопросно‑ответных систем KGQA в сочетании с Lingua Franca по сравнению с стандартными инструментами машинного перевода.
Результаты экспериментов
При оценке разных стратегий подмены сущностей была рассчитана доля «поврежденных» плейсхолдеров и представлений именованных сущностей после их обработки машинным переводом. Эта доля служит показателем фактического качества перевода именованных сущностей
Стратегия 1 (плейсхолдеры в виде строк): 6.63% было утрачено или повреждено.
Стратегия 2 (числовые плейсхолдеры): 2.89% заполнителей были утеряны или повреждены.
Стратегия 3 (замена сущностей их английскими представлениями прямо перед переводом): 6.16% были повреждены.
Таким образом, с использованием нашего подхода мы можем уверенно утверждать, что до 97.11% (стратегия 2) распознанных именованных сущностей в тексте были переведены правильно.
Мы проанализировали результаты экспериментов касающиеся качества ответов на вопросы системами KGQA варьируя следующие составные части экспериментов: пайплайн Lingua Franca или стандартный инструмент машинного перевода, исходный язык, датасет, а также KGQA система. Диаграмма ниже иллюстрирует сравнение между нашим подходом и стандартными инструментами машинного перевода.
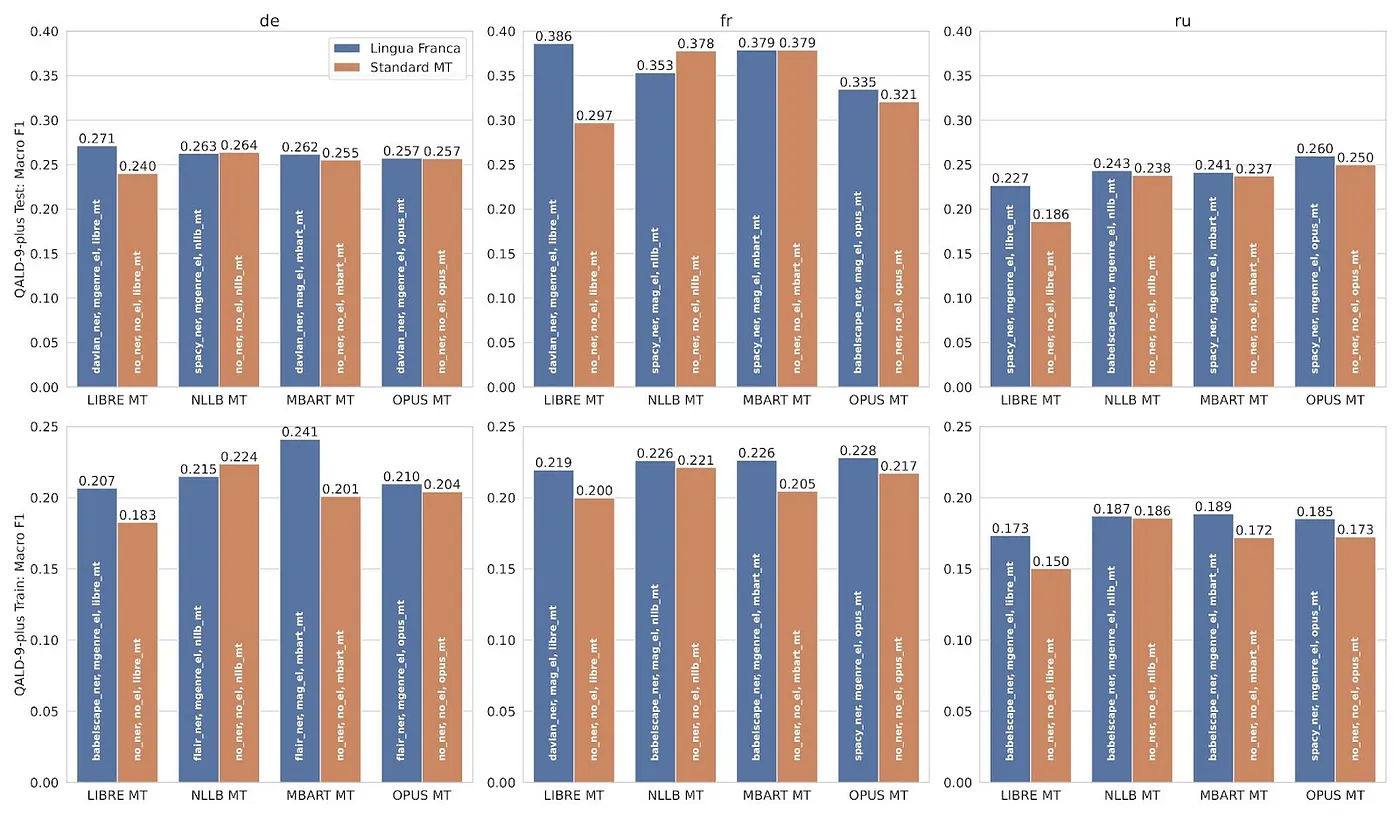
Столбчатая диаграмма показателей Macro F1 для наших экспериментов. Синие столбцы обозначают результаты, полученные в связке с нашим подходом. Оранжевые столбцы — стандартные средства машинного перевода.
Диаграмма вверху иллюстрирует метрику Macro F1 (подсчёт произведён с использованием Gerbil‑QA) для каждого языка и разбиения на train и test. В контексте каждая группа состоит из двух столбцов: первый относится предложенному нами подходу, в то время как второй столбец отражает производительность стандартного инструмента машинного перевода (бейзлайн).
Мы отметили, что в большинстве экспериментальных случаев (19 из 24) системы KGQA, использующие наш подход, превзошли те же системы, которые использовали стандартные инструменты машинного перевода. Для подтверждения вышеуказанного утверждения мы провели тест Уилкоксона на тех же данных. На основе результатов теста (p‑value = 0,0008 при α = 0,01) мы отвергли нулевую гипотезу, которая утверждает, что результаты не имеют различий при сочетании KGQA со стандартным машинным переводом и сочетании KGQA с нашим подходом Lingua Franca. Таким образом, мы приходим к выводу, что наш подход значительно улучшает качество работы многоязычных вопросно‑ответных систем по сравнению со стандартными инструментами машинного перевода.
Воспроизводимость экспериментов была проверена путем их повторения и вычисления коэффициента корреляции Пирсона между метриками качества ответов на вопросы. Полученный коэффициент 0.794 соответствует пограничному значению между сильной и очень сильной корреляцией. Поэтому мы предполагаем, что наши эксперименты воспроизводимы.
Итоги
В данной статье мы представили новый подход к машинному переводу с учётом именованных сущностей под названием Lingua Franca. Разработанный для улучшения многоязычных возможностей и повышения качества вопросно‑ответных систем, Lingua Franca продемонстрировал результаты, превосходящие по качеству стандартные инструменты машинного перевода. Реализация Lingua Franca в виде фреймворка используют модульную структуру и позволяет пользователям интегрировать свои компоненты.
Для будущих исследований мы будем расширять наш экспериментальный сетап, охватывая более широкий спектр языков, датасетов и систем KGQA. Для решения проблем с поврежденными плейсхолдерами в процессе подмены сущностей мы планируем проводить тонкую настройку (fine‑tuning) моделей машинного перевода.
Не забывайте посмотреть нашу статью и репозиторий на GitHub. Если не открывается статья, ссылка на VPN тут.
