KubeVirt: внутреннее устройство и сеть. Как достигнуть совершенства? (обзор и видео доклада)
Всем, привет! Я Андрей Квапил, работаю во «Фланте» над Kubernetes-платформой Deckhouse. Это статья по мотивам моего доклада о разработке нашей системы виртуализации на основе KubeVirt. Я расскажу, какие альтернативы KubeVirt мы рассматривали, чем они нас не устроили, как устроен KubeVirt, как он работает с файловыми хранилищами и сетью, как происходит запуск виртуальных машин внутри Kubernetes. А еще — какие изменения мы внесли в KubeVirt, чтобы он полностью соответствовал нашим задачам. Будет сложно, но интересно.
В начале 2023 года мы уже рассказывали на Хабре о Deckhouse Virtualization.
Что такое облако и для чего оно необходимо
Все началось с того, что нам понадобилась облачная платформа. Давайте посмотрим, какие задачи обычно решают облачные платформы. Если говорить совсем просто, то облако позволяет взять физические ресурсы ваших узлов (например, CPU, RAM или дисковое пространство) и нарезать из них виртуальные машины — по сути, виртуальные серверы, в которых будут запускаться те или иные рабочие нагрузки.

Область применения виртуальных машин достаточно широка, но нас при разработке модуля виртуализации для Deckhouse интересовали вполне конкретные сценарии:
Запуск легаси-софта, не предназначенного для запуска в Kubernetes. При этом важна возможность управлять этим легаси-софтом так же легко, как и любыми другими приложениями, запущенными в Kubernetes.
Запуск Windows, а также возможность при необходимости пробросить в нее виртуальную видеокарту.
Возможность разворачивать вложенные Kubernetes-кластеры.
Исходя из этого мы сформировали ряд требований к будущей облачной платформе.
Kubernetes изначально не является мультитенантным и не предназначен для того, чтобы с одним кластером взаимодействовало несколько команд разработчиков. Поэтому нам была нужна возможность без труда создавать и удалять кластеры внутри облака — это бы позволило легко предоставлять отдельные кластеры каждой группе разработчиков или под конкретное приложение, а также динамически масштабировать кластеры, выделяя дополнительные виртуальные узлы.
Мы хотим предоставлять свою платформу как сервис — для этого необходимо, чтобы у пользователей была возможность заказывать и новые Kubernetes-кластера, и отдельные виртуальные машины в облаке.
Однако при этом важна и возможность устанавливать платформу on-premise (на собственном оборудовании). Поэтому она должна легко расширяться с помощью плагинов и поддерживать уже используемые нами технологии.
Облако должно иметь удобный и понятный пользователю API-интерфейс и поддерживать основные утилиты вроде Terraform, но главная идея — предоставить возможность управлять облаком с помощью обычного kubectl.
Основные потребители нашего облака — это как обычные пользователи, так и различные инструменты автоматизации и интеграции с облаком, с помощью которых приложение может само ходить в API облака и управлять жизненным циклом виртуальных машин, и заказом новых инстансов для автоматического масштабирования кластера.

Для организации такой платформы мы рассматривали только Open Source-решения, лицензии которых позволяли интеграцию в нашу разработку. Вторая причина, по которой мы рассматривали только Open Source-решения, заключается в том, что мы и сами разрабатываем свободный софт и видим большой потенциал в комьюнити, формирующихся вокруг такого софта.
Какие облачные платформы мы рассматривали
Мы выбирали из пяти решений: KubeVirt, OpenStack, Apache CloudStack, OpenNebula и Ganeti.
По нашему опыту, при выборе свободной технологии необходимо обратить внимание на сообщество и организацию процессов в нем. И это даже более значимый фактор, чем сам продукт. Очень важно заранее убедиться, что в будущем вы не столкнетесь с потенциальными блокерами — ведь с этим сообществом вам придется жить и взаимодействовать на протяжении долгого времени, принимать участие в развитии и поддержке технологии.
Apache CloudStack, OpenNebula и Ganeti нам не подошли либо из-за слишком маленьких сообществ, либо из-за того, что их разработку полностью контролирует одна компания. Если не подумать о таких аспектах на старте, потом можно получить кучу проблем.
Например, недавно произошел неприятный инцидент с OpenNebula. OpenNebula разрабатывается одной компанией и несколько версий назад эта компания закрыла исходники миграций между версиями. Такая ситуация могла привести к тому, что в будущем мы просто не имели бы возможности нормально перейти со старой версии на новую. Если же разработка распределена между несколькими компаниями, такие инциденты в принципе исключены.
Второй причиной отказа от этих решений была их плохая интеграция с Kubernetes. Из-за этого нам бы пришлось дорабатывать огромное количество вещей: CSI-драйвер, Cloud Provisioner и др. — то есть с нуля разрабатывать многочисленные инструменты для интеграции, которые уже реализованы и успешно используются в двух других решениях: KubeVirt и OpenStack.
OpenStack — это стандартный выбор для построения собственного облака. Однако он был разработан много лет назад, когда успешные сейчас паттерны проектирования ПО еще не существовали, а потому имеет достаточно сложную архитектуру. Если посмотреть на внутреннее устройство OpenStack, можно увидеть огромное количество сервисов с асинхронным API и собственными базами данных — все эти компоненты придется определенным образом конфигурировать, чтобы они могли нормально взаимодействовать. К тому же поддержка и обновление такого зоопарка — задача очень нетривиальная.
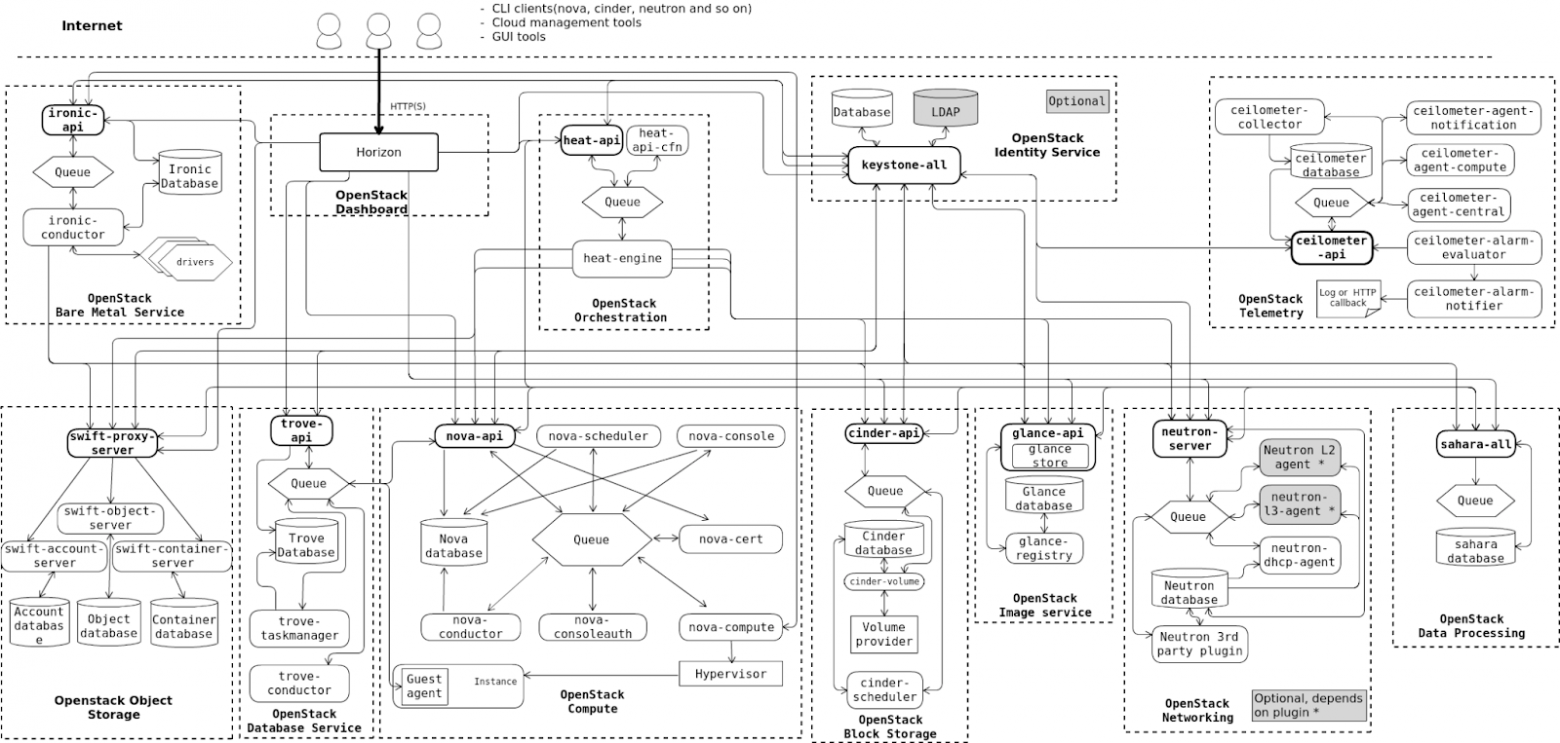
В свете всего этого, KubeVirt выглядел очень неплохой альтернативой OpenStack — особенно учитывая, что это изначально нативное для Kubernetes решение, которое создано с учетом лучших паттернов проектирования ПО в этой среде. Еще одно преимущество KubeVirt — он пытается максимально переиспользовать Kubernetes, и это упрощает его интеграцию в K8s. Однако в то же время он работает с интерфейсами CSI, CNI и CRI, созданными изначально не для виртуализации, а для контейнеризации, из-за чего многие решения выглядят как workaround («костыли»).
К примеру, попытка организовать традиционные виртуальные сети для виртуальных машин используя не предназначенный для этого интерфейс CNI, привела к появлению очень сложной схемы:

В KubeVirt каждая виртуальная машина запускается внутри Kubernetes-контейнера. И для того чтобы она смогла бесшовно использовать сеть этого контейнера, внутри него создается цепочка сетевых интерфейсов. Мало того, что для каждой виртуальной машины создается дополнительный сетевой мост (внутри пода!) для подключения ее интерфейса к интерфейсу пода, так к этой схеме еще добавляется DHCP-сервер, обслуживающий запросы только этой отдельной ВМ. Такой подход негативно сказывается на задержках и производительности виртуальной сети, а также, ввиду своей сложности, не выглядит достаточно стабильным решением. Поэтому от KubeVirt на первом этапе мы тоже решили отказаться.
И раз уж на рынке не было полностью подходящего нам решения, мы задумались над разработкой собственного. Мы очень любим Kubernetes и везде его внедряем, поэтому очень хотели, чтобы наше будущее решение использовало Kubernetes. Для запуска виртуальных машин мы планировали задействовать libvirt — стандартную библиотеку, которая используется практически в любой системе виртуализации. Сами виртуальные машины мы тоже планировали запускать в контейнерах, потому что это удобное, унифицированное решение, которое работает одинаково в любой среде.
В этот момент мы решили ещё раз внимательно посмотреть в сторону KubeVirt. В нем нам не понравилась только реализация сети — остальные компоненты и подходы нас более-менее устраивали. После обсуждений мы все-таки решили взять KubeVirt и тщательно доработать его напильником, вместо того чтобы реализовать всю функциональность с нуля.

Итак, давайте выделим те достоинства KubeVirt, которые склонили чашу весов в его сторону:
Он основан на Kubernetes и реализует его лучшие паттерны, включая логику контроллеров и reconciliation loop.
У него большое и быстрорастущее сообщество — число звезд на GitHub больше, чем у того же OpenStack.
В него контрибьютят крупные компании: Red Hat, Nvidia, ARM, SUSE — и количество таких участников постоянно растет.
Он не подконтролен какой-то конкретной компании, разработка управляется сообществом.
У него достаточно простая архитектура, а также множество общих компонентов, которые мы уже используем в своих инсталляциях Kubernetes.
Как устроен KubeVirt
Основа KubeVirt — это virt-operator, который деплоит остальные микросервисы:
virt-api — обслуживает все запросы к API для ресурсов виртуализации: например: сабресурсы для включения и выключения виртуальной машины или получения доступа к виртуальной консоли, а также запуск вебхуков проходят именно через него.
virt-controller — контроллер-менеджер, который обслуживает ресурсы виртуализации: под каждую виртуальную машину он создает отдельный под, который запускает virt-launcher с нужными параметрами.
virt-handler — отдельный DaemonSet, запускающийся на всех узлах кластера. По сути, он служит для расширения функционала kubelet, который донастраивает окружение пода для запуска виртуальной машины внутри него. На данный момент он отвечает за создание сетевых интерфейсов, а также используется для проброса
dev/kvmи других устройств с узла внутрь пода.virt-launcher — отдельный бинарный исполняемый файл, запускающийся в каждом поде с виртуальной машиной, который отвечает за ее запуск через libvirt.

Разберемся, как все эти компоненты работают в связке и обеспечивают запуск виртуальной машины внутри Kubernetes. Я уже упоминал, что KubeVirt переиспользует многие Kubernetes-интерфейсы:
CRI — Kubernetes Runtime: по сути, Docker или containerd. Отвечает за запуск контейнеров.
CSI — Kubernetes Storage. Позволяет управлять томами и дисками.
CNI — Kubernetes Networking. Отвечает за сеть.
А теперь на примере каждого из них рассмотрим, как выглядит запуск виртуальной машины в Kubernetes — и начнём мы с Container Runtime.

Как запускается виртуальная машина
Если не брать в расчёт работу контроллеров и планировщика, то при запуске пода с виртуальной машиной используются два компонента: virt-handler и virt-launcher. Virt-handler является системным компонентом и имеет полный привилегированный доступ к хостовой системе, тогда как под с виртуальной машиной (он же virt-launcher) — это обычный непривилегированный под в Kubernetes.
Поэтому перед непосредственным запуском виртуальной машины virt-handler пробрасывает определенные настройки в контейнер с будущей ВМ: например, конфигурирует cgroups, чтобы можно было использовать те или иные устройства, создает TAP-интерфейс и пробрасывает устройства с хоста до пода, чтобы ВМ могла их использовать.

Virt-launcher запускает libvirt, и уже с его помощью запускает виртуальную машину.

Здесь нужно отдавать себе отчет, что под — просто сервисная сущность для запуска виртуальной машины. Чтобы лучше понять этот принцип, рекомендую взглянуть на то, как работает лайв-миграция.
Если мы захотим мигрировать виртуальную машину с одного узла на другой в горячем режиме (не выключая), то перед этим на втором узле предварительно запустится такой же под с virt-launcher для запуска этой ВМ. Virt-handler пробросит туда настройки и устройства, а потом запустится libvirt. Только после всех этих подготовительных действий начнется миграция непосредственно виртуальной машины.

После успешной миграции старый под будет уничтожен.

Это наглядно показывает то, о чем я говорил выше: под — это просто сервисная сущность в Kubernetes, которая используется в качестве способа запуска процесса с виртуальной машиной. При миграции виртуальная машина переносится из одного пода в другой, а старый под, соответственно, становится не нужен и удаляется.
Как управляется хранилище
Теперь давайте посмотрим на то, как KubeVirt организует работу с хранилищем. Здесь всё просто — для этого используется стандартный CSI-интерфейс. Например, при запуске пода мы можем просто указать, с какими volumes ему нужно запуститься.

По сути, это обычные PVC (PersistentVolumeClaim), которые можно использовать и для виртуальной машины. Virt-launcher при запуске видит, что к поду подключены соответствующие тома, и создает виртуальные диски внутри них, которые позже будут присоединены к виртуальной машине.

На самом деле проект KubeVirt довольно сильно повлиял на Kubernetes. Одно из нововведений, которое появилось в Upstream в результате такого влияния — это блочные тома. На сегодняшний день многие CSI-драйверы в качестве альтернативы томам с файловой системой поддерживают и блочные тома, которые подключаются в под напрямую, как блочное устройство. В некоторых случаях это также дает возможность использовать режим ReadWriteMany, для того чтобы виртуальная машина могла бесшовно мигрировать между узлами.

Использование блочных томов вместо файловой системы дает более солидную производительность, так как в этом случае виртуальная машина обращается к ним напрямую, не задействуя прослойку в виде файловой системы.
Но возникает и резонный вопрос: как тогда работает горячее подключение дисков в KubeVirt? Ведь spec пода иммутабельна, так что в Kubernetes, по сути, нет возможности добавлять или удалять тома для уже запущенного пода.
В KubeVirt это решено следующим образом: рядом с подом с виртуальной машиной запускается еще один под. этот под ничего не делает, но к нему подключен необходимый нам физический том. Virt-handler автоматически замечает такой под и пробрасывает тот самый том в под с виртуальной машиной.

Внутри пода virt-launcher подключает его уже непосредственно к виртуальной машине.
Containerized Data Importer (CDI)
В Kubernetes контейнеры запускаются из Docker-образов, но в мире виртуальных машин базовые образы могут быть достаточно большими, следовательно, паковать их как Docker-образы может быть весьма неудобно. Однако при создании виртуальной машины нам, как правило, нужно иметь некий базовый образ (в терминах OpenStack — Golden Image). И возникает вопрос: как такой Golden Image появится в Kubernetes?

В KubeVirt подготовкой Golden Image занимается отдельный компонент, Containerized Data Importer (CDI). Это отдельный оператор со своими контроллерами, который обслуживает ресурсы вроде DataVolume:
pvc:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: linstor-thindata-r2
volumeMode: Block
source:
http:
url: https://server/cloud.imgПри создании DataVolume мы можем запросить том определенного размера с нужным нам содержанием. По сути, этот ресурс всегда генерирует PVC, для которого сначала провижинится PV (Persistent Volume), а после запускается специальный под, который скачивает образ из указанного источника на PVC. Это может быть как HTTP, так и Docker-образ в Registry.

После этого DataVolume можно подключить к виртуальной машине, и она начинает работать с импортированным образом. При этом все изменения будут сохраняться уже в PVC.
В принципе, этой информации должно быть достаточно, чтобы понять, как устроено хранилище в KubeVirt. Теперь перейдем к самой интересной и самой болезненной части — реализации сети.
Как работают сетевые интерфейсы
Давайте разберемся, как KubeVirt переиспользует интерфейс CNI для организации сети — чтобы виртуальная машина могла общаться с другими подами или ресурсами в кластере. Сеть в KubeVirt делится на две части — бэкенд и фронтенд.
Бэкенд KubeVirt
Бэкенд отвечает за то, как интерфейсы попадают в под. Например, если запустить в кластере под, то можно быть уверенным в том, что у него появится интерфейс eth0 из сети подов Kubernetes. Это тот самый интерфейс, который обслуживается CNI-драйвером нашего кластера — так выглядит и стандартная сеть подов в Kubernetes.

Есть и второй вариант, про который знают немногие: Multus. Multus — это расширение в Kubernetes, которое позволяет добавлять дополнительные интерфейсы в поды. Он работает как с виртуальными машинами, так и с обычными подами. А сам KubeVirt достаточно сильно зависит от Multus.
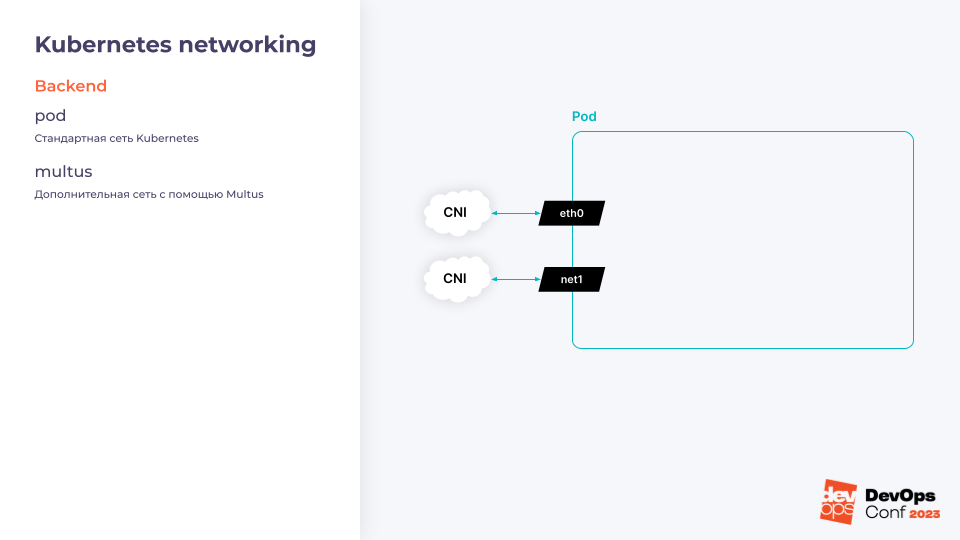
Фронтенд KubeVirt
После запуска пода необходимо подумать о том, как его интерфейсы будут соединены с интерфейсами самой виртуальной машины.

И здесь есть несколько режимов.
Первый используется по умолчанию и называется masquerade. По сути, представляет собой правило iptables, включающее NAT. У виртуальной машины при этом всегда будет неизменная подсеть, а весь трафик между ней и сетью пода NAT«ится один-к-одному.
Чтобы понять, как это работает, представим узел с физическим интерфейсом. После запуска пода CNI-плагин создает veth-интерфейс. Это такая «виртуальная витая пара», которая связывает сетевое пространство имен пода с сетевым пространством имен узла. Внутри пода создается мост. С одной стороны к нему подключается виртуальная машина, а с другой между мостом и внутренним интерфейсом пода добавляется iptables-правило, которое и пробрасывает весь трафик.
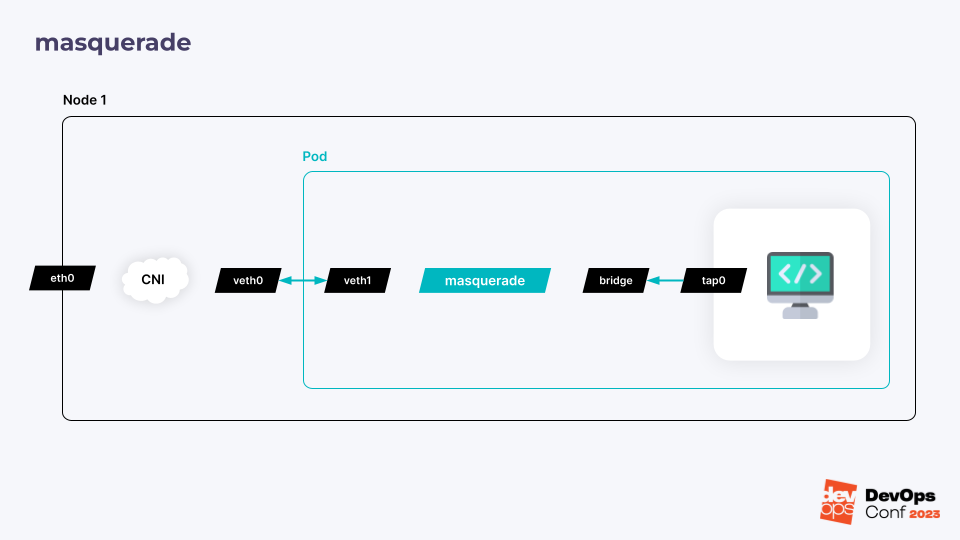
Также на сетевом мосту запускается DHCP-сервер, который обслуживает запросы исключительно для этой конкретной виртуальной машины: он нужен для того, чтобы она могла получить правильные настройки сети и необходимые маршруты.

Второй режим называется slirp. При запуске виртуальной машины процесс QEMU, обслуживающий ее, начинает слушать определенные порты, указанные в спецификации ВМ.
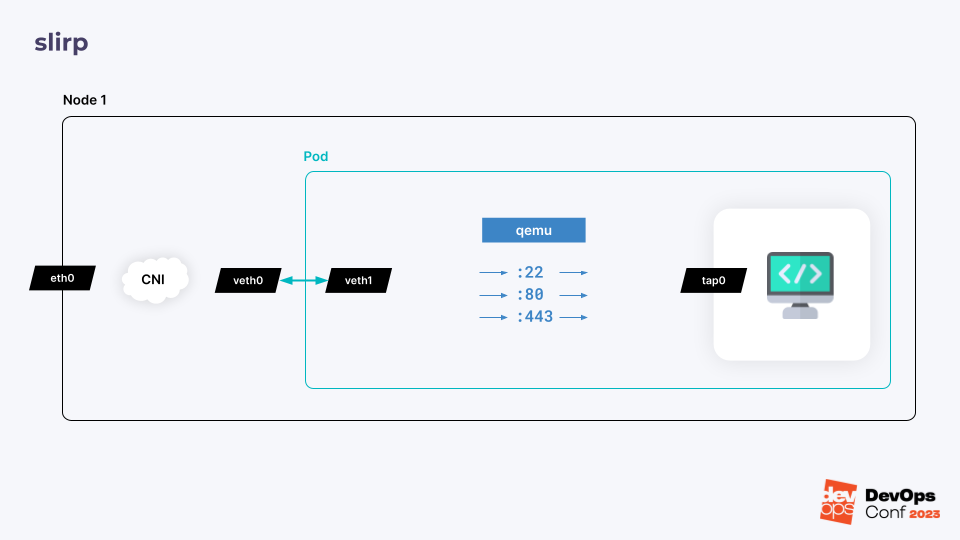
Подключение к этим портам будет проброшено внутрь виртуальной машины.
Проблема этих двух режимов в том, что они достаточно непроизводительны. Кроме того, они могут работать только с сетью подов в Kubernetes. С дополнительными интерфейсами, добавленными с помощью Multus, они уже работать не будут.
Чего не скажешь про третий режим — bridge, использующий обычный сетевой мост для соединения интерфейса пода с интерфейсом виртуальной машины. Этот режим можно использовать как для подключения ВМ к сети подов, так и для дополнительных интерфейсов, добавляемых с помощью Multus. Схема его работы похожа на предыдущие —, но с небольшими отличиями: интерфейс виртуальной машины соединяется напрямую с внутренним интерфейсом пода. Это позволяет виртуальной машине работать с тем же IP-адресом, что и сам под.

Такой режим реализует более высокую производительность по сравнению с двумя предыдущими. Однако при использовании с сетью подов он вносит дополнительные ограничения на выполнение лайв-миграции, а также, в зависимости от CNI, может добавить дополнительные риски, связанные с безопасностью.
Четвертый режим работы — sriov. Если сетевая карта вашего узла умеет создавать Virtual Function PCI-устройства, то KubeVirt умеет пробрасывать эти самые PCI-устройства внутрь пода для использования виртуальной машиной.
Так как в этом случае виртуальная машина получает прямой доступ к устройству, режим sriov обеспечивает наилучшую производительность. Однако есть и недостатки: он должен поддерживаться со стороны железа и не будет работать для доступа к основной сети подов в Kubernetes или к хосту, на котором запущена виртуальная машина.

Последний, пятый режим работы — это macvtap. С помощью дополнительного CNI-плагина macvtap-cni он позволяет реализовать то же, что и sriov — то есть подключить виртуальную машину к физическому сетевому интерфейсу на ноде. Однако macvtap задействует для этого исключительно возможности ядра Linux. В итоге при создании пода отдельный CNI-плагин создает отдельное macvtap-устройство из физического интерфейса ноды и пробрасывает его в под.

Как и в случае sriov, виртуальная машина запускается и работает с устройством напрямую. Macvtap — быстрый и производительный режим, но недостатки у него те же: с помощью macvtap нельзя подключиться к основной сети подов в Kubernetes и непосредственно к хосту, на котором запущена эта виртуальная машина.
В общем, режим macvtap является одним из самых быстрых и к тому же не требует поддержки со стороны железа, но, используя macvtap, мы не сможем получить доступ к сети подов в Kubernetes —, а это очень важно.
Так как мы используем Cilium, нам хотелось иметь возможность использовать его политики, балансировщик нагрузки и все остальные крутые сетевые возможности, которые дает Kubernetes со своей плоской структурой организации сети подов. Поэтому мы решили взять macvtap и доработать его так, чтобы он научился работать со стандартной сетью подов Kubernetes.
В итоге мы обучили KubeVirt создавать macvtap для сети подов. Как это работает? При создании виртуальной машины ее виртуальный интерфейс биндится не на физический интерфейс хоста, а на veth-интерфейс пода. И получается, что виртуальная машина работает с сетью подов практически нативно, как будто это обычный контейнер. Для DHCP-сервера мы тоже добавили дополнительный интерфейс (macvlan), но, в отличие от других реализаций, он не встраивается в ту же цепочку интерфейсов, а работает как бы независимо и обслуживает только отдельные широковещательные запросы от виртуальной машины.

Такая схема позволила получить все возможности Clilium для виртуальных машин. В результате мы больше не зависим от Multus, а можем нативно работать с сетью подов в Kubernetes и пользоваться всеми её преимуществами.
Мы сравнили производительность нашего улучшенного macvtap со стандартными с masqureade и bridge:

Как и ожидалось, число задержек оказалось минимальным для macvtap — как в случае с flannel, так и в случае с Cilium.
Какие проблемы пришлось решить
Но на этом приключения не окончились: как мы знаем, при использовании сети подов у вас по-прежнему остаются ограничения по лайв-миграции виртуальной машины между хостами — ведь Cilium, как и большинство CNI-плагинов, не позволяет аллоцировать IP-адреса в отрыве от podCIDR, назначенных нодам.
Сеть в Kubernetes устроена таким образом, что на каждую ноду выделяется отдельный podCIDR. Это определенная подсеть, которая содержит IP-адреса, доступные для аллокации только на этой ноде. При запуске подов, а соответственно и виртуальной машины, они всегда наследуют адреса из этой подсети.

Так как подсети на нодах разные, то в процессе миграции с одного узла на другой виртуальная машина получает новый IP-адрес.

По этой причине KubeVirt просто запрещает миграцию виртуальных машин, имеющих прямое подключение к сети подов. Однако, если придумать механизм, который бы позволял в процессе миграции сообщать виртуальной машине о необходимости обновления сетевых настроек, это ограничение можно обойти
Это второе улучшение, которое мы внесли в сеть KubeVirt. Когда виртуальная машина мигрирует, для её сетевого интерфейса выполняется link down и link up, в итоге виртуальная машина запрашивает новый адрес и настройки по DHCP.
Получился хороший компромисс для обеспечения лайв-миграции, однако он все еще не позволял выполнить ее абсолютно бесшовно. Поэтому мы не стали останавливаться на достигнутом и придумали следующее: ввели отдельную подсеть vmCIDR, в которой IP-адреса выделяются только для виртуальных машин, а также добавили на узлы специальные роутеры, которые перенаправляют все запросы к адресу виртуальной машины на тот узел, где она запущена в данный момент.
Теперь при миграции виртуальной машины на втором узле запускается под с таким же IP-адресом.

Другими словами, в одно и тоже время у нас существует два пода с одинаковыми IP-адресами, но роутеры направляют трафик только на один из них. После завершения миграции роутеры переключаются на новый под, а старый удаляется.

Это позволило добиться более гладкой миграции виртуальных машин с сохранением их IP-адресов.
Заключение
Что же у нас получилось в итоге:
Мы используем нативную сеть подов вместо дополнительных интерфейсов Multus, что дает нам возможность задействовать все возможности Kubernetes.
У нас поддерживаются все возможности Cilium, как для подов так и для виртуальных машин: мощные сетевые политики, балансировщики нагрузки, Service Discovery. При этом виртуальные машины внутри кластера чувствуют себя так же хорошо, как и любой под.
Для подключения к сети виртуальная машина использует наиболее продуктивный метод macvtap вместо длинной цепочки сетевых мостов Linux, увеличивающих latency.
У нас работает лайв-миграция виртуальной машины с сохранением IP-адреса.
Вся система виртуализации управляется отдельными разработанными Custom Resource, о которых вы можете почитать в нашей предыдущей статье.

Экспериментальная версия системы виртуализации уже доступна в Deckhouse, и ее можно потестировать. А если у вас будут дополнительные вопросы — пишите их в комментариях к статье или приходите в русскоязычные чаты по Deckhouse и KubeVirt.
Видео и слайды
P.S.
Читайте также в нашем блоге:
