Kubernetes tips & tricks: о выделении узлов и о нагрузках на веб-приложение

В продолжение наших статей с практическими инструкциями о том, как облегчить жизнь в повседневной работе с Kubernetes, рассказываем о двух историях из мира эксплуатации: выделении отдельных узлов под конкретные задачи и конфигурации php-fpm (или другого сервера приложений) под большие нагрузки. Как и прежде, описанные здесь решения не претендуют на идеал, а предлагаются как отправная точка для ваших конкретных случаев и почва для размышлений. Вопросы и улучшения в комментариях — приветствуются!
1. Выделение отдельных узлов под конкретные задачи
Мы поднимаем кластер Kubernetes на виртуальных серверах, облаках или серверах bare metal. Если устанавливать всё ПО (Ingress, Prometheus, loghouse, kube-dns или CoreDNS, клиентские приложения) на одни и те же узлы, велика вероятность получить проблемы, когда:
- вдруг клиентское приложение начнёт «утекать» по памяти (а limits сильно завышены);
- при сложных запросах к loghouse, Prometheus или Ingress (актуально для старых версий ingress, когда из-за большого количества websocket-соединений и постоянных reload’ов nginx’а появлялись «зависшие nginx-процессы», которые исчислялись тысячами и потребляли огромное количество ресурсов).
Например, реальный случай с инсталляцией Prometheus с огромным количеством метрик, в котором при просмотре «тяжелых» dashboard (например, представлено большое число контейнеров приложений, с каждого из которых рисуются графики) потребление памяти быстро вырастало до ~15 Гб. В результате, мог «прийти» ООМ killer на хост-системе и начать убивать остальные сервисы, что в свою очередь приводило к «непонятному поведению приложений в кластере». А из-за высокой нагрузки на CPU клиентским приложением легко получить нестабильное время обработки запросов Ingress’ом…
Решение быстро напросилось само собой: нужно выделять отдельные машины под разные задачи. У себя мы выделили 3 основных типа групп по задачам:
- Фронты, где мы ставим только Ingress’ы, чтобы быть уверенными, что никакие остальные сервисы не могут повлиять на время обработки запросов;
- Системные узлы, на которых мы разворачиваем VPN’ы, loghouse, Prometheus, Dashboard, CoreDNS и т.п.;
- Узлы под приложения — собственно то, куда выкатываются клиентские приложения. Они могут быть тоже выделены под окружения или функциональность:
- dev
- prod
- perf
- …
Решение
Как мы это реализуем? Очень просто: двумя родными механизмами Kubernetes. Первый — nodeSelector для выбора нужного узла, куда должно выехать приложение, что осуществляется на основе labels, установленных на каждом узле.
Скажем, у нас есть узел kube-system-1. Мы добавляем на него дополнительный лейбл:
$ kubectl label node kube-system-1 node-role/monitoring=
…, а в Deployment, который должен выкатываться на этот узел, пишем:
nodeSelector:
node-role/monitoring: ""
Второй механизм — taints и tolerations. С его помощью мы явно указываем, что на этих машинах могут запускаться только контейнеры, у которых прописан toleration к данному taint.
Например, есть машина kube-frontend-1, на которую мы выкатывать только Ingress. Добавляем taint на данный узел:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
…, а у Deployment создаем toleration:
tolerations:
- effect: NoExecute
key: node-role/frontend
В случае kops под те же потребности можно создавать отдельные instance groups:
$ kops create ig --name cluster_name IG_NAME
… и получится примерно такой конфиг instance group в kops:
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
creationTimestamp: 2017-12-07T09:24:49Z
labels:
dedicated: monitoring
kops.k8s.io/cluster: k-dev.k8s
name: monitoring
spec:
image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14
machineType: m4.4xlarge
maxSize: 2
minSize: 2
nodeLabels:
dedicated: monitoring
role: Node
subnets:
- eu-central-1c
taints:
- dedicated=monitoring:NoSchedule
Таким образом, на узлы из этой instance group будут автоматически будет добавляться дополнительный лейбл и taint.
2. Настройка php-fpm под большие нагрузки
Существует большое разнообразие серверов, которые используются для работы веб-приложений: php-fpm, gunicorn и подобных. Их использование (в Kubernetes) означает, что есть несколько вещей, о которых всегда надо думать:
- Требуется примерно понимать, сколько воркеров мы готовы выделить в php-fpm в каждом контейнере. Например, мы можем выделить 10 воркеров для обработки входящих вопросов и выделить меньше ресурсов на pod и масштабироваться с помощью количества pod’ов — это хорошая практика. Другой пример — можно выделить 500 воркеров на каждый pod и иметь 2–3 таких pod’а в production…, но это довольно плохая идея.
- Требуются liveness/readiness probes для проверки корректности работы каждого pod’а и на случай, когда pod «залип» из-за проблем с сетью или из-за доступов к базе (тут может быть любой ваш вариант и причина). В таких ситуациях необходимо пересоздавать проблемный pod.
- Важно явно прописывать request и limit ресурсов на каждый контейнер, чтобы приложение не «потекло» и не начало вредить всем сервисам на данном сервере.
Решения
К сожалению, нет серебряной пули, помогающей сразу понять, какое количество ресурсов (CPU, RAM) может понадобиться приложению. Возможный вариант — смотреть потребление ресурсов и с каждым разом подбирать оптимальные величины. Во избежание неоправданных OOM killer’ов и CPU throttling’а, что сильно сказывается на работе сервиса:
- … потребуются корректные liveness/readiness probes, чтобы мы могли точно сказать, что данный контейнер работает корректно. Скорее всего это будет некая страница (служебная), которая проверяет доступность всех элементов инфраструктуры и возвращать код ответа 200 OK.
- … необходимо корректно подобрать количество воркеров, которые будут обрабатывать запросы, и корректно их распределять.
Например, у нас есть 10 pod’ов, которые состоят из двух контейнеров: nginx (для отдачи статики и проксирования запросов на backend) и php-fpm (собственно backend, который обрабатывает динамические страницы). Php-fpm pool настроен на статичное количество воркеров (10). Таким образом, в единицу времени мы можем обрабатывать 100 активных запросов к бэкендам…
Пусть каждый запрос обрабатывается PHP за 1 секунду. Что произойдёт, если в один конкретный pod, в котором сейчас активно обрабатываются 10 запросов, прилетит еще 1 запрос? PHP не сможет его обработать и Ingress отправит его на повторную попытку в следующий pod (если это GET-запрос), а если был POST-запрос, то вернет ошибку. Если еще учесть, что во время обработки всех 10 запросов у нас прилетит проверка от kubelet (liveness probe), она завершится с ошибкой и Kubernetes начнет думать, что с данным контейнером что-то не так (убьет его). При этом все запросы, которые обрабатывались в данный момент, завершатся с ошибкой (!) и на момент рестарта контейнера он выпадет из балансировки, что повлечет за собой увеличение запросов на все остальные бэкенды…
Наглядно
Предположим, что у нас есть 2 pod’а, у которых настроено по 10 воркеров php-fpm. Вот график, который отображает информацию во время «простоя», т.е. когда единственный, кто запрашивает php-fpm, — это php-fpm exporter (мы имеем по одному активному воркеру):
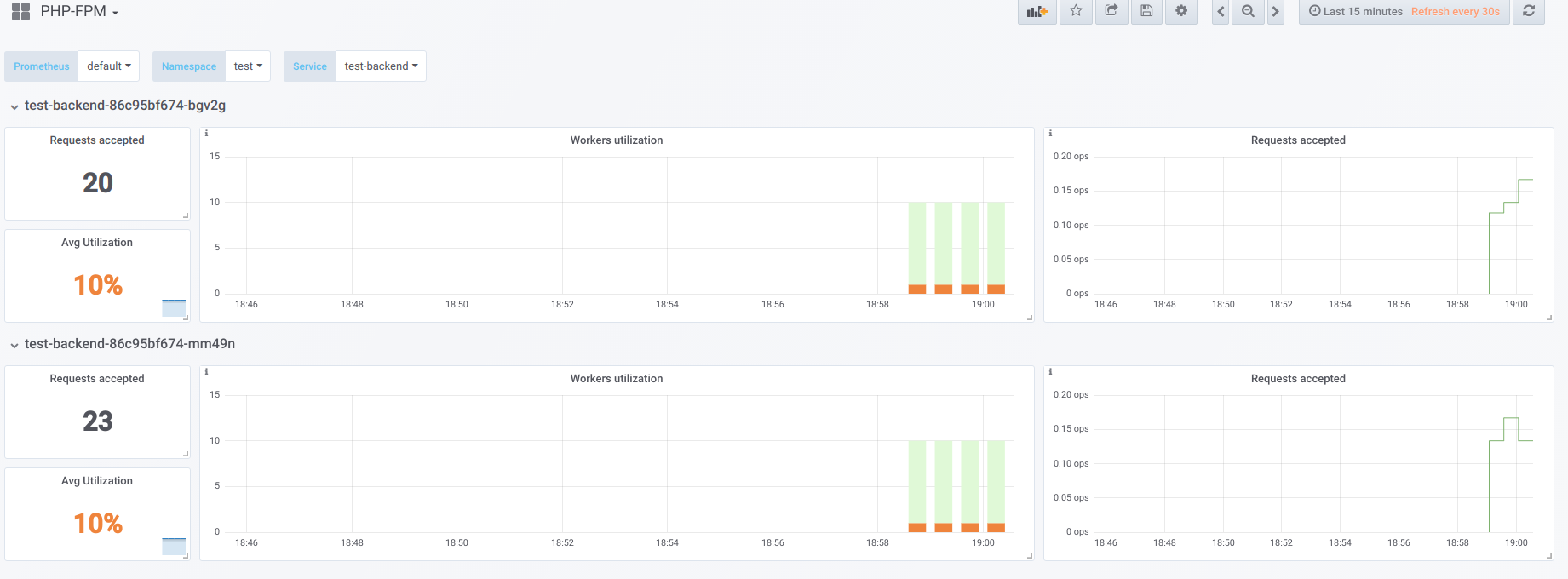
Теперь запустим загрузку с concurrency 19:
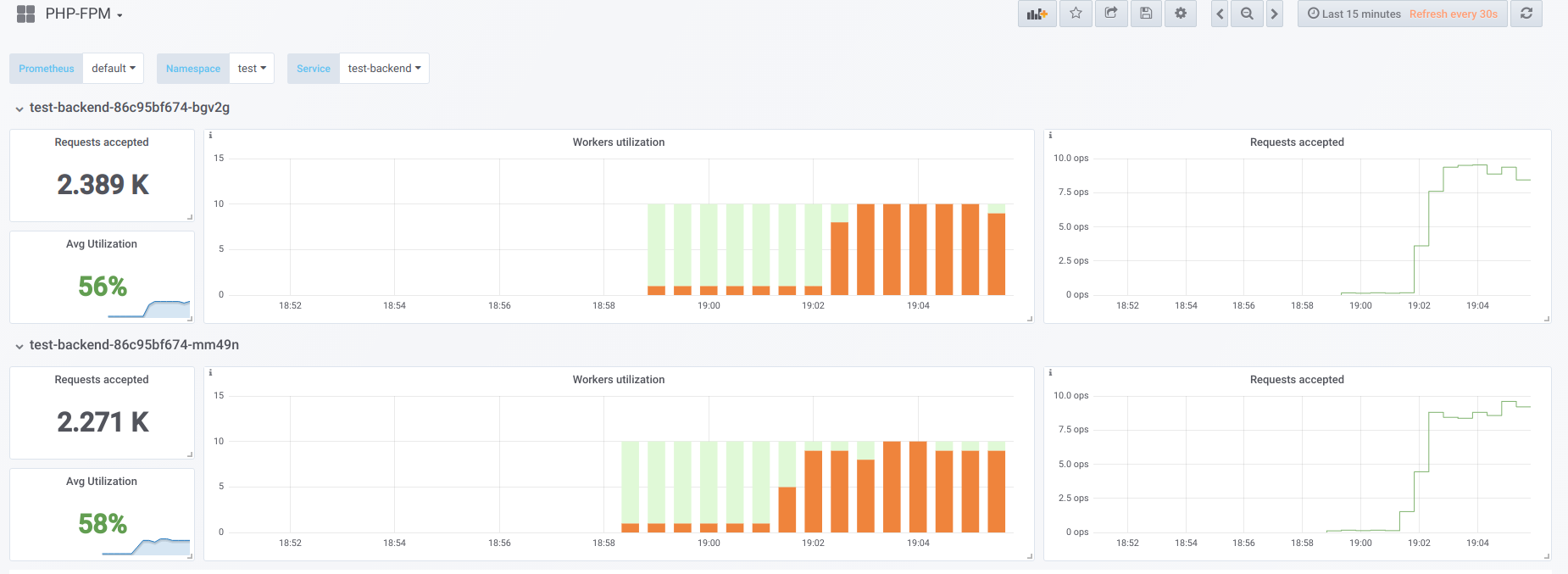
А теперь попробуем сделать concurrency выше, чем мы можем обработать (20)… допустим, 23. Тогда все воркеры php-fpm заняты обработкой клиентских запросов:

Воркеров перестаёт хватать для обработки liveness-пробы, поэтому мы наблюдаем такую картину в Kubernetes dashboard (или describe pod):

Теперь, когда один из pod’ов перезагружается, случается лавинный эффект: запросы начинают попадать на второй pod, который тоже не способен их обрабатывать, из-за чего мы получаем большое количество ошибок у клиентов. После того, как пулы всех контейнеров переполнятся, поднять сервис проблематично — только резким увеличением количества pod’ов или воркеров.
Первый вариант
В контейнере с PHP можно настроить 2 пула fpm: один для обработки клиентских запросов, другой — для проверки «живучести» контейнера. Тогда на контейнере nginx потребуется сделать подобную конфигурацию:
upstream backend {
server 127.0.0.1:9000 max_fails=0;
}
upstream backend-status {
server 127.0.0.1:9001 max_fails=0;
}
Останется лишь направить liveness probe на обработку в upstream под названием backend-status.
Теперь, когда liveness probe обрабатывается отдельно, ошибки всё ещё будут происходить у некоторых клиентов, но хотя бы нет проблем, связанных с рестартом pod’а и обрывом соединений у остальных клиентов. Таким образом, мы сильно уменьшим количество ошибок, даже если наши бэкенды не справляются с текущей нагрузкой.
Этот вариант, безусловно, лучше, чем ничего, однако он плох ещё и тем, что может что-то произойти с основным пулом, о чём мы не узнаем с помощью liveness probe.
Второй вариант
Ещё можно воспользоваться не очень популярным модулем к nginx под названием nginx-limit-upstream. Далее с ним в PHP указать 11 воркеров, а в контейнере с nginx — сделать такой конфиг:
limit_upstream_zone limit 32m;
upstream backend {
server 127.0.0.1:9000 max_fails=0;
limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s;
}
upstream backend-status {
server 127.0.0.1:9000 max_fails=0;
}
Так мы на уровне frontend’а nginx ограничиваем количество запросов, которые будут переданы на backend как 10. Интересный же момент заключается в том, что создаётся специальный отложенный буфер (backlog). С ним, если от клиента приходит 11-й запрос на nginx, а nginx видит, что пул php-fpm занят работой, то данный запрос помещается в backlog на 5 секунд. Если в течение этого времени php-fpm не освободился, то в дело вступает Ingress, который делает retry запроса на другой pod. Это сглаживает картину, так как у нас всегда будет 1 свободный PHP-воркер для обработки liveness-пробы — это не повлечет за собой лавинный эффект.
Другие мысли
Для более универсальных и красивых вариантов решения этой проблемы стоит посмотреть в сторону Envoy и его аналогов.
Вообще же, для того, чтобы в Prometheus была наглядной занятость воркеров, что в свою очередь поможет быстро находить проблему (и уведомлять о ней), очень рекомендую обзавестись готовыми экспортерами, позволяющих преобразовывать данные из ПО в формат Prometheus.
P.S.
Другое из цикла K8s tips & tricks:
Читайте также в нашем блоге:
